 本文是 ES 备份的镜像使用篇,主要介绍了 snapshot 的备份恢复原理和使用细节。
本文是 ES 备份的镜像使用篇,主要介绍了 snapshot 的备份恢复原理和使用细节。上一篇文章中,我们简要的列举了 Elasticsearch 备份 主要的几个方案,比对了一下各个方案的实现原理、优缺点和适用的场景。现在我们来看看 ES 自带的镜像备份方案。
1. 镜像备份
在开始研究镜像备份之前,我先抛三个问题:
- ES 镜像备份是怎么实现增量备份的?
- 历史镜像清理维护是怎么做到保存完整数据的?
- 增量恢复要怎么操作的?
2. 镜像的准备条件
在做镜像备份之前,先要为 ES 注册一个镜像仓库,即 repository。目前 ES 支持的仓库类型有:
| Respository | 配置类型 |
|---|---|
| Shared file system | "type" : "fs" |
| Read-only URL | "type": "url" |
| S3 | "type": "s3" |
| HDFS | "type": "hdfs" |
| Azure | "type": "azure" |
| Google Cloud Storage | "type": "gcs" |
注意: S3, HDFS, Azure and GCS 需要安装相应的插件。
那我们注册一个 S3 插件并使用 MinIO 来做仓库进行测试吧。
MinIO 的安装配置在这里简略了,从安装插件开始。
# 插件安装 在elasticsearch/bin目录下
./bin/elasticsearch-plugin install repository-s3# 添加访问账号,并reload
bin/elasticsearch-keystore add s3.client.default.access_key
bin/elasticsearch-keystore add s3.client.default.secret_keyPOST /_nodes/{node_id}/reload_secure_settings# 注册 repository
PUT _snapshot/my-minio-repository
{"type": "s3","settings": {"bucket": "es-bucket","endpoint": "http://127.0.0.1:9002","compress": true}
}
3. 备份流程
现在我们来看看整个镜像备份的流程,在这里我们使用 sample_data_flights 进行备份测试(为了方便测试比对,我们将该索引主分片设置为 1)。
3.1 首次备份
镜像快照是基于快照开始时间的数据文件备份。
snapshot 备份速度的主要影响参数是 max_snapshot_bytes_per_sec,是单节点数据备份的最快速度,默认为每秒 40mb,可以结合集群磁盘性能在仓库注册时做调整。
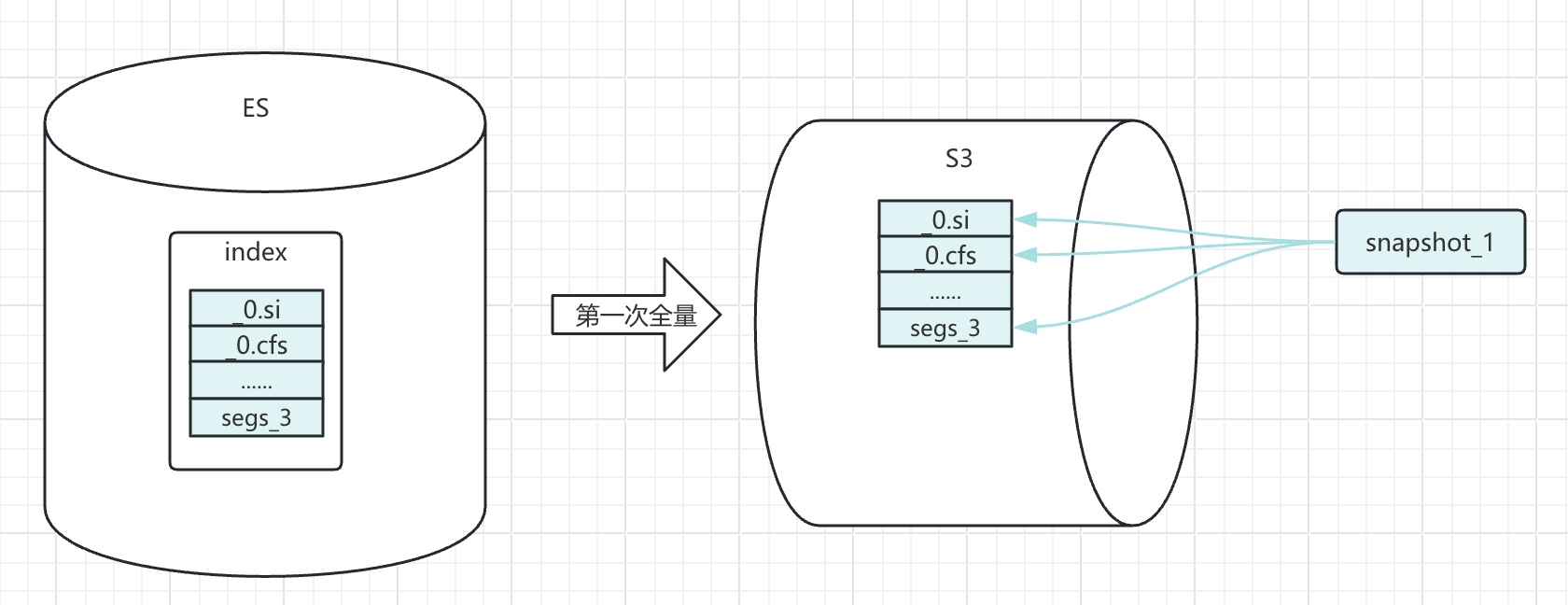
这里就是将 sample_data_flights 数据文件完整的放入 MinIO 存储中。可以查看系统上的文件进行验证。
操作命令:
# 第一次镜像名称设置为 snapshot_1
PUT _snapshot/minio-repository/snapshot_1
{
"indices": "sample_data_flights",
"ignore_unavailable": true,
"include_global_state": false,
"partial": false
}
在 data 目录下去寻找索引的 uuid 能找到对应的数据文件
# pwd
/data/nodes/0/indices/cv8DxU5BTfKB5SnI0ubVtQ/0/index
# ls -lrth
total 5.7M
-rw-rw-r-- 1 infini infini 0 Aug 17 13:17 write.lock
-rw-rw-r-- 1 infini infini 395 Aug 17 13:25 _0.si
-rw-rw-r-- 1 infini infini 5.7M Aug 17 13:25 _0.cfs
-rw-rw-r-- 1 infini infini 405 Aug 17 13:25 _0.cfe
-rw-rw-r-- 1 infini infini 321 Aug 17 13:30 segments_3而在 MinIO 中,我们也可以找到大小相应的数据文件,注意一下这里的文件时间是备份的时间点。
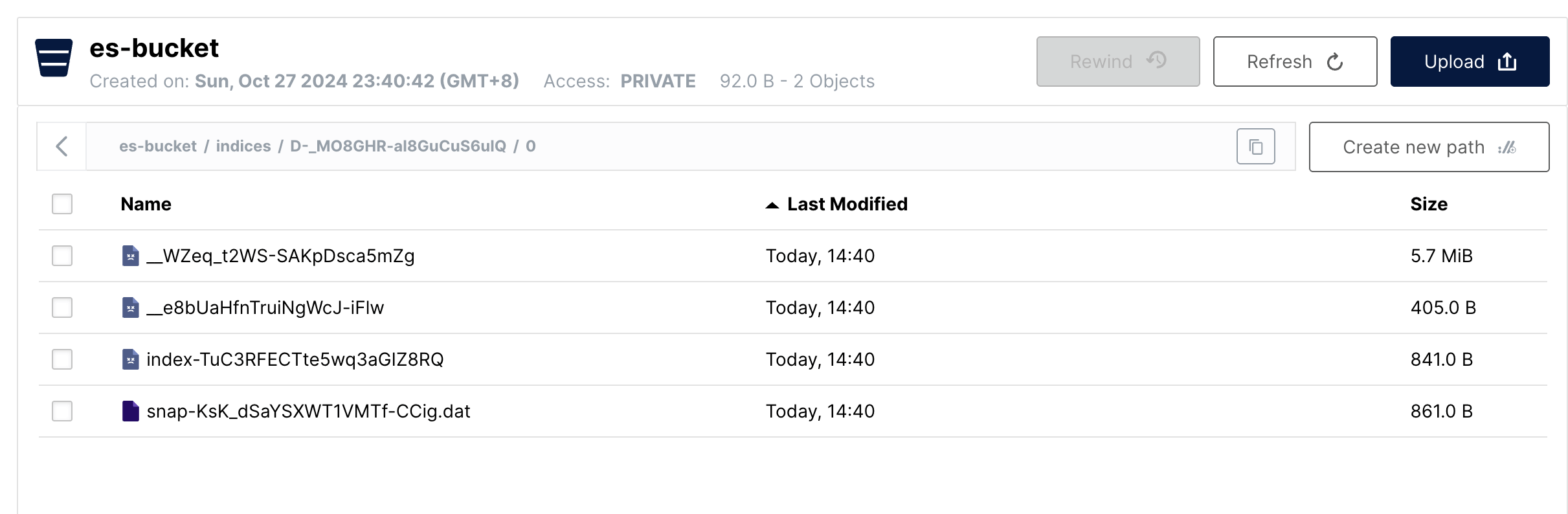
简化理解,我们把快照备份开始后的数据文件变化认为不会在本次快照备份之内。
3.2 增量备份
在同一备份仓库中为同一索引创建第二次快照时,Elasticsearch 并不会复制所有数据,而是通过校验和精准识别出哪些文件发生了变化,仅备份这些增量文件。该机制的巧妙之处在于,每次快照并非简单追加文件,而是会维护一个独立的文件关系映射,构成该时间点完整数据所需的全部文件(包括来自之前快照的未变文件),从而保证了每次快照的独立性和可恢复性。
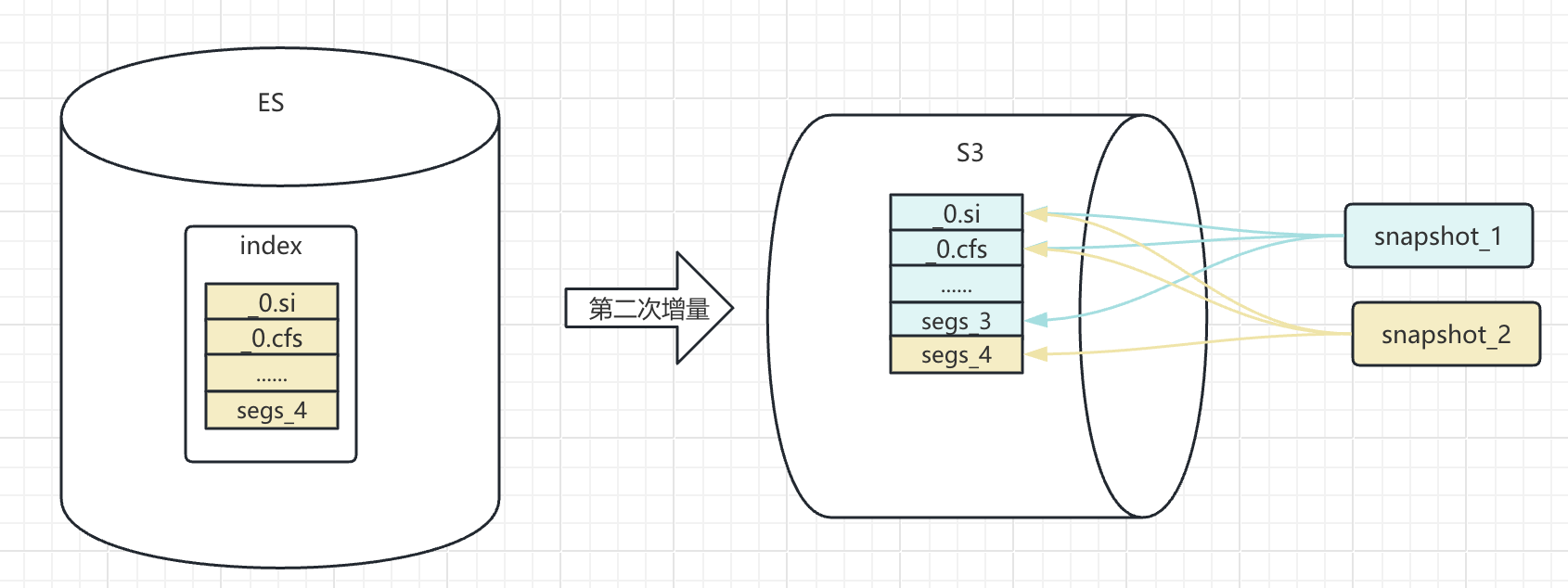
这样的设计也保证了 snapshot 恢复的效率,减少不必要的文件备份,只备份必要的数据文件。
在增量备份测试中,我们修改一部分数据,并执行 refresh,让这个索引的数据文件发生改变。
# 标记目标城市为 Sydney的数据 status 为 update
POST sample_data_flights/_update_by_query?refresh=true
{"script": {"source": "ctx._source.status = 'update'"},"size": 1000,"query": {"term": {"DestCityName": {"value": "Sydney"}}}
}再去查看数据文件,可以看到已经发生了改变。
注:因为测试环境限制,也为了展示直观,索引体量较小,不太能复现索引文件部分更新的状态。
# ls -lrth
total 5.9M
-rw-rw-r-- 1 infini infini 0 Aug 17 13:17 write.lock
-rw-rw-r-- 1 infini infini 395 Aug 17 13:25 _0.si
-rw-rw-r-- 1 infini infini 5.7M Aug 17 13:25 _0.cfs
-rw-rw-r-- 1 infini infini 405 Aug 17 13:25 _0.cfe
-rw-rw-r-- 1 infini infini 321 Aug 17 13:30 segments_3
-rw-rw-r-- 1 infini infini 395 Sep 30 14:44 _1.si
-rw-rw-r-- 1 infini infini 132K Sep 30 14:44 _1.cfs
-rw-rw-r-- 1 infini infini 479 Sep 30 14:44 _1.cfe
-rw-rw-r-- 1 infini infini 160 Sep 30 14:44 _0_1_Lucene80_0.dvm
-rw-rw-r-- 1 infini infini 623 Sep 30 14:44 _0_1_Lucene80_0.dvd
-rw-rw-r-- 1 infini infini 4.5K Sep 30 14:44 _0_1.fnm
可以看到 sample_data_flights 的数据文件有一部分已经变化了。
# 增量备份镜像名称设置为 snapshot_2
PUT _snapshot/minio-repository/snapshot_2
{
"indices": "sample_data_flights",
"ignore_unavailable": true,
"include_global_state": false,
"partial": false
}
那么在 MinIO 中,可以看到会有一批新增的文件,而第一次备份的文件也在。

4. 恢复流程
snapshot 备份索引数据是基于文件的,所以恢复的时候,也是基于文件的。
snapshot 恢复速度的主要影响参数是 max_restore_bytes_per_sec,是单节点数据恢复的最快速度,默认为每秒 40mb,可以结合集群磁盘性能在仓库注册时做调整。
4.1 全量恢复
和备份一样,对一个新索引名进行 restore 操作,就是全量恢复。
POST _snapshot/minio-repository/snapshot_1/_restore
{"indices": "sample_data_flights","rename_pattern": "(.+)","rename_replacement": "restored-$1"
}
可以看到恢复出来的 restored-sample_data_flights 里面并没有 status 为 updated 的文档。
GET restored-sample_data_flights/_count
{"query": {"term": {"status": {"value": "update"}}}
}# 结果为 0
{"count": 0,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0}
}
看一下 restored-sample_data_flights 的数据文件。
# ls -lrth
total 5.7M
-rw-rw-r-- 1 infini infini 0 Sep 30 14:57 write.lock
-rw-rw-r-- 1 infini infini 395 Sep 30 15:01 _0.si
-rw-rw-r-- 1 infini infini 405 Sep 30 15:01 _0.cfe
-rw-rw-r-- 1 infini infini 5.7M Sep 30 15:01 _0.cfs
-rw-rw-r-- 1 infini infini 321 Sep 30 15:05 segments_5
基本和 snapshot_1 时候的一致。
4.2 增量恢复
现在,我们来测试增量恢复,snapshot 的增量恢复是不是和增量备份一样,能自动检测哪些文件是需要更新的,哪些文件是需要删除的,来完成“增量”恢复的呢?
我们使用镜像 snapshot_2 来增量恢复一下。
POST _snapshot/minio-repository/snapshot_2/_restore
{"indices": "sample_data_flights","rename_pattern": "(.+)","rename_replacement": "restored-$1"
}但是恢复失败了。
{"error": {"root_cause": [{"type": "snapshot_restore_exception","reason": "[minio-repository:snapshot_2/XbooG4TDSyubSHqGsoZUQQ] cannot restore index [restored-sample_data_flights] because an open index with same name already exists in the cluster. Either close or delete the existing index or restore the index under a different name by providing a rename pattern and replacement name"}],"type": "snapshot_restore_exception","reason": "[minio-repository:snapshot_2/XbooG4TDSyubSHqGsoZUQQ] cannot restore index [restored-sample_data_flights] because an open index with same name already exists in the cluster. Either close or delete the existing index or restore the index under a different name by providing a rename pattern and replacement name"},"status": 500
}
难道不能增量恢复么?从备份逻辑上,是存在选择不同版本的快照文件来实现增量恢复操作的可能啊。
技术是使用方法的探索,从报错内容中,ES 提示可以 close 索引来规避索引同名问题。lets try it!
POST restored-sample_data_flights/_closePOST _snapshot/minio-repository/snapshot_2/_restore
{"indices": "sample_data_flights","rename_pattern": "(.+)","rename_replacement": "restored-$1"
}
# 返回内容
# POST restored-sample_data_flights/_close
{"acknowledged": true,"shards_acknowledged": true,"indices": {"restored-sample_data_flights": {"closed": true}}
}
# POST _snapshot/minio-repository/snapshot_2/_restore
{"accepted": true
}
这次恢复成功了,那么是不是增量恢复呢?我们查询一下有没有 status 为 update 的文档。
GET restored-sample_data_flights/_count
{"query": {"term": {"status": {"value": "update"}}}
}
# 结果
{"count": 269,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0}
}但是,对应的数据文件却是这样的:
# ls -lrth
total 5.9M
-rw-rw-r-- 1 infini infini 0 Sep 30 14:57 write.lock
-rw-rw-r-- 1 infini infini 395 Sep 30 15:07 _0.si
-rw-rw-r-- 1 infini infini 405 Sep 30 15:07 _0.cfe
-rw-rw-r-- 1 infini infini 623 Sep 30 15:07 _0_1_Lucene80_0.dvd
-rw-rw-r-- 1 infini infini 4.5K Sep 30 15:07 _0_1.fnm
-rw-rw-r-- 1 infini infini 160 Sep 30 15:07 _0_1_Lucene80_0.dvm
-rw-rw-r-- 1 infini infini 132K Sep 30 15:07 _1.cfs
-rw-rw-r-- 1 infini infini 479 Sep 30 15:07 _1.cfe
-rw-rw-r-- 1 infini infini 395 Sep 30 15:07 _1.si
-rw-rw-r-- 1 infini infini 5.7M Sep 30 15:07 _0.cfs
-rw-rw-r-- 1 infini infini 461 Sep 30 15:07 segments_6
虽然结果上看,仿佛这并不是一次增量恢复,但是我们去校验一下两次恢复共有的 _0.si 文件,会发现它们的 cksum 和 md5sum 是一致的。
# ls -lrth
total 5.7M
-rw-rw-r-- 1 infini infini 0 Sep 30 14:57 write.lock
-rw-rw-r-- 1 infini infini 395 Sep 30 15:01 _0.si
-rw-rw-r-- 1 infini infini 405 Sep 30 15:01 _0.cfe
-rw-rw-r-- 1 infini infini 5.7M Sep 30 15:01 _0.cfs
-rw-rw-r-- 1 infini infini 321 Sep 30 15:05 segments_5
# cksum _0.si;md5sum _0.si;
4212537511 395 _0.si
8f12bb6bb50286aea4691091e8e7e0f4 _0.si## snapshot_2 后
# ls -lrth
total 5.9M
-rw-rw-r-- 1 infini infini 0 Sep 30 14:57 write.lock
-rw-rw-r-- 1 infini infini 395 Sep 30 15:07 _0.si
-rw-rw-r-- 1 infini infini 405 Sep 30 15:07 _0.cfe
-rw-rw-r-- 1 infini infini 623 Sep 30 15:07 _0_1_Lucene80_0.dvd
-rw-rw-r-- 1 infini infini 4.5K Sep 30 15:07 _0_1.fnm
-rw-rw-r-- 1 infini infini 160 Sep 30 15:07 _0_1_Lucene80_0.dvm
-rw-rw-r-- 1 infini infini 132K Sep 30 15:07 _1.cfs
-rw-rw-r-- 1 infini infini 479 Sep 30 15:07 _1.cfe
-rw-rw-r-- 1 infini infini 395 Sep 30 15:07 _1.si
-rw-rw-r-- 1 infini infini 5.7M Sep 30 15:07 _0.cfs
-rw-rw-r-- 1 infini infini 461 Sep 30 15:07 segments_6
# cksum _0.si;md5sum _0.si;
4212537511 395 _0.si
8f12bb6bb50286aea4691091e8e7e0f4 _0.si
虽然从源码角度值得深入剖析一下(源码研究以后再鸽),但是在这里也可以去简单高效的佐证这样的操作是否为增量恢复。
我们可以设计一个大索引去观测恢复时间,这样更加直观明了,因为增量恢复的主要意义就是减少恢复时间。这里使用了一个 4.9g 的不断写入的日志类索引进行测试,通过 _snapshot 和 _recovery API 去观测恢复任务的耗时。
全量备份花费 127885 ms,增量备份花费 2021 ms。全量恢复花费了 127373 ms,增量恢复花费了 2196 ms。
除了简单的比对恢复时间,我们也可以利用 _recovery API 去查看两次镜像恢复的文件细节
# 查看恢复细节命令
GET _recovery?filter_path={索引名}.shards.index.files# 第一次全量恢复
{"shards": [{"index": {"files": {"total": 101,"reused": 0,"recovered": 101,"percent": "100.0%"}}}]
}# 第二次增量恢复
{"shards": [{"index": {"files": {"total": 104,"reused": 61,## 这里 ES 标记复用了之前61个文件"recovered": 43,"percent": "100.0%"}}}]
}5. 镜像维护清理
镜像备份的保存也不是无限的,当镜像数据达到需求所需时间时,也可以进行过期镜像的清理,以节省存储空间。
不难看出,镜像的清理也是要维护好现存镜像与备份的数据文件之间的关系。镜像仓库中清理的文件是保留镜像不需要的文件。
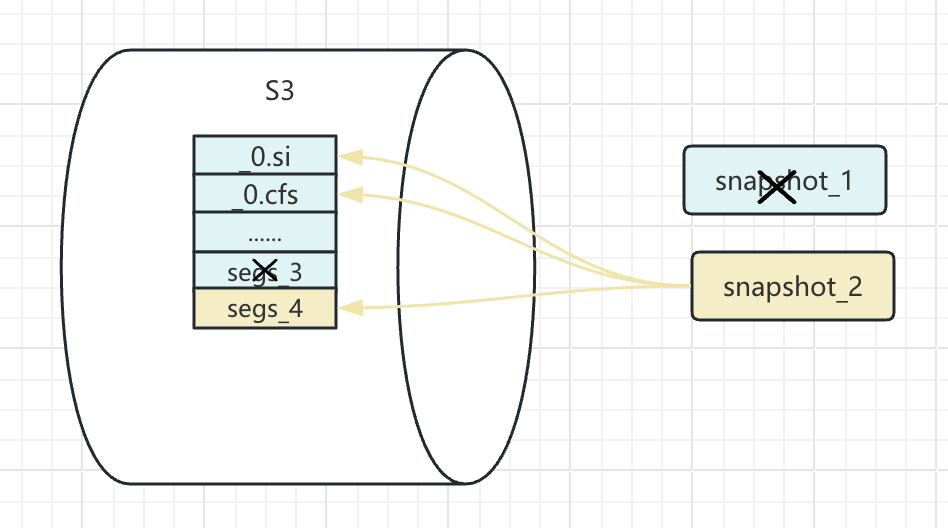
如图所示,要清理 snapshot_1,只需要清理掉 segs_3 对应的文件,至于其他文件则是保留下来的 snapshot_2 需要的。
而在我们这次测试中,清理掉 snapshot_1 则并不会把主要的数据文件清理掉。
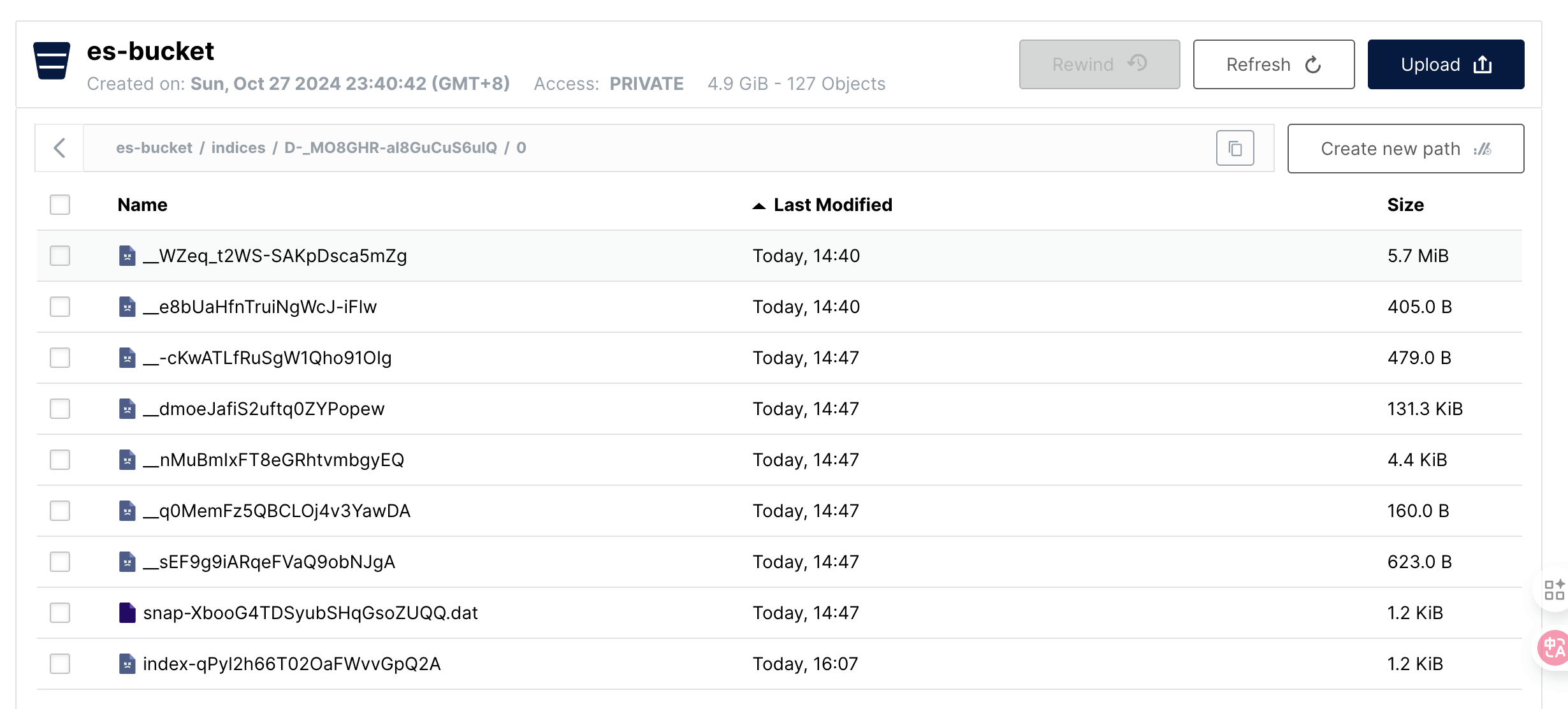
不过可以看到以 snap 开头的文件清理掉了一个,这应该是 snapshot_1 的一个元信息文件。
6. 小结
至此,我们已经对 Elasticsearch Snapshot 备份的使用细节进行了全面梳理,并实践了切实可行的增量恢复操作。它作为一个高效可靠的冷备方案,为数据安全提供了坚实保障。
下一篇,我们将一同探索 Elasticsearch 的热备方案:跨集群复制(CCR)。
特别感谢:社区@张赓 提供的增量验证方法
作者:金多安,极限科技(INFINI Labs)搜索运维专家,Elastic 认证专家,搜索客社区日报责任编辑。一直从事与搜索运维相关的工作,日常会去挖掘 ES / Lucene 方向的搜索技术原理,保持搜索相关技术发展的关注。
原文:https://infinilabs.cn/blog/2025/es-backup-snapshot/