- REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
- TL;DR
- Method
- 实验设计
- 不同方法的对比
- BadCase分析
- 实验设计
- Q&A
- Experiment
- WebShop
- 总结与思考
- 相关链接
REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
link
时间:22.10
单位:Princeton University && Google Brain
相关领域:Agent
作者相关工作:Shunyu Yao
被引次数:4520
项目主页:
- blog: https://research.google/blog/react-synergizing-reasoning-and-acting-in-language-models/
- 主页:https://react-lm.github.io/
- code: https://github.com/ysymyth/ReAct
TL;DR
大语言模型LLMs的推理能力(reasoning)与执行能力(acting)通常作为两个Topic分开研究。本文提出ReACT(Reasoning and Acting),研究如何使两者更好协同,Reasoning能力使模型推导及更新规划,而Acting使用模型可以从环境中接口里获取到更多知识信息。
Method
实验设计
Domains: 在这两个任务中,模型仅接收问题/陈述本身,而不直接获取任何可能包含答案的支撑文档或段落。这意味着模型必须完全依赖其内部知识或通过与外部环境交互来获取必要信息。
Action Space
Wikipedia Web API有三种接口:
- search:根据给定的实体名称(如"George Washington")进行搜索。
- lookup:在当前打开的维基百科页面中,查找包含特定字符串的下一句话。
- finish:终止当前任务,并提交最终答案。

不同方法的对比
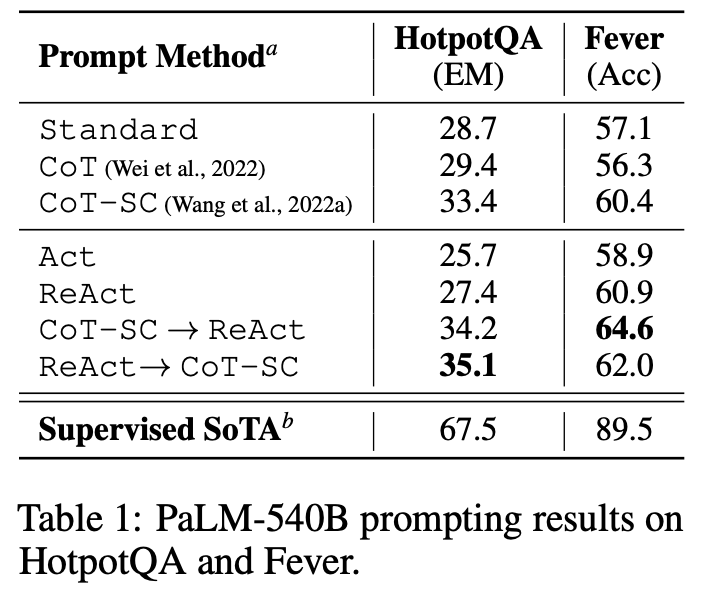
HotPotQA:multi-hop question answering,多轮对话测试集
FEVER:fact verification,事实验证的Benchmark
- CoT-SC: SC是 Self-Consistency 的缩写。其核心做法是在推理时,通过提高解码温度(temperature)来从语言模型中采样生成多条(例如21条)不同的推理轨迹,然后通过多数投票(majority vote)的方式从这些答案中选择最一致的一个作为最终答案,以此提高准确性和鲁棒性。
- ReAct → CoT-SC: 指首先尝试使用ReAct方法(通过API与环境交互获取外部信息)来解决问题。如果ReAct在设定的最大步数内(HotpotQA为7步,FEVER为5步)未能得出答案,则回退(back off) 到使用CoT-SC方法,依赖模型的内部知识进行推理。
- CoT-SC → ReAct: 指首先使用CoT-SC方法进行推理。如果CoT-SC采样产生的多个答案中,得票最高的答案其票数未能超过总采样数的一半(即 n/2),表明模型的内部知识对于此问题并不自信或存在分歧,此时则回退到使用ReAct方法,通过外部交互来寻找答案。
BadCase分析
- CoT的主要问题:幻觉(Hallucination)。这是CoT最主要的失败模式(占56%),即推理链条中混入了不正确的事实或信息。
- ReAct的主要问题:推理错误(Reasoning Error) 和搜索结果错误(Search Result Error)。
Q&A
Q:图1d这种模式对于现在agent很常见,为什么会是本文创新点?
A:“思考-行动-观察”的循环模式如今已成为构建AI Agent的常见范式。但在本文发表的当时(2022年),这是一个重要的范式创新。本文是首个系统性地、通用地将“推理”和“行动”在语言模型中交织(interleave) 起来的工作,并为其命名(ReAct)。
Q:文中的Acting指得是什么?
A:Acting 指的是模型能够发出可执行的动作,与外部环境(external environment) 进行交互,从而获取新的信息或改变环境状态。在知识密集型任务(如HotpotQA, FEVER)中,Acting 特指通过一个简单的 Wikipedia API 进行交互,动作包括:search, lookup, finish。
Experiment
WebShop
WebShop是一个模拟的在线购物网站环境,它包含了从亚马逊爬取的118万种真实商品和1.2万条人类指令。
智能体(Agent)的任务是根据用户的自然语言指令购买符合要求的产品。指令通常包含多项属性要求,例如:“I am looking for a nightstand with drawers. It should have a nickel finish, and priced lower than $140”(我需要一个带抽屉的床头柜。它应该是镍色 finish,并且价格低于140美元)。
评估指标 (Evaluation Metrics)
- 成功率 (Success Rate, SR): 智能体最终购买的商品完全满足指令中所有要求的任务比例
- 平均得分 (Score): 一个更细粒度的指标,计算智能体购买的商品所满足的指令属性要求的百分比,然后在整个测试集上求平均。
基线模型 (Baselines) - 作者将ReAct与之前需要大量数据训练的方法进行比较:
- 模仿学习 (Imitation Learning, IL): 在1,012条人类标注的轨迹上进行训练
- 模仿+强化学习 (IL+RL): 在IL的基础上,额外使用10,587条训练指令进行强化学习优化。
![image]()

总结与思考
比较早想到结合Reasoning与Acting的方法,也设计了比较严谨来证明有效性。可以被认为是Agent系列工作的先驱之作。
相关链接
https://zhuanlan.zhihu.com/p/1921961266257336099