NCCL论文阅读
- NCCL论文阅读
- 前言
- 概述
- NCCL API
- 多GPU管理
- 数据传输
- 通信通道
- 通信层
- 节点内通信
- 节点间通信
- 底层通信协议
- 集合通信算法
- 算法和协议支持
- 通信原语
- 迭代执行模型
- 执行模型对应GPU架构
- 集合通信算法分析
- 总结
前言
NCCL作为当下最为主流的GPU通信库,它的很多系统设计被后续工作(如DeepEP)采纳,NCCL本身也已经成为了行业内的标杆。作为一名网络领域的研究人员,很有必要对NCCL的内部原理进行深入分析和研究。不过,本人尝试过直接阅读NCCL的源码,确实很难以理解,尤其是难以让人对整个NCCL的设计框架有一个完整的概念。好在今年7月份,Nvidia官方发表了一篇分析NCCL的论文,里面对NCCL的设计进行了系统性介绍。基于避重就轻(?)的原则,我们今天就来一起读一下NCCL的这篇论文,学习一下其中关键的设计要点。
注:
- NCCL的这篇论文写的其实非常清晰而且简单,对于追求原汁原味的读者,建议直接阅读原文:Demystifying NCCL: An In-depth Analysis of GPU Communication Protocols and Algorithms。本文主要是对原文的摘抄+翻译+个人理解。有些细节一些地方可能会参考NCCL的官方文档。
- 本文尽量不涉及对NCCL底层代码实现的探讨,在部分地方可能会引用一些具体代码。本文参考了nccl_KIDGINBROOK的博客-CSDN博客。
概述
NCCL API
-
作为一个集合通信库,NCCL的通信操作发生在多个通信成员(communicator)之间。每个communicator对应一个GPU。所有communicator需要先进行初始化并指定其使用的GPU,才能进行通信。
-
NCCL通信成员的初始化分为四种情况:
-
单进程&单线程对应多GPU
这种情况下,单进程只需要使用
ncclCommInitAll就可以初始化所有的GPU,为每个GPU都创建一个communicator,如下面这个例子:ncclComm_t comms[4]; int devs[4] = { 0, 1, 2, 3 }; ncclCommInitAll(comms, 4, devs); -
多进程/线程,每个进程/线程对应一个GPU
这种情况下,所有进程/线程需要先确定一个全局唯一个UniqueId(通过其他方式进行通信,比如MPI),然后分别调用
ncclCommInitRank来初始化各自的GPU。例子如下:ncclUniqueId id; if (myRank == 0) ncclGetUniqueId(&id); MPI_Bcast(&id, sizeof(id), MPI_BYTE, 0, MPI_COMM_WORLD); ncclComm_t comm; ncclCommInitRank(&comm, nRanks, id, myRank); -
多进程/线程,每个进程/线程对应多个GPU
同样地,可以把上面两种情况结合一下。有多个进程/线程,每个进程/线程对应多个communitor(GPU),例子如下。
for (int i=0; i<ngpus; i++) {cudaSetDevice(devs[i]);ncclCommInitRank(comms+i, ngpus*nRanks, id, myRank*ngpus+i); } -
单个GPU多个communicator
最后,也可以让一个GPU对应多个communicator。这些communicator应属于不同的通信组,对应不同的UniqueId。
CUDACHECK(cudaSetDevice(localRank)); for (int i = 0; i < commNum; ++i) {if (myRank == 0) ncclGetUniqueId(&id);MPICHECK(MPI_Bcast((void *)&id, sizeof(id), MPI_BYTE, 0, MPI_COMM_WORLD));NCCLCHECK(ncclCommInitRank(&blockingComms[i], nRanks, id, myRank)); }
-
-
通信操作
NCCL支持多种集合通信操作(collective communication),包括
ncclAllReduce,ncclBroadcast,ncclReduce,ncclAllGather和ncclReduceScatter。NCCL还支持点对点的通信(Point-to-point communication)。至于这些操作的具体含义,以及其他的操作,这里不做赘述,详见官方文档。例子:
ncclAllReduce(sendbuff, recvbuff, count, datatype, op, comm, stream);上述指令会将该操作加入到操作流中,在这之后,可以通过
cudaStreamSynchronize指令来等待任务结束。 -
分组操作
NCCL支持将操作分组从而减少多次调用NCCL的开销。具体做法是用
ncclGroupStart和ncclGroupEnd将多个操作包起来。在执行ncclGroupStart之后,中间的通信操作会被阻塞住;直到ncclGroupEnd被调用时,这些操作才会真正的被执行。
多GPU管理
NCCL提供了3种调用GPU的方式,这三种方式各有优劣:
-
每个进程一个GPU
这种方式的优点是隔离性,便于进程管理。可以根据每个GPU对应的NUMA节点来决定每个进程被调度到哪个CPU上执行。每个进程有独立的地址空间。
-
单进程多线程,每个线程一个GPU
这种方式的优点是便于进程内共享内存,因为进程内的线程地址空间是相同的。这样便于在多个GPU之间进行直接内存访问,从而避免内存拷贝的开销。
-
单线程多个GPU
这种方式的有点是简单,便于开发和调试;缺点是单线程缺少并发性,可能影响效率。
数据传输
注:本段的介绍顺序与NCCL原论文略有不同。本文希望尽可能从一个自顶向下的顺序去讲述整个通信过程。
通信通道
NCCL将通信路径分为多个通道(channel)。每一个channel负责不相交的数据传输,使用独立的硬件资源(包括GPU的流处理器SM和RDMA的QP)。多个channel的使用可以将传输任务平均的分配到多个硬件资源上,有助于提高系统的资源利用率。
对于小消息而言,使用多个channel可能导致每个channel传输的消息过小,从而影响网络的传输效率。因此对于小消息,NCCL会降低使用的channel数量。代码详见enqueue.cc。
在初始化communicator时,NCCL会创建一些初始的channel结构。在执行集合通信操作时,NCCL会根据操作算法、大小、网络带宽等信息自动决定每个操作使用多少个channel。
对于ncclGroupStart和ncclGroupEnd之间的操作,NCCL会尽可能将操作分配到不同的channel上,从而提高操作间的并行性。
通信层
NCCL将通信分为节点内通信(intra-node)和节点间通信(inter-node)两种情况。每种情况有不同的传输策略。这些情况的特点如下图所示:

节点内通信

上图展示了NCCL的节点内通信策略。NCCL的节点内通信主要使用了NVIDIA的GPUDirect Peer-to-Peer (P2P)技术,允许GPU之间直接访问内存,无需CPU参与。
-
当GPU之间通过NVLink互联时,NCCL实现基于NVLink的GPUDirect P2P通信。当没有NVLink时,NCCL实现基于PCIe的GPUDirect P2P通信,这种方式依然要优于基于CPU的
cudaMemcpy。 -
当多个communicator属于同一个进程时,NCCL额外支持一种
P2P_DIRECT的优化。由于进程内的地址空间相同,GPU之间无需使用进程间通信(IPC)的结构。另外,GPU之间通信也无需经过一个中间的缓冲(图中的intermediate FIFO buffer),而是可以使用directSend和directRecv直接将数据从sendBuff传输到recvBuff。注意:GPUDirect P2P和
P2P_DIRECT这两个名字有点像,但实际上是不同的东西。GPUDirect P2P是GPU的功能,核心在于绕过CPU;而P2P_DIRECT指直接访问地址空间,从而实现零拷贝。P2P_DIRECT是基于GPUDirect P2P之上的。 -
当GPU不支持GPUDirect P2P时,NCCL还支持通过主机共享内存(Shared Memory,SHM)的通信。在SHM模式下,一个GPU的控制进程(CPU)负责将数据写入到一块共享的内存区域,而另一个GPU的控制进程负责从共享区域读入数据。
-
最后,NCCL还支持使用网卡(NIC)进行节点内GPU之间的数据传输。这种方式可以更充分的利用PCIe带宽,避免CPU成为瓶颈。前提是网卡支持GPUDirect RDMA。
节点间通信

上图展示了NCCL的节点间通信。NCCL主要支持两种节点间通信模式:使用TCP socker或者Infiniband (IB) verbs。
-
若网络不支持RDMA,NCCL使用TCP socket通信。在这种模式下,intermediate buffer位于主机内存中(CUDA pinned host memory)。发送端CPU将数据从GPU拷贝到主机上的buffer,再用socket发到接收端的buffer中。接收端收到数据后将其拷贝到GPU。使用主机内存会导致PCIe开销。发送端和接收端遵循一个rendezvous protocol,即它们需要先实现同步确定intermediate buffer中有足够的空间,然后才会进行实际的数据传输。
-
若网络支持RDMA(Infiniband或RoCE),NCCL会使用IB进行通信。与TCP socket相同的是,IB依然要使用intermediate buffer进行数据传输,但buffer的位置取决于硬件因素。
若网卡无法直接访问GPU内存,则intermediate buffer位于主机内存中。发送端GPU将数据拷贝到这块内存中,然后CPU的一个代理线程(proxy thread,每个rank一个proxy thread)发起RDMA write请求将数据发送到远端节点中。在接收端,代理线程将数据从主机内存拷贝到GPU内存中。
若网卡支持GPUDirect RDMA,则intermediate buffer位于GPU内存中。网卡直接从GPU中读写数据,从而避免了对主机内存的访问。
注:到目前为止,NCCL尚不支持GPU直接发起RDMA请求(GDA)。因此依然需要使用CPU代理线程发起RDMA请求。
-
一个communicator对每个远端节点和远端网卡建立多个channel(就是上文里的那个channel,默认为``p2pnChannels`=2个,详见paths.cc),负责这个与这个远端网卡对应的所有GPU进行通信,每个channel维护独立的QP。在创建任务时,数据被分块给不同的channel,一起被放入proxy的任务列表中。在执行任务时,proxy轮训这些来自不同channel的任务。这种多channel的连接可以提升多QP的并发性,提高网络利用率。
-
在一个channel中,一个communicator对每个远端的rank(GPU)都建立两个RDMA RC QP。
-
一个正向的QP负责发送数据。proxy会发起一个或多个RDMA_WRITE请求将数据写入到对端。对于每一块(对应后文的chunk)数据的最后一个请求,proxy发送RDMA_WRITE_WITH_IMM用于通知发送结束。详见ncclIbIsend。
-
一个反向的QP用于接受“clear-to-send”(CTS)消息。该消息携带远端的buffer地址、rkey、以及fifo队尾指针等信息,用于告知发送端:远端可以接受数据了。
具体地,在RDMA建链时,发送端会将本地的一个fifo队列的内存地址告知接收端。接收端在post recv之后,用RDMA_WRITE向发送端的fifo数组中用写入CTS消息。详见ncclIbPostFifo。
两个QP有助于将控制消息和数据消息隔离开,降低控制消息的head-of-line延迟。
-
-
特别地,在GPUDirect RDMA下,每次接收端recv接收数据时,都需要执行一下flush操作。这是因为当网卡产生CQE到CPU时,数据不一定已经写入到GPU。具体地,在CPU轮训CQ,收到之前所有post recv的CQE后(调用ncclIbTest),会向一个特殊的本地loopback QP发起一个RDMA_READ请求(调用ncclIbFlush)。这个READ请求的完成标志着之前所有的PCIe WRITE都已经完成,这样就保证了数据已经到达GPU。详见recvProxyProgress。
-
-
虽然论文中没有提及,但现版本的NCCL是支持零拷贝(zero-copy)的。即不使用intermediate buffer,直接将数据写入到远端GPU的output buffer中。详见User Buffer Registration。
底层通信协议
NCCL支持三种通信协议:Simple, LL (low latency)和LL128。下表展示了三者各自的特点。

-
Simple
Simple协议适用于大消息,用于最大化带宽利用率。上文提到的数据切块,flush就是针对simple协议的。
-
LL
LL适用于小消息,用于优化延迟而非带宽利用率。LL的每个消息是一个8-byte的RDMA ATOMIC,包含4-byte的数据和4-byte的flag。LL的intermediate buffer必须位于主机内存,CPU轮训flag从而得知数据是否传输完成。(因为CPU轮训GPU内存非常慢,所以用主机内存。)
-
LL128
LL128在带宽利用率和延迟之间进行了trade-off。LL128发送128-byte的RDMA WRITE,包括120-byte的数据和8-byte的flag,使得带宽利用率约为95%。在发送数据时,LL128依旧仿照Simple对一整块的数据进行发送。
LL128在NVLink上表现良好。不过LL128依赖于传输设备支持128-byte的原子写,可能不适用于某些PCIe设备。
集合通信算法
集合通信算法是NCCL的核心。NCCL将每个集合通信算法拆分为若干个底层的通信原语,并分配到多个并行的channel上。算法的选择取决于网络拓扑(ring或者tree)。
算法和协议支持
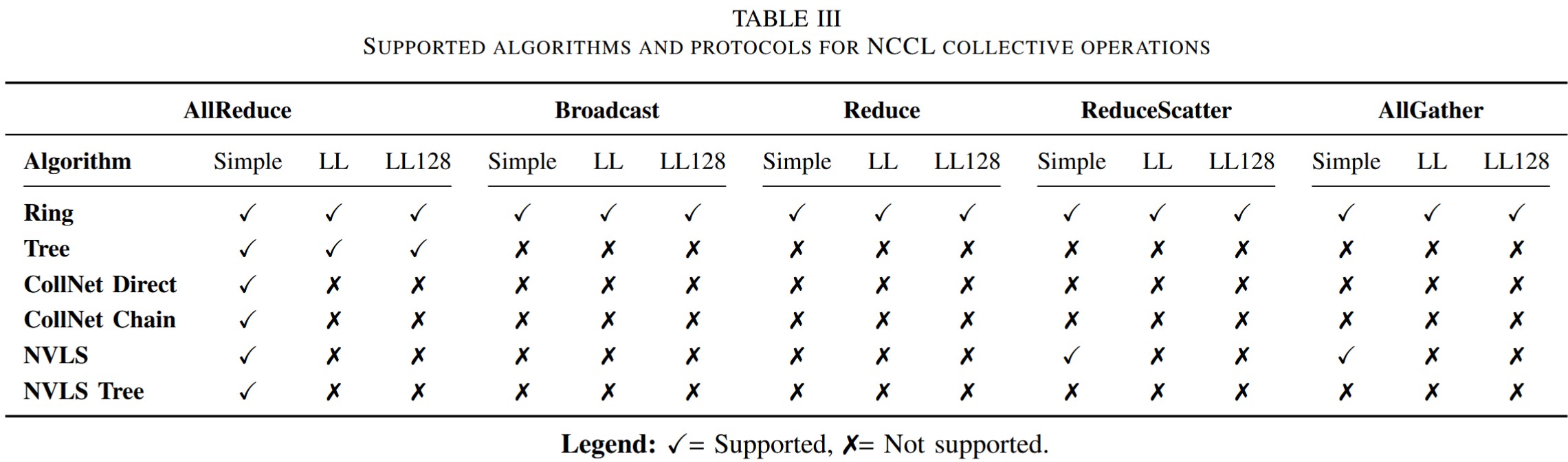
上图展示了NCCL的不同算法和协议之间的支持关系。其中CollNet需要网络交换机支持在网计算(如NVIDIA SHARP),NVLS需要NVLink Switch(NVSwitch)。本文不涉及CollNet和NVLS的具体实现。
通信原语
NCCL将上层的通信算法拆分为底层的通信原语(primitives)。常见的原语包括send, recv, recvReduceSend, recvCopySend, recvReduceCopySend,以及它们的direct版本(对应前文提到的P2P_DIRECT)。这些原语的意义跟它们的名字相同。例如,recvReduceCopySend表示GPU先从上一个远端GPU接受数据,将数据与本地的数据进行reduce,再将结果拷贝到输出buffer中,最后发送给下一个远端GPU。
迭代执行模型
NCCL对数据进行不同层次的分块,用于不同粒度的并行。
-
NCCL将数据切分为若干连续的段,分配给不同的channel,不同channel并行处理数据。
-
每一个channel有一个固定大小的buffer。若一个channel的数据长度超过了它的buffer大小,则将数据切分为多个外层循环(outer loop iteration),每个iteration处理一个buffer的数据。channel迭代执行每个iteration。
-
channel的buffer被分为多个slot(通常为
NCCL_STEP=8个)。在每个iteration中,数据被切分为多干个chunk,每个chunk对应buffer的一个slot(chunk循环使用这些slot)。每个slot/chunk独立的执行原语的不同阶段(比如recv+reduce+send)。多个chunk的好处是可以保证通信始终处于繁忙状态,提升通信带宽的利用率。 -
NCCL的最基本数据单元成为element。对于不含计算的操作(如
ncclAllGather和ncclBroadcast),每个element是一个byte。对于含计算的操作(如ncclAllReduce,ncclReduceScatter,ncclReduce),每个element是一个用户指定的数据类型(如float)。
下图展示了NCCL中的数据切分方案。

执行模型对应GPU架构
接下来,我们看一下上面的执行模型是如何与GPU架构对应的。
-
Grid和Block结构
一个NCCL kernel在启动时的grid维度为
(nChannels, 1, 1),即每个CUDA block对应一个channel。在每个block内部,NCCL使用动态数量的threads。这个数量由NCCL自动调节。 -
channel与block ID的关系
在启动kernel时,NCCL会对每个kernel传入一个
channelMask,代表这个kernel使用的所有channel编号。一个blockIdx.x的block对应的channel编号就是channelMask中第blockIdx.x个为1的位。 -
warp组织
NCCL为每个warp分配不同的工作。前两个warp负责初始化:warp 0负责加载communicator metadata到GPU共享内存,而warp 1负责加载每个channel负责的数据。其余的warp负责真正的计算和通信任务。
不同集合通信操作的warp分工不同。例如,对于端到端通信,warp被分为send和receive两个阶段,它们的数量会根据实际传输的数据进行动态调节。
-
基于slot的流水线模型
前面提到,每个channel包含
NCCL_STEPS个slot,形成流水线结构。一个warp中的threads会轮流使用这些slot进行数据传输。每个slot包含一个fifo结构,标记着当前slot的运行状态,包括当前的数据指针等。不同的slot可以同时位于流水线的不同阶段:正在计算,等待传输,正在传输,传输完成等。 -
thread级别数据搬运
在最细的粒度,NCCL将数据分配给每个warp内的不同threads。一个warp中的threads同时处理不同的数据element。例如,一个warp中的thread同时处理一连串相同的操作(send, reduce, copy),只不过处理不同的data element或者内存地址。这符合GPU的SIMT架构。
-
多个并发的流水线
NCCL的多个channel并行运行在多个SM上,每个channel内的slot运行在原语的不同阶段上,每个warp负责执行不同阶段的通信计算任务。这种多层次的流水线可以最大化带宽利用率。
集合通信算法分析
在了解了NCCL的执行模型后,我们可以来看NCCL的集合通信算法了。我们会分析每个上层的通信算法是如何被拆分为底层原语,并运行在上面的执行模型上的。
前面提到,NCCL的任务分为多个iteration。根据不同的iteration能否流水线执行,NCCL的算法可以分为两种:流水线(pipelined)和非流水线(non-pipelined)。
-
非流水线算法
在非流水线算法中,每个GPU需要完全执行一个iteration中的所有操作后才能开始执行下一个iteration。非流水线算法包括Ring AllReduce, Ring AllGather和Ring ReduceScatter。在下面的分析中,用\(k\)表示参与集合通信的GPU数量。在Ring拓扑中,这\(k\)个GPU形成一个环形结构。
-
Ring AllReduce

NCCL的Ring AllReduce对所有\(k\)个GPU上的数据进行聚合,并将完整的结果交给所有GPU。上图展示了Ring AllReduce的大致流程,包括一个类似ReduceScatter的过程和一个类似AllGather的过程。在每个iteration中,Ring AllReduce的流程包含\(2k-1\)步(step),如下图所示。

在第0步,所有GPU发送自己的一块数据
send给自己的下一个邻。在接下来的\(k-2\)步,所有GPU执行recvReduceSend,从上一个邻居接受数据,与本地的数据进行聚合,并将结果发给下一个邻居。在第\(k-1\)步,所有GPU使用recvReduceCopySend收到一块数据,与本地数据聚合,这样就得到了最终的一块数据结果,然后将该结果拷贝到output buffer中,最后把这块数据发给下一个邻居。在接下来\(k-2\)步,所有GPU使用recvCopySend从上一个邻居获取一块聚合好的结果,拷贝到output buffer中,并将其发给下一个邻居。在最后一步,每个GPU只需要进行recv收到最后一块结果。 -
Ring AllGather

NCCL的Ring AllGather使\(k\)个GPU都获得它们全部的数据。其流程分为\(k\)步。在第0步,所有GPU先将自己的数据拷贝到output buffer中,并发送给下一个邻居。若是in-place操作,则无需进行拷贝。在接下来\(k-2\)步,每个GPU用
recvCopySend从上一个邻居接受数据,拷贝到output buffer中,并发送给下一个邻居;在最后一步,每个GPU用recv接收最后一块数据。 -
Ring ReduceScatter
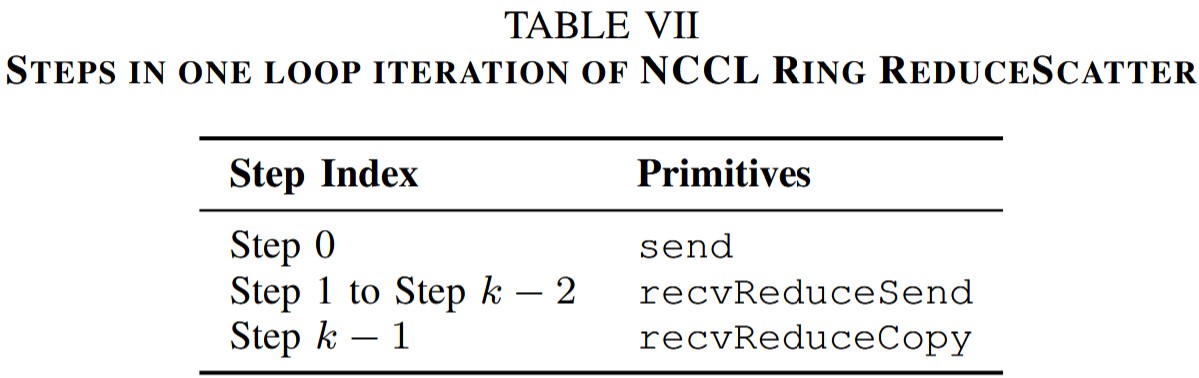
在Ring ReduceScatter开始之前,所有GPU的send buffer包含\(k\)块独立的数据。ReduceScatter对这些数据进行聚合,并将结果分发给不同GPU。其流程分为\(k\)步。在第0步,所有GPU发送一块本地数据给下一个邻居。在接下来\(k-2\)步,所有GPU用
recvReduceSend从上一个邻居接受数据,与本地数据进行聚合,并发给下一个邻居;在最后一步,所有GPU用recvReduceCopy从上一个邻居接受数据,与本地数据进行聚合,并拷贝到output buffer。
特别注意,虽然Ring AllReduce的流程大致上和Ring ReduceScatter+Ring AllGather很像,但它们内部并不相同。一方面,Ring AllReduce将其中的原语进行了合并,可以实现更好的流水线。另一方面,Ring AllReduce和Ring ReduceScatter与Ring AllGather内部的数据排布并不相同。以上面的Fig.4为例。在Ring AllReduce中,若数据被划分为若干个连续的段,分配给不同的channel。假设Ring ReduceScatter也采用同样的排布,则在右上角的ReduceScatter结果中,每个channel都是图中的排布情况。这与ReduceScatter的语义不符:在ReduceScatter中,第\(i\)个GPU应该得到全局的第\(i\)块数据,而不是每一个channel内部的第\(i\)块数据。不过,我还没弄清楚NCCL的Ring ReduceScatter是如何保证数据排布的正确性的。这个留待以后探究,如果有知道的读着欢迎与我讨论。
-
-
流水线算法
在流水线算法中,不同iteration中的steps可以同时进行。流水线算法包含Tree AllReduce, Ring Broadcast和Ring Reduce。
-
Tree AllReduce

上图左下角展示了一个4个节点的tree拓扑。需要注意的是这里的分支只存在于节点之间。节点内的GPU是形成一条链的结构。Tree AllReduce的每个iteration大致分为两个阶段:Reduce和Broadcast。
在NCCL的一种基于Tree的实现方案中,这两个阶段可以同时进行。具体而言,NCCL将SM分为两组,一组负责从叶子到根的Reduce,另一组负责从根到叶子的Broadcast。由于Reduce相比Broadcast更复杂一些,所以可以给Reduce阶段分配更多的threads。

首先,所有叶子GPU将自己的数据
send给父节点。中间的GPU用recvReduceSend从子节点接收数据,与本地数据进行reduce,并发给父节点。根GPU用recvReduceCopySend得到最终结果,并发给子节点。然后中间GPU用recvCopySend接收结果并发给自己的子节点。叶子GPU用recv接收结果。在上述Tree AllReduce算法中,由于Reduce和Broadcast阶段可以流水线执行,每个节点的收发带宽都可以充分利用。但对于一般的Tree Reduce或者Tree Broadcast而言,Tree的拓扑会导致叶子节点只有发送或者接受的流量,导致带宽浪费。为了解决这个问题,NCCL采用了double binary tree (DBT)的拓扑。如下图所示:

在普通binary tree基础上,DBT创建了第二棵树。若节点数目为奇数,则第二棵树可以通过将第一棵树向左移动一位得到。若节点数目为偶数,则第二棵树可以是第一棵树的镜像。在DBT中,没有一个节点在两棵树中都是非叶子节点,至多一个节点在两棵树中都是叶子节点。
以基于DBT的Broadcast算法为例。NCCL将数据分为两部分,交给不同的树,对应不同的channel,每个channel处理其中的一棵树。在每一时刻,中间节点把数据用
recvCopySend从父节点接收数据并下发给子节点。图中的红色表示当前时刻正在发生数据传输的路径。 -
Ring Broadcast

NCCL的Ring Broadcast以一个链的形状对数据进行广播。根节点用
send(对于in-place操作)或者copySend发送数据,中间节点用recvCopySend进行传递,最后的节点用recv接收数据。 -
Ring Reduce
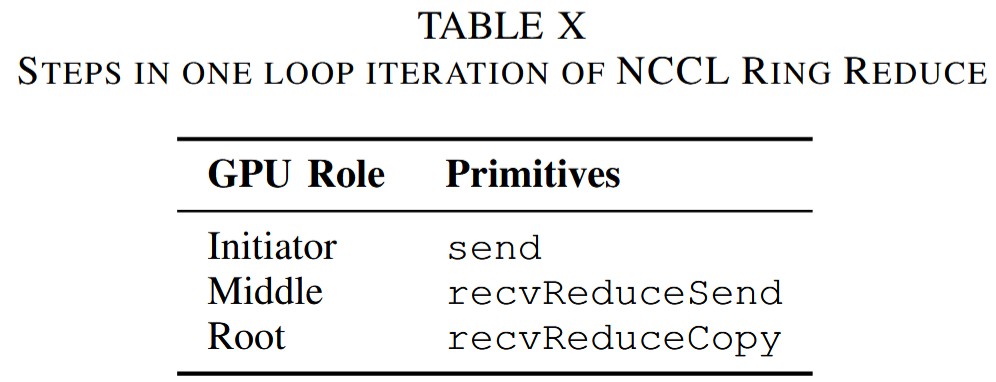
NCCL的Ring Reduce与Broadcast基本相反,以一个链的形状将数据聚合到根节点。
-
总结
本文从一个比较上层的角度分析了NCCL的整体设计,包括其API、传输层协议、对GPU架构的利用、以及简略的通信算法。其中的很多设计都是被后续工作所使用的。比如DeepEP也沿用了其channel的结构,以及GPU内部warp的分工等。当然,NCCL的有些设计也被后人诟病,比如proxy的使用可能导致CPU成为瓶颈,未来可能会被GDA技术取代。本文也有很多细节部分没有提及,比如NCCL如何识别并构建网络拓扑,以及primitive内部如何实现等等。总的来说,本文很好的展示了如何设计一个GPU通信库以充分利用GPU资源。这对于未来基于NCCL进行开发或者设计新的通信库还是很有借鉴意义的。