服务器丢包分析--iptables规则以及MTU大小设置错误
容器利用 Linux 内核提供的命名空间技术,将不同应用程序的运行隔离起来,并用统一的 镜像,来管理应用程序的依赖环境。这为应用程序的管理和维护,带来了极大的便捷性,并 进一步催生了微服务、云原生等新一代技术架构。
容易发生启动过慢、运行一段时间后 OOM 退出等问题。容器化后,应用程序会通过命名空间进行隔离。所以,你在分析时,不要忘了结合命名空间、cgroups、iptables 等来综合分析:
- cgroups 会影响容器应用的运行;
- iptables 中的 NAT,会影响容器的网络性能;
- 叠加文件系统,会影响应用的 I/O 性能等。
数据包还没传输到应用程序中, 就被丢弃了。这些被丢弃包的数量,除以总的传输包数,也就是我们常说的丢包率。丢包通常会带来严重的性能下降,特别是对 TCP 来说,丢包通常意味着网络拥塞和重传, 进而还会导致网络延迟增大、吞吐降低。
丢包模拟
docker run --name nginx --hostname nginx --privileged -p 80:80 -itd feisky/nginx:drop
没有使用 ping,是因为 ping 基于 ICMP 协议,而 Nginx 使 用的是 TCP 协议。
-c 表示发送 10 个请求,-S 表示使用 TCP SYN,-p 指定端口为 80
hping3 -c 10 -S -p 80 10.211.55.66
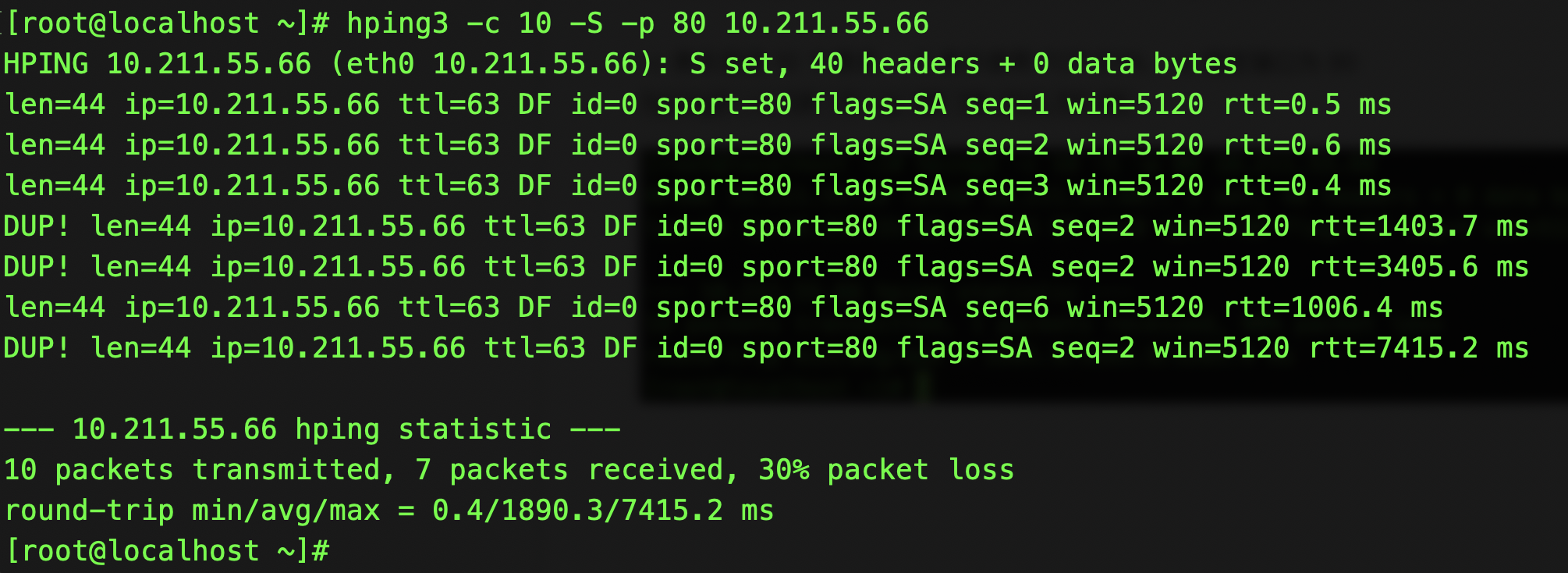
RTT 也有非常大的波动变化,小的时候只 有 0.3ms,而大的时候则有 3s。
3s 的 RTT ,很可能是 因为丢包后重传导致的。
流程分析
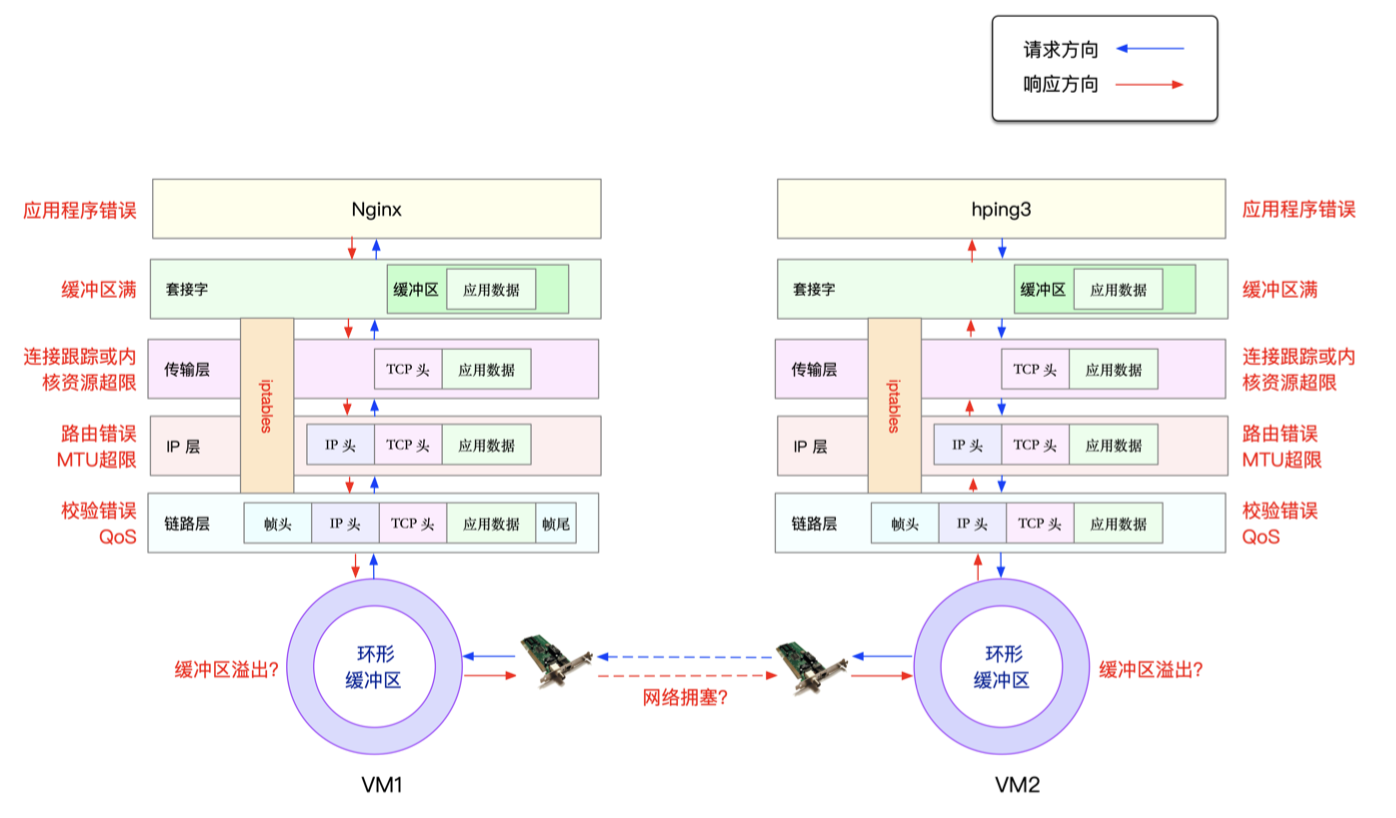
各层分析
VM1 的网络和内核配置也没问题。这样 一来,有可能发生问题的位置,就都在容器内部了。
docker exec -it nginx bash链路层
当缓冲区溢出等原因导致网卡丢包时,Linux 会在网卡收发数据的统计信息中,记录下收发错误的次数。
你可以通过 ethtool 或者 netstat ,来查看网卡的丢包记录。
netstat -i

- 输出中的 RX-OK、RX-ERR、RX-DRP、RX-OVR ,分别表示接收时的总包数、总错误数、 进入 Ring Buffer 后因其他原因(如内存不足)导致的丢包数以及 Ring Buffer 溢出导致的丢包数。
- TX-OK、TX-ERR、TX-DRP、TX-OVR 也代表类似的含义,只不过是指发送时对应的各个 指标。
Docker 容器的虚拟网卡,实际上是一对 veth pair,一端接入容器中用作 eth0,另一端在主机中接入 docker0 网桥中。veth 驱动并没有实现网络统计的功能,所以使用 ethtool -S 命令,无法得到网卡收发数据的汇 总信息。
容器的虚拟网卡没有丢包。
不过要注意,如果用 tc 等工具配置了 QoS,那么 tc 规则导致的丢包,就不会包含在网卡的统计信息中。还要检查一下 eth0 上是否配置了 tc 规则,并查看有没有丢包。
添加 -s 选项,以输出统计信息:

从 tc 的输出中可以看到, eth0 上面配置了一个网络模拟排队规则(qdisc netem),并 且配置了丢包率为 30%(loss 30%)。再看后面的统计信息,发送了 21 个包,但是丢了 16 个。应该就是这里,导致 Nginx 回复的响应包,被 netem 模块给丢了。
直接删掉 netem 模块就可以了。删除 tc 中的 netem 模块:
tc qdisc del dev eth0 root netem loss 30%
不幸的是,从 hping3 的输出中,RTT 的波动也仍旧很大,从 3ms 到 1s。
既然链路层已经排查完了,我们就继续 向上层分析,看看网络层和传输层有没有问题。
网络层和传输层
引发丢包的因素非常多,确认是否丢包非常简单的事,因为 Linux 提供了各个协议的收发汇总情况。在容器终端中,执行下面的 netstat -s 命令,就可以看到协议的收发汇总,以及 错误信息了:
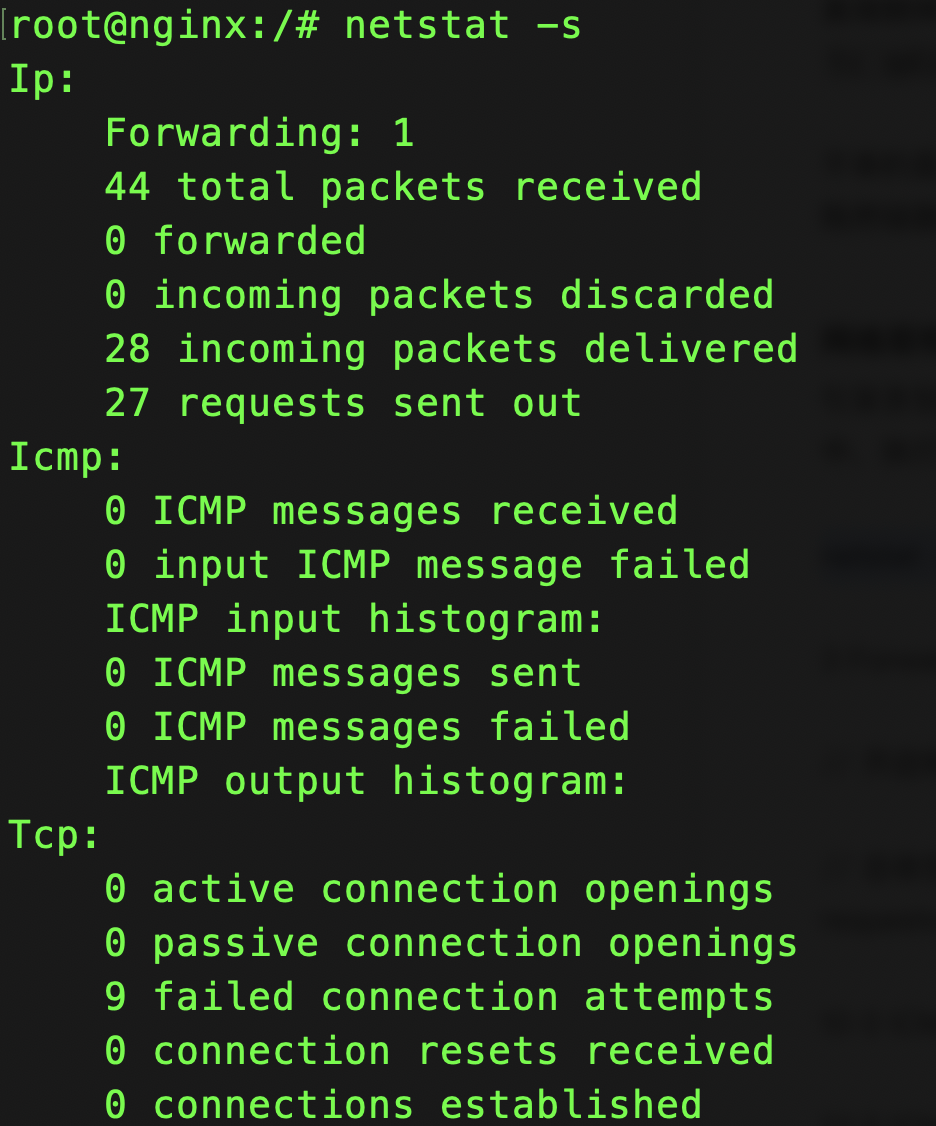
netstat 汇总了 IP、ICMP、TCP、UDP 等各种协议的收发统计信息。不过,我们的目的是 排查丢包问题,所以这里主要观察的是错误数、丢包数以及重传数。

只有 TCP 协议发生了丢包和重传,分别是:
11 次连接失败重试(11 failed connection attempts) ;4 次重传(4 segments retransmitted) ;11 次半连接重置(11 resets received for embryonic SYN_RECV sockets) ;4 次 SYN 重传(TCPSynRetrans); 7 次超时(TCPTimeouts)
TCP 协议有多次超时和失败重试,并且主要错误是半连接重置。主要的失败,都是三次握手失败。
不过,虽然在这儿看到了这么多失败,但具体失败的根源还是无法确定。所以,我们还需要 继续顺着协议栈来分析
除了网络层和传输层的各种协议,iptables 和内核的连接跟踪机制也可能会导致丢包。
连接跟踪限制数 导致问题?
要确认是不是连接跟踪导致的问题,其实只需要对比当前的连接跟踪数和最大连接跟 踪数即可。由于连接跟踪在 Linux 内核中是全局的(不属于网络命名空间),我们需要退出容器终端,回到主机中来查看。
你可以在容器终端中,执行 exit ;然后执行下面的命令,查看连接跟踪数:
sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 262144
sysctl net.netfilter.nf_conntrack_count
net.netfilter.nf_conntrack_count = 182
连接跟踪数只有 182,而最大连接跟踪数则是 262144。显然,这里的丢包,不可能是连接跟踪导致的。
iptables 导致问题?
基于 Netfilter 框架,通过一系列的规则,对网络数据包进行过滤(如防火墙)和修改(如 NAT)。
iptables 规则统一管理在一系列的表中,包括 filter(用于过滤)、nat(用于 NAT)、mangle(用于修改分组数据) 和 raw(用于原始数据包)等。而每张表又可以包括一系列的链,用于对 iptables 规则进行分组管理。
对于丢包问题来说,最大的可能就是被 filter 表中的规则给丢弃了。
那些目标为 DROP 和 REJECT 等会弃包的规则,有没有被执行到?
把所有的 iptables 规则列出来,根据收发包的特点,跟 iptables 规则进行匹配。更简单的方法,就是直接查询 DROP 和 REJECT 等规则的统计信息,看看是否为 0。如果统计值不是 0 ,再把相关的规则拎出来进行分析。
容器下面的 iptables 命令,可以看到 filter 表的统计数据
docker exec -it nginx bash
iptables -t filter -nvL

从 iptables 的输出中,两条 DROP 规则的统计数值不是 0,它们分别在 INPUT 和 OUTPUT 链中。这两条规则实际上是一样的,指的是使用 statistic 模块,进行 随机 30% 的丢包。
再观察一下它们的匹配规则。0.0.0.0/0 表示匹配所有的源 IP 和目的 IP,也就是会对所有 包都进行随机 30% 的丢包。
修复iptables导致的问题
把这两条规则直接删除就可以了。我 们可以在容器终端中,执行下面的两条 iptables 命令,删除这两条 DROP 规则:
iptables -t filter -D INPUT -m statistic --mode random --probability 0.30
iptables -t filter -D OUTPUT -m statistic --mode random --probability 0.30
RTT正常了
RTT正常,请求超时
curl --max-time 3 http://192.168.0.30
连接超时了。用 hping3 验证了 端口正常,现在却发现 HTTP 连接超时,是不是因为 Nginx 突然异常退出。hping3 的结果显示,Nginx 的 80 端口确确实实还是正常状态。
tcpdump
tcpdump -i eth0 -nn port 80
请求之后,

前三个包是正常的 TCP 三次握手,这没问题;但第四个包却是在 3 秒以后了,并且还是客户端(VM2)发送过来的 FIN 包,也就说 明,客户端的连接关闭了。
curl 设置的 3 秒超时选项,是因为 curl 命令超时后退出了。
没有抓取到 curl 发来的 HTTP GET 请求,网卡丢包了,还是客户端压根儿就没发过来?
检查网卡对于正常请求而不是SYN的 丢包情况
netstat -i 命令,确认一下网卡有没有丢包问题:接收丢包数(RX-DRP)是 344,果然是在网卡接收时 丢包了。不过问题也来了,为什么刚才用 hping3 时不丢包,现在换成 GET 就收不到了 呢?
- hping3 实际上只发送了 SYN 包;
- 而 curl 在发送 SYN 包后,还会发送 HTTP GET 请求。HTTP GET ,本质上也是一个 TCP 包,但跟 SYN 包相比,它还携带了 HTTP GET 的数 据。
- 这可能是 MTU 配置错误导致的。为什么呢?
- netstat 的输出界面,第二列正是每个网卡的 MTU 值。eth0 的 MTU 只有 100,而以太网的 MTU 默认值是 1500,这个 100 就显得太小了。
修改MTU的大小
把容器 eth0 的 MTU 改成 1500:
ifconfig eth0 mtu 1500
以 ksoftirqd 为例,分析内核线程 CPU 利用率太高
在排查网络问题时,内核线程的 CPU 使用率很高。比如,在高并发的场景中,内核线程 ksoftirqd 的 CPU 使用率通常就会比较高。是网络收发的软中断导致的。
怀疑是网络问题,就可以用 sar、tcpdump 等分析 网络流量,进一步确认网络问题的根源。这种方法在实际操作中需要步骤比较多,可能并不算快捷。
内核线程
在 Linux 中,用户态进程的“祖先”,都是 PID 号为 1 的 init 进程。init 都是 systemd 进程;而其他的用户态进程,会通过 systemd 来进行管理。
按说内核态的线程,应该先于用户态进程启动,可是 systemd 只管理用户态进程。
Linux 在启动过程中,有三个特殊的进程,也就是 PID 号最小的三个进程:
- 0 号进程为 idle 进程,这也是系统创建的第一个进程,它在初始化 1 号和 2 号进程后,演变为空闲任务。当 CPU 上没有其他任务执行时,就会运行它。
- 1 号进程为 init 进程,通常是 systemd 进程,在用户态运行,用来管理其他用户态进程。
- 2 号进程为 kthreadd 进程,在内核态运行,用来管理内核线程。 所以,要查找内核线程,只需要从 2 号进程开始,查找它的子孙进程即可。可以使用 ps 命令,来查找 kthreadd 的子进程:
ps -f --ppid 2 -p 2- 内核线程的名称(CMD)都在中括号里
ps -ef | grep "\[.*\]"
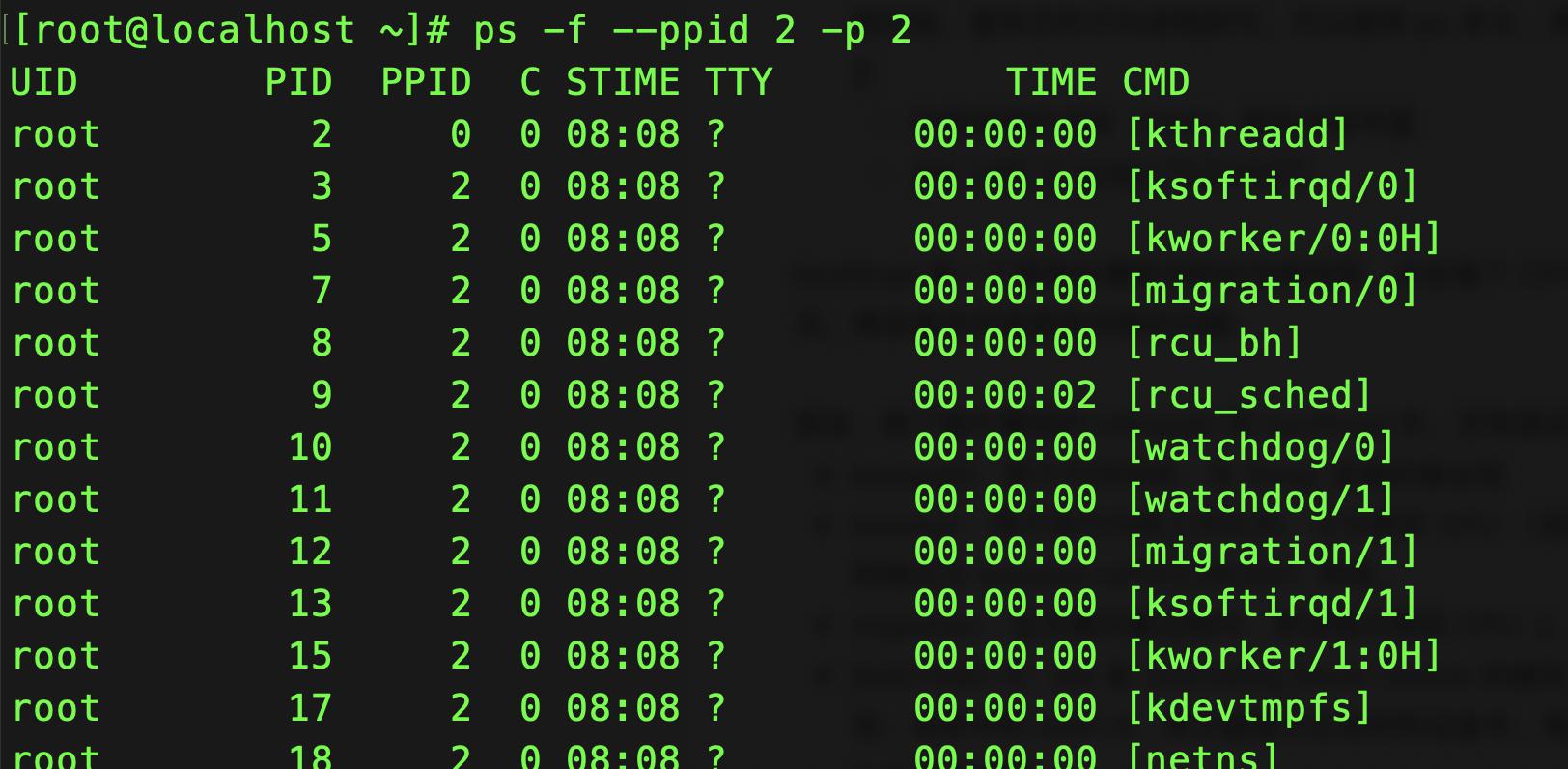
ksoftirqd 是一个用来处理软中断的内核线程,并且每个 CPU 上都有一个。遇到 ksoftirqd 的 CPU 使用高的情况,就会首先怀疑是软中断的问题,
其实,除了刚才看到的 kthreadd 和 ksoftirqd 外,还有很多常见的内核线程:
- kswapd0:用于内存回收。在 Swap 变高时候出现
- kworker:用于执行内核工作队列,分为绑定 CPU (名称格式为 kworker/CPU86330)和未绑定 CPU(名称格式为 kworker/uPOOL86330)两类。
- migration:在负载均衡过程中,把进程迁移到 CPU 上。每个 CPU 都有一个 migration 内核线程。
- jbd2/sda1-8:jbd 是 Journaling Block Device 的缩写,用来为文件系统提供日志功能,以保证数据的完整性;名称中的 sda1-8,表示磁盘分区名称和设备号。每个使用了 ext4 文件系统的磁盘分区,都会有一个 jbd2 内核线程。
- pdflush:用于将内存中的脏页(被修改过,但还未写入磁盘的文件页)写入磁盘(已经 在 3.10 中合并入了 kworker 中)。
案例分析
docker run -itd --name=nginx -p 80:80 nginx
-S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80
-i u10 表示每隔 10 微秒发送一个网络帧 3
注:如果你在实践过程中现象不明显,可以尝试把 10 调小,比如调成 5 甚至 1
hping3 -S -p 80 -i u10 192.168.0.30
top观察:
两个 CPU 的软中断使用率都超过了 30%;而 CPU 使用率 最高的进程,正好是软中断内核线程 ksoftirqd/0 和 ksoftirqd/1。可以猜测是因为大量网络收发,引起了 CPU 使用率升高;
对于普通进程,我们要观察其行为有很多方法,比如 strace、pstack、lsof 等等。但这些 工具并不适合内核线程,比如,如果你用 pstack ,或者通过 /proc/pid/stack 查看 ksoftirqd/0(进程号为 9)的调用栈时。pstack 报出的是不允许挂载进程的错误;而 /proc/9/stack 方式虽然有输出,但输 出中并没有详细的调用栈情况。
perf 观察内核线程 ksoftirqd 的行为
既然是内核线程,自然应该用到内核中提供的机制。perf ,这个内核自带的性能剖析工具。
perf 可以对指定的进程或者事件进行采样,并且还可以用调用栈的形式,输出整个调用链 上的汇总信息
采样 30s 后退出
perf record -a -g -p 9 -- sleep 30
继续执行 perf report命令,你就可以得到 perf 的汇总报告。按上下方向键以及回车键,展开比例最高的 ksoftirqd 后,你就可以得到下面这个调用关系链图: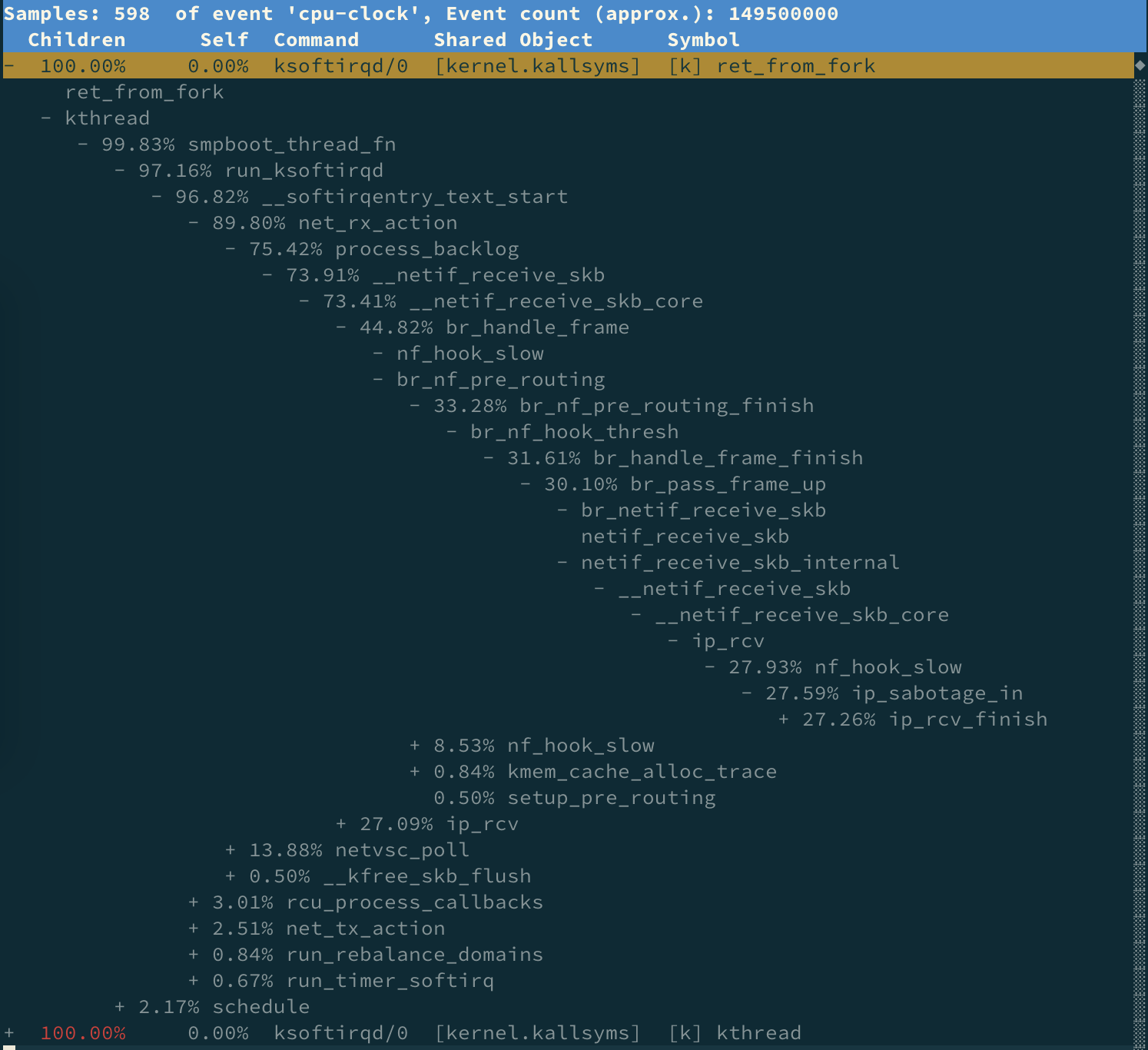 看到 ksoftirqd 执行最多的调用过程:
看到 ksoftirqd 执行最多的调用过程:
- net_rx_action 和 netif_receive_skb,表明这是接收网络包(rx 表示 receive)。
- br_handle_frame ,表明网络包经过了网桥(br 表示 bridge)。
- br_nf_pre_routing ,表明在网桥上执行了 netfilter 的 PREROUTING(nf 表示 netfilter)。而我们已经知道 PREROUTING 主要用来执行 DNAT,所以可以猜测这里有 DNAT 发生。
- br_pass_frame_up,表明网桥处理后,再交给桥接的其他桥接网卡进一步处理。比如, 在新的网卡上接收网络包、执行 netfilter 过滤规则等等。
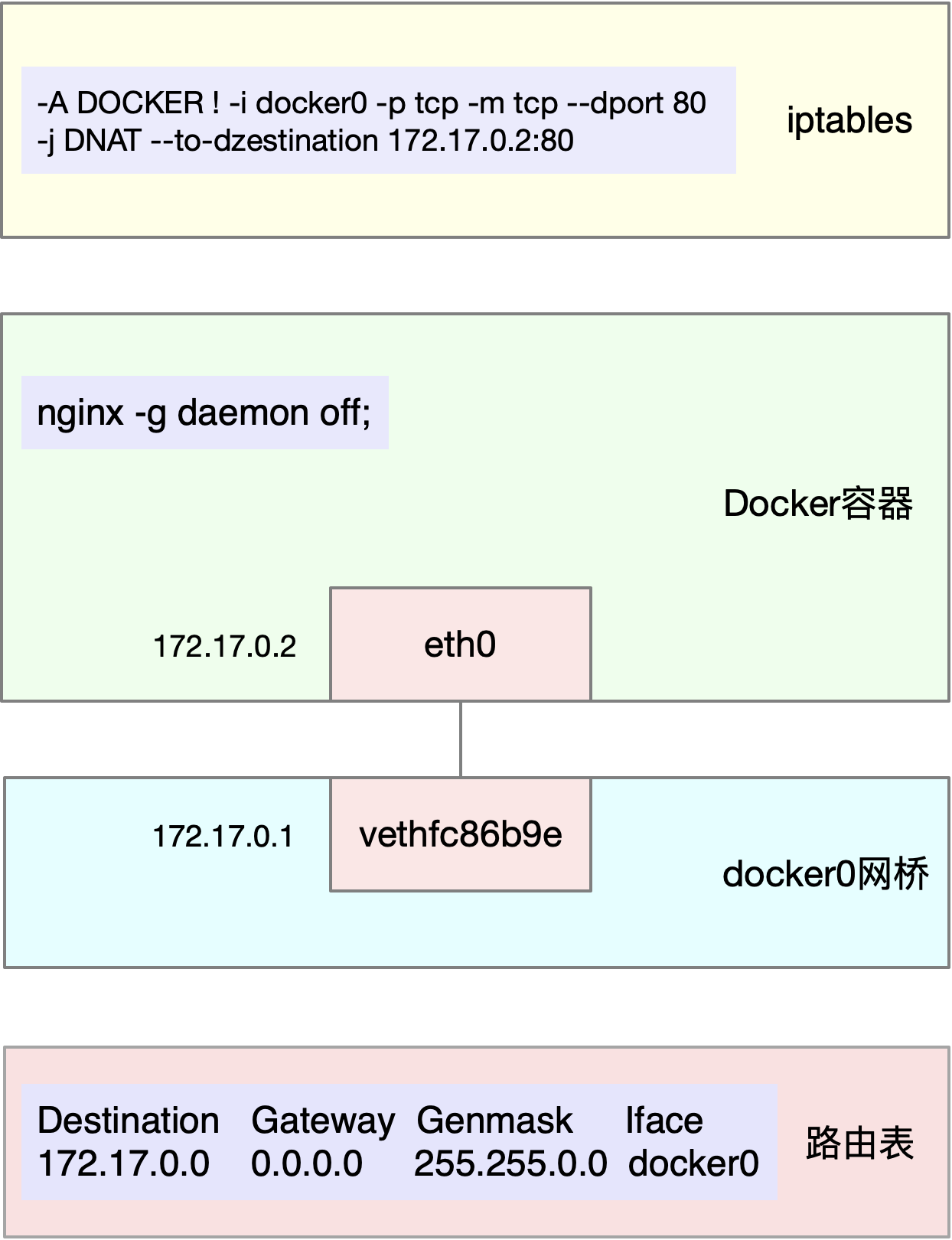
Docker 会自动 为容器创建虚拟网卡、桥接到 docker0 网桥并配置 NAT 规则。
火焰图 查看整个调用栈的信息
针对 perf 汇总数据的展示问题,Brendan Gragg 发明了火焰图,通过矢量图的形式,更 直观展示汇总结果
- 横轴表示采样数和采样比例。一个函数占用的横轴越宽,就代表它的执行时间越长。同一层的多个函数,则是按照字母来排序。
- 纵轴表示调用栈,上下相邻的两个函数中,下面的函数,是上面函数的父函数。这样,调用栈越深,纵轴就越高。
- 颜色,并没有特殊含义,只是用来区分不同的函数。 火焰图是动态的矢量图格式,所以它还支持一些动态特性。比如,鼠标悬停到某个函数上 时,就会自动显示这个函数的采样数和采样比例。而当你用鼠标点击函数时,火焰图就会把 该层及其上的各层放大,方便你观察这些处于火焰图顶部的调用栈的细节。
性能分析的目标来划分:(不同类型的火焰图的结构是一样的,只是函数堆栈不一样,内存火焰图侧重于内存管理函数的调用 栈)
- on-CPU 火焰图:表示 CPU 的繁忙情况,用在 CPU 使用率比较高的场景中。 off-CPU 火焰图:表示 CPU 等待 I/O、锁等各种资源的阻塞情况。
- 内存火焰图:表示内存的分配和释放情况。
- 热 / 冷火焰图:表示将 on-CPU 和 off-CPU 结合在一起综合展示。
- 差分火焰图:表示两个火焰图的差分情况,红色表示增长,蓝色表示衰减。差分火焰图常 用来比较不同场景和不同时期的火焰图,以便分析系统变化前后对性能的影响情况。
运用火焰图来观察刚才 perf record 得到的记录。
火焰图分析
从 perf record 记录生成火焰图的工具,这 些工具都放在 https://github.com/brendangregg/FlameGraph 上面。
git clone https://github.com/brendangregg/FlameGraph
cd FlameGraph
执行 perf script ,将 perf record 的记录转换成可读的采样记录;
执行 stackcollapse-perf.pl 脚本,合并调用栈信息;
执行 flamegraph.pl 脚本,生成火焰图。 不过,在 Linux 中,我们可以使用管道,
用 perf record 生成的文件路径为 /root/perf.data,执行下面的命令,你就可以直接生成火焰图:
perf script -i /root/perf.data | ./stackcollapse-perf.pl --all |./flamegraph.pl > ks
使用浏览器打开 ksoftirqd.svg ,你就可以看到生成的火焰图了。其实跟刚才的 perf report 类似,但直观了很多,中间 这一团火,很明显就是最需要我们关注的地方。
我们顺着调用栈由下往上看(顺着图中蓝色箭头),就可以得到跟刚才 perf report 中一样 的结果:
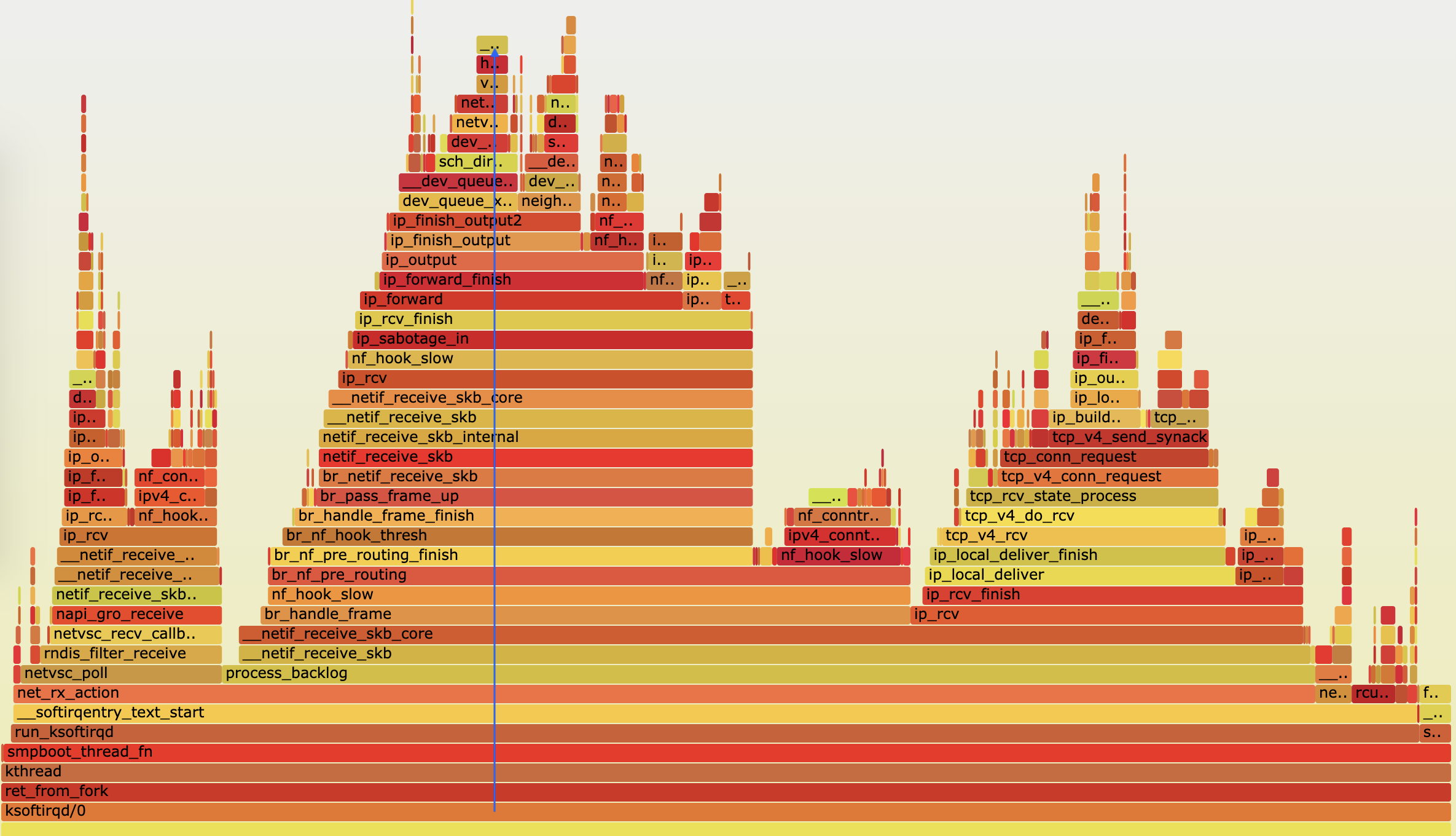
- 最开始,还是 net_rx_action 到 netif_receive_skb 处理网络收包;
- 然后, br_handle_frame 到 br_nf_pre_routing ,在网桥中接收并执行 netfilter 钩子函 数; 再向上, br_pass_frame_up 到 netif_receive_skb ,从网桥转到其他网络设备又一次接 收。
- 不过最后,到了 ip_forward 这里,已经看不清函数名称了。所以我们需要点击 ip_forward,展开最上面这一块调用栈:
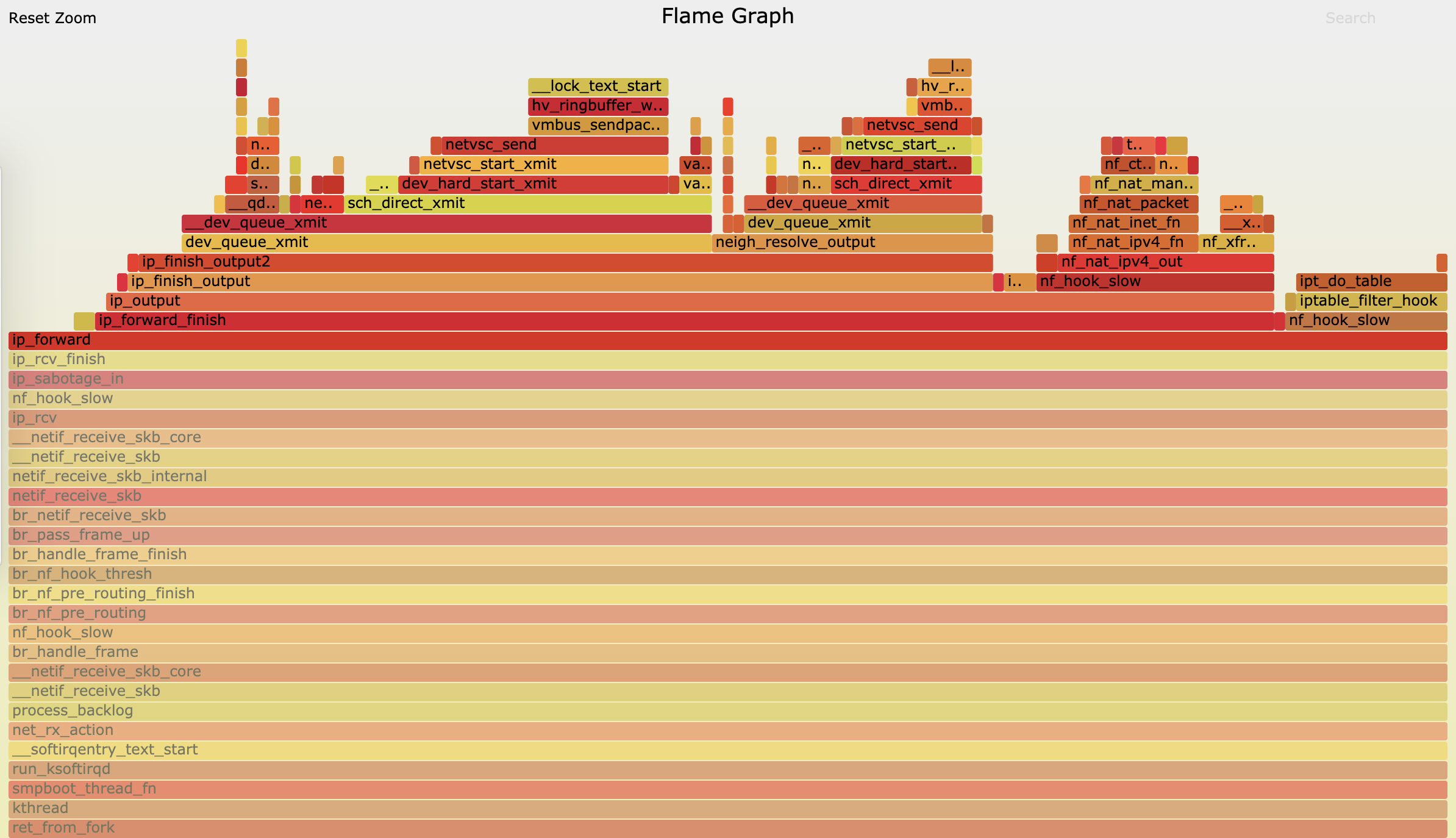
看到 ip_forward 后的行为,也就是把网络包发送出去。
这个流程中的网络接收、网 桥以及 netfilter 调用等,都是导致软中断 CPU 升高的重要因素,也就是影响网络性能的潜 在瓶颈。
这个堆栈中并没有 TCP 相关的调用,也没有连接跟踪 conntrack 相关的函数。实际 上,这些流程都在其他更小的火焰中,你可以点击上图左上角的“Reset Zoom”,回到完 整火焰图中,再去查看其他小火焰的堆栈。
所以,在理解这个调用栈时要注意。从任何一个点出发、纵向来看的整个调用栈,其实只是 最顶端那一个函数的调用堆栈,而非完整的内核网络执行流程。
整个火焰图不包含任何时间的因素,所以并不能看出横向各个函数的执行次序。
找出了内核线程 ksoftirqd 执行最频繁的函数调用堆栈,而这个堆栈中的各层级函数,就是潜在的性能瓶颈来源。
perf 和火焰图方法,我们进一步找出了软中断内核线程的热点函数,其实也就找出了潜在的瓶颈和优化方向。如果遇到的是内核线程的资源使用异常,很多常用的进程级性能工具并不能帮上忙。 这时,你就可以用内核自带的 perf 来观察它们的行为,找出热点函数,进一步定位性能 瓶。当然,perf 产生的汇总报告并不够直观,所以我也推荐你用火焰图来协助排查。实际上,火焰图方法同样适用于普通进程。比如,在分析 Nginx、MySQL 等各种应用场景 的性能问题时,火焰图也能帮你更快定位热点函数,找出潜在性能问题。
总结
动态追踪,就是在系统或者应用程序还在正常运行的时候,通过内核中提供的探针,来动态追踪它们的行为,从而辅助排查出性能问题的瓶颈。
使用动态追踪,便可以在不修改代码也不重启服务的情况下,动态了解应用程序或者内核的 行为。这对排查线上的问题、特别是不容易重现的问题尤其有效。
使用 perf 配合火焰图寻找热点函数,是一个比较通用的性能定位方法,在很多场景中都 可以使用。