📘今日学习总结
一、博客美化
- 通过系统学习与实践,我对博客园平台的美化工作进行了全面的探索与实施。
- 本次学习的核心目标在于提升博客的视觉美感、增强用户体验以及融入个性化元素。
1.1整体视觉与布局的现代化改造
- 本次美化的基础是对博客整体框架进行了修改。
- 主题切换: 采用了备受推崇的 “SimpleMemory” 主题作为基底。
- 布局优化: 通过定制CSS代码,实现了:
- 内容区拓宽: 使文章显示区域更宽,减少了阅读时的局促感,提升了阅读效率。
- 结构清晰化: 对页头、导航栏、侧边栏和页脚进行了重新排版与设计,使博客结构层次分明,逻辑清晰。
1.2个性化功能元素的成功引入
在优化视觉的基础上,我重点引入了一系列互动性与个性化功能,让博客更加nice。
- 动态页脚: 在博客底部成功添加了网站运行时间统计。这个动态更新的元素不仅是一个有趣的小功能,更象征着博客与访客之间一段持续的陪伴,赋予了博客一丝“生命感”。
- 互动看板娘: 成功在页面一角部署了Live2D看板娘。她能够跟随鼠标移动、显示欢迎语并提供简单的互动。这个元素的加入极大地增强了博客的亲和力与趣味性,有效拉近了与访客的距离。
- 样式深度定制:
- 色彩体系: 修改了默认的链接色、背景色等,建立了属于自己的博客色彩标识,避免了千篇一律。
- 代码高亮: 为博客中的代码块更换了美观清晰的语法高亮主题,使其阅读体验堪比专业编辑器,对技术类博客的内容呈现至关重要。
二、Transformer 模型核心机制
-
Transformer 模型由编码器-解码器结构组成,完全基于注意力机制,摒弃了传统的 CNN 和 RNN。
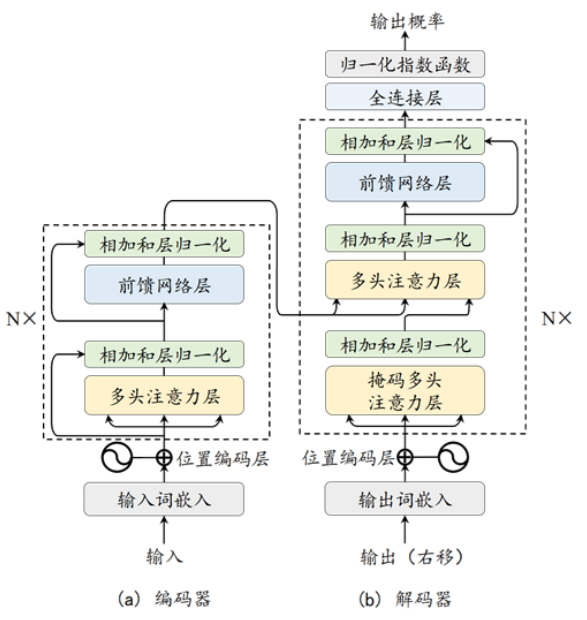
-
其核心机制包括:
2.1注意力机制
-
通过 Query、Key、Value 矩阵计算相似度,实现加权求和。
-
公式为:$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{D}}\right)V$$
-
使用点积注意力是因为其计算效率高,优于加法注意力。
2.2多头注意力
- 将注意力拆分为多个“头”,每个头关注不同语义空间,最后合并结果。
- 类似 CNN 中使用多个卷积核,增强模型表达能力。
2.3位置编码
- Transformer 本身不具备序列顺序感知能力,需引入位置编码。
- 常用正弦-余弦函数编码,也有可学习或 RoPE、ALiBi 等变体。
4. 前馈网络与残差连接
- 前馈网络通常为两层线性变换加激活函数(如 ReLU、GELU、SwiGLU)。
- 残差连接与层归一化提升训练稳定性。
三、大语言模型的关键配置
构建大模型时需考虑以下配置:
3.1归一化方法
![image-20251016093919467]
2. 激活函数

3. 位置编码方式
- 绝对位置编码:如原始 Transformer 的 sin/cos 编码。
- 相对位置编码:如 RoPE、ALiBi,能更好地处理长序列和外推任务。
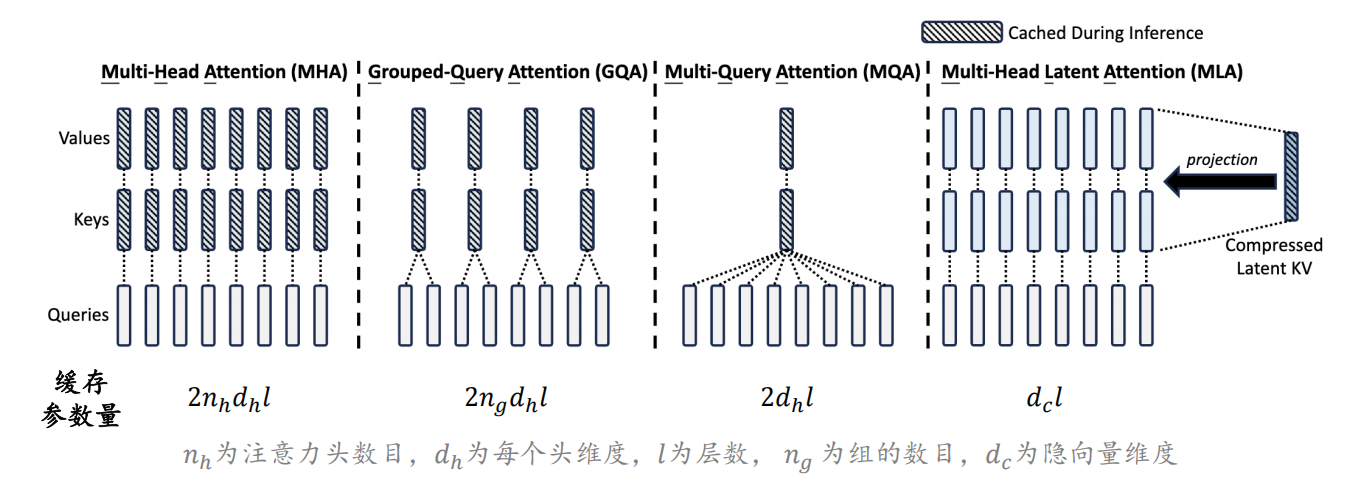
4. 注意力机制优化
- MQA、GQA:减少 KV 缓存,提升推理速度。
- MLA:DeepSeek-V2 提出,进一步压缩 KV Cache,降低显存。
![[image-20251016094411201.png]]
5. 混合专家架构
- 使用多个专家网络,每个词元仅激活部分专家,实现参数扩展而不显著增加计算成本。
四、长上下文模型与扩展方法
为处理长文本(如 128K、200K 甚至 2M 上下文),模型需进行扩展和优化:
4.1长度外推方法
- ALiBi:通过线性偏置惩罚远距离词元,增强外推能力。
- RoPE 扩展:
- 位置插值:缩放位置索引。
- NTK-RoPE:动态调整旋转基,无需训练即可扩展上下文。
- 旋转基截断:控制旋转角度分布,防止超出训练范围。
4.2受限注意力机制
- 并行上下文窗口:分段编码,但顺序关系建模弱。
- Λ型上下文窗口:仅关注开头和邻近词元,如 StreamingLLM。
- 词元选择:基于相似度检索远距离词元,如 Focused Transformer。
4.3长文本数据训练
- 使用少量长文本数据继续预训练,可有效扩展上下文窗口。
- 数据需多样化、连贯,并进行聚合与上采样。
五、新型模型架构探索
为克服 Transformer 在长序列上的计算瓶颈,出现了一系列新型架构:
5.1状态空间模型
- Mamba:引入输入依赖的选择机制,实现线性复杂度。
- RWKV:结合 RNN 与 Transformer 优点,支持并行训练与高效推理。
- RetNet:使用多尺度保留机制,支持递归、并行和分块计算。
- Hyena:使用长卷积与门控机制,替代注意力层。
5.2模型对比
- SSM 类模型在长序列上具有更好的计算效率,但在表达能力上仍需优化。
- 多数新型模型仍在发展中,尚未完全取代 Transformer。
📘今日学习总结
一、博客美化
- 通过系统学习与实践,我对博客园平台的美化工作进行了全面的探索与实施。
- 本次学习的核心目标在于提升博客的视觉美感、增强用户体验以及融入个性化元素。
1.1整体视觉与布局的现代化改造
- 本次美化的基础是对博客整体框架进行了修改。
- 主题切换: 采用了备受推崇的 “SimpleMemory” 主题作为基底。
- 布局优化: 通过定制CSS代码,实现了:
- 内容区拓宽: 使文章显示区域更宽,减少了阅读时的局促感,提升了阅读效率。
- 结构清晰化: 对页头、导航栏、侧边栏和页脚进行了重新排版与设计,使博客结构层次分明,逻辑清晰。
1.2个性化功能元素的成功引入
在优化视觉的基础上,我重点引入了一系列互动性与个性化功能,让博客更加nice。
- 动态页脚: 在博客底部成功添加了网站运行时间统计。这个动态更新的元素不仅是一个有趣的小功能,更象征着博客与访客之间一段持续的陪伴,赋予了博客一丝“生命感”。
- 互动看板娘: 成功在页面一角部署了Live2D看板娘。她能够跟随鼠标移动、显示欢迎语并提供简单的互动。这个元素的加入极大地增强了博客的亲和力与趣味性,有效拉近了与访客的距离。
- 样式深度定制:
- 色彩体系: 修改了默认的链接色、背景色等,建立了属于自己的博客色彩标识,避免了千篇一律。
- 代码高亮: 为博客中的代码块更换了美观清晰的语法高亮主题,使其阅读体验堪比专业编辑器,对技术类博客的内容呈现至关重要。
二、Transformer 模型核心机制
- Transformer 模型由编码器-解码器结构组成,完全基于注意力机制,摒弃了传统的 CNN 和 RNN。
其核心机制包括:
2.1注意力机制
-
通过 Query、Key、Value 矩阵计算相似度,实现加权求和。
-
公式为:$$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{D}}\right)V$$
-
使用点积注意力是因为其计算效率高,优于加法注意力。
2.2多头注意力
- 将注意力拆分为多个“头”,每个头关注不同语义空间,最后合并结果。
- 类似 CNN 中使用多个卷积核,增强模型表达能力。
2.3位置编码
- Transformer 本身不具备序列顺序感知能力,需引入位置编码。
- 常用正弦-余弦函数编码,也有可学习或 RoPE、ALiBi 等变体。
4. 前馈网络与残差连接
- 前馈网络通常为两层线性变换加激活函数(如 ReLU、GELU、SwiGLU)。
- 残差连接与层归一化提升训练稳定性。
三、大语言模型的关键配置
构建大模型时需考虑以下配置:
3.1归一化方法
![[image-20251016093919467.png]]
2. 激活函数
![[image-20251016094024787.png]]
3. 位置编码方式
- 绝对位置编码:如原始 Transformer 的 sin/cos 编码。
- 相对位置编码:如 RoPE、ALiBi,能更好地处理长序列和外推任务。
4. 注意力机制优化
- MQA、GQA:减少 KV 缓存,提升推理速度。
- MLA:DeepSeek-V2 提出,进一步压缩 KV Cache,降低显存。
![[image-20251016094411201.png]]
5. 混合专家架构
- 使用多个专家网络,每个词元仅激活部分专家,实现参数扩展而不显著增加计算成本。
四、长上下文模型与扩展方法
为处理长文本(如 128K、200K 甚至 2M 上下文),模型需进行扩展和优化:
4.1长度外推方法
- ALiBi:通过线性偏置惩罚远距离词元,增强外推能力。
- RoPE 扩展:
- 位置插值:缩放位置索引。
- NTK-RoPE:动态调整旋转基,无需训练即可扩展上下文。
- 旋转基截断:控制旋转角度分布,防止超出训练范围。
4.2受限注意力机制
- 并行上下文窗口:分段编码,但顺序关系建模弱。
- Λ型上下文窗口:仅关注开头和邻近词元,如 StreamingLLM。
- 词元选择:基于相似度检索远距离词元,如 Focused Transformer。
4.3长文本数据训练
- 使用少量长文本数据继续预训练,可有效扩展上下文窗口。
- 数据需多样化、连贯,并进行聚合与上采样。
五、新型模型架构探索
为克服 Transformer 在长序列上的计算瓶颈,出现了一系列新型架构:
5.1状态空间模型
- Mamba:引入输入依赖的选择机制,实现线性复杂度。
- RWKV:结合 RNN 与 Transformer 优点,支持并行训练与高效推理。
- RetNet:使用多尺度保留机制,支持递归、并行和分块计算。
- Hyena:使用长卷积与门控机制,替代注意力层。
5.2模型对比
- SSM 类模型在长序列上具有更好的计算效率,但在表达能力上仍需优化。
- 多数新型模型仍在发展中,尚未完全取代 Transformer。