分布式 ID 生成方案实战指南:从选型到落地的全场景避坑手册(三) - 实践
五、方案 4:Redis 自增 ID—— 极高并发的轻量选择
5.1 问题场景:直播平台礼物 ID 生成
某直播平台,峰值 QPS 达 10 万(用户送礼物),需生成全局唯一、高性能的礼物 ID,无需强有序(仅需唯一标识),且避免依赖数据库 / ZooKeeper。
5.2 方案原理:利用 Redis 的 INCR 命令
Redis 的INCR key命令是原子操作,支持每秒万级 / 十万级自增,核心思路:
用 Redis 的
INCR生成自增 ID(如INCR gift:id);为避免 Redis 单点故障,部署 Redis 集群(主从 + 哨兵);
可选:添加业务前缀(如礼物类型 + 日期),增强 ID 语义(如
gift_1_20240520_123456)。
5.3 实战代码:Redis 自增 ID 实现(Spring Boot)
5.3.1 1. 依赖配置(pom.xml)
<!-- Spring Data Redis --><dependency><groupId>org.springframework.boot\</groupId><artifactId>spring-boot-starter-data-redis\</artifactId></dependency><!-- Redis客户端(Lettuce,支持集群) --><dependency><groupId>io.lettuce\</groupId><artifactId>lettuce-core\</artifactId></dependency>5.3.2 2. Redis 配置(application.yml)
spring:
redis:
# Redis集群地址(主从+哨兵)
sentinel:
master: mymaster # 主节点名称
nodes: 192.168.1.100:26379,192.168.1.101:26379,192.168.1.102:26379
# 连接池配置
lettuce:
pool:
max-active: 16 # 最大连接数
max-idle: 8 # 最大空闲连接数
min-idle: 4 # 最小空闲连接数
# 密码(生产环境必填)
password: Redis@123456
# 超时时间
timeout: 2000ms5.3.3 3. Redis 自增 ID 服务实现(Java)
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.TimeUnit;
@Service
public class GiftIdGenerator
{
// Redis key前缀(区分不同业务)
private static final String REDIS\_KEY\_PREFIX = "gift:id:";
// 时间格式(用于ID前缀,如20240520)
private static final SimpleDateFormat DATE\_FORMAT = new SimpleDateFormat("yyyyMMdd");
// 本地缓存ID的过期时间(5分钟,避免频繁访问Redis)
private static final long CACHE\_EXPIRE\_MINUTES = 5;
@Resource
private RedisTemplate\<
String, Long> redisTemplate;
// 生成礼物ID(格式:gift\_礼物类型\_日期\_自增ID,如gift\_1\_20240520\_123456)
public String generateGiftId(int giftType) {
// 1. 构建Redis key(按日期分片,避免单key自增过大)
String date = DATE\_FORMAT.format(new Date());
String redisKey = REDIS\_KEY\_PREFIX + date;
// 2. 执行Redis INCR命令(原子自增)
ValueOperations\<
String, Long> valueOps = redisTemplate.opsForValue();
Long incrId = valueOps.increment(redisKey);
// 3. 设置Redis key过期时间(按天过期,避免key堆积)
if (incrId != null && incrId == 1) {
// 首次生成时设置过期时间(2天)
redisTemplate.expire(redisKey, 2, TimeUnit.DAYS);
}
// 4. 构建带业务前缀的ID(增强语义)
return String.format("gift\_%d\_%s\_%d", giftType, date, incrId);
}
// 优化:本地缓存ID(减少Redis访问,适合极高并发)
private volatile Long localCacheId;
private volatile long cacheExpireTime;
public String generateGiftIdWithLocalCache(int giftType) {
long currentTime = System.currentTimeMillis();
// 1. 检查本地缓存是否过期
if (localCacheId == null || currentTime > cacheExpireTime) {
// 2. 从Redis获取自增ID(一次获取100个,批量缓存)
String date = DATE\_FORMAT.format(new Date());
String redisKey = REDIS\_KEY\_PREFIX + date;
Long batchId = redisTemplate.opsForValue().increment(redisKey, 100);
// 一次增100
if (batchId == null) {
throw new RuntimeException("Redis自增ID获取失败");
}
// 3. 更新本地缓存(起始ID=batchId-100,过期时间=当前+5分钟)
localCacheId = batchId - 100;
cacheExpireTime = currentTime + CACHE\_EXPIRE\_MINUTES \* 60 \* 1000;
}
// 4. 本地缓存ID递增
long currentId = localCacheId++;
// 5. 构建最终ID
String date = DATE\_FORMAT.format(new Date());
return String.format("gift\_%d\_%s\_%d", giftType, date, currentId);
}
// 测试:生成10个礼物ID
public static void main(String\[] args) {
// 模拟Spring注入RedisTemplate(实际项目中由Spring管理)
GiftIdGenerator generator = new GiftIdGenerator();
for (int i = 0; i <
10; i++) {
// 输出示例:gift\_1\_20240520\_123456
System.out.println(generator.generateGiftId(1));
}
}
}5.3.4 4. Redis 集群一致性保障(RedLock)
若 Redis 集群存在脑裂风险(主节点下线,从节点未同步完数据),可使用 RedLock(红锁)确保 ID 生成一致性:
部署 3 个独立的 Redis 集群(无主从关系);
生成 ID 时,向 3 个集群同时执行
INCR命令;至少 2 个集群执行成功,才认为 ID 生成有效,避免脑裂导致的 ID 重复。
RedLock 实现代码(Java + Redisson):
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import java.util.concurrent.TimeUnit;
public class RedLockGiftIdGenerator
{
// 3个独立Redis集群地址
private static final String REDIS\_CLUSTER\_1 = "redis://192.168.1.100:6379";
private static final String REDIS\_CLUSTER\_2 = "redis://192.168.1.101:6379";
private static final String REDIS\_CLUSTER\_3 = "redis://192.168.1.102:6379";
// 初始化3个Redisson客户端
private RedissonClient redisson1 = createRedissonClient(REDIS\_CLUSTER\_1);
private RedissonClient redisson2 = createRedissonClient(REDIS\_CLUSTER\_2);
private RedissonClient redisson3 = createRedissonClient(REDIS\_CLUSTER\_3);
// 创建Redisson客户端
private RedissonClient createRedissonClient(String address) {
Config config = new Config();
config.useSingleServer().setAddress(address).setPassword("Redis@123456");
return Redisson.create(config);
}
// RedLock生成礼物ID
public String generateGiftIdWithRedLock(int giftType) {
String date = new SimpleDateFormat("yyyyMMdd").format(new Date());
String redisKey = "gift:id:" + date;
long incrId = 0;
int successCount = 0;
// 1. 向3个Redis集群执行INCR
try {
// 集群1执行
Long id1 = redisson1.getBucket(redisKey).incrementAndGet();
if (id1 != null) {
successCount++;
incrId = id1;
}
// 集群2执行
Long id2 = redisson2.getBucket(redisKey).incrementAndGet();
if (id2 != null) {
successCount++;
incrId = id2;
}
// 集群3执行
Long id3 = redisson3.getBucket(redisKey).incrementAndGet();
if (id3 != null) {
successCount++;
incrId = id3;
}
// 2. 至少2个集群成功,才返回ID
if (successCount >= 2) {
return String.format("gift\_%d\_%s\_%d", giftType, date, incrId);
} else {
throw new RuntimeException("RedLock ID生成失败:成功集群数=" + successCount);
}
} finally {
// 3. 关闭Redisson客户端(实际项目中无需关闭,全局单例)
// redisson1.shutdown();
// redisson2.shutdown();
// redisson3.shutdown();
}
}
}5.4 故障案例:Redis 宕机导致 ID 生成中断
5.4.1 问题背景
某短视频平台用 Redis 自增生成评论 ID,Redis 主节点宕机后,哨兵未及时切换从节点,导致评论服务无法生成 ID,评论功能中断 5 分钟。
5.4.2 根因分析
Redis 集群仅部署 1 主 1 从,从节点同步延迟(约 1 秒),主节点宕机后,从节点数据未完全同步;
哨兵切换超时(配置为 5 秒),期间服务无法访问 Redis;
评论服务无 “降级方案”,Redis 不可用时直接抛出异常,导致业务中断。
5.4.3 解决方案
部署 Redis 集群(3 主 3 从),减少单点故障风险;
缩短哨兵切换时间(配置
down-after-milliseconds=1000,failover-timeout=2000);服务添加降级方案:Redis 不可用时,临时使用 “本地自增 + 节点 ID” 生成 ID(如
comment_123_456,123 = 节点 ID,456 = 本地自增),Redis 恢复后合并数据;配置 Redis 持久化(AOF+RDB),避免宕机后数据丢失。
5.5 避坑总结
✅ 适用场景:极高并发(10 万 + QPS)、无强有序要求、轻量依赖的场景(礼物 / 评论 / 点赞);
❌ 不适用场景:需强有序 ID、Redis 集群维护成本高的场景;
⚠️ 必避坑点:
Redis 必须部署集群(主从 + 哨兵),避免单点故障;
用 “按日期分片” 的 Redis key(如
gift:id:20240520),避免单 key 自增过大;必须配置持久化(AOF+RDB),防止 Redis 宕机后 ID 重置;
服务需添加降级方案,Redis 不可用时确保业务不中断。
六、方案对比与选型指南
6.1 四大方案核心指标对比
| 方案 | 唯一性 | 有序性 | 性能(QPS) | 可用性 | 依赖服务 | 适用场景 |
|---|---|---|---|---|---|---|
| UUID / 优化版 | 高 | 低 | 10 万 + | 高 | 无 | 内部系统、低并发、无有序要求 |
| 数据库分段 / 号段 | 高 | 高 | 1 万 - 10 万 | 中 | 数据库 | 分库分表、中低并发、强有序 |
| 雪花算法 | 高 | 高 | 10 万 + | 中 | ZooKeeper / 配置中心 | 高并发、强有序、水平扩容 |
| Redis 自增 | 高 | 中 | 10 万 + | 高 | Redis 集群 | 极高并发、无强有序、轻量依赖 |
6.2 选型决策树
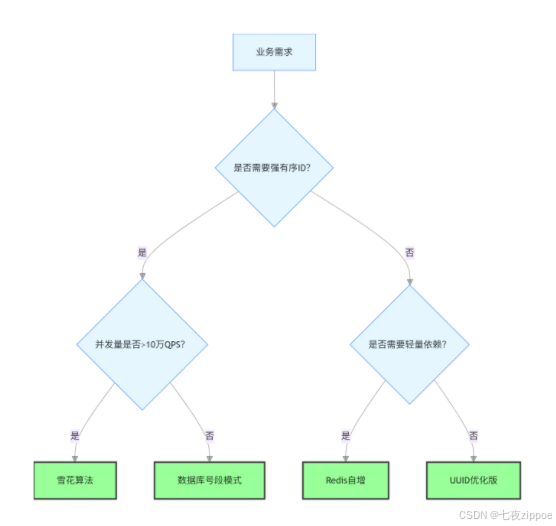
6.3 实战选型案例
电商订单系统:强有序、并发 5 万 QPS→雪花算法;
物流单号系统:强有序、分库分表、并发 1 万 QPS→数据库号段模式;
直播礼物系统:无强有序、并发 10 万 QPS→Redis 自增;
内部 CRM 系统:无强有序、并发 1 千 QPS→UUID 优化版;
支付流水系统:强有序、高可用、并发 8 万 QPS→雪花算法(ZooKeeper+Redis 冗余校验)。
七、总结:分布式 ID 生成的核心原则
唯一性优先:无论选择哪种方案,全局无重复是底线(可通过冗余校验、机器 ID、时间戳确保);
性能匹配业务:低并发用简单方案(UUID),高并发用复杂方案(雪花 / Redis),避免过度设计;
可用性兜底:所有方案需考虑单点故障(如数据库主从、Redis 集群、ZooKeeper 集群),并添加降级方案;
可扩展预留:机器 ID、号段大小、Redis key 分片等设计需预留扩容空间(如雪花算法支持 1024 个节点);
故障早发现:添加 ID 生成监控(如 Prometheus 监控 ID 生成耗时、重复率),并配置告警(如生成耗时 > 1ms、重复率 > 0)。
通过本文的 4 大方案拆解与实战案例,你可根据业务场景快速选型,并避开 90% 的落地坑,真正实现 “分布式 ID 生成” 从理论到落地的无缝衔接。