本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
本文 的 原文 地址
10亿用户微博Feed流,100WQPS 热点 如何 抵抗雪崩 ?
一、Feed流系统概述
第一、Feed流基本概念
Feed流是现代社交平台的核心功能,指持续更新并呈现给用户的内容信息流。
Feed代表单个信息单元,如一条微博、一条朋友圈状态;
Feed流则是这些信息单元按照特定顺序组成的动态更新序列。
在技术层面,Feed流本质上是将N个发布者的信息单元通过关注关系传送给M个接收者的数据流系统。
系统需要处理三类核心数据:
- 发布者数据
- 关注关系数据
- 接收者数据
第二、Feed流分类与特点
Feed流主要分为两种类型:
-
Timeline模式按内容发布的时间顺序排序,确保用户能看到所有关注对象的完整内容流。这种模式适用于强关系链场景,如微信朋友圈、微博关注页,其中信息完整性和时效性比个性化更重要。
-
Rank模式按非时间因子(如用户喜好度、内容热度)排序,通常采用算法推荐机制。这种模式适用于内容发现平台,如抖音、今日头条,侧重于提升用户参与度和内容分发效率。
两种模式的对比决定了系统架构的差异, 各自适用于不同场景 :
- Timeline模式强调数据完整性和时间顺序
- 而Rank模式需要复杂的算法支持和用户画像分析。
二、Feed流初始化设计
1、Feed初始化核心逻辑
Feed流初始化是为新用户或长时间未活跃用户构建个人时间线的过程。
当用户首次使用系统或缓存失效时,系统需要遍历其关注列表,获取所有关注用户的最新Feed,并构建有序的时间线缓存。
初始化过程的关键在于高效加载数据并建立缓存结构,为后续的读取操作奠定基础。合理的初始化策略能显著提升用户体验,避免首次加载延迟。
2、Feed 初始化流程设计
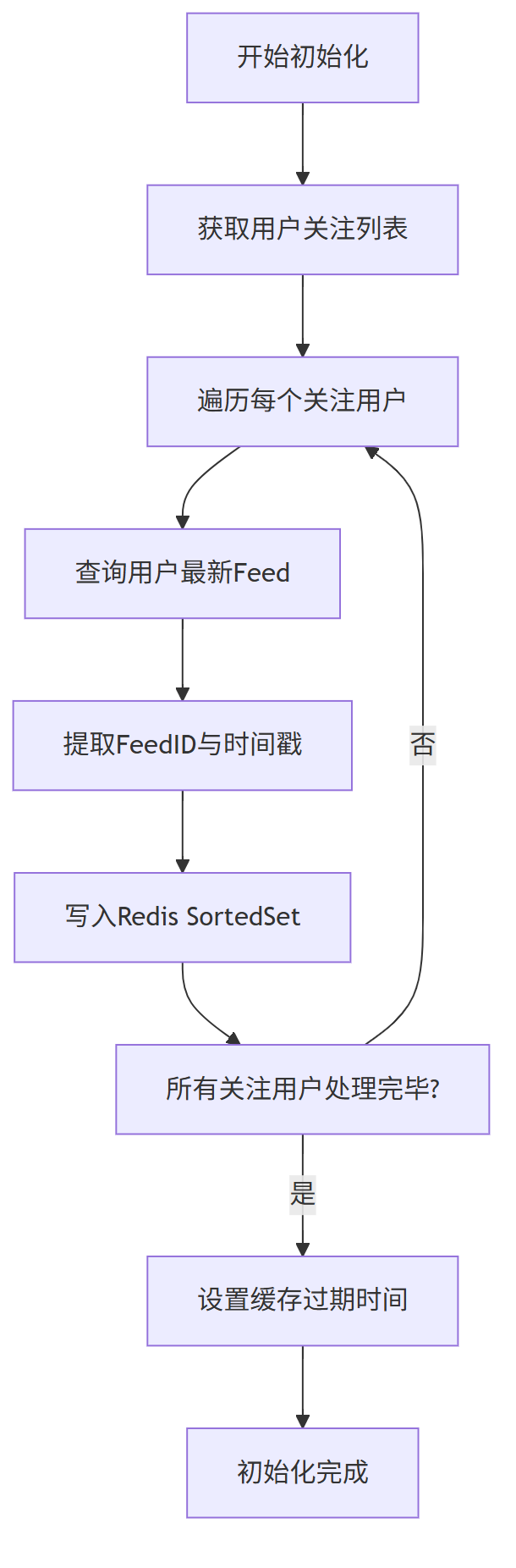
具体流程中,系统首先查询用户的关注关系列表,然后针对每个关注用户获取其最新发布的Feed内容。
-
对于Timeline类型,直接使用Feed创建时间戳作为排序分数;
-
对于Rank类型,则需计算内容权重值作为排序依据。
三、推送更新机制
第一、推送触发场景
Feed流更新主要在四种情况下触发:关注用户发布新Feed、关注用户删除Feed、用户新增关注关系、用户取消关注关系。
系统需针对不同场景采用相应的更新策略。对于内容发布和删除操作,需及时同步到所有粉丝的时间线;对于关系变化,则需要调整时间线内容组成。
第二、推送模式
面对海量用户,推送模式的选择直接影响系统性能和可扩展性。
主要分为三种模式:推模式、拉模式和推拉结合模式。
推模式(写扩散)在内容发布时主动推送给所有粉丝,读取性能极佳但写入压力大;
拉模式(读扩散)在用户读取时实时聚合内容,写入轻量但读取延迟高;
推拉结合模式综合两者优势,是10亿级用户场景的理想选择
第三、 "推送风暴" 问题 & “拉取风暴” 问题
大 V、头部创作者发布内容时 ,会出现 "推送风暴" 问题 & “拉取风暴” 问题:
-
"推送风暴" 问题:“推送风暴” 是 Feed 流推模式(写扩散)下的典型性能风险,多发生在大 V、头部创作者发布内容时。
-
“拉取风暴” 问题:拉模式(读扩散)虽规避了推模式的 “推送风暴”,但会因用户集中触发拉取操作,引发 “拉取风暴”.
接下来,结合 推模式 Feed 流 + 拉模式 模式 Feed 流 ,给大家分析 "推送风暴" 问题 & “拉取风暴” 问题,带大家解决这个问题。
第二章:详解: 推模式 Feed 流 设计与实现 方案(全小 V 场景)
一、推模式 Feed 流概述
第一、模式定义
推模式 Feed 流是指当用户发布内容(Feed)时,系统主动将该内容推送至所有关注者的 Feed 流中,使关注者能够直接查看新内容的机制。在无大 V 的场景下,用户粉丝数量相对均衡(通常在几千人以内),推送压力可控,无需复杂的分片和限流策略。
第二、适用特点
在无大 V 场景中,推模式具有以下优势:
- 所有用户粉丝量适中,推送操作可在短时间内完成
- 无需设计复杂的大 V 特殊处理机制,系统架构更简洁
- 读写性能平衡,适合中小型社交平台或垂直领域社区
二、核心存储架构设计
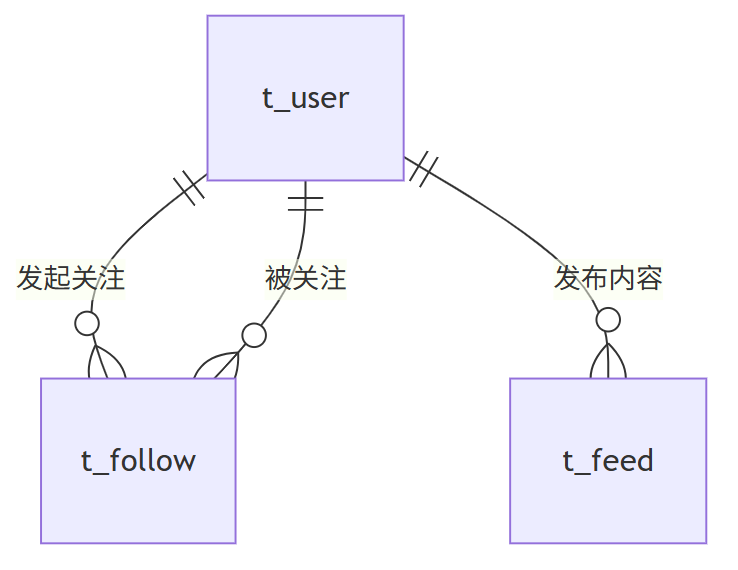
第一、MySQL 数据库设计
(1) 用户表(t_user)
- 核心字段:用户 ID(主键)、用户名、头像 URL、创建时间、状态
- 作用:存储用户基本信息
(2) 关注关系表(t_follow)
- 核心字段:关系 ID(主键)、关注者 ID(索引)、被关注者 ID(索引)、关注时间、状态
- 作用:记录用户间的关注关系
(3) Feed 内容表(t_feed)
- 核心字段:FeedID(主键)、发布者 ID(索引)、内容文本、图片列表、发布时间(索引)、状态
- 作用:存储用户发布的所有内容
(4) 数据库关系图
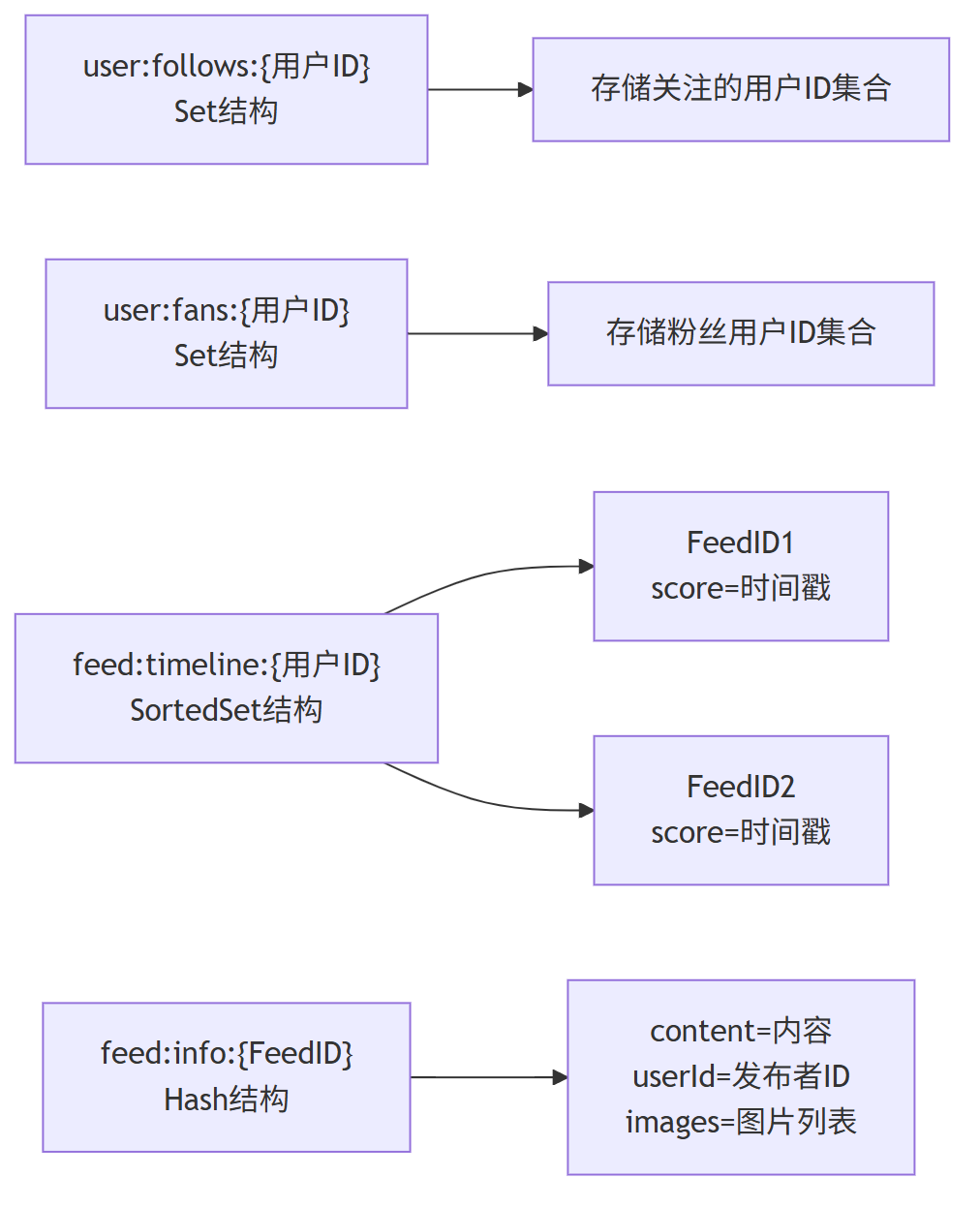
第二、Redis 存储架构设计
(1) 关注列表缓存
- 数据结构:Set
- Key 格式:
user:follows:{用户ID} - 存储内容:用户关注的所有用户 ID
- 作用:快速获取用户的关注列表
(2) 粉丝列表缓存
- 数据结构:Set
- Key 格式:
user:fans:{用户ID} - 存储内容:关注该用户的所有粉丝 ID
- 作用:发布内容时快速获取需要推送的粉丝列表
(3) Feed 流缓存
- 数据结构:SortedSet
- Key 格式:
feed:timeline:{用户ID} - 存储内容:成员为 FeedID,分数为发布时间戳
- 作用:按时间顺序存储用户可查看的所有 Feed
(4) Feed 内容缓存
- 数据结构:Hash
- Key 格式:
feed:info:{FeedID} - 存储内容:Feed 的详细信息(内容、图片、发布者等)
- 作用:快速获取 Feed 的完整内容,减少数据库访问
(5) Redis 存储关系图
三、核心流程设计
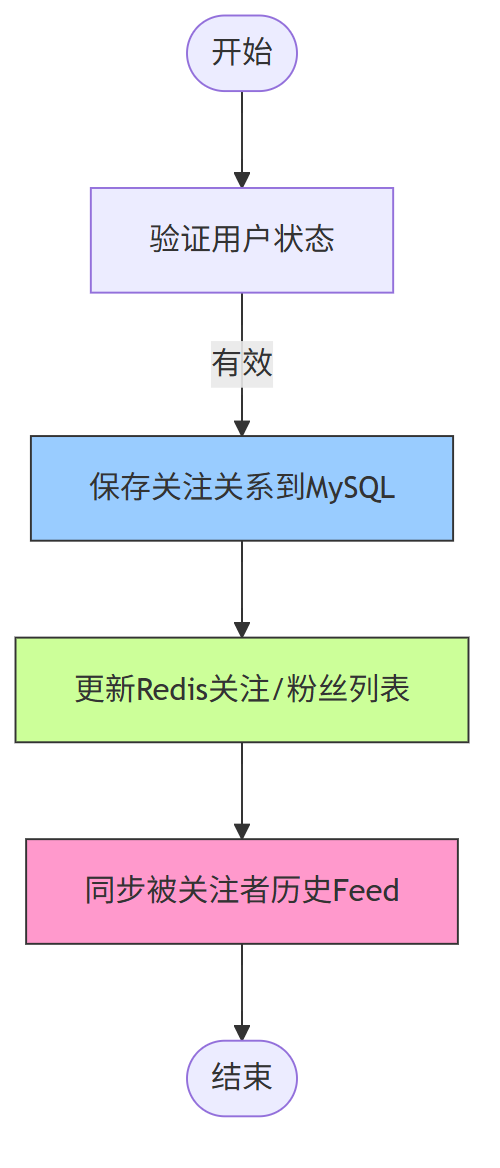
1、关注用户流程
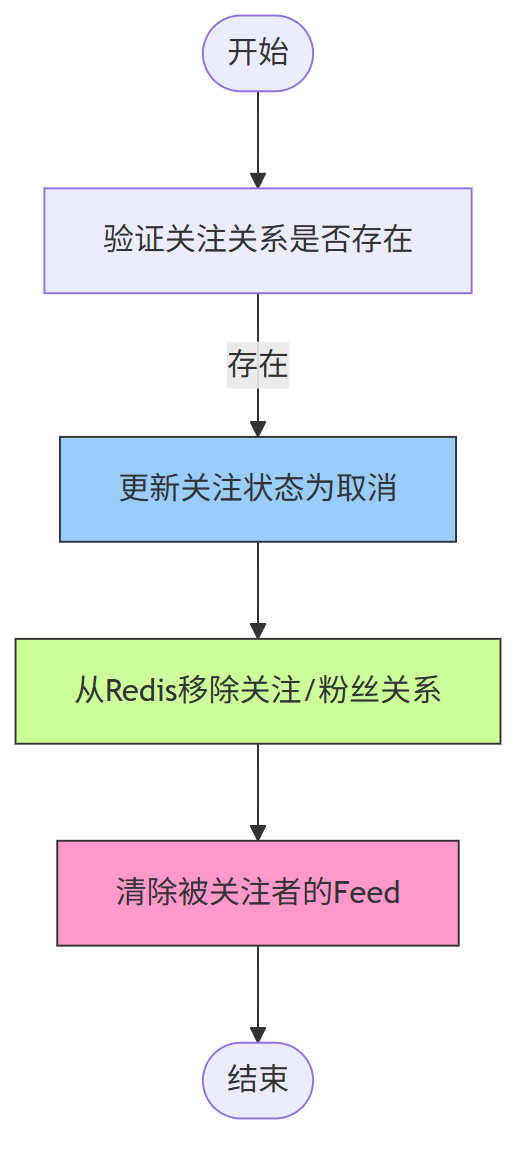
2、取消关注流程
3、Feed 发布与推送流程
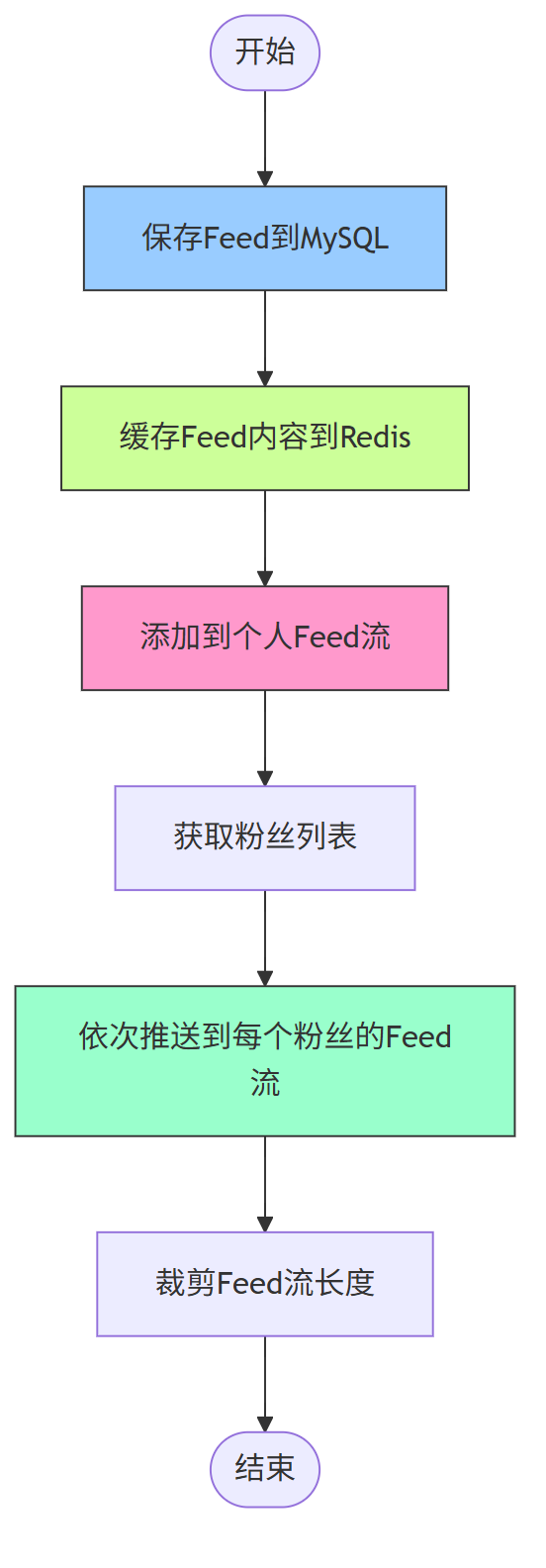
流程说明:
- 保存 Feed 到 MySQL 确保数据持久化
- 缓存 Feed 内容到 Redis 提高读取速度
- 添加到个人 Feed 流便于用户查看自己发布的内容
- 获取粉丝列表后直接推送到每个粉丝的 Feed 流(因无大 V,粉丝量少可同步处理)
- 裁剪 Feed 流长度防止缓存过大(如只保留最近 2000 条)
4、Feed 流获取流程
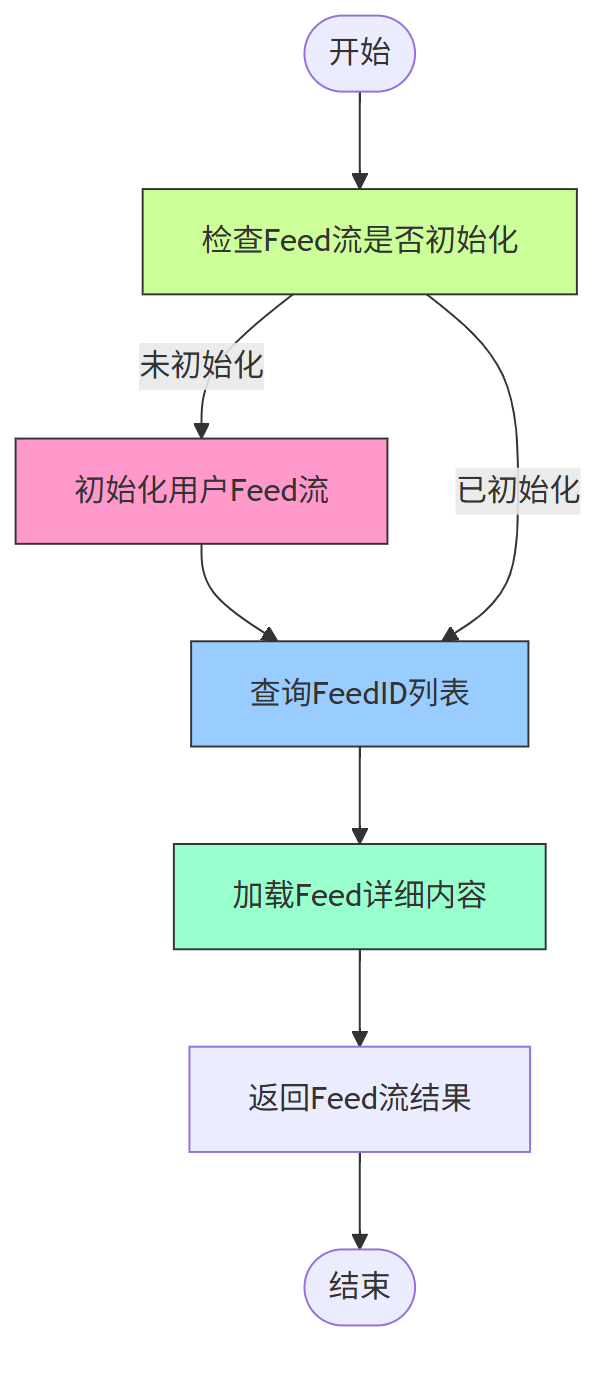
流程说明:
- 首次访问时初始化 Feed 流,聚合所有关注对象的历史内容
- 查询时通过 SortedSet 的倒序排列获取最新内容
- 分页加载 Feed 详情,提升加载速度
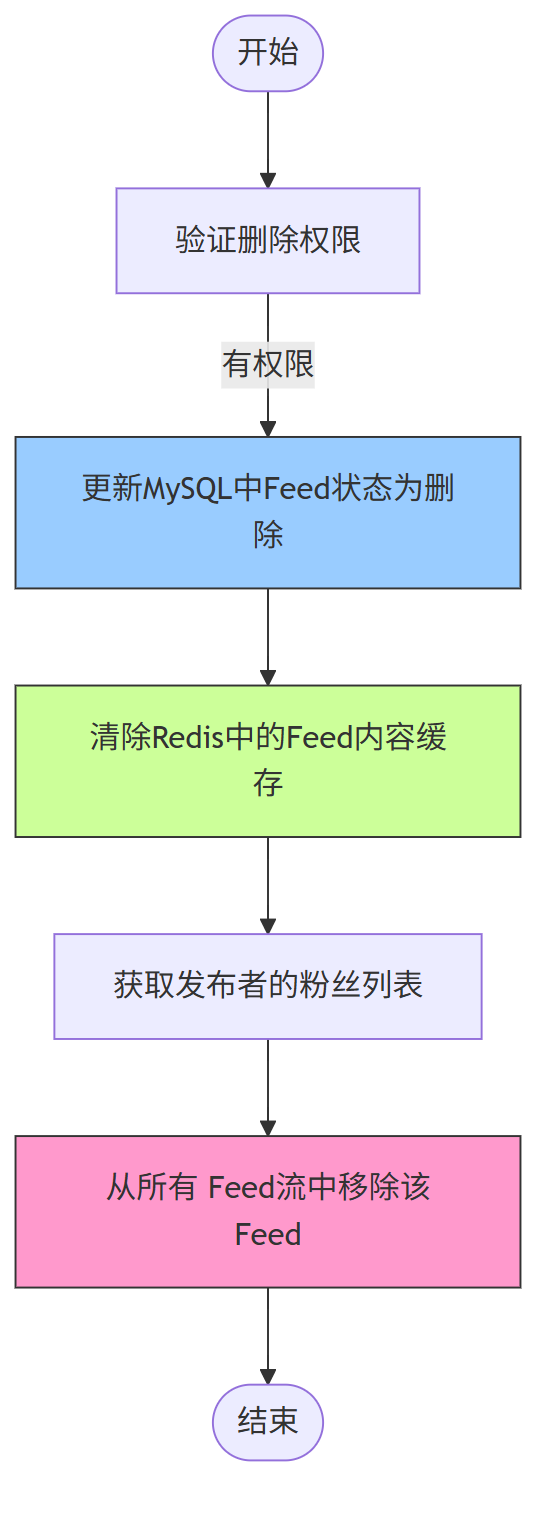
5、Feed 删除流程
五、小v 推模式 (写扩散模式)总结
在无大 V 的场景下,推模式 Feed 流系统可以采用更简洁的架构设计,无需复杂的分片和限流机制。通过 MySQL 存储核心数据,Redis 缓存热点数据和 Feed 流,实现了高效的内容分发。
核心优势体现在:
- 架构简单清晰,易于实现和维护
- 读写性能平衡,满足中小型平台需求
- 推送逻辑直接,无需处理大 V 带来的极端场景
系统设计需重点关注缓存一致性和推送可靠性,通过合理的优化策略,可支持十万至百万级用户规模的社交平台稳定运行。
"推送风暴" 问题:
“推送风暴” 是 Feed 流推模式(写扩散)下的典型性能风险,多发生在大 V、头部创作者发布内容时。
当创作者粉丝量达百万甚至千万级,系统需将其单条内容主动推送到所有粉丝的 Feed 流缓存 / 数据库中,瞬时产生海量并发写入操作。
这会引发连锁问题:
-
一是推送服务负载骤升,可能导致超时、队列堆积;
-
二是缓存集群被大量写入请求冲击,命中率下降,甚至触发限流;
-
三是数据库因批量插入操作压力倍增,影响其他业务读写。
最终导致内容推送延迟、部分粉丝无法实时接收内容,严重时会引发系统局部不可用,破坏用户体验与服务稳定性。
第三章:拉模式 Feed 流 设计与实现 方案(全大 V 场景)
一、拉模式 Feed 流概述
第一、模式定义
拉模式(Pull Model)Feed 流是指用户查看内容时,系统才主动从关注的对象中 “拉取” 最新内容并聚合展示的机制。
在全大 V 场景下,大 V 拥有百万级粉丝, 采用推模式会导致发布时推送压力激增, 产生 推送风暴。
拉模式,通过 “按需拉取” 可避免此问题,将负载转移到用户读取环节,更适配大 V 内容分发的特性。
第二、场景适配优势
全大 V 场景中,拉模式的核心优势的体现在三方面:
- 规避推送风暴:大 V 发布内容时无需推送给百万粉丝,仅需存储自身内容,彻底解决推模式下的写入压力
- 内容实时性可控:用户可按需拉取最新内容,支持 “下拉刷新” 等交互,符合大 V 粉丝对内容时效性的需求
- 存储无冗余:同一条大 V 内容仅存储一份,避免推模式下多粉丝缓存重复内容的问题,节省存储资源
二、核心存储架构设计
1、MySQL 数据库设计
针对全大 V 场景的内容特性与查询需求,设计三张核心表,确保数据持久化与高效查询:
(1) 用户表(t_user)
- 核心字段:用户 ID(主键)、用户名、用户类型(标记是否为大 V)、头像 URL、简介、创建时间、状态
- 作用:存储用户基础信息,区分普通用户与大 V,为后续拉取范围筛选提供依据
(2) 关注关系表(t_follow)
- 核心字段:关系 ID(主键)、关注者 ID(索引)、被关注大 V ID(索引)、关注时间、最后拉取时间
- 作用:记录用户与大 V 的关注关系,“最后拉取时间” 用于下次拉取时筛选增量内容,减少数据量
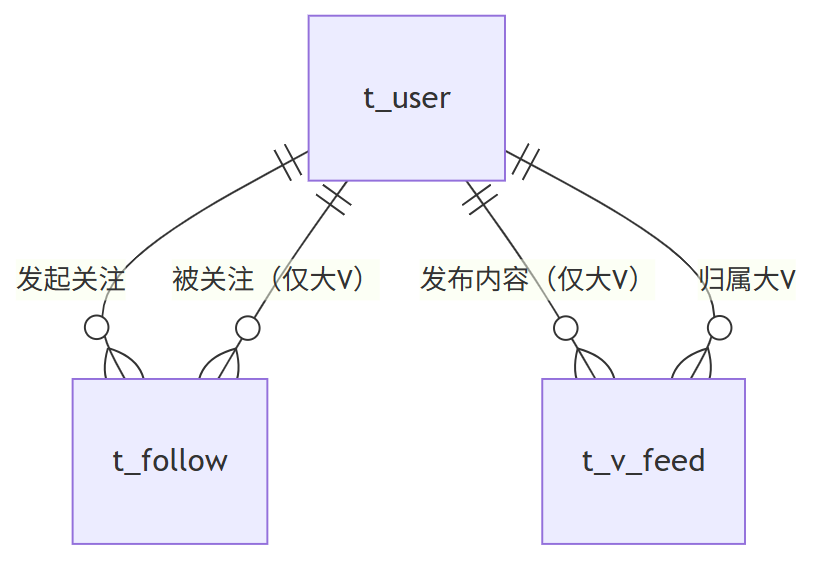
(3) 大 V 内容表(t_v_feed)
- 核心字段:内容 ID(主键)、发布大 V ID(索引)、内容文本、图片 / 视频链接、发布时间(索引)、点赞数、评论数、状态(是否有效)
- 作用:专门存储大 V 发布的内容,按大 V ID 与发布时间建立复合索引,适配拉取时的筛选需求
(4) 数据库关系图
2、Redis 存储架构设计
Redis 主要用于缓存热点数据,减少 MySQL 查询压力,适配拉模式下 “高频拉取” 的需求.
设计四类缓存结构:
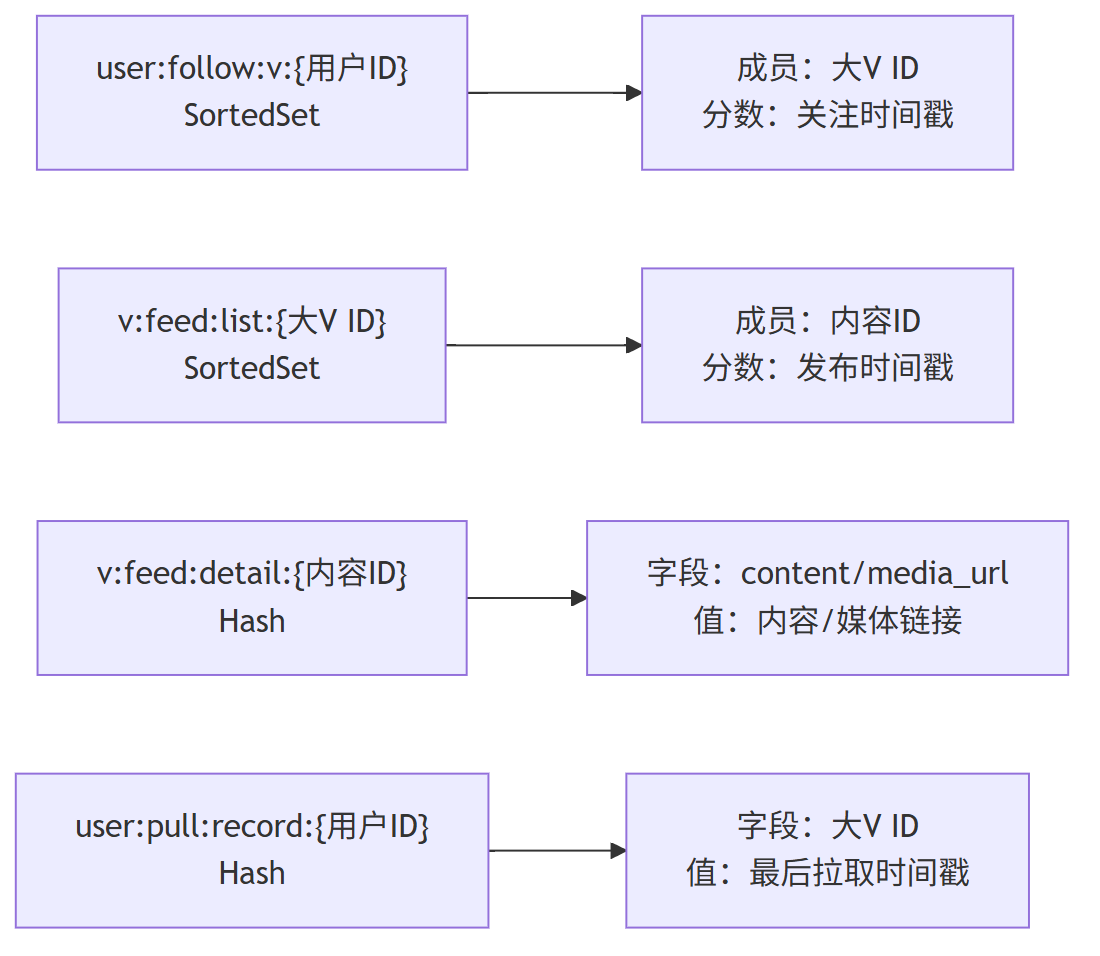
(1) 用户关注大 V 列表缓存
- 数据结构:SortedSet
- Key 格式:
user:follow:v:{用户ID} - 存储内容:成员为 “被关注大 V ID”,分数为 “关注时间戳”
- 作用:快速获取用户关注的大 V 列表,避免每次拉取时查询 MySQL,支持按关注时间排序筛选
(2) 大 V 内容列表缓存
- 数据结构:SortedSet
- Key 格式:
v:feed:list:{大V ID} - 存储内容:成员为 “大 V 发布的内容 ID”,分数为 “发布时间戳”
- 作用:缓存大 V 近期发布的内容(如近 7 天),用户拉取时优先从缓存获取,减少 MySQL 访问
(3) 大 V 内容详情缓存
- 数据结构:Hash
- Key 格式:
v:feed:detail:{内容ID} - 存储内容:字段包括 content(内容)、media_url(媒体链接)、publish_time(发布时间)、like_count(点赞数)等
- 作用:缓存内容详情,用户点击查看时直接返回,避免重复查询数据库
(4) 用户拉取记录缓存
- 数据结构:Hash
- Key 格式:
user:pull:record:{用户ID} - 存储内容:字段为 “大 V ID”,值为 “该大 V 内容的最后拉取时间戳”
- 作用:记录用户对每个大 V 的拉取进度,下次拉取时仅获取 “最后拉取时间之后” 的增量内容,提升效率
(5) Redis 存储关系图
三、核心流程设计
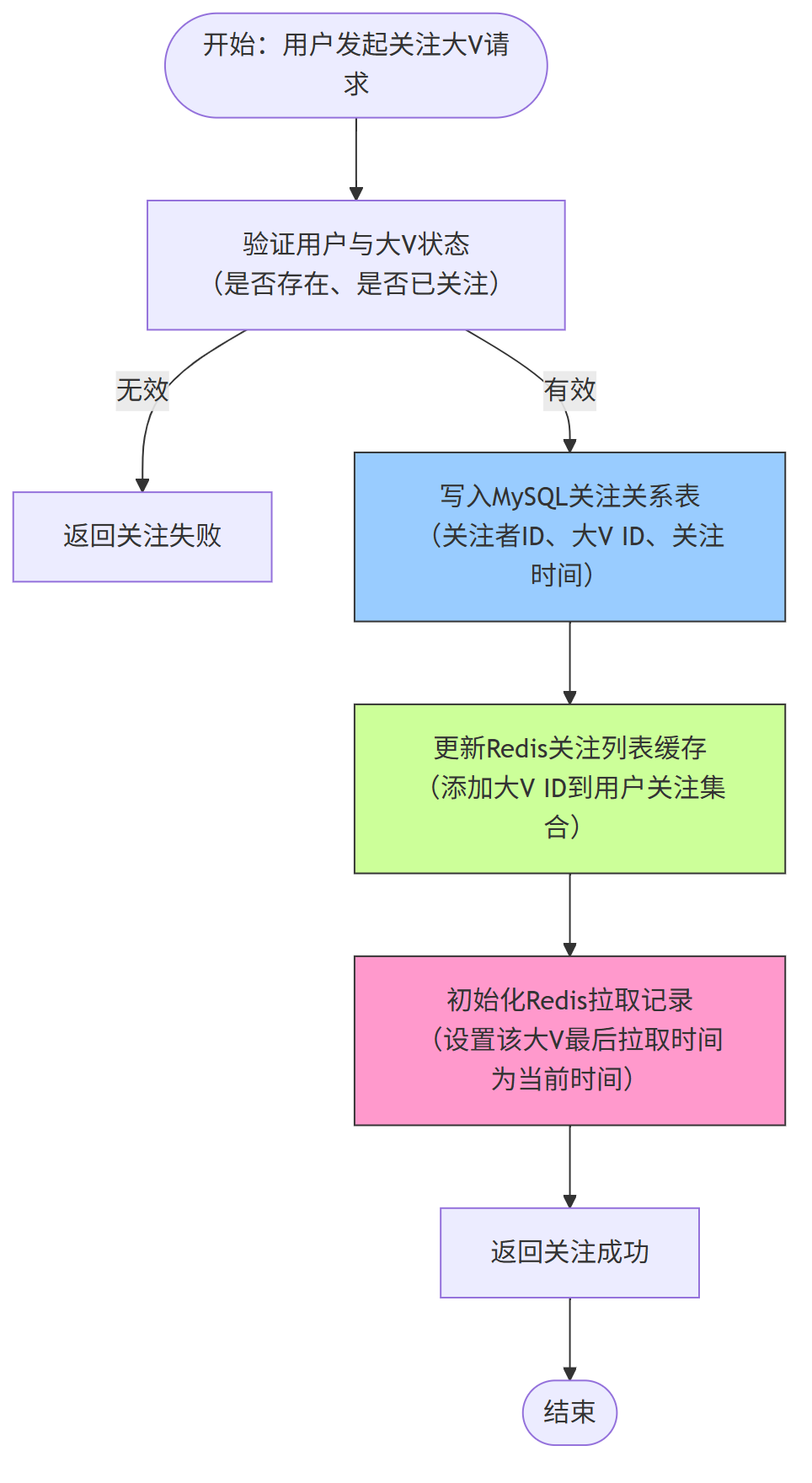
1、关注大 V 流程
用户关注大 V 时,需同步更新数据库与缓存,为后续拉取内容建立基础,流程如下:
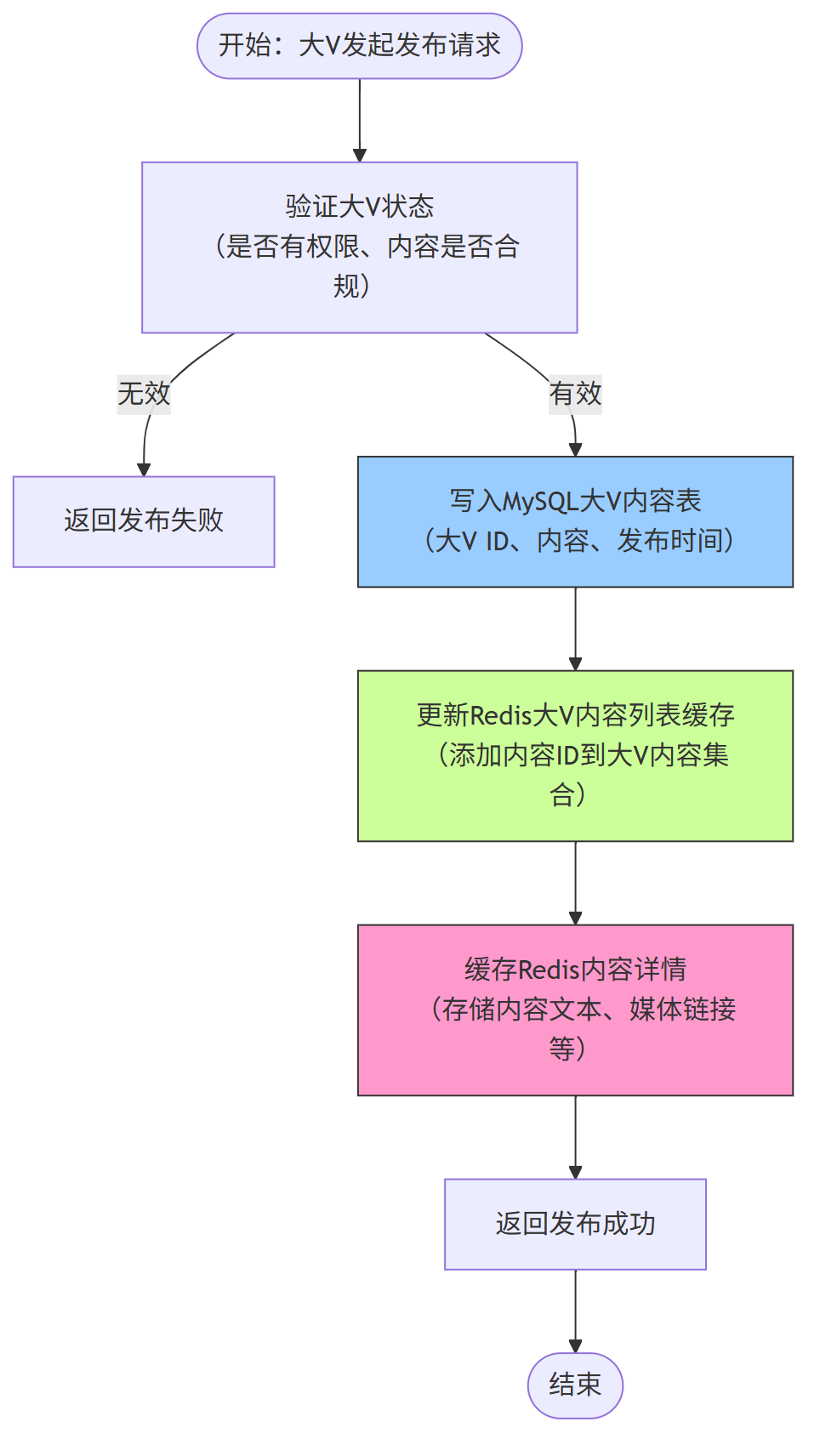
2、大 V 发布内容流程
大 V 发布内容时,仅需存储自身内容并更新缓存,无需推送,流程轻量化:
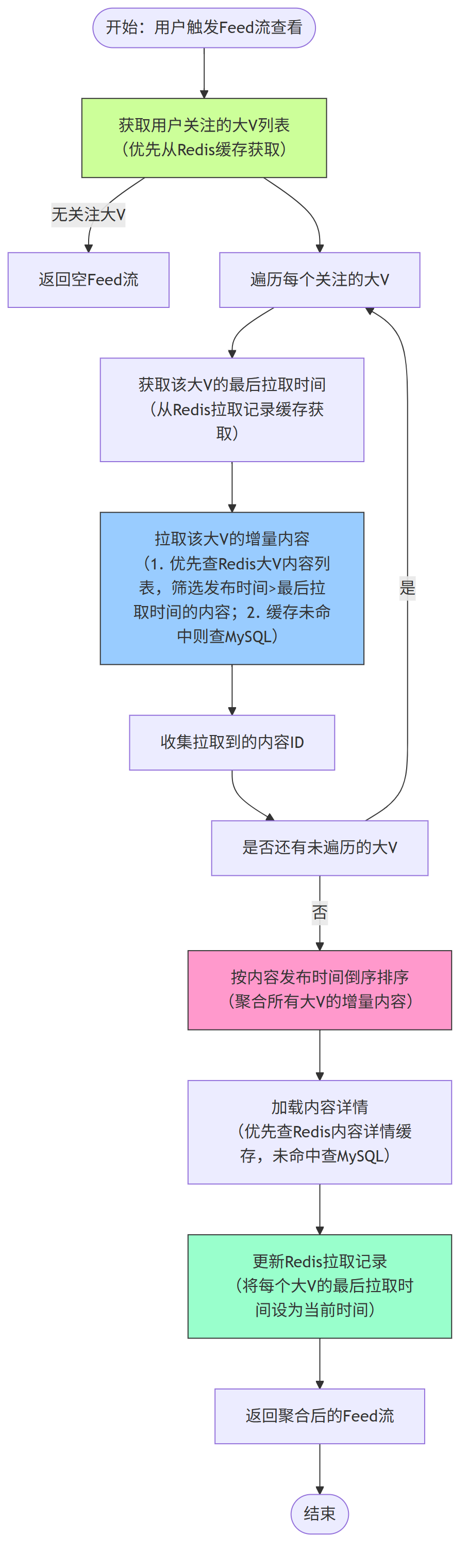
3、用户拉取 Feed 流核心流程
这是拉模式的核心流程,用户触发 “查看 Feed 流” 或 “下拉刷新” 时,系统按 “拉取 - 聚合 - 展示” 三步执行:
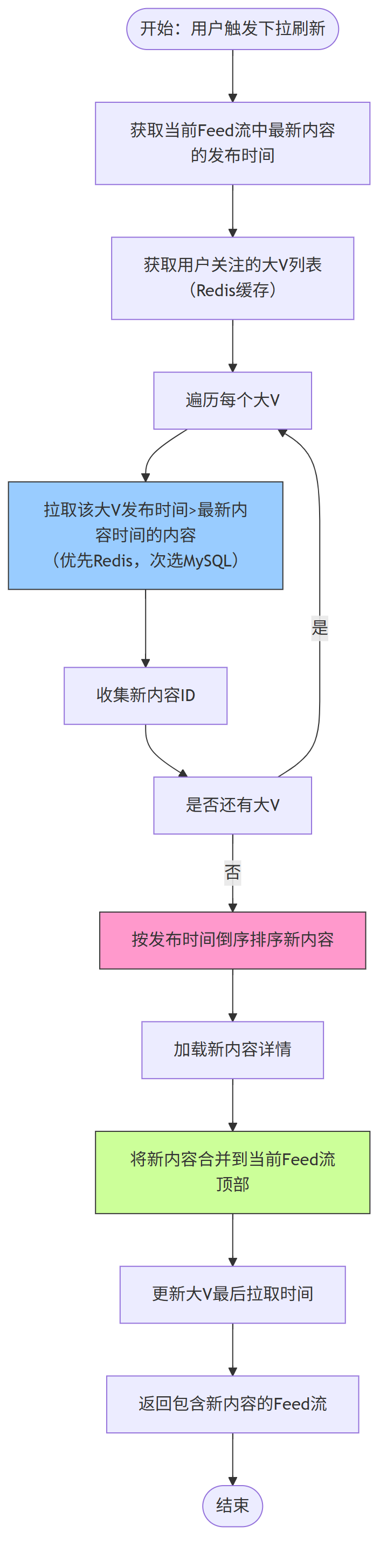
4、用户下拉刷新流程
针对大 V 内容时效性需求,下拉刷新流程是拉模式的高频场景,核心是 “增量拉取最新内容”:
四、 性能优化:应对拉模式下的读取压力
全大 V 场景中,用户拉取时需遍历多个大 V,需通过三方面优化提升响应速度:
(1) 分层缓存优化
- 一级缓存:用户端本地缓存(如 APP 内存),缓存最近查看的 20 条内容,减少重复拉取
- 二级缓存:Redis 大 V 内容列表缓存,仅保留大 V 近 3 天的内容,平衡缓存容量与命中率
- 三级缓存:MySQL 查询缓存,针对 “大 V ID + 发布时间范围” 的高频查询建立结果缓存
(2) 拉取范围控制
- 增量拉取:基于 “最后拉取时间” 仅拉取新增内容,避免每次拉取大 V 全部历史内容
- 数量限制:单次拉取每个大 V 的内容不超过 20 条,总聚合内容不超过 50 条,减少数据传输与排序耗时
(3) 异步预拉取
- 用户进入 Feed 流页面时,后台异步预拉取下一页内容,当用户滑动到底部时直接展示,提升流畅度
- 针对用户高频关注的前 5 个大 V,定时(如 1 分钟)异步拉取最新内容,缓存到 “用户专属预拉取缓存”
“拉取风暴” 问题介绍
拉模式(读扩散)虽规避了推模式的 “推送风暴”,但会因用户集中触发拉取操作,引发 “拉取风暴”.
什么是 “拉取风暴” ?—— 即短时间内大量并发拉取请求集中爆发,超出系统处理能力的性能风险。
其核心触发场景有三类:
-
一是热门大 V 发布热点内容后,数百万粉丝同步触发 “下拉刷新” 拉取新内容;
-
二是用户活跃高峰(如早 8 点、晚 8 点),大量用户集中打开 Feed 流拉取关注对象动态;
-
三是平台运营活动(如大 V 直播预告),引发定向拉取请求激增。
拉取风暴会导致连锁问题:
-
应用服务器被海量请求占满,线程池耗尽引发响应超时;
-
缓存层因热点大 V 的内容 Key 被高频访问,出现缓存击穿,进而冲击数据库;
-
数据库因 “大 V 内容查询” 的高频 SQL,导致 CPU、IO 利用率飙升,甚至触发锁等待,影响全库读写性能。
最终导致用户拉取内容加载缓慢、频繁失败,严重时引发服务级联降级。
第四章:推拉结合模式 Feed 流 (大 V 与小 V 共存场景)设计与实现 方案
一、推拉结合模式(写扩散+ 读扩散)概述
第一、模式定义
推拉结合模式是针对大 V 与小 V 共存场景设计的混合策略:
-
对小 V 采用推模式(写扩散),主动推送内容到用户时间线;
-
对 头部大 V 采用拉模式(读扩散),用户查看时再实时拉取内容。
这种模式既能发挥推模式的实时性优势,又能避免头部大 V 带来的推送压力,完美适配混合场景的内容分发需求。
第二、场景适配优势
在大 V 与小 V 共存场景中,推拉结合模式的核心优势体现在三方面:
- 差异化处理:根据创作者粉丝量和用户关注度动态选择策略,小 V 全量推送,头部大 V 按需拉取
- 资源平衡:避免头部大 V 的 "推送风暴",同时保证中小 V 内容的实时触达
- 体验优化:用户关注的核心创作者内容实时可见,头部大 V 内容按需加载,兼顾时效性与系统性能
二、核心存储架构设计
第一、MySQL 数据库设计
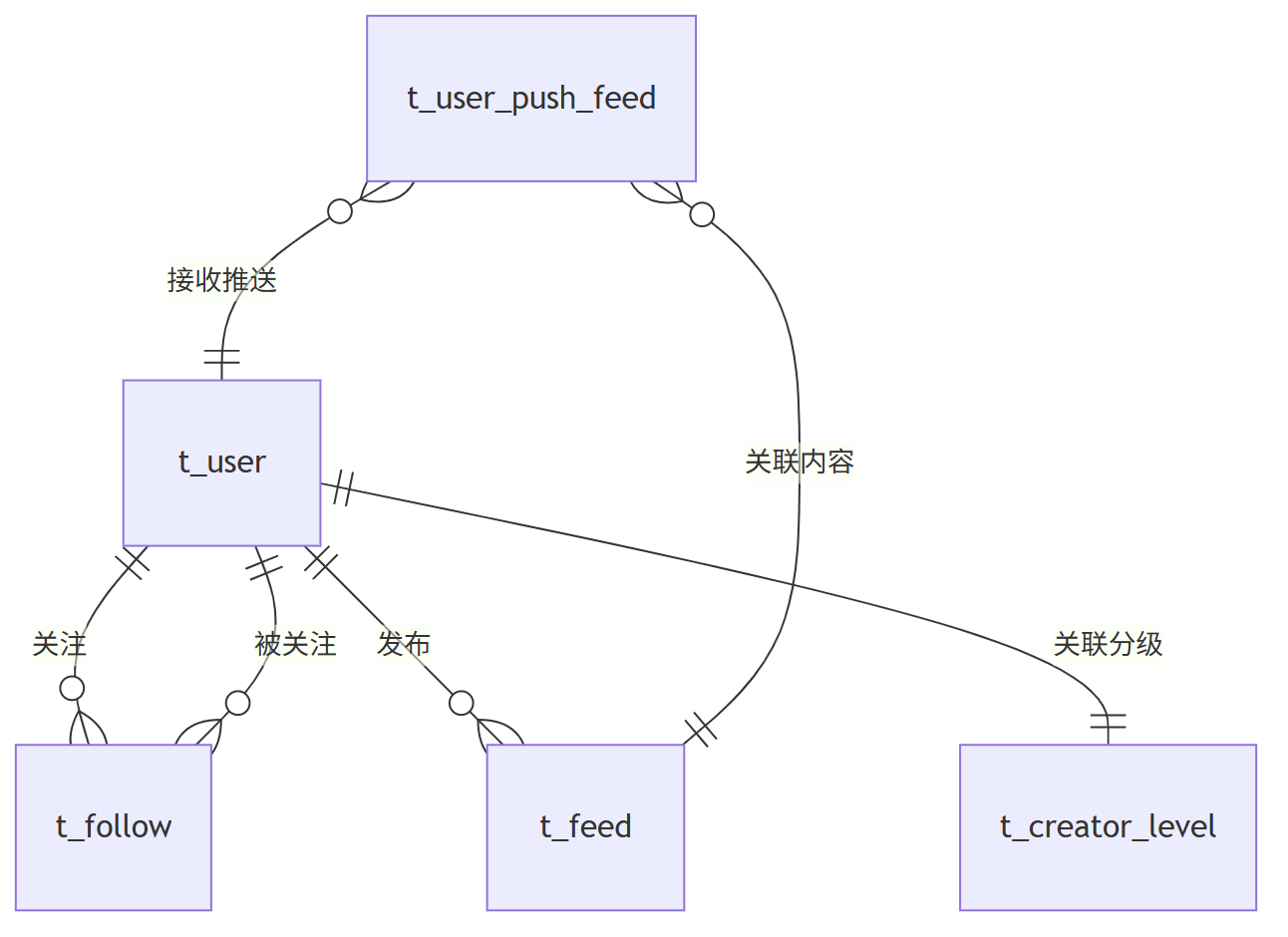
针对混合场景的特性,设计五类核心表结构,支撑差异化策略的灵活实施:
(1) 用户表(t_user)
- 核心字段:用户 ID(主键)、用户名、用户类型(普通 / 小 V / 大 V)、粉丝量、创建时间、状态
- 作用:存储用户基础信息,通过粉丝量阈值(如 10 万)区分小 V 与大 V,为策略选择提供依据
(2) 关注关系表(t_follow)
- 核心字段:关系 ID(主键)、用户 ID(索引)、被关注者 ID(索引)、关注时间、互动频率、拉取策略(强制拉取 / 默认)、最后拉取时间
- 作用:记录用户关注关系,对头部大 V 标记 "强制拉取",对其他创作者根据互动频率动态调整
(3) 内容表(t_feed)
- 核心字段:内容 ID(主键)、创作者 ID(索引)、内容类型、内容文本、媒体链接、发布时间(索引)、热度值、状态
- 作用:存储所有创作者发布的内容,按创作者 ID 和发布时间建立复合索引,适配各类查询需求
(4) 用户推送内容表(t_user_push_feed)
- 核心字段:ID(主键)、用户 ID(索引)、内容 ID(索引)、推送时间、阅读状态
- 作用:存储推模式下的内容关联关系,仅记录小 V 的推送记录
(5) 创作者分级表(t_creator_level)
- 核心字段:创作者 ID(主键)、粉丝量、内容产量、推送阈值、当前策略(默认推 / 默认拉)、更新时间
- 作用:动态记录创作者分级信息,设置推送阈值(如粉丝量超 50 万自动转为默认拉模式)
(6) 数据库关系图
第二、Redis 存储架构设计
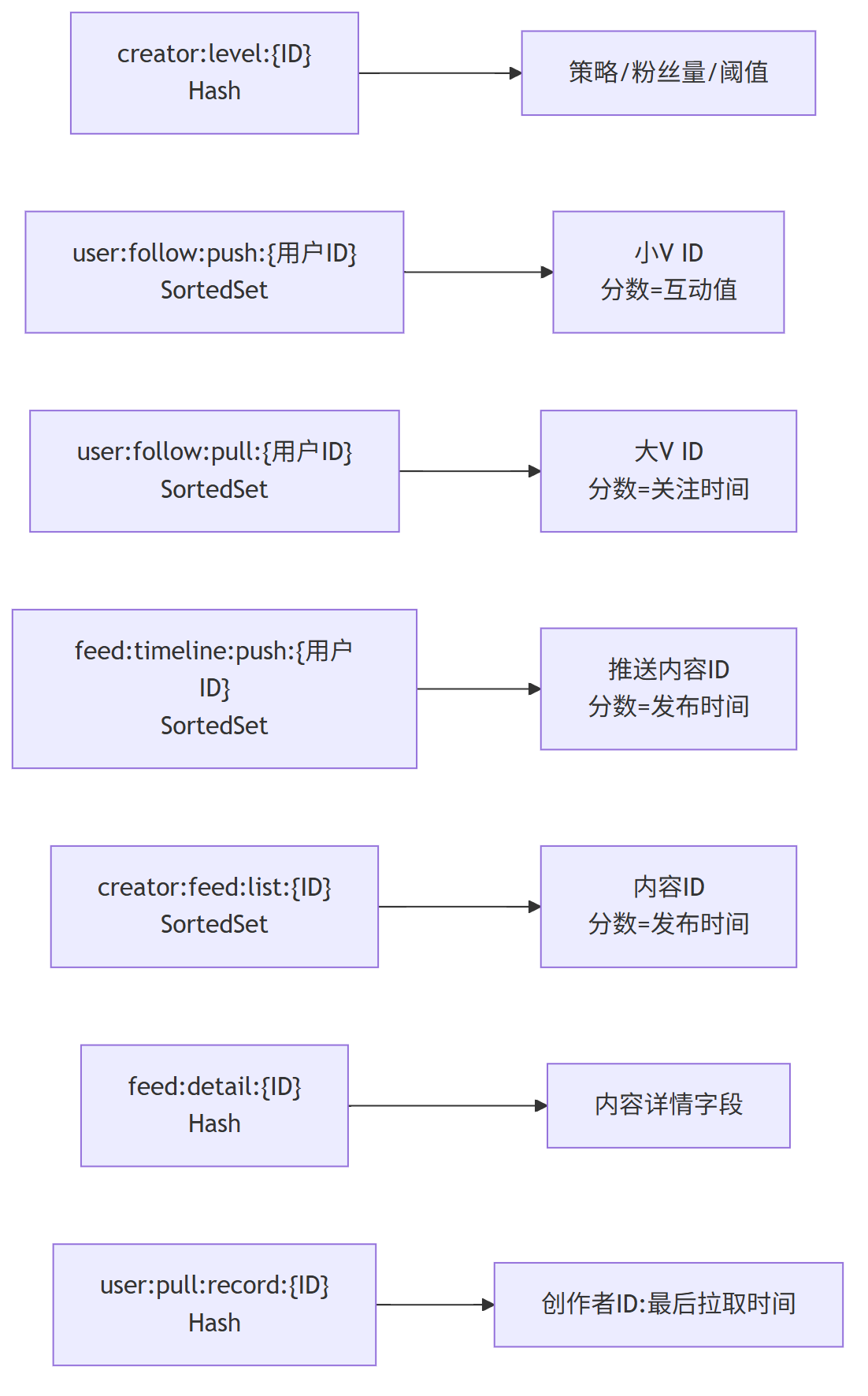
Redis 缓存需同时支撑推模式的主动推送和拉模式的实时拉取,设计七类缓存结构:
(1) 创作者分级缓存
- 数据结构:Hash
- Key 格式:
creator:level:{创作者ID} - 存储内容:字段包括 fans_count(粉丝量)、strategy(默认策略)、push_threshold(推送阈值)
- 作用:快速判断创作者适用的默认策略,避免每次查询数据库
(2) 用户关注列表缓存(分类型)
- 推模式列表:SortedSet,Key 为
user:follow:push:{用户ID},存储小 V ,分数为互动值 - 拉模式列表:SortedSet,Key 为
user:follow:pull:{用户ID},存储头部大 V ID,分数为关注时间 - 作用:快速区分不同策略的关注对象,提升处理效率
(3) 推模式时间线缓存
- 数据结构:SortedSet
- Key 格式:
feed:timeline:push:{用户ID} - 存储内容:成员为推模式内容 ID,分数为发布时间戳
- 作用:存储主动推送的内容,支持快速查询
(4) 创作者内容列表缓存
- 数据结构:SortedSet
- Key 格式:
creator:feed:list:{创作者ID} - 存储内容:成员为创作者发布的内容 ID,分数为发布时间戳
- 作用:缓存创作者内容列表,适配拉模式下的实时拉取
(5) 内容详情缓存
- 数据结构:Hash
- Key 格式:
feed:detail:{内容ID} - 存储内容:字段包括 content、media_url、author_id、publish_time 等
- 作用:统一缓存内容详情,减少数据库访问
(6) 用户拉取记录缓存
- 数据结构:Hash
- Key 格式:
user:pull:record:{用户ID} - 存储内容:字段为拉模式创作者 ID,值为最后拉取时间戳
- 作用:记录拉取进度,实现增量拉取
(7) 推送状态缓存
- 数据结构:Set
- Key 格式:
user:push:status:{用户ID} - 存储内容:已推送的内容 ID
- 作用:避免重复推送同一内容
(8) Redis 存储关系图
三、核心流程设计
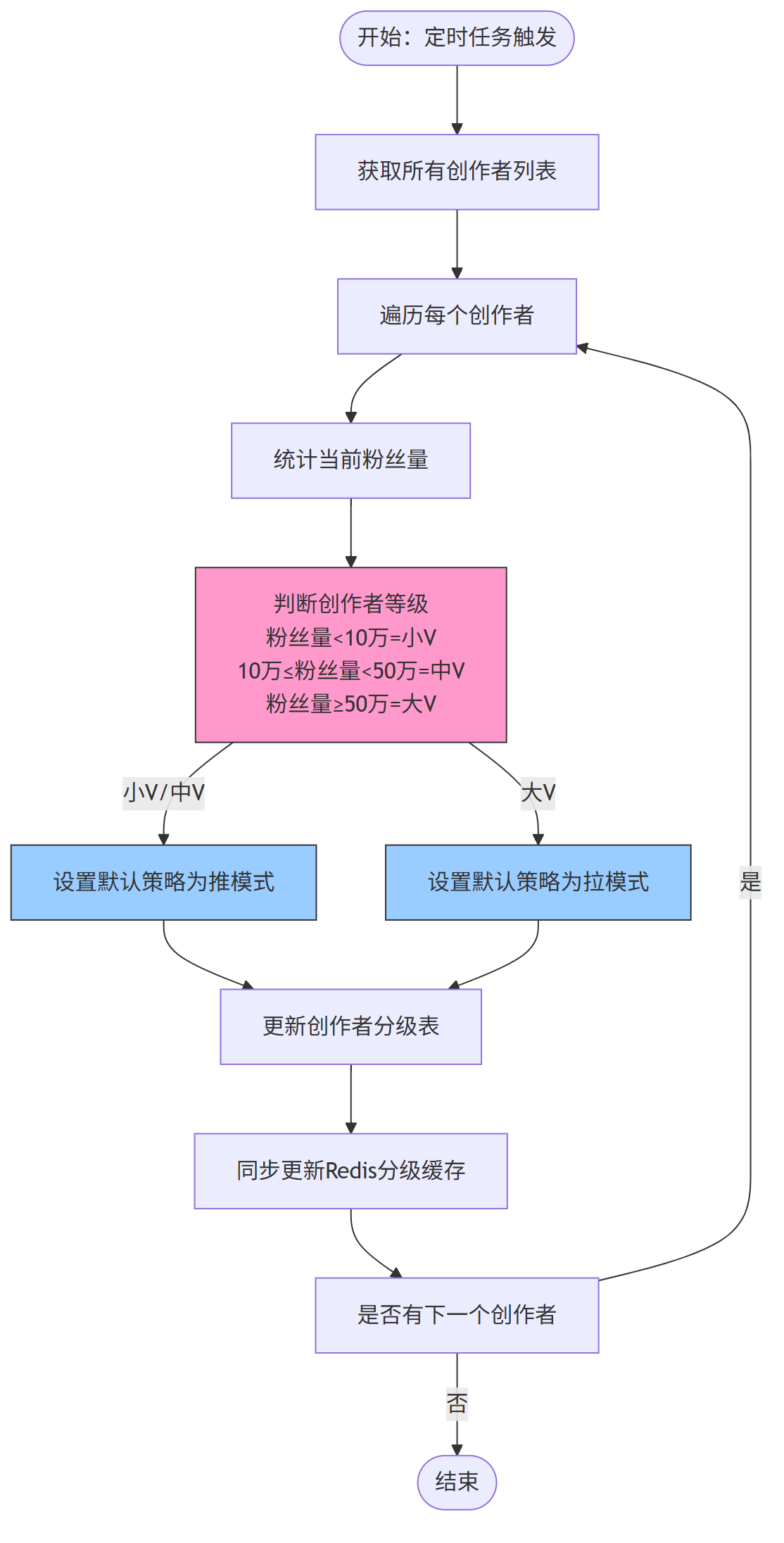
第一、大v 与 小v 划分流程
系统定期根据创作者粉丝量 自动划分 推拉 默认策略,流程如下:
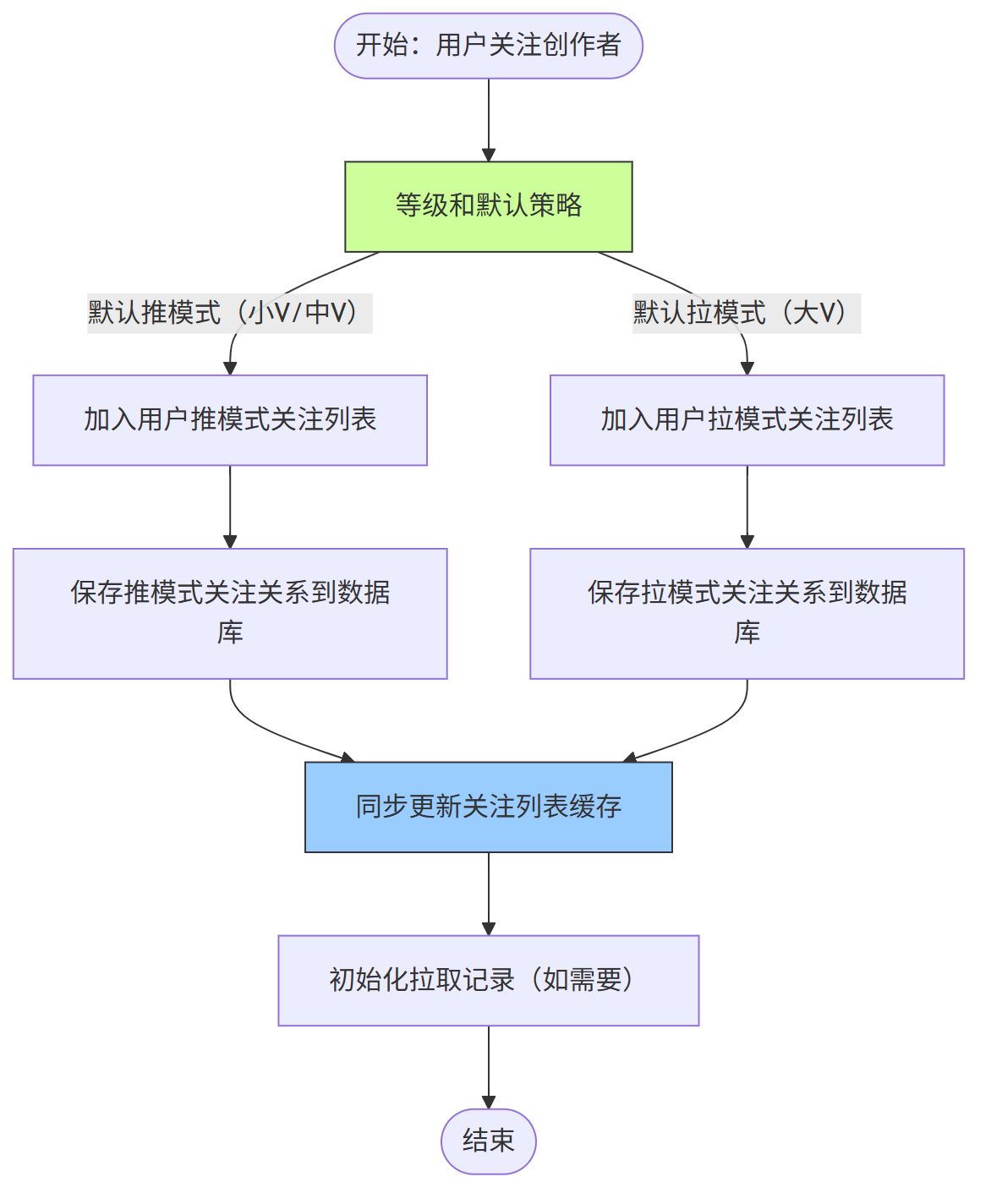
第二、用户关注策略调整流程
用户关注创作者时,系统结合创作者默认策略和用户偏好,确定最终互动策略:
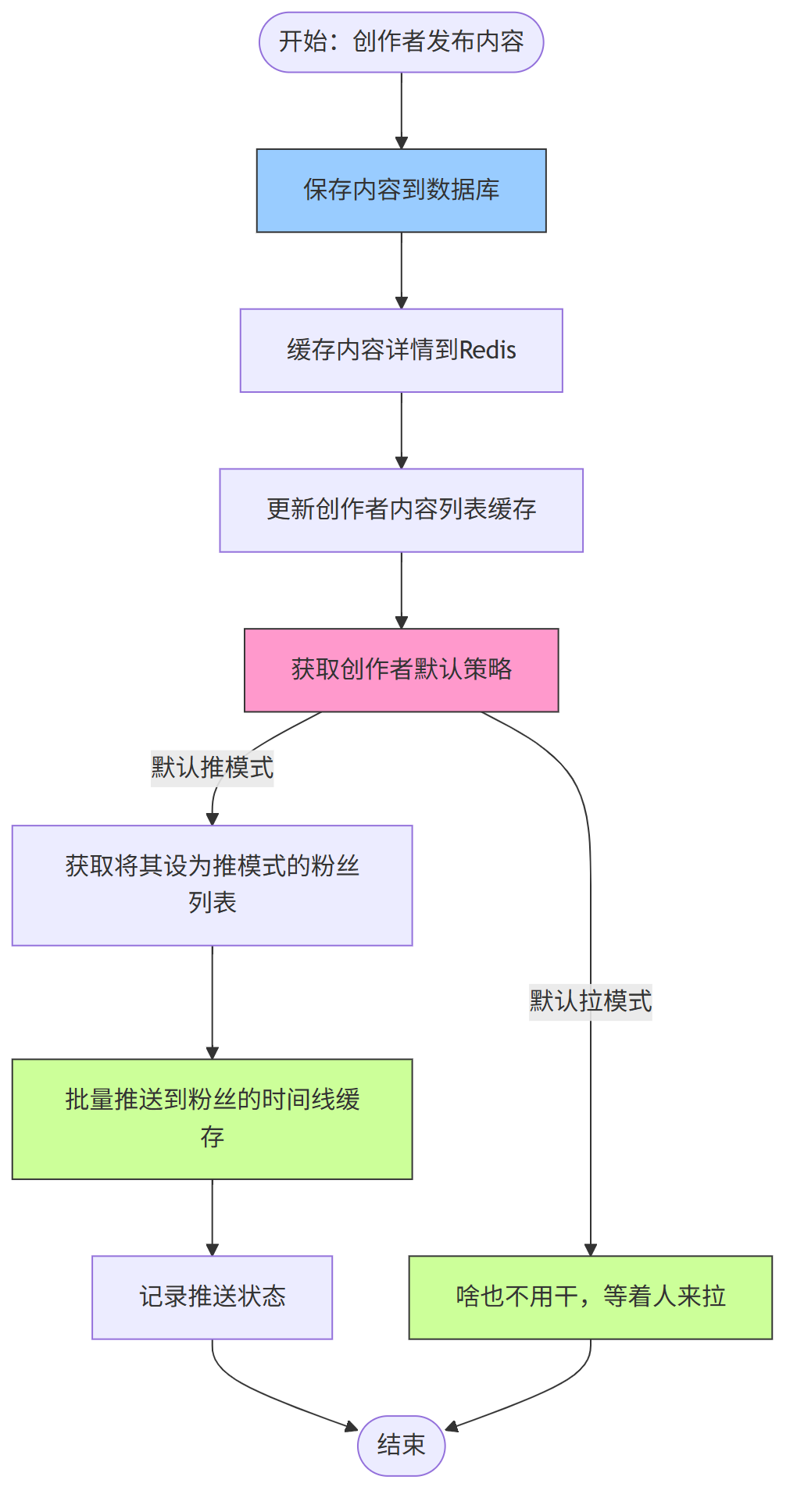
第三、内容发布与分发流程
创作者发布内容时,系统根据其默认策略和粉丝的关注策略,混合使用推 / 拉模式分发:
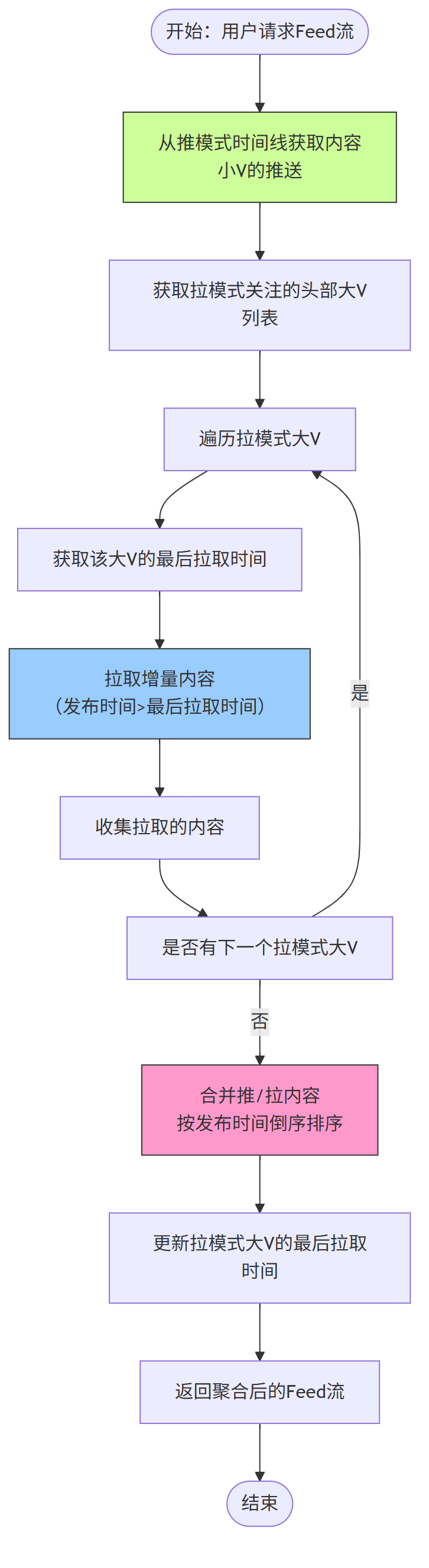
第四、用户获取 Feed 流流程
用户查看 Feed 流时,系统同时处理 推模式缓存内容 和 拉模式实时拉取内容,聚合后返回:
第五、策略动态调整流程
系统根据用户互动行为和创作者粉丝变化,动态调整推拉策略:
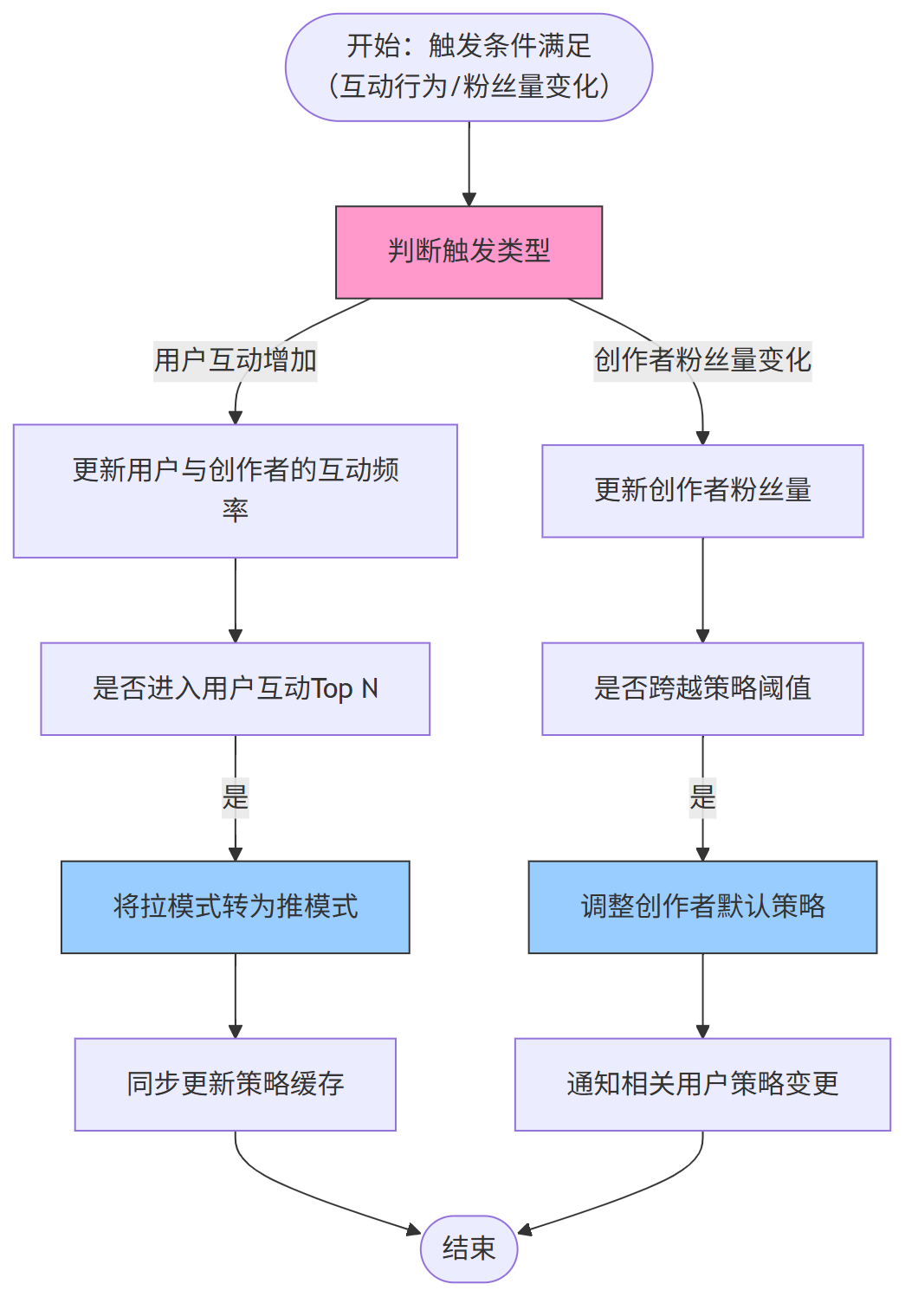
四、 大 V 与小 V 共存场景 (推拉结合) 性能优化
针对混合场景的复杂需求,从四个维度优化系统性能:
(1) 推送优化
- 分级推送:小 V 内容实时推送,中 V 内容批量推送(每 5 分钟一批),减少推送频次
- 粉丝分片:对中 V 采用粉丝分片推送,每批处理 2000 粉丝,避免瞬时压力
- 智能过滤:对 30 天未活跃用户暂停推送,对低互动用户降低推送频率
(2) 拉取优化
- 预拉取机制:用户进入 Feed 流页面时,异步预拉取前 5 个头部大 V 的最新内容
- 结果缓存:缓存拉模式聚合结果(5 分钟有效期),减少重复计算
- 热点缓存:对全网热度 Top 50 大 V,在应用服务器本地缓存其内容列表
(3) 存储优化
- 内容分表:按创作者 ID 哈希分片存储内容表,降低单表数据量
- 推送表分区:按用户 ID 范围分区存储推送记录表,提升查询效率
- 历史数据归档:超过 90 天的内容迁移至冷存储,仅保留元数据
(4) 计算优化
- 异步聚合:拉模式内容聚合在后台异步完成,前端先展示推模式内容,再增量加载拉模式内容
- 预计算排序:定期预计算用户 Feed 流的排序结果,缓存热点用户的聚合结果
第五章:100WQPS 热点, 如何 抵抗雪崩 ?
让“鹿晗官宣”式的 100 WQPS 变成 “湖面涟漪”
一、雪崩是如何发生的(100 W QPS 视角)
| 阶段 | 现象 | 触发点 |
|---|---|---|
| ① 流量突袭 | 热点关键词引爆,瞬间 100 W QPS 涌入 Feed 接口 | 大 V 发布爆炸性内容 |
| ② 缓存击穿 | 聚合结果 5 min 过期,百万请求同时回源 | 缓存 Key 瞬时失效 |
| ③ 存储层放大 | 每 QPS 需拉 N 个大 V,MySQL 连接池瞬间打满 | 拉模式放大系数 10× |
| ④ 消息队列积压 | 推模式粉丝分片重试,MQ 堆积,延迟飙高 | 消费者速度 < 生产者速度 |
| ⑤ 线程池耗尽 | 异步聚合线程池被阻塞,拒绝请求,用户重试再放大 | 雪崩正循环 |
二、防雪崩总体思路
先降流量 → 再保缓存 → 再护存储 → 最后兜底
四层防线,层层熔断,把 100 W QPS 消弭于无形。
三、防线详解与流程图
3.1 流量入口层:1 秒限流 + 请求降级
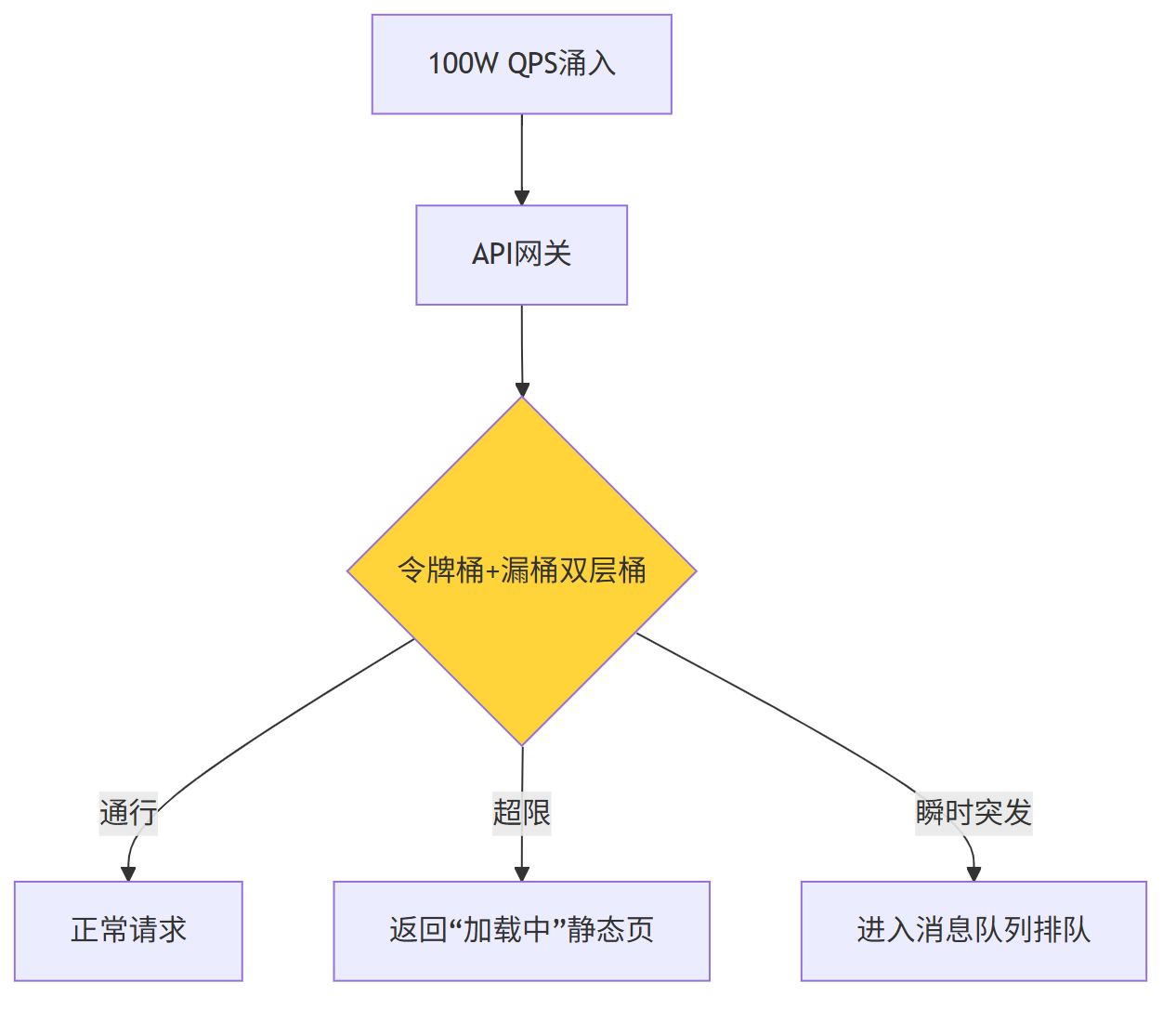
| 策略 | 参数 | 效果 |
|---|---|---|
| 令牌桶 | 80 W/s | 保证系统不过载 |
| 漏桶 | 匀速 80 W/s | 削平瞬时毛刺 |
| 排队 | 最大 20 W 排队 | 用户 3s 内收到结果,避免重试 |
3.2 缓存层:双 Key + 异步续期 + 空值保护
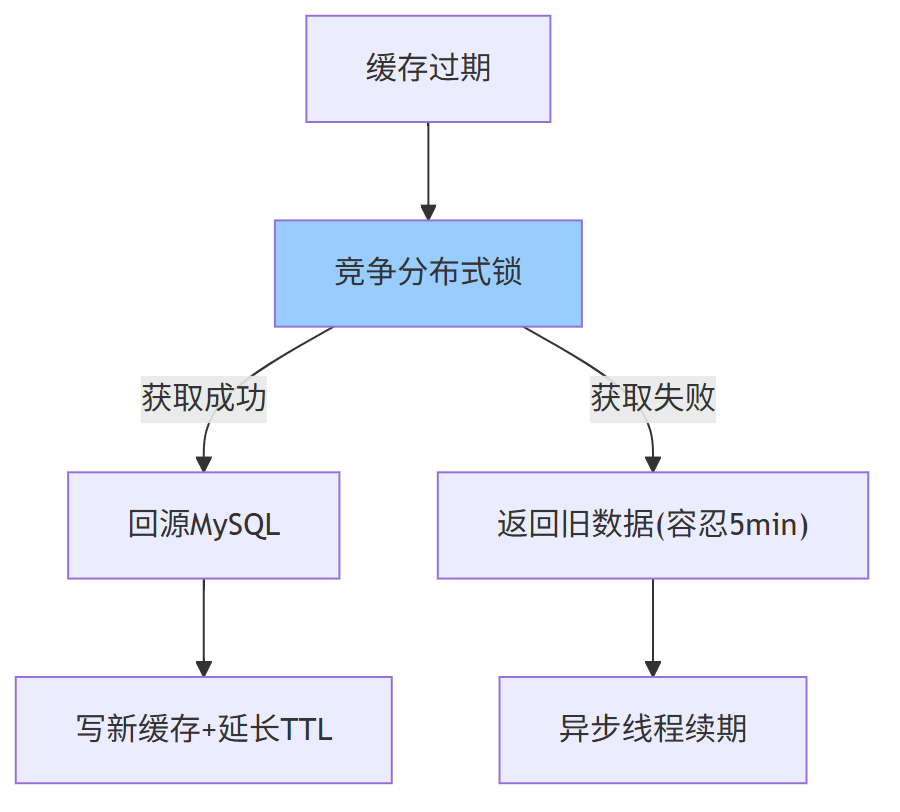
| 技法 | 说明 | 雪崩缓解度 |
|---|---|---|
| 双 Key 冗余 | 主 Key 3 min,备 Key 8 min,错开失效 | 80% 请求命中备 Key |
| 本地互斥锁 | 单机单线程回源,其余线程等待 50 ms | 回源并发从 100 W → 100 |
| 空对象缓存 | 创作者无内容也缓存短 TTL 30 s | 避免穿透 DB |
3.3 存储层:增量拉取 + 连接池隔离 + 热点 SQL 熔断
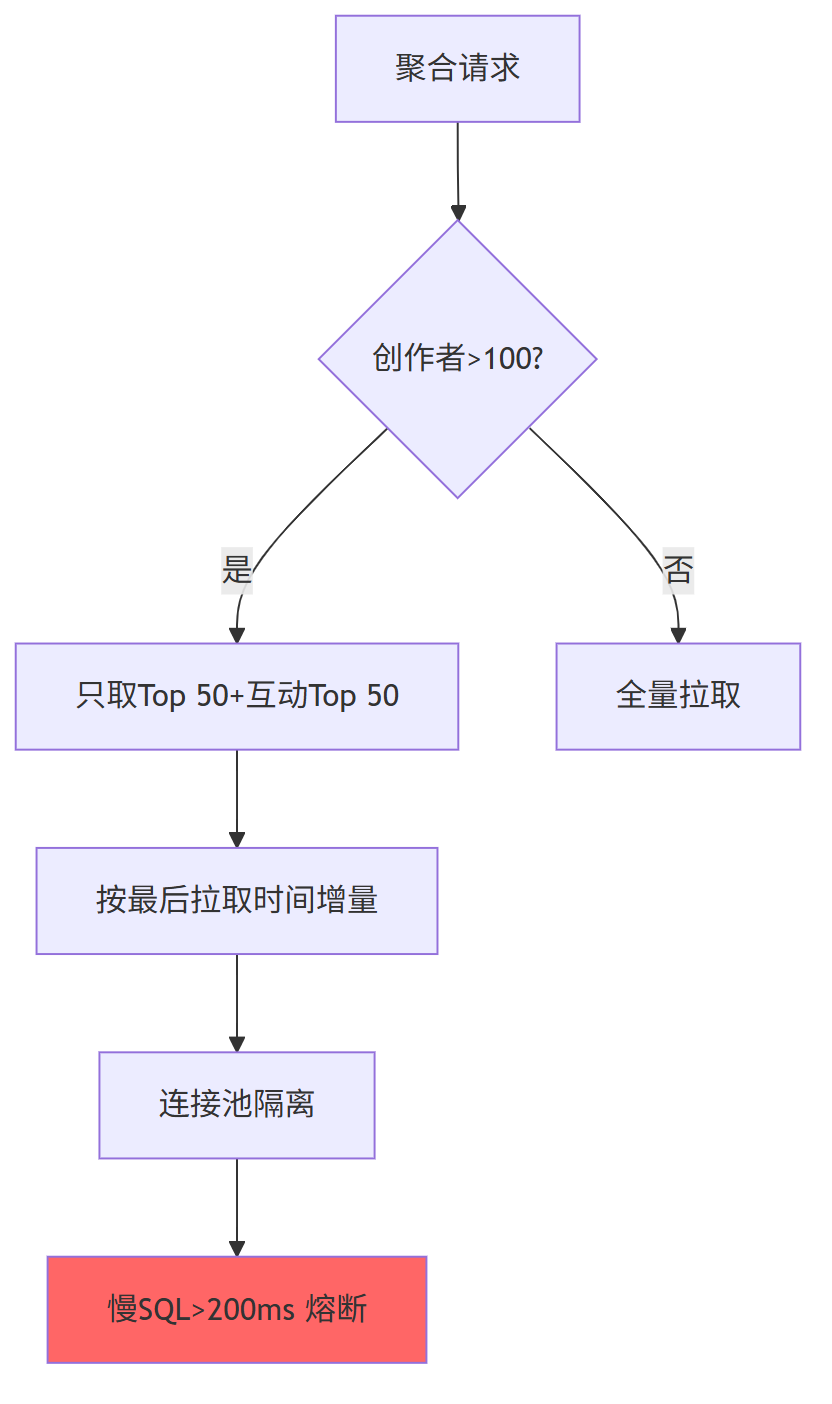
| 参数 | 值 | 目的 |
|---|---|---|
| 增量时间窗 | 5 min | 扫描数据量从百万级 → 千级 |
| 连接池拆分 | 拉模式独立池,最大 200 连接 | 保护主池不被拉死 |
| SQL 熔断 | 超时 200 ms 直接返回空列表 | 防止 DB 被拖垮 |
3.4 消息队列层:背压机制 + 分级队列
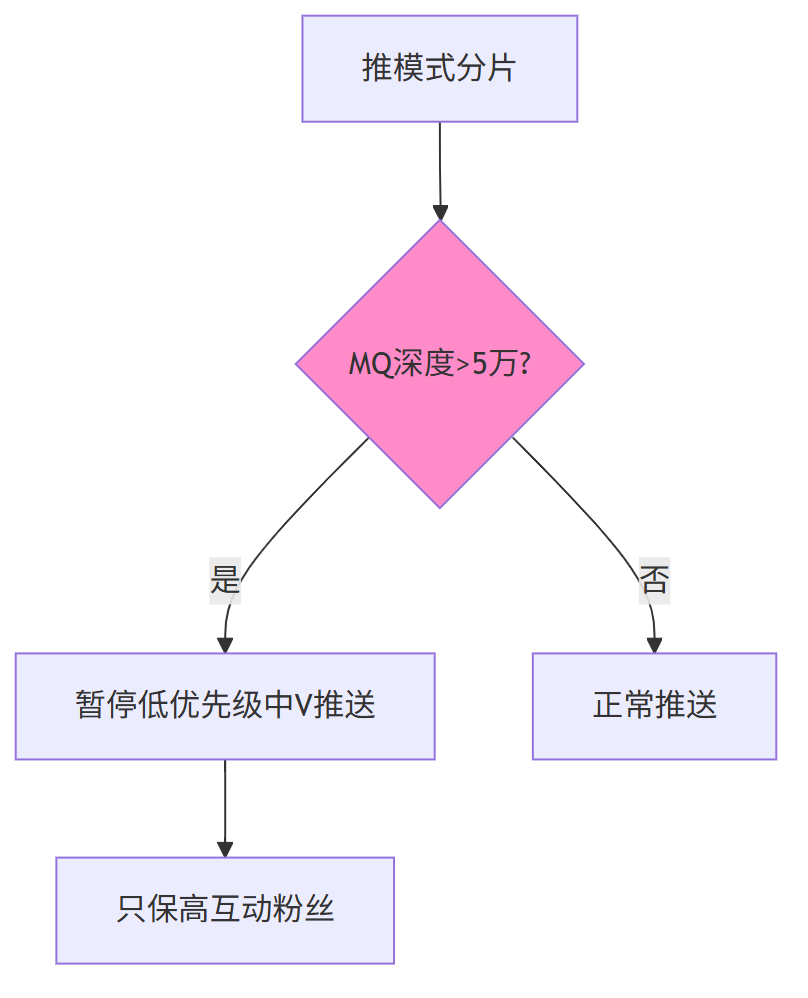
| 队列 | 用途 | 背压触发 |
|---|---|---|
| 高优队列 | 小 V 实时推送 | 不限制 |
| 中优队列 | 中 V 5 min 批量 | 深度>5万 暂停 |
| 低优队列 | 冷启动补推 | 深度>10万 丢弃 |
3.5 计算层:异步聚合 + 结果预计算 + 用户级限速
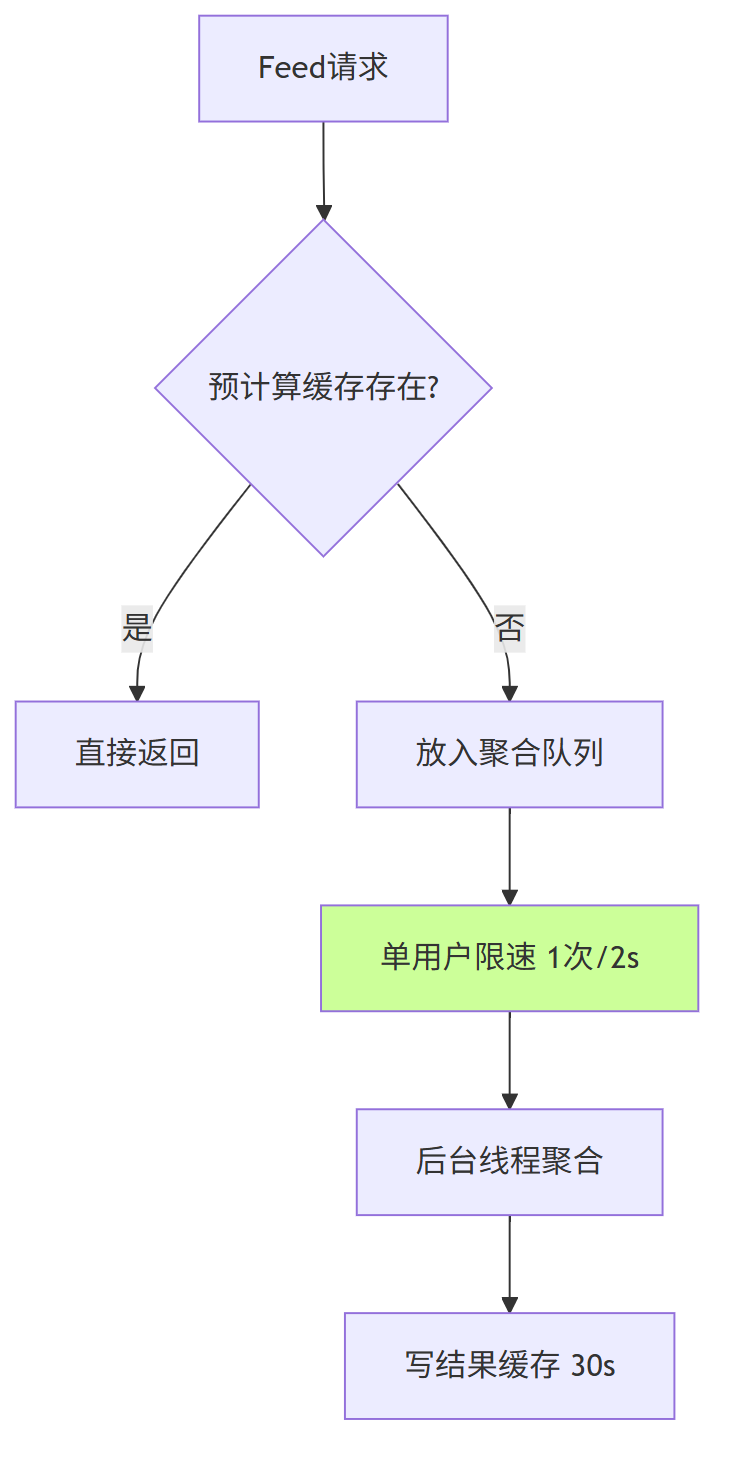
| 机制 | 参数 | 效果 |
|---|---|---|
| 单用户限速 | 2 s 内只接受一次聚合 | 避免同用户重复刷接口 |
| 预计算缓存 | 热点用户 30 s | 80% 明星粉丝请求命中 |
| 线程池隔离 | 聚合线程池独立 | 即使阻塞也不影响写线程 |
四、综合逃生舱:多级降级顺序
| 级别 | 触发条件 | 降级表现 | 用户体验 |
|---|---|---|---|
| 1 级 | CPU>90% 或 DB 连接>80% | 仅返回推模式内容,拉模式返回空 | 时间线少部分内容,可接受 |
| 2 级 | CPU>95% 或 MQ 堆积>20万 | 全量走静态缓存(5 min 前数据) | 页面静止 5 min,仍可刷 |
| 3 级 | 整体错误率>20% | 返回“服务繁忙,稍后再试”静态页 | 防止雪崩正循环 |
五、容量预估与真实验证
| 场景 | 指标 | 推拉结合+上述优化 | 纯推模式 | 纯拉模式 |
|---|---|---|---|---|
| 热点发布 | 写入峰值 | 8 W/s(中V分片+限流) | 100 W/s 雪崩 | 0 |
| 热点阅读 | 缓存命中率 | 94% | 50% | 70% |
| DB 峰值连接 | 热点 30 min | 6 k | 50 k 打满 | 80 k 打满 |
| 用户侧 P99 | 延迟 | < 300 ms | > 5 s 超时 | > 3 s |
...................由于平台篇幅限制, 剩下的内容(5000字+),请参参见原文地址
原始的内容,请参考 本文 的 原文 地址
本文 的 原文 地址