当我们说“让AI理解人类语言”时,第一步是什么? 计算机是无法直接处理文本的,它需要数字。而模型与分词器就是完成“文本 → 数字 → 理解”这个神奇转换的关键二人组。本文将带你彻底理解这两者是什么、如何工作以及如何协同工作的。并使用 Transformers 库中的代码演示。
1. 分词器
所谓分词器就是一个将原始文本切分成模型可处理的基本单元(Token)并转换为数字ID的组件。分词器包括三个核心任务,分别是分词、映射、编码,在神经网络中,我们知道网络处理的都是数值数据,所以我们的文本也要转换为数字,最后词嵌入得到向量,网络处理的就是词向量,将文本转换为数字的过程称为编码(Encoding),编码包括分词与映射两个步骤,基本概念如下:
分词 : 把连续的字符串切分成有意义的、模型能够处理的基本片段,这些片段被称为 Token,常用的分词算法有BPE、WordPiece等。
映射 :将上一步得到的每一个Token,在一个预定义的词汇表中查找其对应的唯一数字ID。
编码:简单的数字ID列表,丰富并打包成模型所需的、包含更多信息的标准化的张量格式,常常包括添加特殊Token,填充或截断,创建注意力掩码,解码器输入id(有解码器的翻译任务)。
接下来,先详细看下token,对于计算机而言,Token就是词汇表中的一个索引(数字ID),是模型的基本输入单位。对于人类而言来说Token可能是一个词、一个子词、一个字符,甚至是一个标点符号。下面先通过使用transformers的代码来看一个简单的英文句子分词。
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") text="hello,world! I like learning large language model" tokens1 = tokenizer.tokenize(text) print("分词结果:", tokens1) #分词结果: ['hello', ',', 'world', '!', 'i', 'like', 'learning', 'large', 'language', 'model'] text2 = "Hello, world! This is a simple tokenization demo." tokens2 = tokenizer.tokenize(text2) print("分词结果:", token2) #分词结果: ['hello', ',', 'world', '!', 'this', 'is', 'a', 'simple', 'token', '##ization', 'demo', '.']
代码中选择了bert-base-uncased这个模型,运行时,会从huggingface自动下载模型到缓存目录C:\Users\Administrator\.cache\huggingface\hub。句子hello,world! I like learning large language model分词结果为'hello', ',', 'world', '!', 'i', 'like', 'learning', 'large', 'language', 'model' 这与人的感觉是一致的。但是下面的text2分词结果中出现了将tokenization拆分并出现#的情况。这也说明分词的每个token有时候也不是简单的一个完整单词,具体取决于词表与算法,我们看下面的分词策略。
分词策略:根据切分粒度的不同,分词策略可以分为按词切分 (Word-based),按字符切分 (Character-based),按子词切分 (Subword)
按字符切分:
"I don't like ice cream." → ["I", " ", "d", "o", "n", "'", "t", " ", "l", "i", "k", "e", " ", "i", "c", "e", " ", "c", "r", "e", "a", "m", "."]
优点:
-
词汇表极小:英文只有26个字母+标点,中文几千个常用字
-
几乎不存在未登录词:任何新词都能被处理
缺点:
-
序列长度极长:处理长文本时计算效率低
-
语义信息稀疏:单个字符通常没有完整含义
-
模型难以学习:需要从字符组合中推断单词含义
按词切分:
"I don't like ice cream." → ["I", "don't", "like", "ice", "cream", "."]
优点:
-
直观易懂,每个token通常具有明确的语义
-
序列长度相对较短
缺点:
-
词汇表爆炸:词汇表可能变得非常大(几十万甚至上百万)
-
未登录词问题:无法处理不在词汇表中的新词
-
形态学问题:
"like"、"likes"、"liked"、"liking"会被视为完全不同的词
按子词切分 (目前最主流,介于词级和字符级之间),其算法包括如下:
Byte Pair Encoding (BPE) - 用于GPT系列,WordPiece - 用于BERT,前者基于频率,后者基于频率,这里不详细讨论。
由于按子词切分在词汇表大小和序列长度之间取得最佳平衡,且通过拆分机制,能有效处理训练时未见过的词汇,模型能更好地学习词形变化规律,适合处理形态丰富的语言和混合语言场景,成为了主流,后面全部使用的分词都是按子词划分的,然后看一个使用子词划分的例子:
text3="running, unbelievable debugging tokenization punctuation transformer" tokens3 = tokenizer.tokenize(text3) print("分词结果:", tokens3) #['running', ',', 'unbelievable', 'de', '##bu', '##gging', 'token', '##ization', 'pun', '##ct', '##uation', 'transform', '##er']
我们可以看到并不是所有的组合词都会被拆分,那些高频出现的组合词不会被拆分。结果中出现的##是WordPiece算法的特征,用于标识"延续子词",每个元素都是一个token,所以##er 是一个完整的token,有独立的ID编码,## 作为前缀是token的一部分,# 不会被单独编码;在解码时会自动去除 ##,恢复原始文本。看完分词,再看下是怎么映射的,所谓映射就是对应一个词表,下载的模型中一般有tokenizer.json(完整的分词器配置,现代推荐)、vocab.json(简单的词汇表映射)。打开如下:
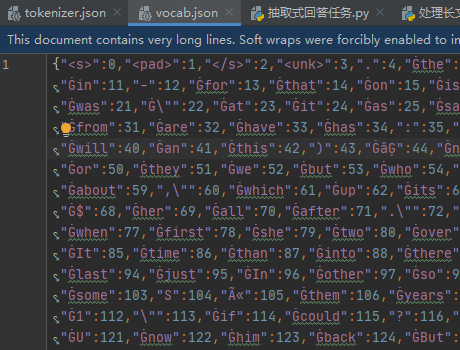
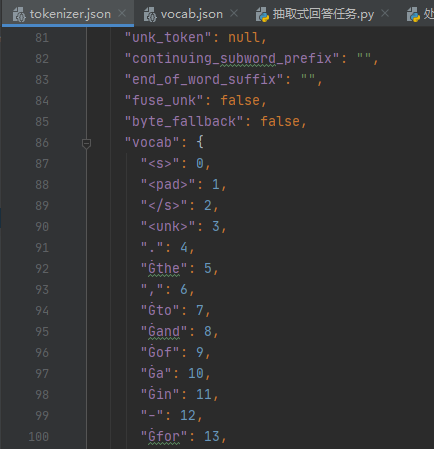
2. 保存分词器
from transformers import BertTokenizertokenizer = BertTokenizer.from_pretrained("bert-base-cased") tokenizer.save_pretrained("./models/bert-base-cased/")
调用 Tokenizer.save_pretrained() 函数会在保存路径下创建三个文件:
- special_tokens_map.json:映射文件,里面包含 unknown token 等特殊字符的映射关系;
- tokenizer_config.json:分词器配置文件,存储构建分词器需要的参数;
- vocab.txt:词表,一行一个 token,行号就是对应的 token ID(从 0 开始)。
3. 映射
前面介绍完了分词,然后通过 convert_tokens_to_ids() 将切分出的 tokens 转换为对应的 token IDs后,模型才能处理,
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") tokenized_text = tokenizer("Using a Transformer network is simple") print(tokenized_text) #{'input_ids': [101, 2478, 1037, 10938, 2121, 2897, 2003, 3722, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
打印结果如上面代码的注视部分:
input_ids -输入ID,将文本token转换为模型可以理解的数字ID序列
token_type_ids - 句子类型标识,常用于句子对,区分toeken属于哪个句子,例子中全0,表示每个token都来自同一句子。
attention_mask - 注意力掩码,1表示模型需要关注该token,当有填充不需要关注,就置0,比如后面介绍的句子长度对齐,不足使用填充,掩码部分置0。
在input_ids中 101 和 102 分别是 [cls]和[sep] 对应的 token IDs,表示句子首部与结尾,对于该分词器来说,每个句子都会加上101与102。
4. Padding操作
按批输入多段文本产生的一个直接问题就是:batch 中的文本有长有短,而输入张量必须是严格的二维矩形,维度为(batch,sequence length),先看下面的例子:
import torch from transformers import AutoTokenizer, AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english" tokenizer = AutoTokenizer.from_pretrained(checkpoint) model = AutoModelForSequenceClassification.from_pretrained(checkpoint) batched_ids = [[101, 10938, 2121, 2897, 2003, 3722, 102], #['[CLS]', 'transform', '##er', 'network', 'is', 'simple', '[SEP]'][101, 2478, 1037, 10938, 2121, 2897, 2003, 3722, 102], #['[CLS]', 'transform', '##er', 'network', 'is', 'simple', '[SEP]']
] print(model(torch.tensor(batched_ids)).logits)
上面的程序中为方便测试全部直接转换成了token的id形式,真实token为绿色注释后面的。s输入到模型运行后发现报错了,如下:

是因为批次的句子中,第一个句子与第二句子的token数量不相等,我们改为填充后再测试如下:
import torch from transformers import AutoTokenizer, AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english" tokenizer = AutoTokenizer.from_pretrained(checkpoint) model = AutoModelForSequenceClassification.from_pretrained(checkpoint)batched_ids = [[101, 10938, 2121, 2897, 2003, 3722, 102,tokenizer.pad_token_id,tokenizer.pad_token_id], #['[CLS]', 'transform', '##er', 'network', 'is', 'simple', '[SEP]'][101, 2478, 1037, 10938, 2121, 2897, 2003, 3722, 102], #['[CLS]', 'transform', '##er', 'network', 'is', 'simple', '[SEP]']
]
print(model(torch.tensor(batched_ids)).logits)
我们加上了tokenizer.pad_token_id,对于该分词器而言,它的值为0。程序运行打印输出后如下,能正常运行了。

5. AttentionMask
前面初步提到了,这里先看例子,看是如何起到作用的。
import torch from transformers import AutoTokenizer, AutoModelForSequenceClassification checkpoint = "distilbert-base-uncased-finetuned-sst-2-english" tokenizer = AutoTokenizer.from_pretrained(checkpoint) model = AutoModelForSequenceClassification.from_pretrained(checkpoint) sequence1_ids = [[101, 10938, 2121, 2897, 2003, 3722, 102]] sequence2_ids = [[101, 2478, 1037, 10938, 2121, 2897, 2003, 3722, 102]] batched_ids = [[101, 10938, 2121, 2897, 2003, 3722, 102,tokenizer.pad_token_id,tokenizer.pad_token_id],[101, 2478, 1037, 10938, 2121, 2897, 2003, 3722, 102], ]print(model(torch.tensor(sequence1_ids)).logits) print(model(torch.tensor(sequence2_ids)).logits) print(model(torch.tensor(batched_ids)).logits)
运行结果如下:
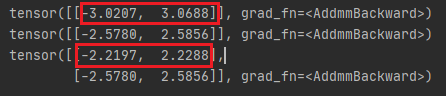
我们为了让批次batch中的句子token个数相同,使用了tokenizer.pad_token_id,但是句子1的输出并不相等,也就是说是填充导致模型输出不同,所以要想办法让模型不关注填充。再看下面代码:
import torch from transformers import AutoTokenizer, AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english" tokenizer = AutoTokenizer.from_pretrained(checkpoint) model = AutoModelForSequenceClassification.from_pretrained(checkpoint)sequence1_ids = [[101, 10938, 2121, 2897, 2003, 3722, 102]] sequence2_ids = [[101, 2478, 1037, 10938, 2121, 2897, 2003, 3722, 102]]batched_ids = [[101, 10938, 2121, 2897, 2003, 3722, 102,tokenizer.pad_token_id,tokenizer.pad_token_id],[101, 2478, 1037, 10938, 2121, 2897, 2003, 3722, 102], ]batched_attention_masks = [[1, 1, 1, 1, 1, 1, 1, 0, 0],[1, 1, 1, 1, 1, 1, 1, 1, 1], ]print(model(torch.tensor(sequence1_ids)).logits) print(model(torch.tensor(sequence2_ids)).logits) # print(model(torch.tensor(batched_ids)).logits) outputs = model(torch.tensor(batched_ids),attention_mask=torch.tensor(batched_attention_masks)) print(outputs.logits)
输出结果如下:
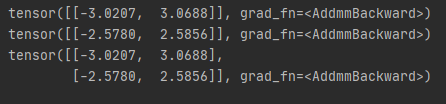
完全相同了,这个代码中,我们加上了注意力掩码attention_mask,0的位置表示不需要模型关注的token。事实上这里只是举例来说明输入模型不只是映射ID,还有token类别ID与注意力掩码,在写程序时候,分词器都帮我们做好了,这里只是介绍其作用。
6. 解码
前面介绍了文本编码为数字ID,(中间其实还包括位置编码,最后组合后送入模型的),经过模型输出后logits结果,我们通过softmax可以得到对应的词表映射就能输出文本了,这里简单演示transformers解码(对token ID)。
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") decoded_string = tokenizer.decode([2478, 1037, 10938, 2121, 2897, 2003, 3722]) print(decoded_string) decoded_string = tokenizer.decode([101, 2478, 1037, 10938, 2121, 2897, 2003, 3722, 102]) print(decoded_string)

这里的101与102分别对应开始[CLS]与结尾[SEP]。
小结:虽然标题为模型与分词器,本文还是主要讲解了分词器,如果涉及到翻译类的任务还需要解码器,输入除了映射ID,句子类别ID,注意力掩码外还包括decoder_input_ids。还有关于填充的长度与参数,特殊token的添加等这里暂时没有讲到,后面再补充。
参考资料:
https://zhuanlan.zhihu.com/p/1953846538536200054
若存在不足之处,欢迎评论与指出。