大语言模型的工作原理说起来很直接:根据输入内容和已生成的文本,预测下一个最合适的词(token)。输入先转换成 token,再变成向量表示,最后在输出层重新转回 token。
真正的挑战在于如何从候选词中做出选择。这个过程本质上是统计和概率性的,叫做"采样"。每个解码步骤模型都要从整个词汇表的概率分布中采样出下一个 token。
采样策略决定了模型的表现:只选概率最高的词,输出会很安全但缺乏新意而完全随机选择又会导致输出混乱。所以对大模型来说,精髓就在这两个极端之间找平衡。
Min-p 采样提供了一个新的解决思路:这是一种随机技术,能根据模型的置信度动态调整截断阈值,让阈值变得对上下文敏感,这样一来阈值不再固定,而是取决于当前 token 分布的确定程度。
现有采样方法的局限性
我们先看看目前主流的方法都有什么问题。
贪心解码和束搜索属于准确定性方法,每步都选最可能的 token。这样做很稳但也意味着错过了更多样化和创新的输出可能。
温度参数像个风险调节器,较低的温度值可以让模型保守行事,而高温则鼓励冒险尝试不太可能的词汇。但温度调节比较粗糙,缺乏精细控制。
Top-k 采样只从概率最高的 k 个候选中选择,问题是它不会根据模型置信度变化而调整。k 值小了过于保守,限制创造力,这时如果温度值高了的话又很容易产生噪音和不连贯的输出。
Top-p(核采样)动态选择累积概率超过阈值 p 的最小 token 集合。不过在高温度下这种方法也可能产生重复或不连贯的文本。p 值低了太保守,p 值高了又太冒险。
动态阈值采样会根据模型置信度调整 token 阈值,当温度很高(T>2)时,概率分布被"拉平",许多 token 的概率都很接近且偏低,即便配合 top-p 或 top-k 也容易出现退化、重复甚至胡言乱语,所以这个采样值需要更多的调参步骤。
下图直观展示了各种采样方法的区别: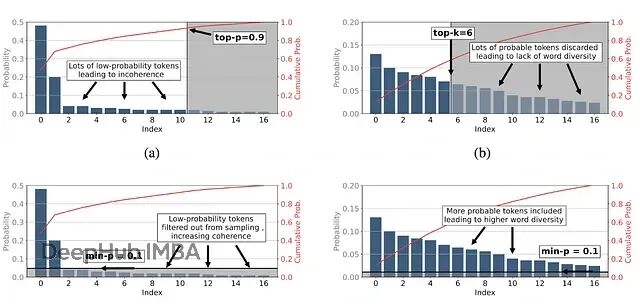
图(a)为初始 token 分布。图(b)为 top-p 采样。图(c)为 top-k 采样。图(d)为 min-p 采样。
https://avoid.overfit.cn/post/0f692943578945c09e18288e73615f4f