彩笔运维勇闯机器学习--GBDT - 详解
前言
本文讨论的GBDT算法,也是基于决策树
开始探索
scikit-learn
老规矩,先上代码,看看GBDT的用法
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
gbdt_model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=0)
gbdt_model.fit(X_train, y_train)
gbdt_pred = gbdt_model.predict(X_test)
print("\nClassification Report (GBDT):")
print(classification_report(y_test, gbdt_pred))脚本!启动:
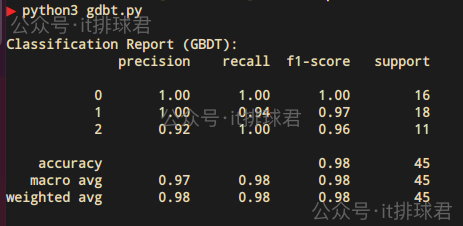
深入理解GBDT
GBDT全称,梯度提升决策树(Gradient Boosting Decision Tree),通过“不断拟合上一步误差”的方式来迭代构建模型,每一步都用一棵新的决策树来逼近当前的残差,从而不断提升整体模型性能
不断的迭代决策树,通过损失函数的负梯度作为每一轮迭代的优化目标,每一棵决策树纠正前一棵树的误差,最终将所有树的预测结果加权求和得到最终输出
基本思路
1)首先计算出初始概率:
预测值计算公式(logit公式): F=log(p1−p)F=log(\frac{p}{1-p})F=log(1−pp)
概率计算公式(sigmoid公式): P=11+e−FP=\frac{1}{1+e^{-F}}P=1+e−F1
2)计算残差,通过一棵回归树拟合该残差
Tt(x)={a,x∈正类b,x∈负类 \begin{aligned} T_t(x)= \left\{ \begin{array}{ll} a \qquad ,x ∈ 正类 \\ b \qquad ,x ∈ 负类 \end{array} \right. \end{aligned} Tt(x)={a,x∈正类b,x∈负类
3)再次计算概率
该轮预测值: Ft(x)=Ft−1(x)+η⋅Tt(x)F_t(x)=F_{t-1}(x)+η·T_t(x)Ft(x)=Ft−1(x)+η⋅Tt(x)
- Ft(x)F_t(x)Ft(x):当前轮次对x的预测值
- Ft−1F_{t-1}Ft−1:上一轮次对x的预测值
- ηηη:学习率,每轮更新的步长
- Tt(x)T_t(x)Tt(x):每轮训练的回归树,用来拟合上一轮训练的残差
计算出概率: P=11+e−FP=\frac{1}{1+e^{-F}}P=1+e−F1
4)计算残差、拟合残差、求树的梯度。循环往复,直至收敛
举例说明
下面以二分类任务为例,有10个样本,6个正类(1),4个负类(0)
1)计算初始概率
初始预测值:所有样本的初始预测值为正类的对数几率,通过logit函数计算:F=log(p1−p)=log(0.60.4)≈0.4055F=log(\frac{p}{1-p})=log(\frac{0.6}{0.4}) \approx 0.4055 F=log(1−pp)=log(0.40.6)≈0.4055
带入到sigmoid计算预测概率:P=11+e−F=11+e−0.4055≈0.6P=\frac{1}{1+e^{-F}}=\frac{1}{1+e^{-0.4055}} \approx 0.6P=1+e−F1=1+e−0.40551≈0.6
2)计算残差,所谓残差,是单个样本点的预测值与真实值之间的差
正类样本(1)的残差:ri=1−0.6=0.4r_i=1-0.6=0.4ri=1−0.6=0.4
负类样本(0)的残差:ri=0−0.6=−0.6r_i=0-0.6=-0.6ri=0−0.6=−0.6
3)训练第一棵决策回归树
Tt(x)={6⋅0.46=0.4,x∈正类4⋅(−0.6)4=−0.6,x∈负类 \begin{aligned} T_t(x)= \left\{ \begin{array}{ll} \frac{6·0.4}{6} = 0.4 \qquad ,x ∈ 正类 \\ \frac{4·(-0.6)}{4} = -0.6 \qquad ,x ∈ 负类 \end{array} \right. \end{aligned} Tt(x)={66⋅0.4=0.4,x∈正类44⋅(−0.6)=−0.6,x∈负类
4)再次计算概率
假设学习率η=0.1\eta=0.1η=0.1,更新模型预测:
- 正类预测:F正类=0.4055+0.1×0.4=0.4455F_{正类}=0.4055+0.1×0.4 = 0.4455F正类=0.4055+0.1×0.4=0.4455
- 负类预测:F负类=0.4055+0.1×(−0.6)=0.3455F_{负类}=0.4055+0.1×(−0.6) = 0.3455F负类=0.4055+0.1×(−0.6)=0.3455
计算预测概率
更新预测概率PPP
- 正类概率:P正类=11+e−0.4455≈0.6095P_{正类}=\frac{1}{1+e^{-0.4455}} \approx 0.6095P正类=1+e−0.44551≈0.6095
- 负类概率:P负类=11+e−0.3455≈0.5854P_{负类}=\frac{1}{1+e^{-0.3455}} \approx 0.5854P负类=1+e−0.34551≈0.5854
由于设置了迭代次数:n_estimators=5,继续迭代
4)计算二轮残差
- 正类残差:r正类=1−0.6095=0.3905r_{正类}=1-0.6095=0.3905r正类=1−0.6095=0.3905
- 负类残差:r负类=0−0.5854=−0.5854r_{负类}=0-0.5854=−0.5854r负类=0−0.5854=−0.5854
5)继续训练第二棵决策回归树
Tt(x)={6⋅0.39056=0.3905,x∈正类4⋅(−0.5854)4=−0.5854,x∈负类 \begin{aligned} T_t(x)= \left\{ \begin{array}{ll} \frac{6·0.3905}{6} = 0.3905 \qquad ,x ∈ 正类 \\ \frac{4·(-0.5854)}{4} = -0.5854 \qquad ,x ∈ 负类 \end{array} \right. \end{aligned} Tt(x)={66⋅0.3905=0.3905,x∈正类44⋅(−0.5854)=−0.5854,x∈负类
- 模型预测FFF
- 正类预测:F正类=0.4455+0.1×0.3905≈0.4846F_{正类}=0.4455+0.1×0.3905 \approx 0.4846F正类=0.4455+0.1×0.3905≈0.4846
- 负类预测:F负类=0.3455+0.1×(−0.5854)≈0.287F_{负类}=0.3455+0.1×(-0.5854) \approx 0.287F负类=0.3455+0.1×(−0.5854)≈0.287
- 预测概率PPP
- 正类概率:P正类≈0.6188P_{正类} \approx 0.6188P正类≈0.6188
- 负类概率:P负类≈0.5713P_{负类} \approx 0.5713P负类≈0.5713
6)不断迭代,直至n_estimators=5
默认使用最后一次的参数,有位彦祖就说,这不合理啊,有可能中途第三次训练的参数拟合度更高,为什么不用第三次的参数呢,这个问题可以使用早停法解决,后面会说
回归树
有位彦祖问了,我明明是做分类问题,为什么要用回归树来拟合残差?“回归”这个词到底指的是什么?
我们用的决策树,是回归决策树,是为了拟合残差。之前讨论过决策树,但是是分类决策树,这里简单描述一下回归决策树
直接上一个例子,更加明白。比如现在有一组样本
| x | y |
|---|---|
| 1 | 5 |
| 2 | 6 |
| 3 | 7 |
| 4 | 15 |
| 5 | 16 |
| 6 | 17 |
为了简单说明,假设我们的树深度只有1
1)选择切分点,两个样本中间
x = [1 2 3 4 5 6] => [1.5 2.5 3.5 4.5 5.5]
假设选择3.5的切分点
2)计算损失函数MSE
左子集:x = [1 2 3],y = [5 6 7]
- 均值:5+6+73=6\frac{5+6+7}{3} = 635+6+7=6
- MSE = 1n∑i=1n(yi−y^i)2=(5−6)2+(6−6)2+(7−6)23≈0.6667\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 = \frac{(5-6)^2+(6-6)^2+(7-6)^2}{3} \approx 0.6667n1∑i=1n(yi−y^i)2=3(5−6)2+(6−6)2+(7−6)2≈0.6667
右子集:x = [4 5 6],y = [15 16 17]
- 均值:15+16+173=16\frac{15+16+17}{3} = 16315+16+17=16
- MSE = 1n∑i=1n(yi−y^i)2=(15−16)2+(16−16)2+(17−16)23≈0.6667\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 = \frac{(15-16)^2+(16-16)^2+(17-16)^2}{3} \approx 0.6667n1∑i=1n(yi−y^i)2=3(15−16)2+(16−16)2+(17−16)2≈0.6667
加权总MSE:36⋅0.6667+36⋅0.6667=0.6667\frac{3}{6}·0.6667 + \frac{3}{6}·0.6667 = 0.666763⋅0.6667+63⋅0.6667=0.6667
也可以选择其他的分割点,然后计算MSE,选择最优分割点
3)拟合树
Tt(x)={5+6+73=6,x>3.515+16+173=16,x<=3.5 \begin{aligned} T_t(x)= \left\{ \begin{array}{ll} \frac{5+6+7}{3} = 6\qquad ,x > 3.5 \\ \frac{15+16+17}{3} = 16 \qquad ,x <= 3.5 \end{array} \right. \end{aligned} Tt(x)={35+6+7=6,x>3.5315+16+17=16,x<=3.5
残差与梯度
根据二分类的交叉熵公式以及求概率公式
{L(y,y^)=−(ylog(y^)+(1−y)log(1−y^))y^=11+e−F \begin{cases} L(y, \hat{y})=-(y \log(\hat{y}) + (1 - y) \log(1 - \hat{y})) \\ \hat{y}=\frac{1}{1+e^{-F}} \\ \end{cases} {L(y,y^)=−(ylog(y^)+(1−y)log(1−y^))y^=1+e−F1
对特征xxx求导,通过剥洋葱方法:
∂L∂F=∂L∂y^⋅∂y^∂F=−(yy^−1−y1−y^)⋅e−F(1+e−F)2\frac{\partial L}{\partial F}=\frac{\partial L}{\partial \hat{y}}·\frac{\partial \hat{y}}{\partial F}=-(\frac{y}{\hat{y}}-\frac{1-y}{1-\hat{y}})·\frac{e^{-F}}{(1+e^{-F})^2}∂F∂L=∂y^∂L⋅∂F∂y^=−(y^y−1−y^1−y)⋅(1+e−F)2e−F
由于y^=11+e−F\hat{y}=\frac{1}{1+e^{-F}}y^=1+e−F1,那么1−y^=e−F1+e−F1-\hat{y}=\frac{e^{-F}}{1+e^{-F}}1−y^=1+e−Fe−F,带入上面:
∂L∂F=−(yy^−1−y1−y^)⋅y^(1−y^)=y^−y\frac{\partial L}{\partial F}=-(\frac{y}{\hat{y}}-\frac{1-y}{1-\hat{y}})· \hat{y}(1-\hat{y})=\hat{y}-y∂F∂L=−(y^y−1−y^1−y)⋅y^(1−y^)=y^−y
梯度有了,那负梯度自然也计算出来了
y−y^y-\hat{y}y−y^
通过计算,负梯度=残差,所以,在上面演示的GBDT二分类任务中,就是沿着负梯度(残差)方向不断的寻找
早停法
顾名思义,就是发现模型性能下降的时候,立刻停止训练,并且保留性能最高的那组参数
import lightgbm as lgb
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = make_classification(n_samples=1000, n_features=20, random_state=0)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=0)
train_data = lgb.Dataset(X_train, label=y_train)
val_data = lgb.Dataset(X_val, label=y_val, reference=train_data)
params = {'objective': 'binary','metric': 'binary_logloss','learning_rate': 0.1,'max_depth': 3,'num_leaves': 7,'verbose': -1
}
model = lgb.train(params,train_data,num_boost_round=1000,valid_sets=[val_data],callbacks=[lgb.early_stopping(stopping_rounds=5),lgb.log_evaluation(period=10)]
)
y_pred = model.predict(X_val, num_iteration=model.best_iteration)
y_pred_binary = [1 if p > 0.5 else 0 for p in y_pred]
print(f"Validation Accuracy: {accuracy_score(y_val, y_pred_binary):.4f}")
print(f"Best iteration: {model.best_iteration}")脚本,启动!
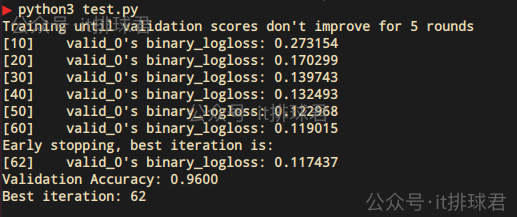
objective:binary表示分类任务的损失函数metric:binary_logloss表示监控指标为对数损失函数,也可以换成binary_error表示误差率num_boost_round=1000:最大迭代次数stopping_rounds=5:连续5轮不提升则停止period=10:每10轮打印日志
小结
给一组系统性能数据,能不能发现潜在的风险,风险判定为,日志错误率为>100条
如果错误日志为80条,虽然没有告警,但是系统已经在风险边缘了
先给一组数据,通过系统性能指标进行分类,然后再对于各时段的性能数据进行分类,看系统是否处于崩溃边缘
联系我
- 联系我,做深入的交流

至此,本文结束
在下才疏学浅,有撒汤漏水的,请各位不吝赐教…