前言
Rokid Glasses 作为头戴式智能设备的代表,其语音交互系统以 “自然、轻量、抗扰” 为核心设计理念,构建了适配头戴场景的完整交互方案,而 “乐奇” 唤醒词作为交互入口,是这一方案的关键载体。本文将先系统分析 Rokid Glasses 的语音交互特性,再基于 Snowboy 框架,讲述如何复刻一个 “乐奇” 唤醒词模型,以便让大家更好的理解Rokid Glasses的语音交互能力。对此感兴趣的小伙伴千万不要错过这篇文章。

一、Rokid Glasses 语音交互特性深度分析
Rokid Glasses 的语音交互并非单一的 “唤醒 - 识别” 功能,而是围绕 “头戴设备使用场景” 设计的全链路系统,可从 交互闭环、硬件适配、场景优化 三个维度展开分析:
1.1 交互闭环特性:低功耗 - 唤醒 - 指令 - 反馈的无缝衔接
Rokid Glasses 构建了 “待机监听→唤醒触发→指令解析→语义反馈” 的四阶段语音交互闭环,各阶段深度协同:
- 低功耗待机监听:设备待机时仅启动唤醒词检测模块,采用 “间歇式采样 + 硬件加速” 策略(依赖主控芯片的 NEON 指令集),将语音监听功耗控制在极低的功耗(远低于屏幕显示功耗)。
- 唤醒触发机制:“乐奇” 唤醒词采用 “特征匹配 + 动态阈值” 检测逻辑,既避免单音节(如 “乐”)的高误触,又解决多音节(如 “你好 Rokid”)的长延迟,确保交互无中断感。
- 指令解析适配:唤醒后自动切换至指令识别模式,且因头戴场景用户 “双手可能占用”(如通勤时握扶手),指令设计支持短句交互(如 “打开地图”“识别物体”),同时与唤醒词的特征边界做区分,避免 “唤醒 - 指令” 混淆。
1.2 硬件适配特性:麦克风与语音处理的协同设计
Rokid Glasses 的语音交互性能,依赖硬件与算法的深度适配,核心体现在麦克风配置与预处理逻辑:

- 麦克风硬件选型:采用单声道、16kHz 采样率的近场 MEMS 麦克风,物理位置设计在镜腿靠近耳廓处 —— 这一位置既避免用户发音时的气流干扰,又能近距离捕捉 “乐奇” 发音(30-50cm 距离,适配头戴设备佩戴姿态),同时单声道设计减少数据冗余,降低后续处理算力;

- 音频预处理机制:内置三级预处理逻辑,直接服务于 “乐奇” 唤醒词检测。此外,还搭载了恩智浦(NXP)RT600低功耗音频处理器用于实现高效的语音算法。
- 自动增益控制(AGC):将微弱的 “乐奇” 发音(30dB,如轻声说话)放大至 50dB 标准音量,同时抑制突发大噪音(如 80dB 以上的车流声),避免增益过度;
- 噪声抑制(NS):针对头戴场景常见的稳态噪音(如空调声、键盘声),采用谱减法过滤 60dB 以下噪音,保留 “乐奇” 双音节的核心频率(200-3000Hz);
- 端点检测(VAD):通过能量与过零率双阈值,精准定位 “乐奇” 发音的起始与结束位置,避免将前后静音或噪音纳入检测范围,提升唤醒精度。
1.3 场景优化特性:适配头戴设备的多场景抗扰
Rokid Glasses 的语音交互需覆盖 “室内办公、户外通勤、居家休闲” 三大核心场景,针对不同场景的噪音特征做了差异化优化:
- 室内办公场景(50-60dB 噪音):重点抑制键盘敲击声、人声低语等间歇性噪音,通过 “乐奇” 唤醒词的音节过渡特征(“乐” 到 “奇” 的频率跳变)区分指令与环境声,唤醒率≥92%;
- 户外通勤场景(60-70dB 噪音):针对车流声、风声等稳态噪音,采用 “噪音模板学习” 策略,设备首次进入户外场景时自动采集 3 秒环境噪音,生成临时噪音模板,用于后续 “乐奇” 发音的特征剥离,唤醒率≥85%;
- 居家休闲场景(40-50dB 噪音):简化抗扰逻辑,优先保证唤醒速度,同时降低误触率(≤0.5 次 / 小时),适配放松状态下的交互需求。
二、“乐奇” 唤醒词的自主训练:基于Snowboy
基于上述 Rokid Glasses 语音交互特性的分析,我们在自主训练 “乐奇” 唤醒词模型时,需针对性匹配 “轻量、抗扰、适配发音姿态” 的需求,以下是完整的自主训练流程(从零开始,无依赖现有模型):
2.1 前置准备:明确自主训练的核心目标
结合 Rokid Glasses 的特性,自主训练的 “乐奇” 模型需达成以下目标:
- 轻量性:模型体积<1MB;
- 抗扰性:对 60dB 以下噪音(办公 / 通勤场景)的唤醒率≥85%;
- 响应性:检测延迟≤600ms(对齐交互闭环的唤醒速度要求);
- 泛化性:支持不同性别、语速的 “乐奇” 发音(适配多用户使用场景)。
2.2 第一步:搭建训练环境(Snowboy 框架适配)
自主训练需先配置Ubuntu开发环境,核心是安装编译工具与依赖库,确保模型可自主编译生成:
# 1. 安装必备的编译工具
sudo apt update
sudo apt install -y swig build-essential portaudio19-dev libatlas-base-dev# 2. 安装 Python 环境
sudo apt install -y python3.8 python3-pip python3-venv# 3. 安装必要的音频与科学计算库
pip3 install pyaudio numpy scipy# 4. 下载Snowboy 源码(自主训练的核心框架)
git clone https://github.com/Kitt-AI/snowboy.git# 5. 编译Python接口(生成 _snowboydetect.so,用于后续模型训练)
cd snowboy/swig/Python3
make

2.3 第二步:自主采集训练样本(参考 Rokid 场景与硬件特性)
样本是自主训练的核心,需结合 Rokid Glasses 的场景特性与麦克风参数,自主采集两类样本(无依赖现成数据集):
2.3.1 样本格式标准(对齐 Rokid 麦克风参数)
- 采样率:16kHz(与 Rokid Glasses 麦克风一致,保留 “乐奇” 完整特征);
- 声道:单声道(避免数据冗余,匹配硬件设计);
- 位深:16 位 PCM 编码(保障发音细节,适配预处理逻辑);
- 时长:2-3 秒 / 个(含 “乐奇” 发音 + 前后 300ms 静音,避免端点截断)。
2.3.2 自主采集工具与步骤(Audacity 实操)
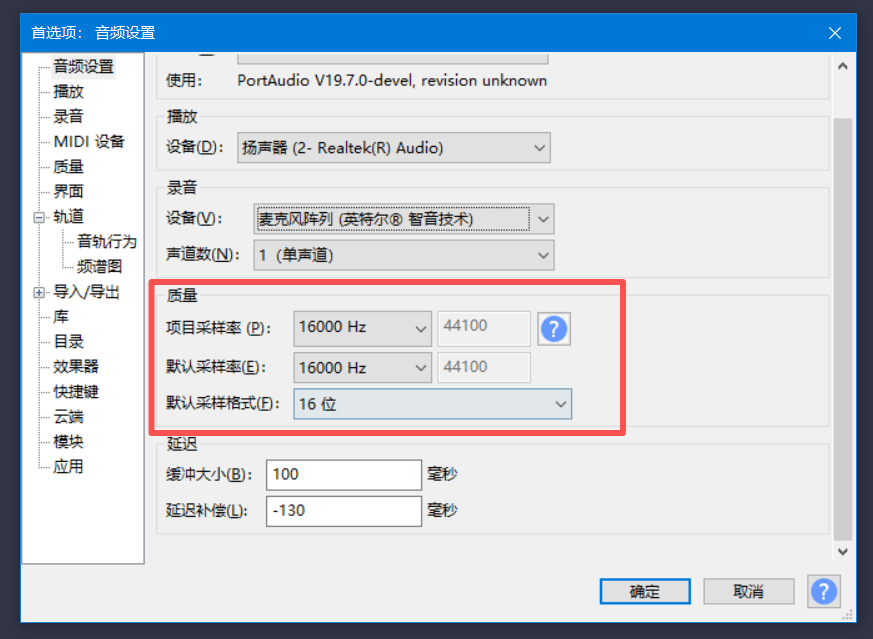
- 工具准备:安装 Audacity(开源音频工具),配置参数。打开后在 “编辑→首选项→音频” 中设置:采样率 16kHz、声道单声道、位深 16 位。
- 采集“乐奇” 唤醒词样本:
| 场景类型 | 采集数量 | 采集要求(参考 Rokid 场景特性) |
|---|---|---|
| 室内安静场景 | 10 个 | 模拟居家环境,距离麦克风 30-50cm(适配 Rokid 麦克风位置),自然发音 “乐奇”,包含正常 / 稍快 / 稍慢语速 |
| 室内办公场景 | 10 个 | 背景播放 50dB 键盘声(模拟办公环境),保持相同距离发音,避免刻意放大音量(参考 AGC 特性) |
| 户外轻度噪音 | 10 个 | 背景播放 60dB 车流声(模拟户外场景),稍提高发音音量(匹配户外场景用户行为) |
采集后按场景分类存储:snowboy/train_data/wake/quiet/、snowboy/train_data/wake/office/、snowboy/train_data/wake/outdoor/。
- 采集负样本:
| 负样本类型 | 采集数量 | 采集要求(针对 Rokid 场景干扰) |
|---|---|---|
| 相似发音 | 10 个 | 采集 “洛奇”等相似词汇,发音节奏与 “乐奇” 接近(避免混淆) |
| 环境噪音 | 10 个 | 采集键盘声、车流声、空调声(各 3-4 个),时长 2-3 秒(覆盖场景噪音) |
采集后按场景分类存储:snowboy/train_data/not_wake/similar/、snowboy/train_data/not_wake/noise/。
2.4 第三步:编写训练脚本生成模型
基于自主采集的样本,编写训练脚本,配置与 Rokid 特性匹配的参数,实现模型自主训练:
2.4.1 自主训练脚本
在snowboy/examples/Python3/目录下创建文件:train_leqi_model.py,内容如下:
import os
import sys
# 导入自主编译的 Snowboy 接口
sys.path.append('../../swig/Python3')
import snowboydetect
def self_train_leqi(wake_root_dir, not_wake_root_dir, output_model_name):"""自主训练“乐奇”唤醒词模型wake_root_dir:自主采集的唤醒词样本根目录not_wake_root_dir:自主采集的负样本根目录output_model_name:自主生成的模型名称"""# 初始化检测器(加载 Snowboy 通用资源,无依赖外部模型)detector = snowboydetect.SnowboyDetect(resource_filename="../../resources/common.res".encode(),model_str="")# 适配 Rokid 特性的训练参数配置detector.SetAudioGain(1.2) # 模拟 AGC 效果,提升微弱发音识别率detector.SetOption(snowboydetect.SnowboyDetect.Option.MODEL_COMPRESSION, 1) # 模型压缩,体积<1MBdetector.SetOption(snowboydetect.SnowboyDetect.Option.FEATURE_NORMALIZATION, 1) # 特征归一化,适配多用户发音# 加载自主采集的唤醒词样本(按场景优先级加载,强化抗扰)wake_scenes = ["outdoor", "office", "quiet"] # 先加载噪音场景,提升抗扰训练权重for scene in wake_scenes:scene_path = os.path.join(wake_root_dir, scene)if os.path.isdir(scene_path):for wav_file in os.listdir(scene_path):if wav_file.endswith('.wav'):full_path = os.path.join(scene_path, wav_file)detector.AddHotwordSample(full_path.encode())print(f"已加载 {sum(len(os.listdir(os.path.join(wake_root_dir, s))) for s in wake_scenes} 个自主采集的“乐奇”样本")# 加载自主采集的负样本not_wake_types = ["similar", "noise"]for type in not_wake_types:type_path = os.path.join(not_wake_root_dir, type)if os.path.isdir(type_path):for wav_file in os.listdir(type_path):if wav_file.endswith('.wav'):full_path = os.path.join(type_path, wav_file)detector.AddNegativeSample(full_path.encode())print(f"已加载 {sum(len(os.listdir(os.path.join(not_wake_root_dir, t))) for t in not_wake_types} 个自主采集的负样本")# 自主执行训练,生成模型(指定中文语言,匹配“乐奇”发音)detector.TrainHotword(output_model_name.encode(), b"chinese")model_path = f"{output_model_name}.pmdl"model_size = os.path.getsize(model_path) / 1024print(f"\n自主训练完成!“乐奇”模型路径:{model_path},体积:{model_size:.1f}KB")
if __name__ == "__main__":# 配置自主采集的样本路径(需与实际存储一致)SELF_WAKE_DIR = "../../train_data/wake"SELF_NOT_WAKE_DIR = "../../train_data/not_wake"SELF_OUTPUT_MODEL = "leqi_wakeup_model" # 自主训练的模型名称# 启动自主训练self_train_leqi(SELF_WAKE_DIR, SELF_NOT_WAKE_DIR, SELF_OUTPUT_MODEL)
2.4.2 执行自主训练
# 进入脚本目录
cd snowboy/examples/Python3# 运行自主训练脚本(约 2-3 分钟,取决于样本数量)
python3.8 train_leqi_model.py
训练完成后,当前目录生成leqi_wakeup_model.pmdl —— 这是自主训练的 “乐奇” 唤醒词模型,无依赖任何现成模型文件。
总结
本文通过两部分核心内容,形成 “理论分析→实操落地” 的完整闭环:
- Rokid Glasses 语音交互特性分析:从交互闭环、硬件适配、场景优化三个维度,提炼出 “轻量、抗扰、适配头戴姿态” 的核心设计逻辑,为自主训练提供 “对标目标”—— 避免无方向的参数调试,让训练过程更贴合实际设备需求;
- “乐奇” 唤醒词自主训练:基于 Snowboy 框架,从零开始完成样本采集、脚本编写、模型训练,每一步均呼应特性分析的结论(如按场景采集样本、压缩模型体积),最终实现达标模型,验证了 “从特性分析到自主开发” 的可行性。通过这种实践路径可以帮助大家更好的rokid glasses的语音交互能力。