你好呀,我是歪歪。
最近遇到一个业务上的问题,在网上看到一个对应场景下的解决方案,我感觉这个场景还挺有通用性的,分享一下。
以后遇到类似问题,或者当它以面试场景题出现的时候,你可以拿去就用。

事情是这样的。
程序里面有一条“线路”,这个“线路”是购买的外部服务,使用起来是要收费的。
为了更好的理解这个“收费的线路”,你可以假设为这是一个付费的 AI 接口。
然后你可以把“线路”简单的理解为一个 FIFO 的公共队列,对应着多个生产者。
也就是同时有很多人,即消费者,在使用这个“AI 接口”提问。
画个示意图是这样的:
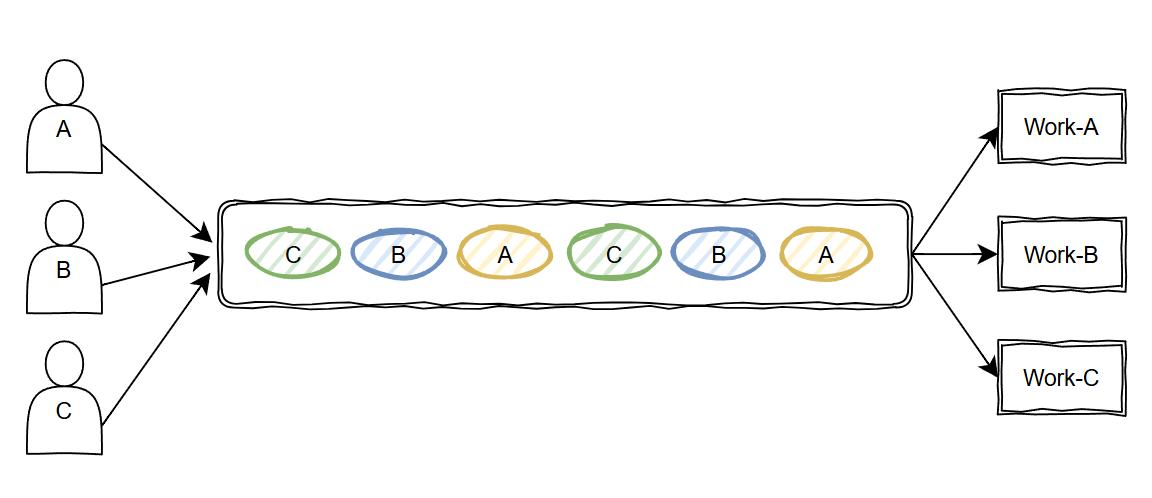
理想情况下,我们期望大家和和气气轮流用,你一个我一个,节奏均匀得像心跳。
但是,实际使用过程中,可能会出现一个卷王 A 生产者,突然快速的生产了大批量的数据,导致 B、C 生产者产生的少量的数据排在队列的最后面,等到天荒地老:
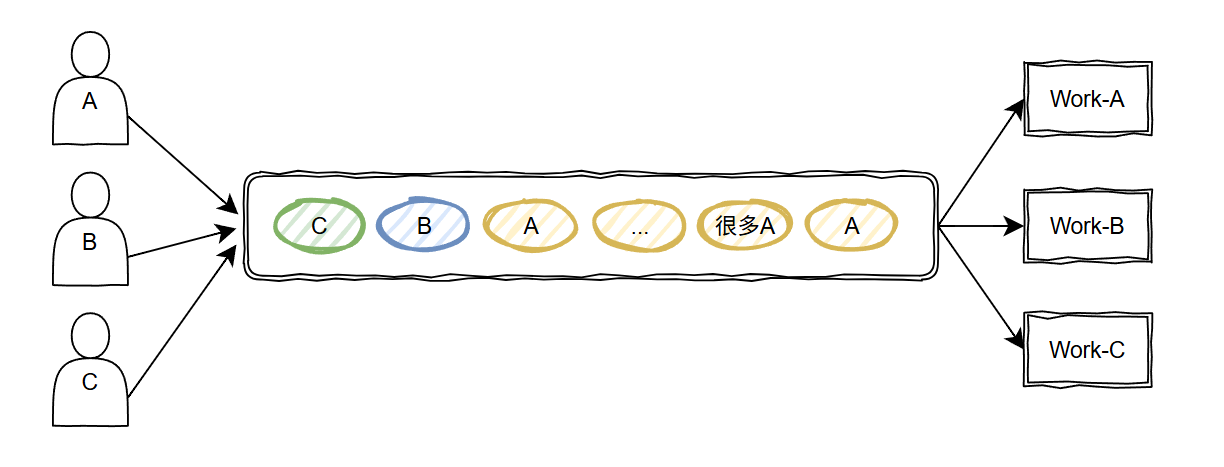
整个队列呈现出的短时间内只为 A 生产者服务的效果。
即 A 生产者“长时间霸占”了整个队列。
很明显,这样对其他生产者不友好。
我在网上查询了一下,这个现象还有一个专门的名词,叫做吵闹邻居问题(Noisy Neighbor Problem)。
主要是指在多租户环境中,单个用户过度占用资源导致其他用户服务质量下降的现象。
常见的方案
针对这个问题,常见的方案一般有两个。
第一个是把队列,即“线路”分来,就像这样:
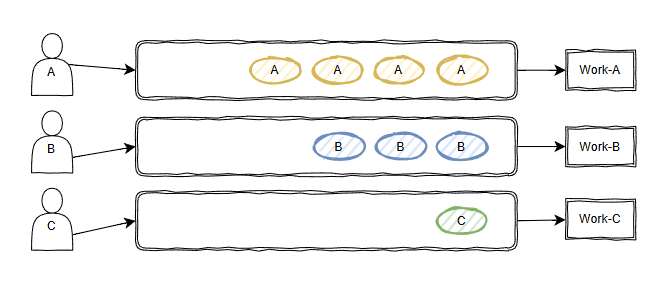
各玩儿各的,互不干扰。
没有邻居,也就不存在“吵闹邻居”的问题。
这样可以解决问题,但是会带来一个新的问题。
前面说了,这个“线路”是有购买成本的。
如果为每一个消费者都提供一个单独的队列,即上面说的“线路”,那成本就太高了。
那你可能会反驳一句:不需要为每个人提供单独的队列,只为高频使用的人员提供就行了嘛。
是的,这样也没有毛病。
但是实际情况是,高频使用的人, 也只是在某个小段时间内高频使用,随后就是长期的闲置,浪费购买成本。
而且,在实际情况中,还会出现一个情况是,某个低频使用的用户,突然在某一段时间出现业务高峰。
那这种情况为了不影响其他用户,还得紧急给业务高峰的用户搞个专门的队列。
运营成本太高。
所以,这个方案适用于长期稳定都是高频用户的情况。
第二个方案是限制生产者的生产速度。
这个方案在解决问题的同时也带来了新问题。
第一个问题是我需要实现一个限流功能,提升了基础组件的复杂度。
第二个问题是由于下游有限流机制,那上游必然就要有重试机制,增加了整体系统的复杂度。
这两个常见的方案,一个烧钱,一个烧脑。
我了解了之后,发现和我的场景都不太匹配,不能直接使用。
Amazon SQS
在我向大模型求助的时候,它给了我这样一个关键词:
智能调度算法:正如Amazon SQS所使用的公平队列(Fair Queueing) 机制,在软件层面确保资源被公平地分配给所有用户,防止任何一个用户垄断资源。

于是我在网上找到了 Amazon 官方网站中这个文章:
https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-fair-queues.html

从文章中的描述看,它有一个识别谁是“吵闹邻居”的机制:

当识别到 A 是一个“吵闹邻居”之后,Amazon SQS 会把其他租户(B、C 和 D)的消息放在最前面。
这里的“租户”,你可以认为就是我们前面提到的生产者。
这种优先级有助于保持安静租户 B、C 和 D 的低停留时间,而租户 A 的消息停留时间会延长,直到队列积压被消耗,而不会影响其他租户:
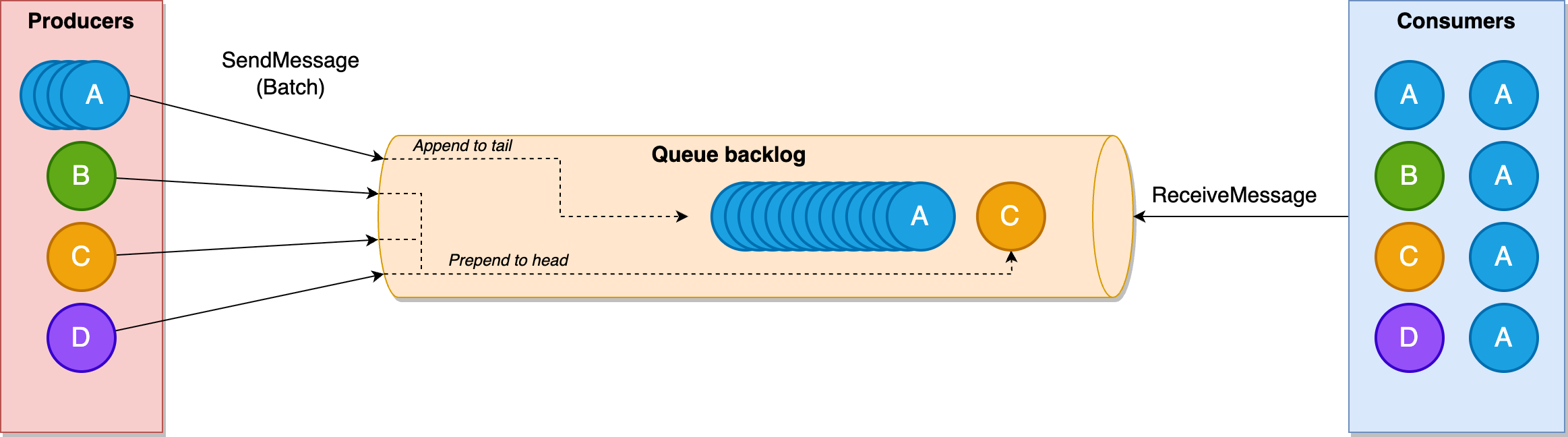
看起来确实能解决我的问题。
于是追问了一下大模型关于它的问题,想要进一步了解一下底层原理:


从大模型的回答来看,它核心逻辑是有一个“动态权重调整机制”。
“动态权重调整机制”的目的,我个人理解是为了给每个生产者一个合适的权重,从而决定这次生产的任务是应该放在队列的前面还是后面。
大概是这个意思:
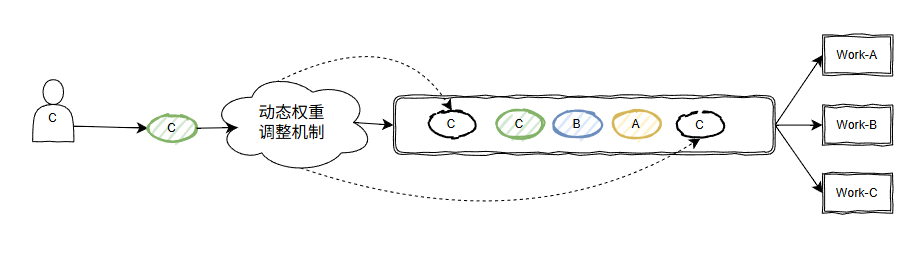
初步了解之后,感觉它底层实现还有点复杂,我把握不住。
有一种杀鸡用牛刀的感觉,所以我不打算使用它。
但是也不算白忙活,至少知道了 Amazon SQS 这个东西的存在。
换个思路
于是我在网上继续搜索,找到了这篇文章,它描述的思路,完美解决了我的问题:
https://densumesh.dev/blog/fair-queue/
而且它的思路很简单,简单到让我觉得如果让我深入的思考一下,也许我也能想到这个方案。
它的核心思路,用文章中的这张图就能说清楚:
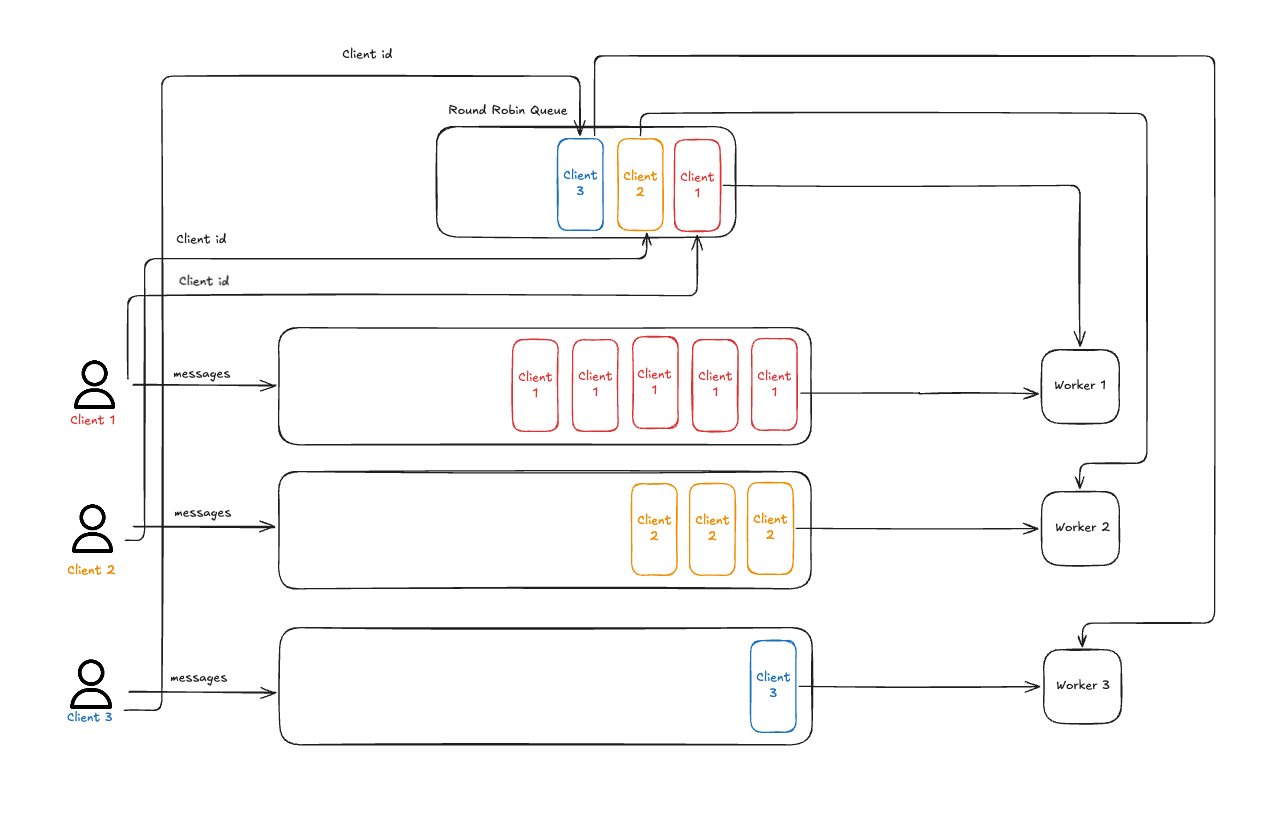
给每个生产者分配一个存放 messages 的队列,同时给每个生产者分配一个 client id。
然后你注意看这里:
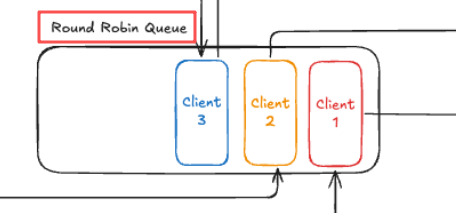
把 client id 放在一个 Round Robin Queue。
这是个什么玩意?
其实就是一个简单的轮询策略。
先从队首取出 client id。
然后由选择出的 client id 找到对应的 work 去从对应的队列中取出消息来消费。
最后视情况而定,是否需要把这个 client id 放在队尾。
由于轮询机制,所以会确保各个生产者的消息是交替执行。
作者使用 Rust 语言实现了上面的逻辑,并取名叫做:Broccoli。
翻译过来是一个我不喜欢吃的蔬菜:西兰花。
这是对应的仓库链接:
https://github.com/densumesh/broccoli
这个“西兰花”的核心架构非常简单,主要有两个主要组件:每个客户端的专用队列和单个轮转调度器。
对于基础组件来说,设计越简单,就越可靠。
作者在文章中也介绍了核心逻辑的伪代码:
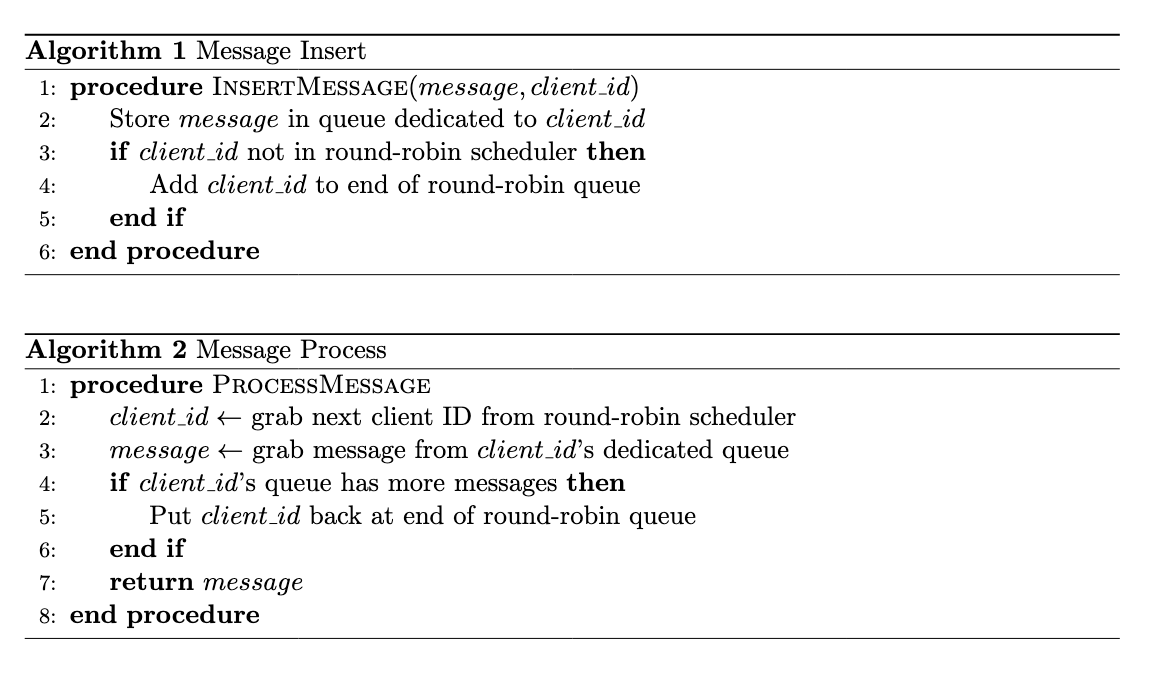
并不复杂,只有几行代码,我带你盘一盘。
核心逻辑分为两坨。
第一坨逻辑是产生新消息,对应插入操作。
首先,将某个生产者新产生的消息存储在一个专门的对应生产者的队列中。
然后,检查这个生产者对应的 client id 是否已经在轮询队列中。
如果在,那就完事了。
如果不在,那就把这个 client id 加在轮询队列的末尾。
只要放到轮询队列里面去了,就只需要等着被调度就行了。
第二坨逻辑是消费消息。
首先,从轮询队列中获取队首的 client id。
然后,从这个 client id 的专属队列中获取一条消息进行处理。
处理完毕后,检查这个 client id 的专属队列是否还有消息。
如果专属队列空了,这个 client id 就不需要放回到轮询队列了。
如果专属队列还有消息,那把这个 client id 放回到轮询队列的队尾,就完事了。
看起来逻辑确实非常简单、清晰。
这个方法的优点在于它完全能自我平衡。
“吵闹的邻居”会留在轮询队列中,“空闲的邻居”会自动退出,并且无论他们排队的工作量有多少,每个人都能公平地获得处理时间。
看到这里有的小伙伴可能会产生一个疑问:前面不是说了如果为每一个消费者都提供一个单独的队列,即付费“线路”,成本太高了吗?那为什么这里就可以一人一个呢?
我把上面的图,再多画一点出来,你就明白了:
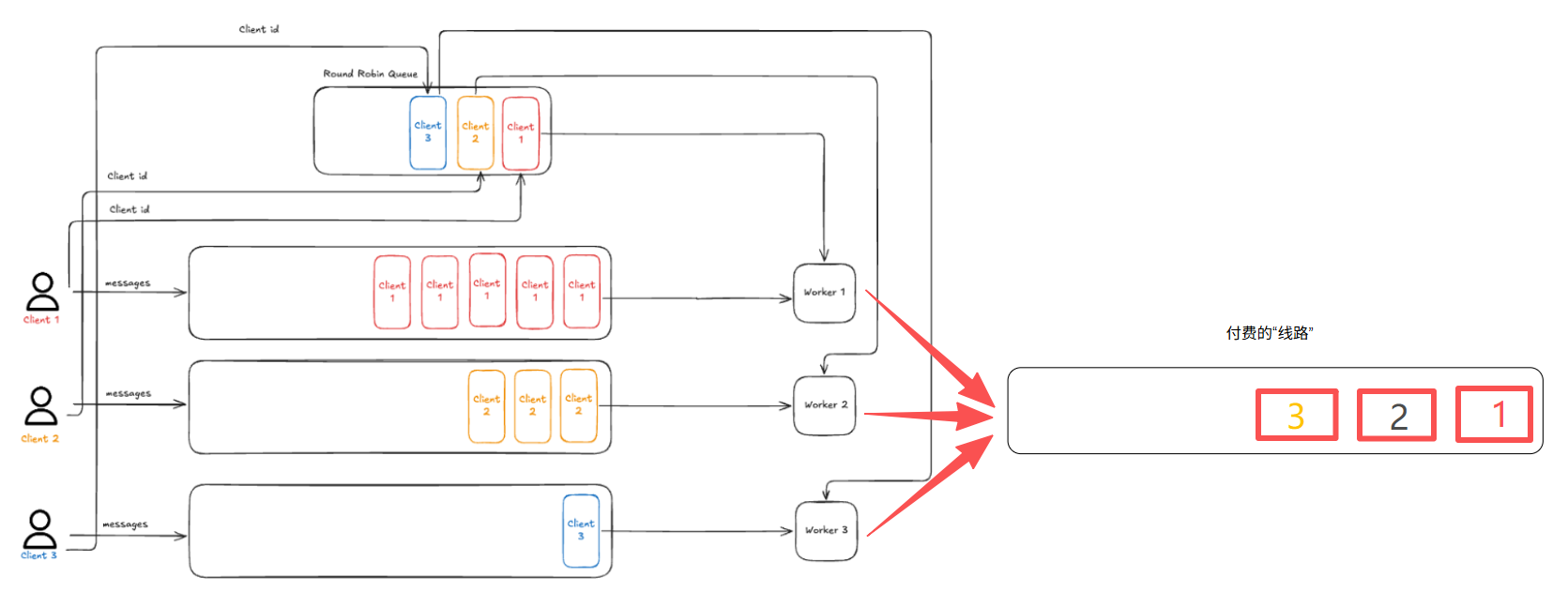
这里的“一人一个”是真的就一个队列而已。
经过这套逻辑之后,各个生产者的消息会呈现出交叉串行的形态,再穿过真正的“付费线路”。
“付费线路”只有一条,并没有产生额外的费用。
代码
思路有了,代码不是手到擒来的事儿吗?
我这里也不给你粘代码了,直接给你上个代码截图:
但是我可以告诉你怎么去获取对应的代码实现。
去问大模型就行了。
我把流程示意图和伪代码描述直接扔给 DeepSeek:

让它给我一份 Java 代码,就行了:

如果你让我按照上面的思路去敲代码,我觉得我至少得写 30 分钟才能把初版写好,而且这都算是快的。
现在,大模型会在一分钟内给你安排的明明白白:

你只需要最终检查一下代码逻辑就行了。
哎,我已经忘记上次纯古法手工敲代码是什么时候的事儿了。
眼熟吗?
另外,你有没有发现这个“Broccoli”方案,有点眼熟?
这不就是操作系统的进程调度器玩了几十年的经典套路吗?
早期的操作系统或某些简单场景下,CPU 调度使用先来先服务(FCFS)策略。
先到的进程先获得 CPU,执行完了才轮到下一个。
如果一个“计算密集型”的进程(比如 A 用户)拿到 CPU,它可能执行很长时间(比如一个耗时循环),导致后面所有“交互密集型”的进程(比如 B、C 用户的轻量任务)都被阻塞,系统响应速度急剧下降。
这不就是“吵闹邻居”问题的翻版吗?
A 进程就是那个吵闹邻居。
为了解决 FCFS 的公平性问题,操作系统引入了时间片轮转调度算法。
这几乎和“Broccoli”的方案一模一样。
核心思想是为每个进程分配一个固定的时间片。
进程在 CPU 上运行一个时间片后,就会被强制剥夺 CPU 使用权,并排到就绪队列的末尾,让下一个进程运行。
对应“西兰花”来说:
CPU 时间片 ->你的调度器每次从用户专属队列里取出一个任务进行处理。 就绪队列 -> 你的 Round Robin Queue(轮询队列),里面放的是有任务待处理的用户 ID。 剥夺 CPU 并排到队尾 -> 处理完一个用户的一个任务后,如果他还有任务,就把他的用户 ID 重新放回轮询队列的队尾。
现在看这张图,是不是感觉它就是一个微型的操作系统调度器?
而且,操作系统还有更高级的玩法——多级反馈队列。
这可以给“西兰花”未来的优化提供方向:
多队列:设置多个不同优先级的队列。新来的进程先进入最高优先级队列。 时间片不同:高优先级队列的时间片短(保证响应快),低优先级队列的时间片长(提高吞吐量)。 反馈机制:如果一个进程在一个时间片内用完了还没结束,说明它可能是“长任务”,就把它降级到低优先级队列。如果一个进程在时间片用完前主动放弃 CPU(比如进行I/O操作),说明它可能是交互式的“短任务”,就让它留在高优先级队列。
另外,操作系统调度磁盘 I/O 请求时,也会遇到一模一样的问题。
如果完全按照 FIFO,某个进程的大量顺序读写请求会霸占磁头,导致其他进程的随机读写请求饥饿。
解决方案之一就是电梯算法(SCAN) 或其变体,其核心也是将单个 FIFO 队列拆解,重新排序请求,以在公平性和效率之间取得平衡。
这和我们前面的思路,可以说是同宗同源。
所以,恭喜你,无意中在应用层瞥见了一个微内核的操作系统调度器!
最后,在上个价值。
计算机科学中很多看似复杂的底层原理,其核心思想都具有极强的普适性。
真正优秀的设计模式,会反复出现在从硬件到应用、从底层到高层的各个层面。
下次再有人问你如何解决资源争抢问题,你不仅可以甩出“西兰花”方案,还可以淡定地补充一句:
这其实就是操作系统级的时间片轮转调度算法在分布式系统中的应用。我们不过是在业务层,用最低的成本,复刻了操作系统几十年来验证过的公平性智慧。

好了,就到这里了。
这个方案之前是别人的,后来变成了我的,现在是你的了。
不客气,来个三连就行。