一、第一页
1、现有的轻量级模型主要通过 自注意力机制 和 卷积 来进行 token混合,阻碍了 感知 和 聚集 过程的高效性。
2、感知 对token之间的上下文关系进行建模,聚合 则基于对应关系集成token特征。
3、自注意力机制 通过整体特征交互作用得到全局知觉,通过所有特征加权和得到全局聚合。卷积 使用token之间的相对位置关系进行感知,并使用 静态核权重 聚集特征。
4、发现问题: 自注意力机制 缺乏重大相互联系的区域的过度关注,反而在不重要的背景下有着一样多的计算复杂性。 卷积 因为用的是 静态核权重,导致对不同上下文邻域缺乏敏感性。
二、第二页
1、人类视觉系统。“视杆细胞” 首先通过外围视觉大视场感知,捕捉广泛概貌,即“看大”,然后“视锥细胞”注意力可以指向场景的特定元素,进行小视场聚焦,即“看小”。应用于感知和聚合。
2、LS卷积 用于大场感知的大核静态卷积和用于小场聚集的小核动态卷积。首先利用大核深度卷积捕获广泛的上下文信息来建模空间关系,然后在此基础上,构造了一种具有分组机制的小核动态卷积运算。
三、第三页
1、相关工作。其他人对轻量级模型做出的努力。
2、自注意力机制 和 卷积 感知和聚合 的原理。
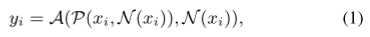
P表示感知,涉及提取上下文信息和捕捉标记之间的关系。A表示聚集,基于感知的结果整合特征,并使得能够合并来自其他标记的信息(第二个N(xi))。
3、自注意力机制 token mixing 的原理。
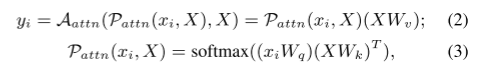
xi是 each token,Wq、Wk、Wv是投影矩阵。感知P通过Softmax归一化得到注意力得分,聚合A通过 注意力得分(感知P)对X的特征进行加权得到yi。
4、卷积 token mixing 的原理。
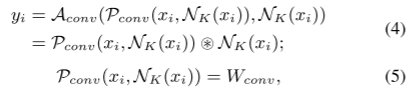
对于核大小为K的卷积,上下文域 就是 以xi为中心大小为K×K的邻域。每个xj∈Nk的聚集权重就是 静态卷积核 Wconv中对应位置处的值。
四、第四页
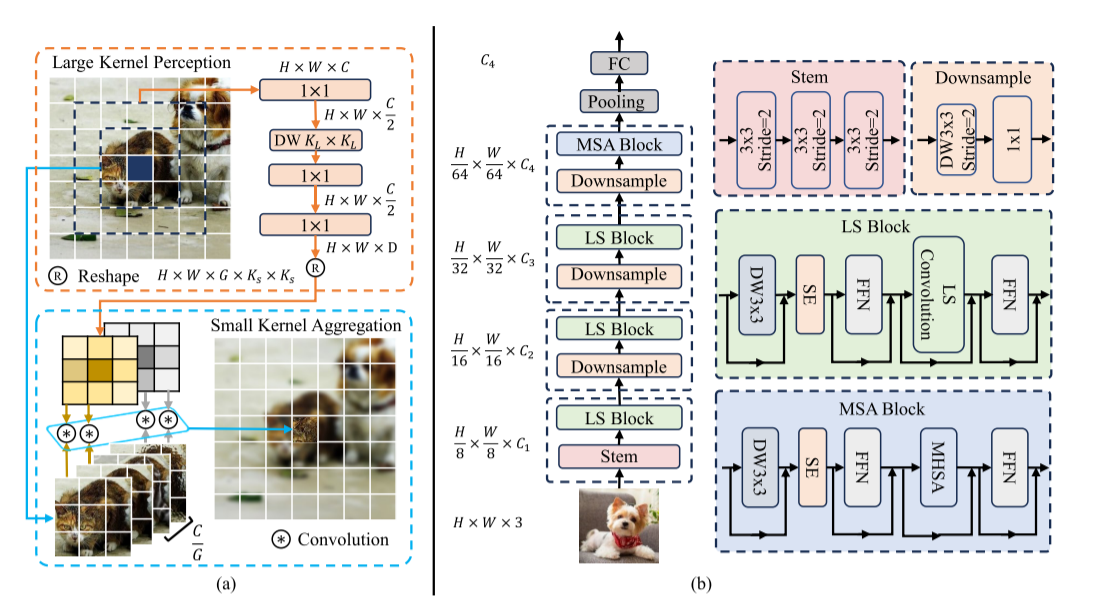
1、大核感知(LKP)
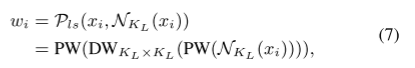
先用PW(1×1卷积)将token降低到二分之C维度,以降低计算成本;然后用DW(深度卷积)来有效捕捉上面计算结果的大场空间上下文信息;然后再用PW(1×1卷积)对上面得到的上下文信息进行建模,也就是为聚集步骤生成 上下文自适应权重Wi。
2、小核聚合(SKA)
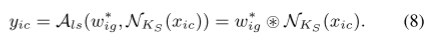
将其通道分为G组,每一组C/G个通道共享聚合权重,以减少计算成本;对于每个xi,我们reshape由大核感知得到的wi得到wi(Ks是小核尺寸);然后我们用wi来聚合xi的上下文N(卷积运算)。
公式里:xi的第c个通道表示为xic,属于第g个通道组。
3、复杂度分析。
五、第五页
分析了模型图。
FFN:前馈神经网络用于channel mixing。FFN通过两层线性变换和激活函数,将注意力机制的输出从高维压缩到更高维(扩展特征空间),再整合回原维度(特征聚合)。例如,将输入向量从512维升至2048维,再降回512维,从而捕捉更复杂的语义关联。
Downsample:一个3×3+步幅2的深度卷积和1×1的卷积,降低空间分辨率和调制信道维度。
MSA:三轮的LS Block后,加入了一个MSA Block,用于捕捉由于分辨率较小而导致的长距离依赖关系(61、80)。MSA里有MHSA(多头自注意)。
DW3×3和SE(34)的作用:引入更多局部结构信息。
六、第六页
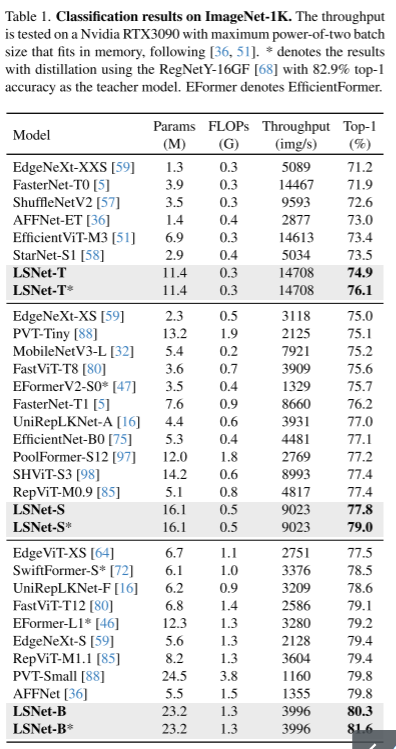
1、分类任务(table 1)
LSNet在Top1 mAcc评价指标中,吞吐量Throughput、准确率都效果更好。
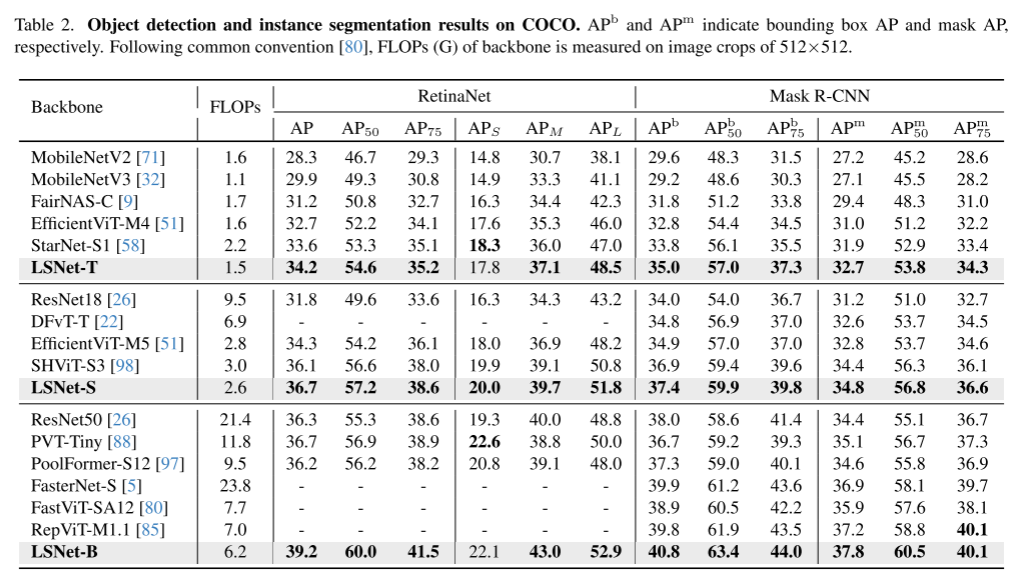
2、目标检测和实例分割(table 2)
将LSNet集成到RetinaNet和MASK R-CNN中,并在COCO-2017上进行实验。
目标检测:在RetinaNet目标检测框架中,LSNet效果更好。
实例分割:在MASK R-CNN框架中,LSNet效果更好。
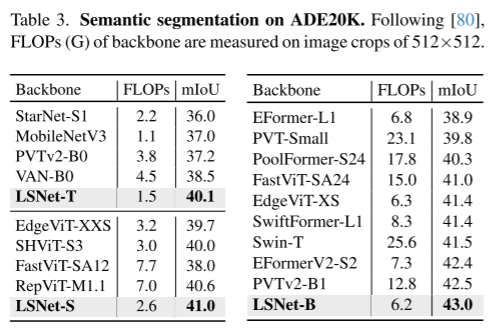
3、语义分割(table 3)
在ADE20K(数据集)上训练,将LSNet引入FPN模型作为Backbone,LSNet的效果都更好。
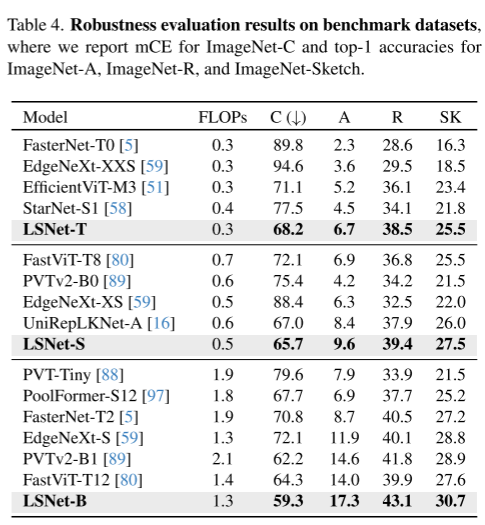
4、健壮性评估(table 4)
基准:ImageNet-C、ImageNet-A、ImageNet-R、ImageNet-Sketch。
例如,与UniRepLKNet-A相比,效果都更好。
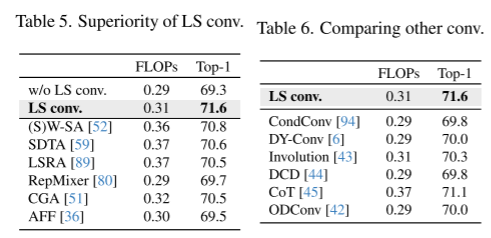
5、模型评估(table 5、6)
将所有LS卷积都替换成恒等式函数就是“w/o LS卷积”。
LS卷积与w/o LS卷积在TOP-1上比较,准确率更高,且每秒浮点运算操作(FLOPS)只增加了0.02G;
通过将LS卷积替换成其他token mixing方法,LS卷积的效果都要更好。
七、第八页
1、大核感知的重要性。(table 7)
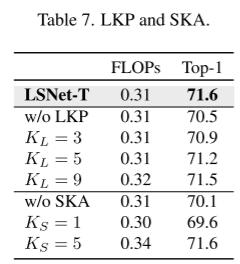
将 大核感知(LKP) 与 去掉LKP中的大核深度卷积的“w/o LKP” 比较,TOP-1准确率LKP更好。 另外,随着核大小的增加,模型性能不断提高,TOP-1的精度在核KL大小为7时达到饱和点。
2、小核聚集的重要性。(table 7)
将小核聚集(SKA)与w/o SKA(核大小为Ks×Ks的静态深度卷积)比较,TOP-1中我们的效果更好。 另外,当Ks大小为3时,实现精度和计算代价之间的最优折衷。
3、分组数量的影响。(table 8)
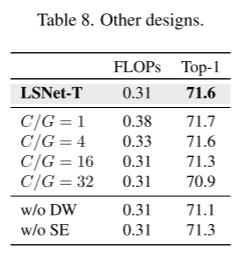
随着分组数G的增加,共享聚合权重的信道数量(C/G)减少,计算成本增加。如table 8,当C/G=8时,准确率和计算复杂度达到最好的平衡。
4、额外的DW和SE层的影响。
引入更多局部结构信息。有比没有好。
5、将LS卷积移植到ResNet和DeiT中,取代它们中全部的3×3卷积和self-attention,TOP-1的正确率都有了提高。