Linux 文本编辑三剑客之 grep
Linux 文本处理三剑客是面试和后端工作中较为常见的。需要掌握:
- grep:文本过滤、筛选
- sed:文本编辑加工
- awk:文本格式化输出
本节内容基于正则表达式:
正则表达式
借助正则表达式可以快速匹配、过滤需要的字符串,在 Linux 上处理大量文本比较高效。
- 一次处理一行
- Linux 上只有文本处理工具三剑客(grep、sed、awk)常用,编程语言都有对应支持
- 扩展正则是基本正则的补充,一般结合三剑客使用建议直接使用扩展正则的写法,简洁
基本正则
| 符号 | 作用 |
|---|---|
^ |
模式匹配最左侧,^abc就是以abc开头 |
$ |
模式匹配最右侧,abc$就是以abc结尾 |
^$ |
组合符。空行 |
. |
任意一个且只有一个字符,不匹配空行 |
* |
匹配前一个字符0或多次,不单独使用 |
.* |
组合符。匹配任意多个字符 |
^.* |
组合符。匹配任意多个字符开头 |
.*$ |
组合符。匹配任意多个字符结尾 |
\ |
特殊字符还原本意,\.是小数点 |
[abc] |
匹配集合内任意字符 |
[^abc] |
匹配集合之外的字符 |
<> |
定位单词的左侧和右侧。<deltaqin> 可以找出 deltaqin nb找不出deltaqinnb |
扩展正则
| 符号 | 作用 |
|---|---|
+ |
匹配前面字符一次或多次 |
[:@]+ |
组合符。匹配[]内的字符一次或多次 |
? |
匹配前面字符0次或1次 |
| ` | ` |
() |
分组过滤,括号内是一个整体 |
a{m,n} |
前面的字符最少m最多n次 |
a{m,} |
前面的字符最少m次 |
a{m} |
前面的字符m次 |
a{,m} |
前面的字符最多m次 |
具体使用还是要结合三剑客一起
Why grep
文本搜索工具,根据指定的过滤条件对文本逐行匹配
What grep
grep [option] [pattern] file
- option:可选参数
- -i 忽略ignore大小写
- -v 显示不能被匹配的行
- -E 使用正则表达式匹配
- -n 显示行号
- -c 统计匹配的行数
- -o 只显示被匹配的关键字,一般用来计数
- pattern:可以是普通文本字符,也可以是正则表达式
How grep--基本正则
以 i 开头的行


以 n 结尾的行

以特殊符号结尾的行


空行

贪婪匹配

匹配数字或者字符


匹配小写之外的字符

How grep--扩展正则
匹配1个或多个

匹配0或1次

匹配自定义次


匹配或

分组
- 括号的内容当做整体来匹配

分组与引用找出用户名和shell名相同的行
- 括号的内容可以被引用
\1是第一个括号中匹配的字符\2是第二个括号中匹配的字符


^([^:]+).*\1$其中\>代表单词结尾
[^:]+冒号外的多个字符^[^:]+冒号外的多个字符开头的行^([^:]+\>)冒号外的多个字符开头的行,并且匹配一个完整的单词\1$结尾是前面括号的内容,这里就是用户名
常见使用案例
过滤root或者de开头的行,不区分大小写,并显示行号

精确过滤root或者deltaqi开头的行
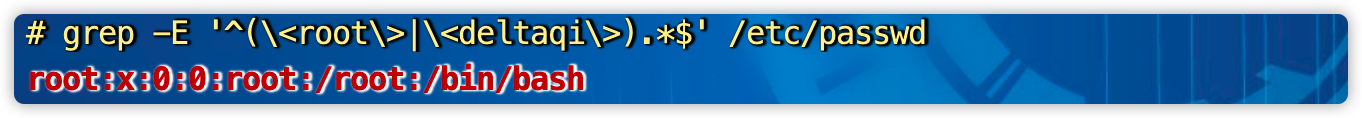
列出不以nologin结尾的行

找到两位数或者三位数
错误写法,没有精确匹配


至少一个空格开头,后面全是非空字符的行


找出文件所有的函数名
