文章目录
- 一、为什么 Redis 把 “64 字节” 作为字符串分界线
- 1.1 Redis 字符串底层是 SDS
- 1.2 SDS 的头部开销
- 1.3 柔性数组
- 1.4 redisObject 的内存占用
- 1.5 embstr 与 raw 两种编码
- 1.6 为什么阈值是 44 字节?
- 二、Redis 跳表
- 2.1 什么是跳表
- 1.2 为什么需要跳表
- 1.3 随机层数
- 1.4 Redis 中跳表的具体实现特点
- 1.5 跳表在 Redis 有序集合(Zset)中的应用
一、为什么 Redis 把 “64 字节” 作为字符串分界线
面试参考回答:
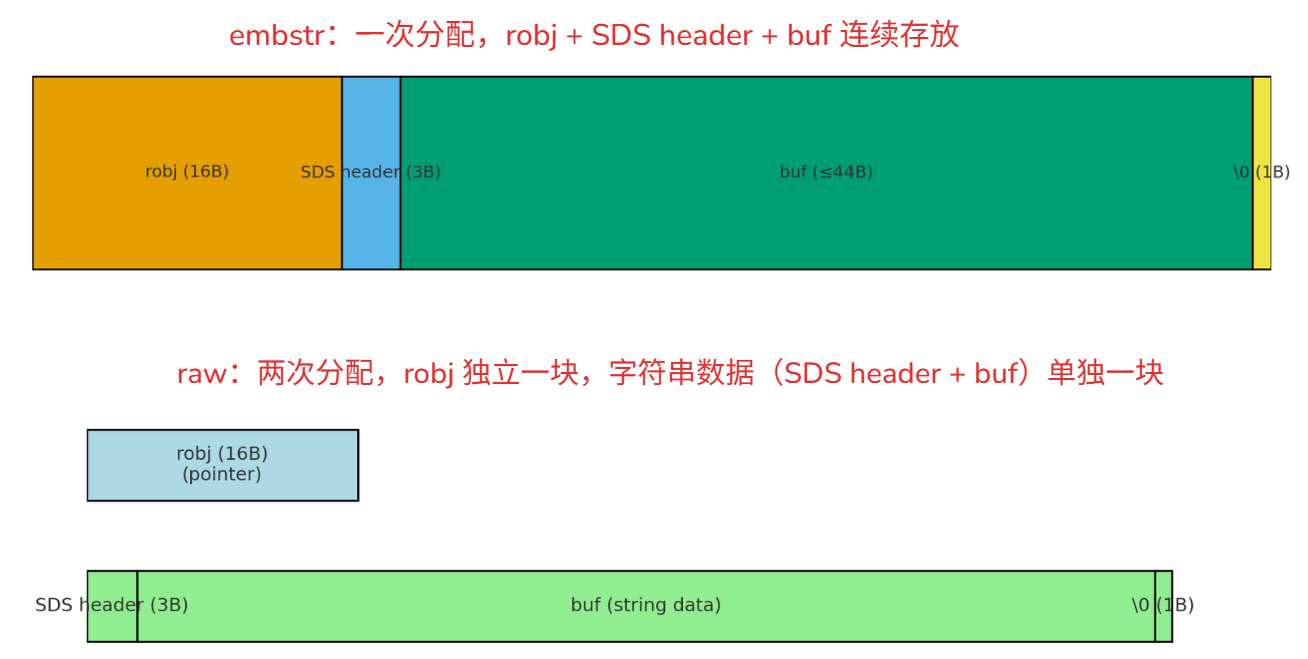
Redis 在处理字符串时,区分了 embstr 和 raw 两种编码。embstr 就是
embedded string(嵌入字符串),它把robj、字符串数据 SDS 头和字符串内容,放在同一块内存里,一次性分配。相比之下,raw 方式下robj只维护一个指针,实际的字符串数据在堆上另行分配。对于短字符串,Redis 采用 embstr 可以减少一次 malloc/free,避免指针跳转,访问效率更高。为什么选 64 字节 作为边界?这是因为常见的内存分配器都会按 2 的幂次分配小块内存,64B 是一个典型的分配粒度。同时,现代 CPU 缓存行的最小访问单位通常也是 64B。把
robj和字符串内容打包在 64B 内,可以让对象元数据和字符串落在同一缓存行里,提升缓存命中率和访问局部性。为什么阈值是 44 字节?在 64B 里,
robj占 16B,SDS 头占 3B,结尾\0占 1B,剩下 44B 可用于存放字符串内容。因此,Redis 把 44 字节作为 embstr 与 raw 的分界线。短字符串用 embstr,性能和空间利用率最好;超过 44B 时,就用 raw,把字符串单独放在堆上,更灵活。
1.1 Redis 字符串底层是 SDS
在 Redis 中,字符串不是用传统的 char* 来管理,而是用 SDS(Simple Dynamic String)。
SDS 的核心特点是用“长度信息”而不是 \0 来描述字符串,这样就支持二进制安全的字符串,像图片、视频、字节流等都可以存放,不会因为遇到 \0 而被截断。同时,SDS 在字符串结尾依然保留一个 \0,这样也能兼容 C 标准库的字符串函数。
1.2 SDS 的头部开销
SDS 有不同的头部类型(如 sdshdr5/8/16/32/64),根据字符串长度不同选择合适的头部,以节省空间。
短字符串常用 sdshdr8,它的结构大致如下(packed 后不会有额外填充):
struct __attribute__((__packed__)) sdshdr8 {
uint8_t len;
// 已用长度,1 字节
uint8_t alloc;
// 总分配大小(不含 header 和 '\0'),1 字节
unsigned char flags;
// 标志(1 字节)
char buf[];
// 字符数据(后面紧接)
};这个头部占用 3 个字节(len + alloc + flags = 3),紧随其后的 buf[] 用来放实际字符。这里 buf[]是柔性数组,柔性数组 buf[] 不占用结构体本身空间,真正的大小要靠 malloc 分配。
1.3 柔性数组
柔性数组(Flexible Array Member,简称 FAM)必须定义在结构体中,并且必须放在结构体的最后一个成员。结构体不能只包含柔性数组,必须至少有一个普通成员,否则编译器会报错。
sizeof(结构体)不包含柔性数组的大小,仅仅计算到柔性数组前为止。- 在上例中,
sizeof(struct sdshdr8)只包含len + alloc + flags的大小,不包括buf[]。 - 柔性数组成员只是个“占位符”,本身不占空间。
如果要使用柔性数组,需要额外分配一段内存:
// 分配一个带 128 字节 buf 的 sdshdr8
struct sdshdr8 *sh = malloc(sizeof(struct sdshdr8) + 128);sizeof(struct sdshdr8):是结构体本身大小,不包括buf[]。+128:给柔性数组buf[]分配 128 字节空间。- 此时
sh->buf就可以直接使用了。
取出数据有两种常见方式:
1. 直接用结构体指针访问
sh->buf[0] = 'A';因为 buf[] 的起始地址已经包含在 sh 里面。
2. 如果先拿到 char *,再取结构体
比如 Redis 的 sds 实现:
char *sds = (char*)sh->buf;
// 用户只看到字符串部分那么要取回 struct sdshdr8,需要回退
struct sdshdr8 *sh = (void*)(sds - sizeof(struct sdshdr8));如果结构体中使用 char *buf 指针成员而不是柔性数组 buf[],那么在申请内存时需要先为结构体本身分配一次,再为指针指向的缓冲区分配一次,释放时也要对应执行两次 free,这样既繁琐又容易造成内存碎片;而如果使用柔性数组 char buf[],则只需一次 malloc 就能同时为结构体和数组申请连续内存空间,并且只需一次 free 即可释放,效率更高,内存管理更简单。
1.4 redisObject 的内存占用
Redis 中的字符串对象需要一个 redisObject(简称 robj)来描述。 在典型的 64 位环境下,robj 大约占 16 字节,主要字段有:
typedef struct redisObject {
unsigned type:4;
// 位域:type, encoding, lru 等合起来通常占 4 字节
unsigned encoding:4;
unsigned lru:24;
// 假设合并为 4 字节总和
int refcount;
// 4 字节
void *ptr;
// 64-bit 系统为 8 字节
} robj;
// 合计:4 + 4 + 8 = 16 字节(在典型 64-bit 编译器布局下)1.5 embstr 与 raw 两种编码
Redis 为了存储字符串,提供了两种方式:
- embstr:把
robj、SDS header 和字符串内容一次性分配到同一块连续内存。这样只需一次 malloc,减少指针跳转,性能更好。 - raw:
robj本身只保存一个指针,字符串内容单独在堆上分配。适合大字符串,因为可以灵活扩展。
区别在于:短字符串用 embstr,更高效;长字符串用 raw,更灵活。
对于短字符串,embstr 可以减少一次内存分配、减少指针跳转、提升缓存局部性与性能;但当字符串比较大时,把数据也放在 robj 所在的那块内存会使得一次分配变得很大且可能浪费内存/改变分配器行为,因此超过阈值 44 字节就改用 raw。
1.6 为什么阈值是 44 字节?
现代 CPU 的缓存行大小通常是 64 字节,把 robj + SDS header + 字符串内容 + 结尾 \0 全部放在 64 字节内。

逐步计算:
- 缓存行大小:64 字节
- 减去
robj16B:64 − 16 = 48 - 减去 SDS 头 3B:48 − 3 = 45
- 再减去结尾
\0为 1B:45 − 1 = 44
所以,实际能存放的字符串长度是 44 字节。
因此,Redis 规定:字符串长度 ≤44 时,用 embstr;超过时用 raw。
虽然 SDS 用 len 表示字符串长度,但它仍在末尾保留一个 \0,方便和 C 库函数兼容。
这个 \0 会占用一个字节,所以要在计算时专门减掉。
二、Redis 跳表
Redis 的有序集合需要既能快速按分数排序,又能高效插入删除。普通链表或数组都有缺陷,B+树实现复杂,所以 Redis 选择了跳表。跳表通过“多层级的有序链表”加速查找,查找、插入、删除的期望复杂度都是
O(log n),实现比树简单。
Redis 使用概率方式决定节点的层数,不需要频繁重建结构,还把最高层数限制为 32。
在 zset 里,小数据用紧凑编码节省内存,大数据用“跳表+哈希表”组合:哈希表用于按成员名快速查找,跳表用于按分数排序和范围查询。
2.1 什么是跳表
跳表可以理解为一种对传统链表进行优化的数据结构,它通过建立多级“索引”或“快速通道”来加速查找过程。用空间换时间:通过上层稀疏索引快速跨越大量节点,再逐层下降到更精细的层次,最终在底层链表完成精确定位。
一个理想化的例子:
假设一个有序链表存储着数据 1, 3, 7, 9, 12, 17。如果我们要查找数字 9,在普通链表中只能从头开始逐个比较,需要 4 次。而在一个理想的多层级跳表中,查找路径可能是这样的:
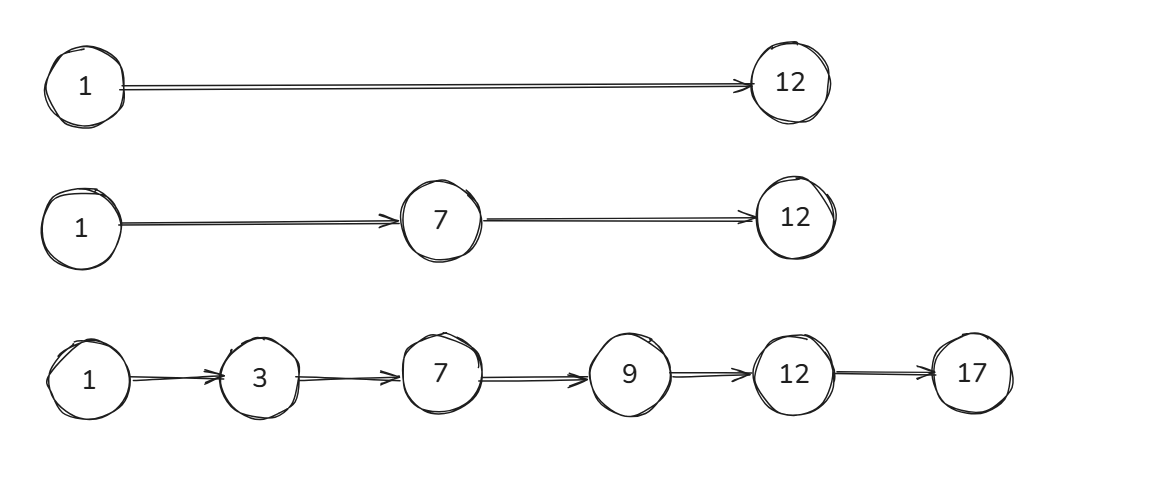
- 第一层(最稀疏的索引层):我们发现 9 在节点 1 和节点 12 之间。
- 下降到第二层:在节点 1 和节点 12 之间的第二层,我们发现 9 不在节点 1 和节点 7 之间,所以不下降。
- 在第二层继续:从节点 7 开始,发现 9 在节点 7 和节点 12 之间,于是下降到最底层。
- 最底层(原始数据层):从节点 7 开始向后查找,很快就在下一个节点找到了 9。
这种查找方式比单链表高效很多,因为减少了遍历步数。
1.2 为什么需要跳表
Redis 使用跳表主要是为了其有序集合(Sorted Set / Zset) 的实现。Zset 需要支持两种核心操作:
- 范围查询:快速获取指定分数区间的成员,例如
ZRANGEBYSCORE。 - 高效更新:能够快速地进行插入、删除和修改。
传统的数据结构在面对这些需求时有明显短板:
- 有序数组:查找快(二分查找,O(log n)),但插入和删除需要移动大量元素,非常慢(O(n))。
- 普通有序链表:插入和删除快(O(1)),但查找效率极低(O(n)),因为只能从头到尾遍历。
跳表则是在链表的基础上,通过增加多级索引,以空间换时间,实现了接近二分查找的效率,同时保留了链表插入删除灵活的优点。
1.3 随机层数
上文设想的理想跳表结构(比如严格每两个节点建立一个索引)在理论上很高效。但在现实中,每次插入或删除一个节点,都可能破坏原有完美的索引层级关系,如果需要重新构建整个索引结构,成本将非常高,使得更新操作变得很慢。
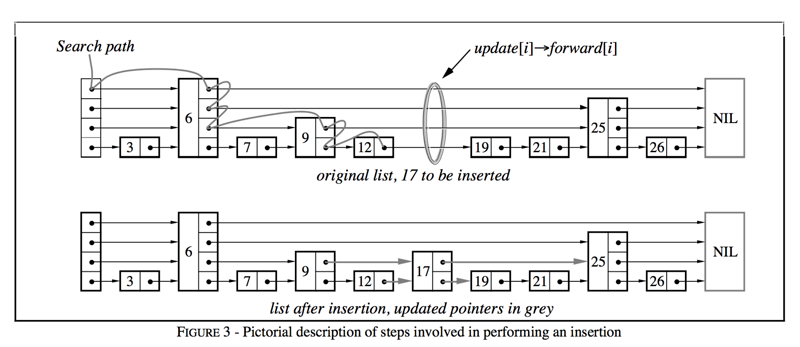
为了避免维护理想结构的高昂代价,Redis 和大多数跳表实现采用了一种巧妙的概率化方法来决定每个新插入节点的层级:
- 每个新节点在插入时,会通过一个随机算法生成一个层数(level)。
- 这个随机算法通常保证:
- 约有 50% 的概率节点只有 1 层(即只存在于最底层链表)。
- 约有 25% 的概率节点有 2 层。
- 约有 12.5% 的概率节点有 3 层。
- 以此类推…
这种方式虽然使得跳表在局部上不是最完美的形态,但从统计学的宏观角度来看,其结构性能依然非常接近理想跳表。最大的好处是插入和删除操作变得非常简单高效,只需要调整相邻节点指针,而无需重构整个索引。
1.4 Redis 中跳表的具体实现特点
Redis 对跳表的实现进行了一些工程上的优化:
最大层级限制:Redis 将跳表的最大层级限制为 32。即使随机算法理论上可能生成很高的层数,这个限制也能防止在极端情况下消耗过多内存。
内存与性能的平衡:通过调整随机算法的参数,Redis 让跳表的整体结构相对“扁平”一些,平均层数较低。虽然查找性能略有牺牲,但显著节约了内存使用,整体上更适合内存数据库的需求。
1.5 跳表在 Redis 有序集合(Zset)中的应用
Zset 会根据元素数量和成员字符串长度智能选择更节省内存的底层表示,从而在内存占用和操作效率之间做出平衡。Redis 的有序集合有两种底层实现:
- 紧凑编码(listpack/ziplist):数据量少、字符串短时,用它节省内存。
- 跳表 + 哈希表:数据量大时使用。
切换条件是:
- 当元素数量较少(默认 ≤ 128)且所有成员字符串长度较短(默认 ≤ 64 字节)时,使用更紧凑的 listpack(新版)或 ziplist(旧版)结构存储。
- 元素个数 > 128,或者有一个成员字符串长度 > 64 内部结构会自动转换为 “跳表(Skiplist) + 字典(Hash Table)” 的组合。
跳表 + 字典的组合,结合了两种数据结构的优势,既能快速定位成员,又能支持排序和范围操作。:
- 字典(哈希表):用来快速按成员名查找对应的分数,复杂度
O(1)。 - 跳表:用来按照分数排序、做范围查询,复杂度
O(log n)。