本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
本文 的 原文 地址
尼恩说在前面
在45岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题:
-
什么是 JIT,JIT什么优势?什么是 类的生命周期七个阶段 ?
-
什么是 字节码增强?
最近有小伙伴在面试京东、 阿里、希音等大厂,又遇到了相关的面试题。 小伙伴 没系统梳理, 支支吾吾的说了几句,面试官不满意, 挂了。
针对上面的面试题, 接下来 尼恩结合互联网上的一些实际案例, 大家做一下系统化、体系化的梳理。 使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
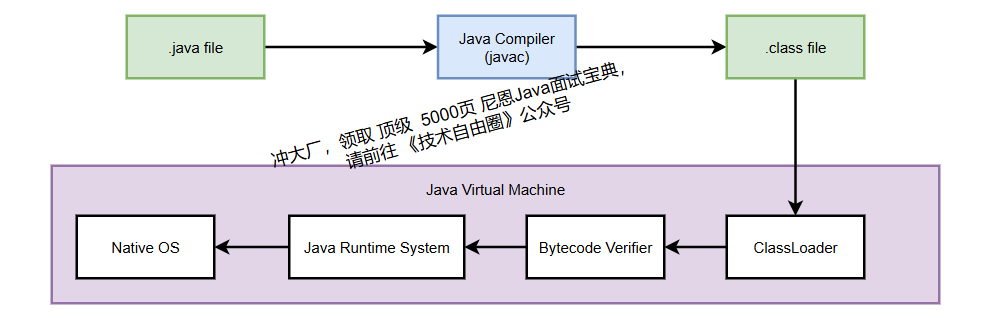
一、字节码文件
1、什么是字节码?
在Java之前, 跨平台 是一个难题。 而 Java 跨平台 的优势: “一次编译,到处运行” 。
构成 Java 生态 跨平台 的基石—— Java 字节码。
无论在何种环境下编译,Java 源代码都能生成标准格式的字节码(.class 文件),由 JVM 解释执行。
为啥要从 字节码入手。
对开发者而言,了解字节码有助于更深入、直观地理解 Java 语言的底层机制。
例如,通过查看字节码,可以清楚地看到
volatile关键字是如何生效的。例如,字节码增强技术在 Spring AOP、ORM 框架及热部署等领域应用广泛,掌握其原理对我们大有裨益。
还有,由于 JVM 规范的标准性,任何能生成符合规范的字节码的程序都可以在 JVM 上运行,因此像 Scala、Groovy、Kotlin 等 JVM 语言也有机会扩展 Java 不具备的特性或实现更友好的语法糖。
从字节码的视角学习这些语言,往往能够更深刻地理解其设计思路。
我们通常使用 javac命令将 .java源文件编译为字节码文件
字节码文件由十六进制数值构成,JVM 按一组两个十六进制值(即一个字节)为单位进行读取。
2、字节码文件的结构
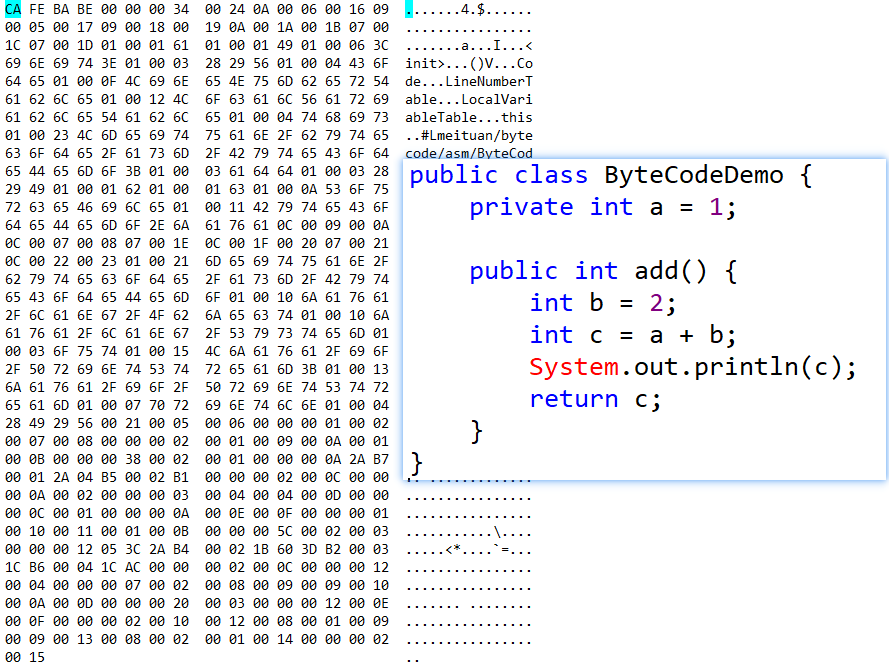
.java文件经 javac编译后生成 .class文件。
编译后得到的 ByteCodeDemo.class文件以十六进制形式打开后,表现形式如下:
JVM 规范要求字节码文件必须按以下十部分顺序构成:
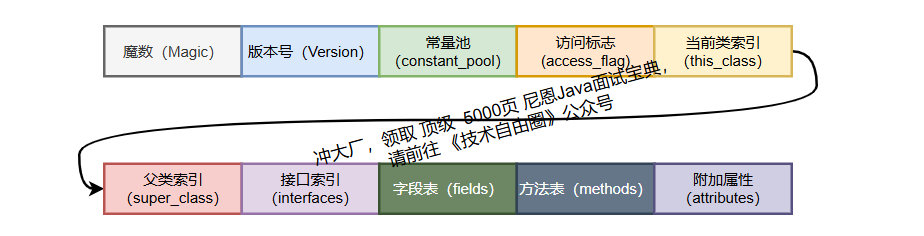
(1)魔数(Magic Number)
每个 .class文件的前 4 个字节是固定的魔数值:0xCAFEBABE。
JVM 通过该标志,快速判断文件是否为可能有效的字节码文件。
有趣的是,魔数“CAFEBABE”由 Java 之父 James Gosling 指定,意为“Cafe Babe”(咖啡宝贝),而 Java 的图标正是一杯咖啡。
(2)版本号
魔数之后的 4 个字节是版本号信息:前 2 个字节表示次版本号(Minor Version),后 2 个字节表示主版本号(Major Version)。
例如 00 00 00 34表示次版本号为 0,主版本号为 52(十六进制 0x34),对应 Java 8。
(3)常量池(Constant Pool)
版本号之后是常量池,它是字节码文件中的资源仓库,主要存放两大类常量:
- 字面量:如
final修饰的常量值、文本字符串等; - 符号引用:包括类/接口的全限定名、字段名称与描述符、方法名称与描述符等。
常量池的结构分为两部分:
- 常量池计数器(constant_pool_count):2 个字节,表示常量池中的常量数量(实际数量为
计数值 - 1); - 常量池数据区:由多个
cp_info表项组成,每个cp_info对应一个常量。
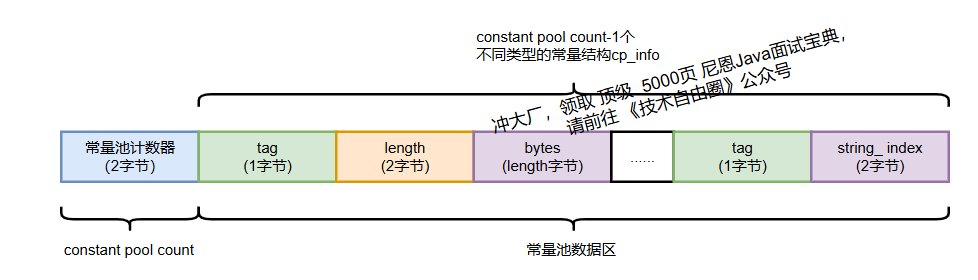
JVM 共定义了 14 种 cp_info类型,其通用结构如下:
cp_info {u1 tag; // 常量类型标识u2 info_length; // 后续信息长度(视类型而定)u1 bytes[info_length]; // 具体数据内容
}
通过 javap -verbose ByteCodeDemo可查看反编译后的常量池内容,更直观易懂:

(4)访问标志(Access Flags)
常量池后的 2 个字节是访问标志,用于标识类或接口的访问权限及属性,例如是否为 public、final、abstract等。
JVM 使用位掩码表示多个标志组合,例如 public final类对应的标志值为 0x0001 | 0x0010 = 0x0011。
常见访问标志如下:
| 标志名 | 十六进制值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | public类型 |
| ACC_FINAL | 0x0010 | final类型 |
| ACC_SUPER | 0x0020 | 使用invokespecial指令 |
| ACC_INTERFACE | 0x0200 | 接口 |
| ACC_ABSTRACT | 0x0400 | 抽象类或接口 |
| ACC_SYNTHETIC | 0x1000 | 合成类型 |
| ACC_ANNOTATION | 0x2000 | 注解类型 |
| ACC_ENUM | 0x4000 | 枚举类型 |
(5)当前类名
访问标志后的 2 个字节是一个索引值,指向常量池中该类全限定名的字符串常量。
(6)父类名称
当前类名后的 2 个字节也是一个索引值,指向常量池中父类的全限定名字符串。
(7)接口信息
父类名称后是接口计数器(2 字节)及接口索引列表,列出所有实现的接口在常量池中的索引。
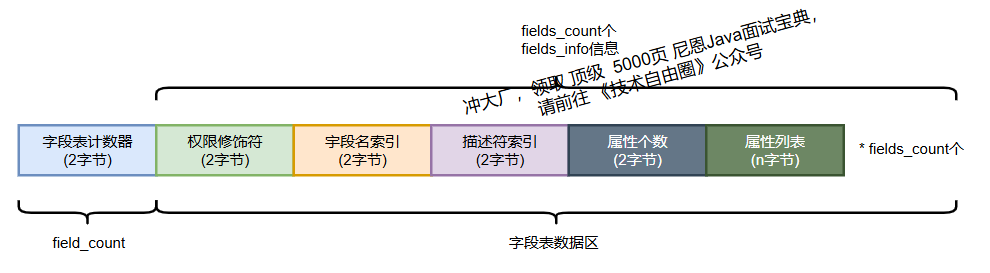
(8)字段表(Fields Table)
字段表用于描述类中声明的字段(类变量和实例变量),不包括方法内的局部变量。结构分为两部分:
- 字段计数器(2 字节):表示字段个数;
- 字段信息表(field_info):每个字段的详细信息。
字段信息结构如下:
field_info {u2 access_flags; // 访问标志,如private、static等u2 name_index; // 字段名在常量池中的索引u2 descriptor_index;// 字段描述符(如I表示int)索引u2 attributes_count;// 属性个数attribute_info attributes[attributes_count]; // 属性表
}
案例中private int a,0002对应为Private。
通过索引下标在常量池查询#7号常量,得到字段名为“a”,描述符为“I”(代表int)。
综上,就可以唯一确定出一个类中声明的变量private int a。

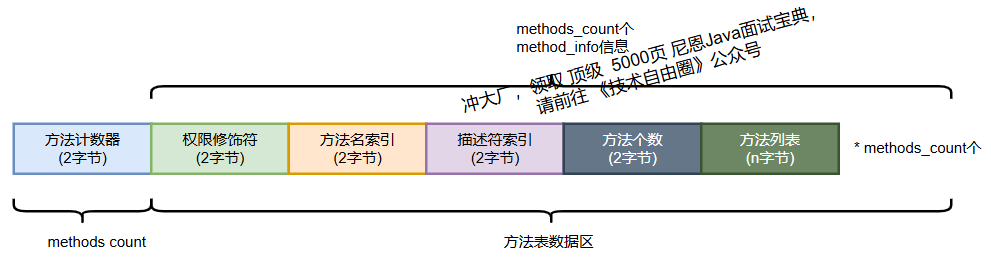
(9)方法表(Methods Table)
方法表存储所有方法的信息,也分为两部分:
- 方法计数器(2 字节):表示方法个数;
- 方法信息表(method_info):每个方法的详细信息。
方法信息结构如下:
method_info {u2 access_flags; // 访问标志,如public、synchronized等u2 name_index; // 方法名在常量池中的索引u2 descriptor_index; // 方法描述符(如()V)索引u2 attributes_count; // 属性个数attribute_info attributes[attributes_count]; // 属性表
}
通过 javap -verbose可查看方法表的详细信息,可以看到主要包括以下三个部分:
- “Code区”:源代码对应的JVM指令操作码,在进行字节码增强时重点操作的就是“Code区”这一部分。
- “LineNumberTable”:行号表,将Code区的操作码和源代码中的行号对应,Debug时会起到作用(源代码走一行,需要走多少个JVM指令操作码)。
- “LocalVariableTable”:本地变量表,包含This和局部变量,之所以可以在每一个方法内部都可以调用This,是因为JVM将This作为每一个方法的第一个参数隐式进行传入。当然,这是针对非Static方法而言。

(10)附加属性表(Additional Attributes)
字节码文件的最后部分可包含自定义属性信息,如源文件名称、注解信息等。
3、字节码指令集
JVM 字节码指令是堆栈导向的,操作码长度为一个字节(0x00~0xFF),最多支持 256 条指令。
Java 虚拟机规范定义了丰富的指令集,包括算术运算、类型转换、对象创建、方法调用等类别。
以下是一些常见指令示例:
| 指令助记符 | 操作码(十六进制) | 功能说明 |
|---|---|---|
| iconst_2 | 0x05 | 将int型常量2压入操作数栈 |
| istore_1 | 0x3C | 将栈顶int值存入局部变量槽1 |
| iadd | 0x60 | 弹出栈顶两个int值,相加后压回 |
| ireturn | 0xAC | 返回int类型结果 |
完整指令集可参考 Oracle 官方文档。
在上图中,Code区的红色编号0~17,就是.java中的方法源代码编译后让JVM真正执行的操作码,也就是完整的add()方法的实现
4、操作数栈与字节码执行
JVM的指令集是基于栈而不是寄存器,基于栈可以具备很好的跨平台性(因为寄存器指令集往往和硬件挂钩),
但缺点在于,要完成同样的操作,基于栈的实现需要更多指令才能完成(因为栈只是一个FILO结构,需要频繁压栈出栈)。
另外,由于栈是在内存实现的,而寄存器是在CPU的高速缓存区,相较而言,基于栈的速度要慢很多,这也是为了跨平台性而做出的牺牲。
这也是为啥 java 比 go 慢的原因之一。
JVM:基于栈的虚拟机,这个是java慢的一个核心原因之一
- JVM 字节码 是一种中间语言,运行在虚拟机上。
- 它的指令操作主要依赖于操作数栈(operand stack),而不是寄存器。
- 例如,
iadd指令会从栈顶弹出两个整数,相加后再压回栈中。- 优点:指令集简洁,跨平台,容易实现。
- 缺点:性能相对较低,因为频繁的栈操作。
Go 基于寄存器的机器码,这个是Go 快的一个核心原因之一
- Go 是静态编译型语言,编译器(如
gc)会将 Go 代码直接编译成目标平台的机器码(如 x86-64、ARM)。- 这些机器码是基于寄存器的,因为现代 CPU 架构(如 x86、ARM)本身就是寄存器架构。
- Go 编译器在生成代码时,会使用寄存器来存储变量、参数、返回值等,而不是像 JVM 那样用栈。
- 所以,Go 的“指令集”其实就是目标平台的机器指令集,是寄存器驱动的。
我们在上文所说的操作码或者操作集合,其实控制的就是这个JVM的操作数栈。
为了更直观地感受操作码是如何控制操作数栈的,以及理解常量池、变量表的作用,这里 将add()方法的对操作数栈的操作制作为GIF动图,如下图所示。
GIF动图中,仅截取了常量池中被引用的部分,以指令iconst_2开始到ireturn结束,与方法表Code区0~17的指令一一对应:
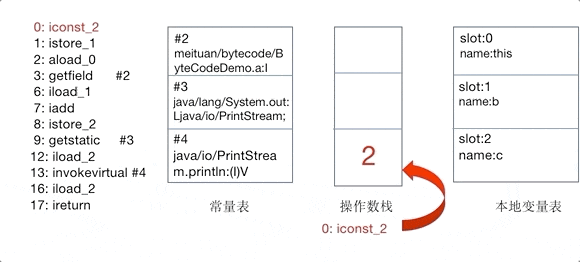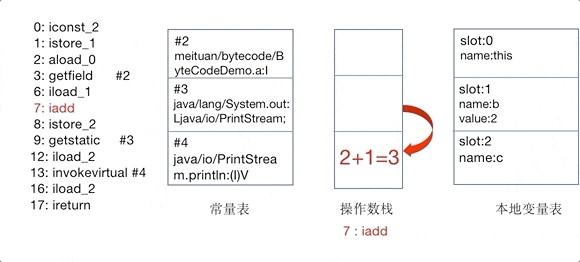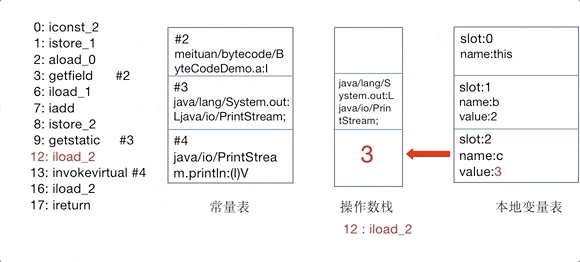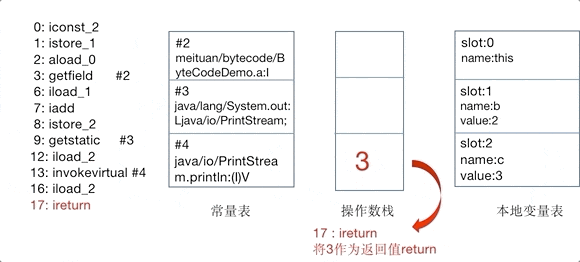
基于栈的设计使 JVM 具有良好的跨平台性,但执行性能可能不如基于寄存器的架构。
为了缓解性能问题,JVM 引入了 JIT(即时编译)技术,将热点代码编译为本地机器码执行。
理论 上, JIT 最终吐出来的东西一定是“基于寄存器的真正机器码”,因为只有这样才能在物理 CPU 上直接跑。
但JIT 不是一次性把整个 Java 字节码“平移”成机器码,而是先把基于栈的 byte-code 当输入,经过一次“栈→寄存器”的转换,再生成宿主 CPU 的寄存器指令。
下面把流程拆开说清:
1、输入:基于栈的字节码
例:
iload_1
iload_2
iadd
istore_3语义:把局部变量 1、2 压栈 → 弹出两个 int 相加 → 结果存回局部变量 3。
全程没有寄存器名字,只有深度为 2 的 operand stack。
2、JIT 编译器(C1/C2/Graal 等)做的核心事情
a. 字节码解析 + 类型推导 → 得到一个有类型的“栈机器”中间表示(IR)。
b. “栈调度”(stack-to-register allocation):把每条 push/pop 映射到虚拟寄存器(SSA 值)。
c. 全局寄存器分配(图着色、线性扫描等):把虚拟寄存器再映射到物理寄存器(x86 的 rax/rbx/rsi…)。
d. 指令选择:生成真正的 ADD、MOV、LEA… 指令。
e. 优化 + 重排 + 发射:最终得到可在 CPU 上直接运行的机器码片段。
3、 输出:基于寄存器的机器码
上面 4 条字节码可能被 JIT 编译成(x86-64):
mov eax, [rbp+local_1] ; eax = local_1
add eax, [rbp+local_2] ; eax += local_2
mov [rbp+local_3], eax ; local_3 = eax已经没有 operand stack 的影子,完全使用寄存器与内存操作数。
JIT 的输入是“基于栈的字节码”,输出是“基于寄存器的本地机器码”;中间经过把栈语义等价变换成寄存器语义的编译过程。
5、查看字节码的工具
除了使用 javap命令反编译字节码外,推荐使用 IntelliJ IDEA 插件 jclasslib可视化查看字节码细节。
安装后,通过菜单栏的 “View” → “Show Bytecode With jclasslib” 即可查看当前类的字节码信息,包括常量池、方法表、属性表等,界面直观友好。
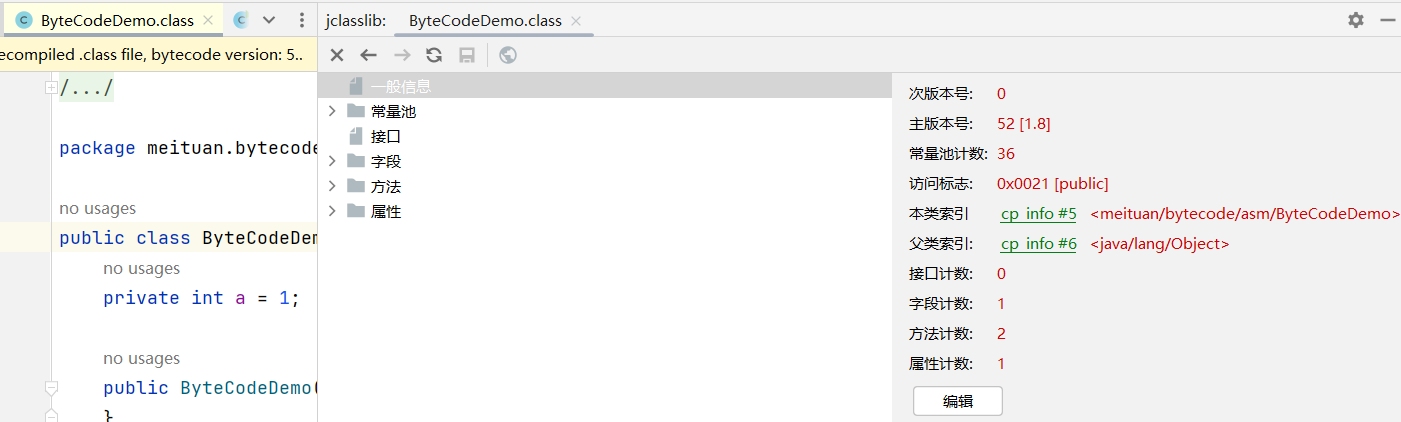
掌握字节码结构与指令集,不仅有助于我们深入理解 Java 程序的运行机制,也是学习高级主题如字节码增强、性能优化的重要基础。
二、类装载机制
类的装载就是将字节码文件加载到JVM中的过程
1、类的入口点
在深入探讨JVM如何加载.class文件之前,先回顾一下C语言的执行过程。
一个简单的C程序:
#include <stdio.h>
int main() {printf("Hello, World! \n");return 0;
}编辑完保存为hello.c文本文件,然后安装gcc编译器(GNU C/C++)
$ gcc hello.c
$ ./a.out
Hello, World!这个过程就是gcc编译器将hello.c文本文件编译成机器指令集,然后读取到内存直接在计算机的CPU运行。
从操作系统层面看的话,就是一个进程的启动到结束的生命周期。
而Java的执行方式,和c 有所不同。
我们编写一个HelloWorld类:
public class HelloWorld {public static void main(String[] args) {System.out.println("my classLoader is " + HelloWorld.class.getClassLoader());}
}需要通过两个步骤执行:
$ javac HelloWorld.java # 编译
$ java HelloWorld # 执行这里的关键区别在于:执行Java程序时,操作系统启动的是java命令对应的进程(即JVM),而HelloWorld类只是传递给这个进程的参数。
JVM会寻找并执行指定类中的main方法作为程序入口。
Java的main方法有严格的格式要求,必须是public static void main(String[] args)。
我们可以通过实验验证这些要求的必要性:
- 去掉public修饰符:JVM会报错,因为需要访问权限
- 去掉static修饰符:JVM会报错,因为需要能够不创建实例就调用
- 修改返回类型:JVM会报错,因为需要统一的void返回类型
- 更改方法名:JVM会报错,因为找不到约定的入口方法
这些规则确保了JVM能够以统一的方式启动任何Java程序。
从底层实现来看,java命令(由C++编写)通过JNI(Java Native Interface)调用Java的main方法。
源码简化后的调用逻辑如下:
// 获取主类名
mainClassName = GetMainClassName(env, jarfile);// 加载主类
mainClass = LoadClass(env, classname);// 获取main方法ID
mainID = (*env)->GetStaticMethodID(env, mainClass, "main", "([Ljava/lang/String;)V");// 调用main方法
(*env)->CallStaticVoidMethod(env, mainClass, mainID, mainArgs);2、类的生命周期七个阶段
当我们编写一个Java类并运行它时,这个类在JVM中会经历完整的生命周期。
理解这个过程对于掌握JVM工作原理至关重要。
一个类在JVM中的完整生命周期包括7个阶段:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)。
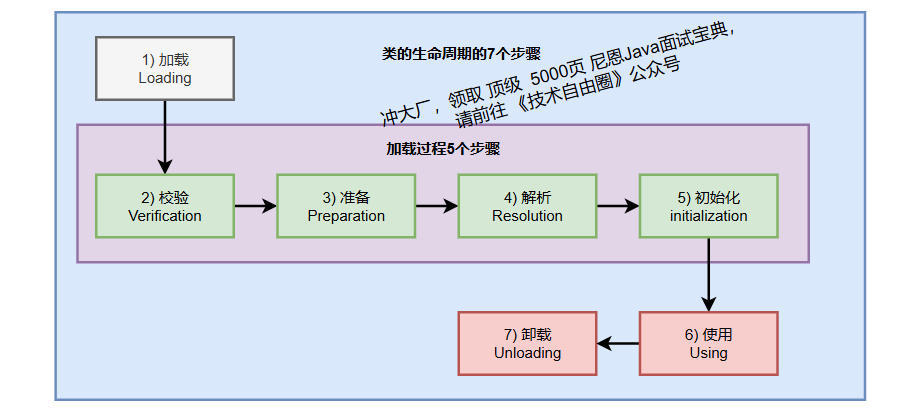
前五个阶段(加载到初始化)统称为类加载过程。
下面我们详细分析每个阶段的具体工作。
2.1 加载阶段(Loading)
加载是类生命周期的起点,主要任务是找到类的二进制表示并将其加载到内存中。
核心操作:
- 根据类的全限定名(如
java.lang.String)定位class文件 - 读取class文件的二进制字节流
- 将字节流转换为方法区的运行时数据结构
- 在堆内存中生成一个代表该类的
java.lang.Class对象,作为访问方法区数据的入口
技术细节:
加载阶段由类加载器(ClassLoader)具体执行。JVM内置了三级类加载器:
- 启动类加载器(Bootstrap ClassLoader):加载JRE核心库
- 扩展类加载器(Extension ClassLoader):加载扩展库
- 应用类加载器(Application ClassLoader):加载用户类路径上的类
如果找不到指定的类文件,JVM会抛出NoClassDefFoundError。值得注意的是,加载阶段并不检查class文件的语法和格式是否正确,这些检查会在后续阶段进行。
2.2 验证阶段(Verification)
验证是连接过程的第一步,确保被加载的类符合JVM规范且不会危害虚拟机安全。
这个阶段就像是对进口商品进行海关检查,防止有害内容进入国内。
验证内容包括:
(1) 文件格式验证:检查魔数(CAFEBABE)、版本号等基本信息
(2) 元数据验证:对类的元数据进行语义检查,如是否有父类、是否实现所有抽象方法等
(3) 字节码验证:通过数据流和控制流分析,验证程序逻辑的合理性
(4) 符号引用验证:检查常量池中的符号引用能否正确解析
可能抛出的异常:
VerifyError:验证失败ClassFormatError:类格式错误UnsupportedClassVersionError:版本不支持
验证过程中可能需要加载其他相关类,如果发现类层次结构问题(如循环继承),JVM会抛出ClassCircularityError。
2.3 准备阶段(Preparation)
准备阶段为类变量分配内存并设置初始值。这些变量指的是被static修饰的静态变量,不包括实例变量。
关键特点:
- 分配内存:在方法区中为静态变量分配内存空间
- 设置默认值:为静态变量赋予类型默认值(0、false、null等)
- 不执行代码:此阶段不会执行任何Java代码或赋值语句
示例分析:
public static int value = 123; // 准备阶段后value的值为0,而非123
public static final int CONST = 456; // 准备阶段后CONST的值就是456对于final静态常量,某些JVM实现会直接在此阶段赋值,这是因为常量的值在编译期就能确定。
这种差异有时会让开发者感到困惑,特别是从其他语言(如C#)转来的开发者。
2.4 解析阶段(Resolution)
解析阶段将常量池中的符号引用转换为直接引用。这个过程就像是将地址簿中的名称转换为实际的家庭住址。
解析内容:
- 类或接口解析:将类名解析为实际类引用
- 字段解析:将字段符号引用解析为具体字段
- 方法解析:将方法符号引用解析为具体方法
- 接口方法解析:将接口方法符号引用解析为具体实现
技术细节:
符号引用是一组描述被引用目标的符号,包含在class文件的常量池中。直接引用则可以是直接指向目标的指针、相对偏移量或能间接定位到目标的句柄。
解析阶段可以在初始化之后进行,这是Java语言"运行时绑定"特性的基础。JVM实现可以根据需要灵活选择解析时机,采用惰性解析策略以提高性能。
2.5 初始化阶段(Initialization)
初始化是类加载过程的最后一步,真正开始执行类中定义的Java代码。
触发条件:
JVM规范严格规定,只有在类首次被"主动使用"时才进行初始化。主动使用包括:
- 创建类的实例
- 访问类的静态变量或静态方法
- 使用反射调用类方法
- 初始化子类会触发父类初始化
- 包含main方法的启动类
初始化内容:
- 执行静态变量赋值语句
- 执行静态代码块(static{})
- 执行类构造器
<clinit>()方法
2.6 使用和卸载阶段
初始化完成后,类就进入了使用阶段,可以被正常实例化和调用了。当类不再被需要时,可能进入卸载阶段。
使用阶段:
类完全加载后,应用程序可以创建实例、调用方法、访问字段等。这是类生命周期中最长的阶段。
卸载条件:
当满足以下条件时,类可以被卸载:
- 该类的所有实例都已被回收
- 加载该类的ClassLoader已被回收
- 该类对应的Class对象没有被任何地方引用
卸载类的过程由JVM的垃圾收集器完成,开发者通常不需要关心这个过程。
2.7 惰性加载(Lazy Loading)机制
HotSpot JVM为了提高性能,采用了许多优化策略。
其中最重要的是惰性加载(Lazy Loading)机制:除非必要,否则不会提前加载和链接类。
示例说明:
class A {static {System.out.println("A初始化");}
}class B {static {System.out.println("B初始化");}public static void method() {System.out.println("B的方法被调用");}
}public class LazyLoadingDemo {public static void main(String[] args) {A a = null; // 不会触发A的初始化System.out.println("A的引用已创建");B.method(); // 第一次主动使用B,触发B的初始化}
}输出结果:
A的引用已创建
B初始化
B的方法被调用这种惰性加载策略显著提高了JVM的启动性能和内存使用效率。
只有当一个类被真正"主动使用"时,JVM才会执行完整的加载、链接和初始化过程。
3、类加载器
在JVM执行main方法之前,首先需要找到对应的.class文件并将其加载到内存中。
这个任务由类加载器(ClassLoader)完成。
从操作系统层面看,类加载本质上就是JVM进程通过I/O操作从磁盘或网络读取.class文件的二进制数据,然后将其存入内存的特定区域。
如果单纯从技术实现角度考虑,类加载可以用很简单的代码实现:
C语言版本:
char *fgets(char *buf, int n, FILE *fp);Java版本:
InputStream f = new FileInputStream("HelloWorld.class");但如果只是简单地将类文件读入内存,没有良好的组织和管理机制,JVM将无法高效地使用这些类。
因此,JVM设计了一套完整的类加载体系结构。
3.1 系统内置的类加载器
...................由于平台篇幅限制, 剩下的内容(5000字+),请参参见原文地址
原始的内容,请参考 本文 的 原文 地址
本文 的 原文 地址