第一题
核心代码和运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup# 获取2020年中国大学排名数据
target_url = "http://www.shanghairanking.cn/rankings/bcur/2020"
page_response = requests.get(target_url)
page_response.encoding = "utf-8"page_content = BeautifulSoup(page_response.text, "html.parser")# 定位大学信息所在的表格行
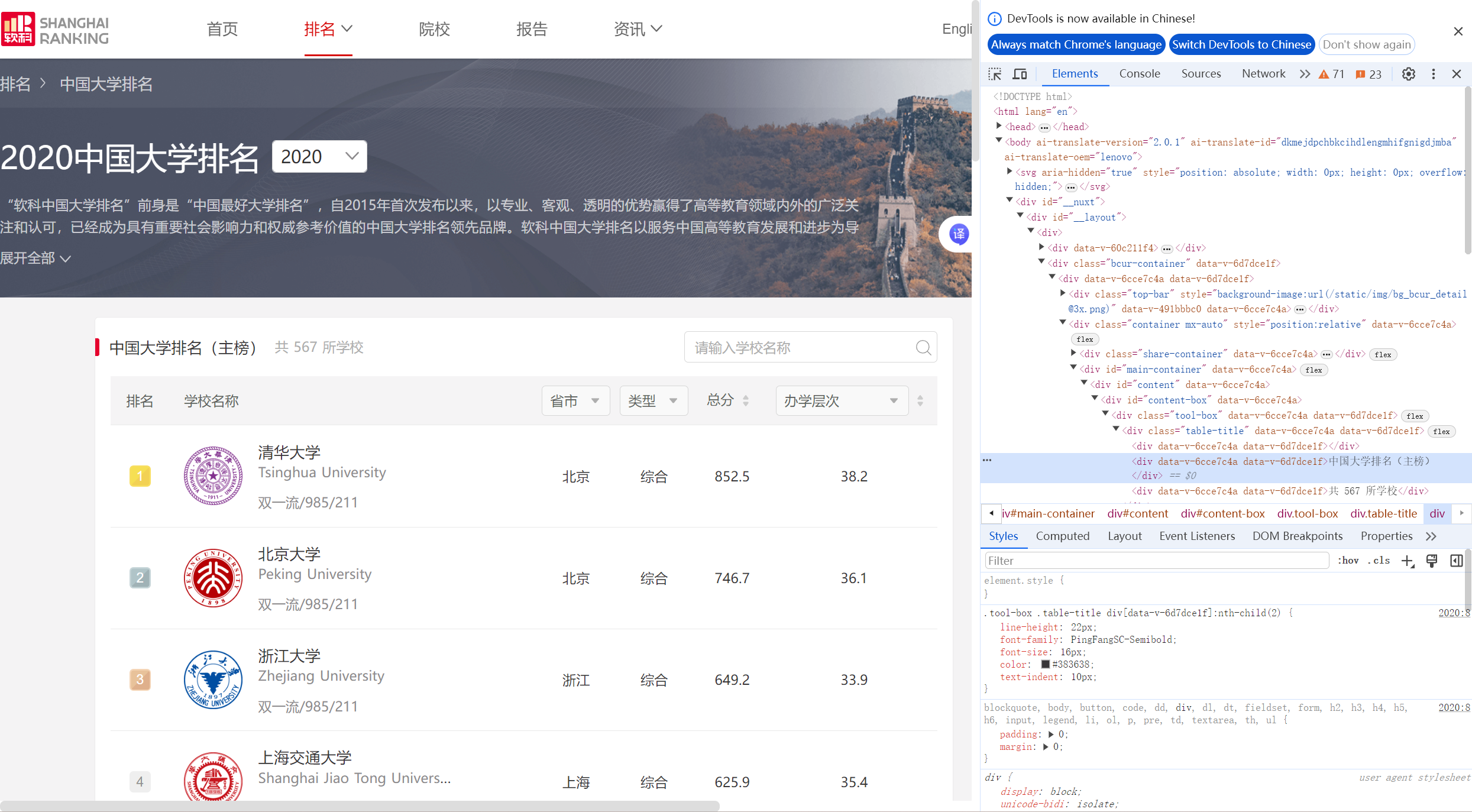
college_data_rows = page_content.select('tr[data-v-389300f0]')print("位次 院校名称\t\t地区\t类别\t综合得分")
print("=" * 55)# 解析并显示每所大学的信息
for data_row in college_data_rows:rank_element = data_row.select_one("div.ranking")if rank_element:table_cells = data_row.find_all("td")if len(table_cells) >= 5:ranking = rank_element.get_text().strip()chinese_name = table_cells[1].select_one("span.name-cn")college_name = chinese_name.get_text().strip() if chinese_name else "未获取"location = table_cells[2].get_text().strip()category = table_cells[3].get_text().strip()total_score = table_cells[4].get_text().strip()print(f"{ranking:>3} {college_name:14} {location:6} {category:6} {total_score:6}")

作业心得
本次实验我掌握了requests和BeautifulSoup的基本用法,在实验中,我先访问了目标网站,然后确定目标数据的位置和HTML标签结构,并检查网页是否使用JavaScript动态加载,最后使用requests进行HTTP请求,BeautifulSoup进行HTML解析,在提取数据时,我发现数据格式不一致,在检查元素数量后发现越界,修改后解决了问题。由于数据通过JavaScript加载,分页内容无法获取,我尝试使用Selenium渲染html,解决问题。
第二题
核心代码和运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
import re
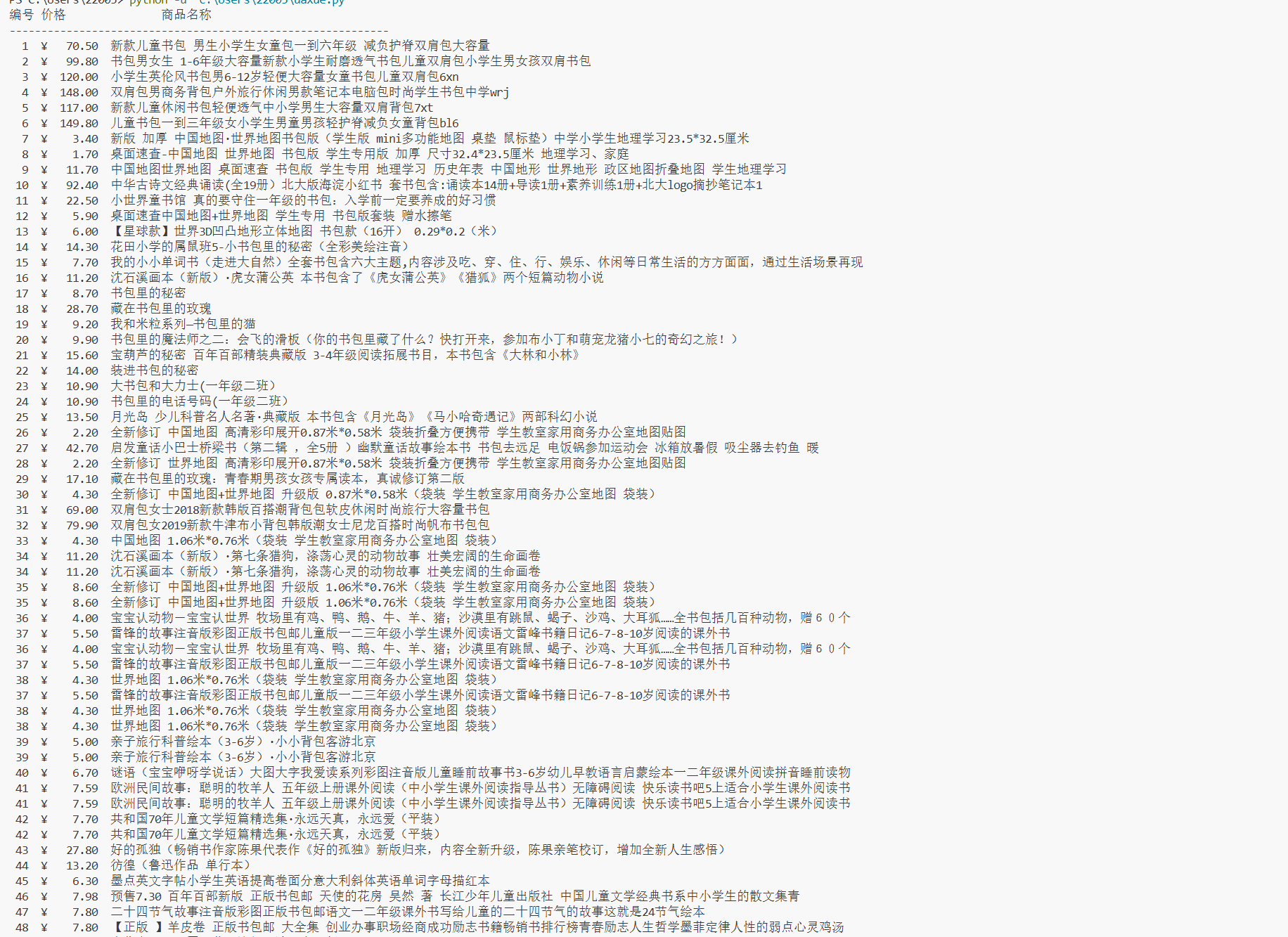
def fetch_book_products():"""获取当当网书包搜索页面商品信息"""# 目标网页地址page_url = 'https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'# 发送网络请求获取页面内容page_response = requests.get(page_url)page_response.encoding = "gbk"webpage_content = page_response.text# 使用正则表达式匹配商品列表项item_regex = r'<li[^>]*ddt-pit="\d+"[^>]*class="line\d+"[^>]*>.*?</li>'found_items = re.findall(item_regex, webpage_content, re.DOTALL)# 输出表头print("编号 价格\t\t商品名称")print("-" * 60)# 遍历每个匹配的商品项for product_item in found_items:# 提取商品编号item_id_match = re.search(r'ddt-pit="(\d+)"', product_item)product_id = item_id_match.group(1) if item_id_match else "N/A"# 提取商品标题name_match = re.search(r'<a title="([^"]+)"', product_item)product_name = name_match.group(1) if name_match else "未命名商品"# 提取商品价格cost_match = re.search(r'<span class="price_n">\s*¥\s*([\d.]+)\s*</span>', product_item)product_price = cost_match.group(1) if cost_match else "未知"# 格式化输出商品信息print(f"{product_id:>3} ¥{product_price:>8} {product_name:40}")
# 执行主函数
if __name__ == "__main__":fetch_book_products()
作业心得
在最开始选择目标网站时,我尝试了京东和淘宝,结果遭到了反爬机制的制裁,然后我选择了当当网,实验过程中,我发现于HTML结构复杂,数据格式存在不一致性,于是我修改了正则表达式使可以将html实体转化为¥符号。而且存在输出乱码的问题,尝试使用字节流分析网页gbk。最终成功格式化爬取结果。
第三题
核心代码和运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
from urllib.parse import urljoin
import time
def download_single_image(img_url, save_folder):"""下载单张图片并保存到指定文件夹"""try:# 获取图片数据img_response = requests.get(img_url)img_response.raise_for_status()# 生成文件名original_name = os.path.basename(img_url)save_path = os.path.join(save_folder, original_name)# 处理重名文件base_name, extension = os.path.splitext(original_name)duplicate_count = 1while os.path.exists(save_path):new_name = f"{base_name}_copy{duplicate_count}{extension}"save_path = os.path.join(save_folder, new_name)duplicate_count += 1# 保存图片with open(save_path, 'wb') as img_file:img_file.write(img_response.content)print(f"成功下载: {os.path.basename(save_path)}") # 添加短暂延迟避免请求过快time.sleep(0.1) except requests.exceptions.RequestException as error:print(f"下载失败 {img_url}: {error}")except IOError as error:print(f"文件保存失败 {img_url}: {error}")
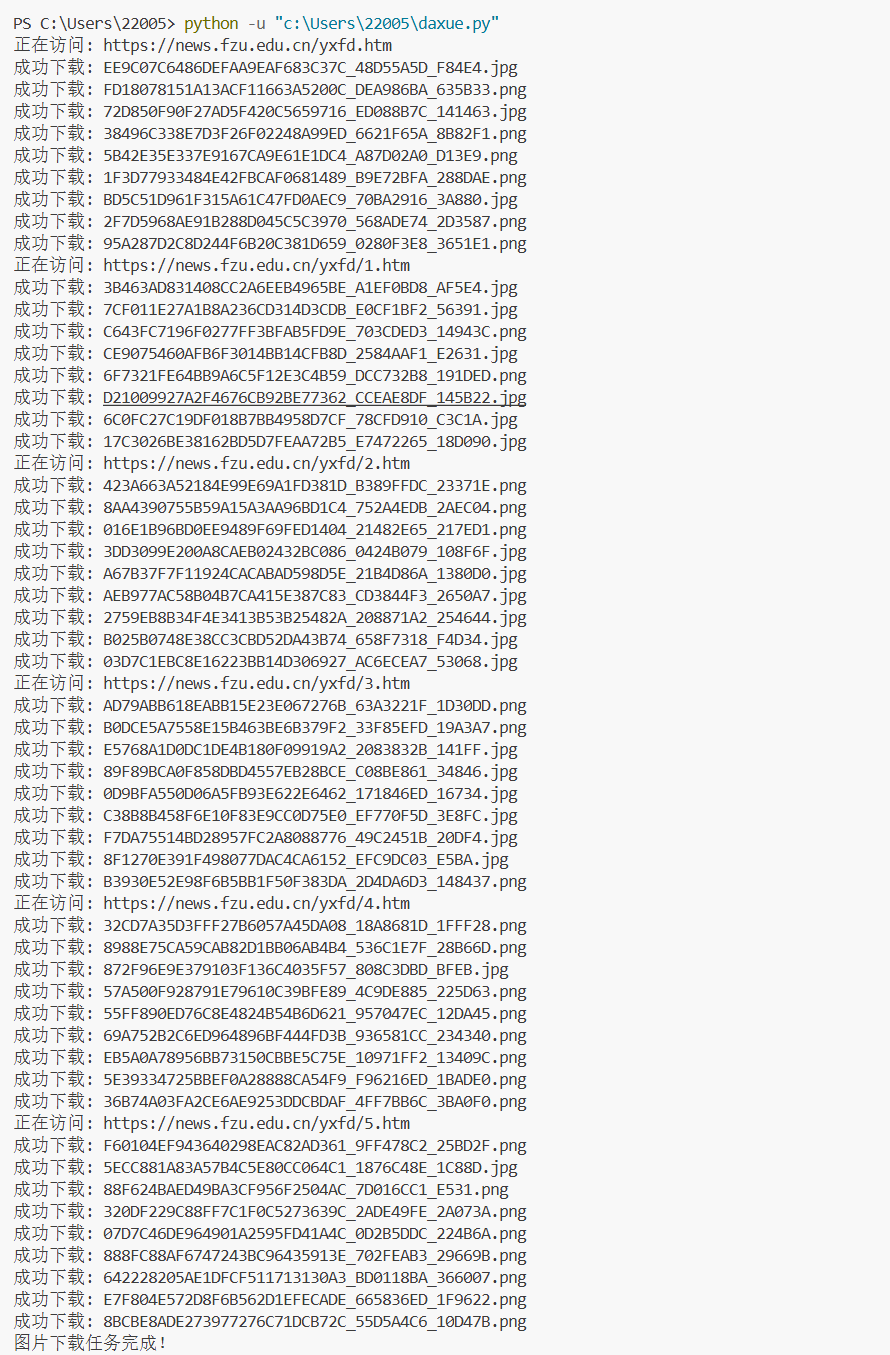
def fetch_web_images():"""从福州大学新闻网站下载图片到本地文件夹"""# 创建存储目录image_dir = 'fzu_pictures'if not os.path.exists(image_dir):os.mkdir(image_dir)print(f"创建目录: {image_dir}")# 处理多个页面for page_num in range(0, 6):# 构建页面URLif page_num == 0:target_url = 'https://news.fzu.edu.cn/yxfd.htm'else:target_url = f'https://news.fzu.edu.cn/yxfd/{page_num}.htm' print(f"正在访问: {target_url}") # 获取页面内容page_response = requests.get(target_url)page_response.encoding = 'utf-8'page_content = BeautifulSoup(page_response.text, 'lxml') # 定位图片容器image_containers = page_content.find_all('div', {'class': 'img slow'}) # 处理每个图片容器for container in image_containers:image_element = container.find('img')if image_element and image_element.has_attr('src'):image_src = image_element['src']full_image_url = urljoin(target_url, image_src) # 验证图片格式valid_extensions = ('.jpg', '.jpeg', '.png', '.gif')if full_image_url.lower().endswith(valid_extensions):download_single_image(full_image_url, image_dir)print("图片下载任务完成!")
if __name__ == "__main__":fetch_web_images()
作业心得
我在实验中实验中运用requests库进行网页请求、BeautifulSoup解析HTML结构、os模块管理文件系统,遇到了函数定义顺序导致的NameError,通过调整函数定义顺序解决了这一问题,握了静态网页图片采集的完整流程。
代码链接:https://gitee.com/chen-caiyi041130/chen-caiyi