通过token节流实现LLM流水线推理服务的全局负载均衡
背景
vllm中的流水线调度策略
在当前的vllm调度中,对于pipeline并行的实现还不完善,存在大量气泡,当前在vllm中的流水线并行调度如下。
以4卡的流水线并行推理为例,在vllm中,会启动4个worker,然后维护一个大小为4的batch_queue队列。当batch_queue不满的时候,就去从running队列和waiting队列中调度任务,然后去异步的运行。由于这里是异步调度的,所以每当有一次推理完成的时候,就会继续调度新的请求。这样就流水线跑起来了。
这部分代码逻辑如下:
def step_with_batch_queue(self) -> tuple[Optional[dict[int, EngineCoreOutputs]], bool]:batch_queue = self.batch_queuemodel_executed = Falseif self.scheduler.has_requests():scheduler_output = self.scheduler.schedule()future = self.model_executor.execute_model(scheduler_output,non_block=True)batch_queue.appendleft((future, scheduler_output)) # type: ignore[arg-type]model_executed = scheduler_output.total_num_scheduled_tokens > 0if model_executed and len(batch_queue) < self.batch_queue_size \and not batch_queue[-1][0].done():# Don't block on next worker response unless the queue is full# or there are no more requests to schedule.return None, Trueelif not batch_queue:# Queue is empty. We should not reach here since this method should# only be called when the scheduler contains requests or the queue# is non-empty.return None, False# Block until the next result is available.future, scheduler_output = batch_queue.pop()model_output = self.execute_model_with_error_logging(lambda _: future.result(), scheduler_output)return engine_core_outputs, model_executed
那么,这里的scheduler.schedule()是如何调度的呢。scheduler会获取一个token budget值,这个值表示本次最多可以调度用来计算的token数量。这里调度的token是指需要计算KV-cache的token。比如,在prefill阶段,所有的没有计算prefill的token都被计入1个,在decode阶段,由于是自回归的,所以往往一个请求只有1个token(就是上次生成的token)需要推理。另外,vllm的调度策略是FCFS(先来先服务)的,所以首先会按照请求抵达的顺序去调度running队列中的请求,当显存不足够满足当前请求的kv-cache空间请求的时候,会从后向前释放running队列中请求的显存占用,并将这些被抢占的请求加入waiting队列中。当running队列中的请求全部调度完,还有能力调度更多请求的时候,就去调度waiting的请求。
那么这个token budget的值是多少呢,是2048(没错是个定值)与model_max_len的较大值,值得说明的是,vllm的推理不是PD分离的,也就是说这token budget个token可以既调度prefill阶段的 token,也可以调度decode阶段的token。
这部分的代码比较长,链接在这
现有问题
在上述的调度策策略下,每次调度都没有进行全局考虑,只是尽可能在本次调度中调度更多的请求,这样就会导致很严重的负载不均衡。正常情况下,我的等待prefill的token数量往往是远远多于等待decode的token数量的。由于我只固定了总的token budget,并且是按照FCFS的策略调度的,这样实际上就成了首先调度所有的decode阶段请求,然后尽可能调度剩下的prefill请求来填满tokenbudget,往往这样会导致在后面prefill很快做完了,并且剩下了很多的decode阶段没有完成。
不妨假设一种极端情况,当前所有prefill都完成了,并且没有新的请求到来,这样只剩下一些decode请求。往往这种decode请求的数量是远小于token budget的,没有办法均匀的填满4个batch queue。导致流水线并行出现了不均衡。
例如在使用vllm benchmark进行静态请求测试的场景下,一次性发起26个请求,pp=4进行并行。在后期prefill全部完成,这时只剩下26个decode请求等待逐步decode。实际调度时,出现了4、4、4、14调度的情况。这样必然会在1,2,3这3个请求上出现气泡。
方法
prefill阶段节流策略
首先通过总的待prefill的数据量进行节流。其中\(\#MinP,\#MaxP,\#T\)为三个超参数,用于控制上下限token数量以及每次期待处理完所有prefill请求的轮次。\(\#WP\)表示等待进行prefill的token的总数量。\(\#P\)表示本次用于推理的token数量。
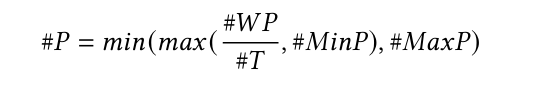
然后根据KVcache的剩余可用显存比例来进行节流。

之前会存在prefill过早抢占decode请求导致重计算(不懂这里为什么会有重计算?)所以设置一个KVcache阈值,当空闲的kvcache显存小于该阈值的时候,就不要再调度prefill请求。本质上这种方法给decode预留了一部分至少的生存空间。

decode
decode阶段相对是比较平稳的,因为需要连续进行多轮的decode,比如在8kin/1kout场景下,decode的时候需要进行1k次自回归的推理,但是prefill很快就完成了。所以decode的节流就直接用所有待处理的token数量除以pp深度。
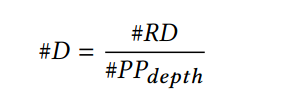
实验
暂时留个坑吧。
思考
我还没来得及去复现测试性能。目前手里只有深信服的同事的复现结果。
gllm的开源代码是基于vllm0.9版本的,后面同事将其移植到0.10上也进行了测试,所以这里讲一下这两个版本的结果。
vllm0.9.1
这里测试的场景是8k-in/350-out,24并发,4rps。
vllm:TTFT均值为2248ms,ITL均值为129ms.
gllm:TTFT均值为2235ms,ITL均值为117ms
vllm0.10.1
这里测试的场景是8k-in/350-out,16并发,2rps。
vllm:TTFT均值为2224ms,ITL均值为96ms。
gllm:TTFT均值为2055ms,ITL均值为102ms。
结论
根据上面的测试结果来看,效果并不好。(而且为什么vllm0.10劣于vllm0.9)。
后面我再自己测试一下更多场景,抓一下流量,将结果更新在这里。