Spring 事务
详情请查看:Spring 事务
Spring 事务实现方式有哪些?
事务就是一系列的操作原子执行。Spring事务机制主要包括声明式事务和编程式事务。
- 编程式事务:通过编程的方式管理事务,这种方式带来了很大的灵活性,但很难维护。
- 声明式事务:将事务管理代码从业务方法中分离出来,通过aop进行封装。Spring声明式事务使得我们无需要去处理获得连接、关闭连接、事务提交和回滚等这些操作。使用
@Transactional注解开启声明式事务。
@Transactional相关属性如下:
| 属性 | 类型 | 描述 |
|---|---|---|
| value | String | 可选的限定描述符,指定使用的事务管理器 |
| propagation | enum: Propagation | 可选的事务传播行为设置 |
| isolation | enum: Isolation | 可选的事务隔离级别设置 |
| readOnly | boolean | 读写或只读事务,默认读写 |
| timeout | int (in seconds granularity) | 事务超时时间设置 |
| rollbackFor | Class对象数组,必须继承自Throwable | 导致事务回滚的异常类数组 |
| rollbackForClassName | 类名数组,必须继承自Throwable | 导致事务回滚的异常类名字数组 |
| noRollbackFor | Class对象数组,必须继承自Throwable | 不会导致事务回滚的异常类数组 |
| noRollbackForClassName | 类名数组,必须继承自Throwable | 不会导致事务回滚的异常类名字数组 |
说一下 spring 的事务隔离级别?
Spring的事务隔离级别是指在并发环境下,事务之间相互隔离的程度。Spring框架支持多种事务隔离级别,可以根据具体的业务需求来选择适合的隔离级别。以下是常见的事务隔离级别:
- DEFAULT(默认):使用数据库默认的事务隔离级别。通常为数据库的默认隔离级别,如Oracle为READ COMMITTED,MySQL为REPEATABLE READ。
- READ_UNCOMMITTED:最低的隔离级别,允许读取未提交的数据。事务可以读取其他事务未提交的数据,可能会导致脏读、不可重复读和幻读的问题。
- READ_COMMITTED:保证一个事务只能读取到已提交的数据。事务读取的数据是其他事务已经提交的数据,避免了脏读的问题。但可能会出现不可重复读和幻读的问题。
- REPEATABLE_READ:保证一个事务在同一个查询中多次读取的数据是一致的。事务期间,其他事务对数据的修改不可见,避免了脏读和不可重复读的问题。但可能会出现幻读的问题。
- SERIALIZABLE:最高的隔离级别,保证事务串行执行,避免了脏读、不可重复读和幻读的问题。但会降低并发性能,因为事务需要串行执行。
通过@Transactional注解的isolation属性来指定事务隔离级别。
有哪些事务传播行为?
在TransactionDefinition接口中定义了七个事务传播行为:
PROPAGATION_REQUIRED如果存在一个事务,则支持当前事务。如果没有事务则开启一个新的事务。如果嵌套调用的两个方法都加了事务注解,并且运行在相同线程中,则这两个方法使用相同的事务中。如果运行在不同线程中,则会开启新的事务。PROPAGATION_SUPPORTS如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行。PROPAGATION_MANDATORY如果已经存在一个事务,支持当前事务。如果不存在事务,则抛出异常IllegalTransactionStateException。PROPAGATION_REQUIRES_NEW总是开启一个新的事务。需要使用JtaTransactionManager作为事务管理器。PROPAGATION_NOT_SUPPORTED总是非事务地执行,并挂起任何存在的事务。需要使用JtaTransactionManager作为事务管理器。PROPAGATION_NEVER总是非事务地执行,如果存在一个活动事务,则抛出异常。PROPAGATION_NESTED如果一个活动的事务存在,则运行在一个嵌套的事务中。如果没有活动事务, 则按PROPAGATION_REQUIRED 属性执行。
PROPAGATION_NESTED 与PROPAGATION_REQUIRES_NEW的区别:
使用PROPAGATION_REQUIRES_NEW时,内层事务与外层事务是两个独立的事务。一旦内层事务进行了提交后,外层事务不能对其进行回滚。两个事务互不影响。
使用PROPAGATION_NESTED时,外层事务的回滚可以引起内层事务的回滚。而内层事务的异常并不会导致外层事务的回滚,它是一个真正的嵌套事务。
Spring 事务传播行为有什么用?
主要作用是定义和管理事务边界,尤其是一个事务方法调用另一个事务方法时,事务如何传播的问题。它解决了多个事务方法嵌套执行时,是否要开启新事务、复用现有事务或者挂起事务等复杂情况。
总结用途:
- 控制事务的传播和嵌套:根据具体业务需求,可以指定是否使用现有事务或开启新的事务,解决事务的传播问题。
- 确保独立操作的事务隔离:某些操作(如日志记录、发送通知)应当独立于主事务执行,即使主事务失败,这些操作也可以成功完成
- 控制事务的边界和一致性:不同的业务场景可能需要不同的事务边界,例如强制某个方法必须在事务中执行,或者确保某个方法永远不在事务中运行
谈谈对Spring事务和AOP底层实现原理的区别
Spring的声明式事务其实也是通过AOP的这一套底层实现原理实现的,都是通过同一个bean的后置处理器来完成的动态代理创建的,只是:
- 创建动态代理的匹配方式不一样: 区别就是AOP的增强通常是通过切面+切点+通知来完成的, 在创建bean的时候发现bean和切点表达式匹配就会创建动态代理。 而事务内置一个增强类, 在创建bean的时候, 一旦发现你的类加了@Transactional注解 就会创建动态代理。
- 执行动态代理的增强不一样: 在执行AOP的bean时会先执行动态代理的增强类, 通过责任链分别按顺序执行通知。
在执行事务的bean的时候会先执行动态代理的增强类, 在执行目标方法前进行异常捕捉,出现异常回滚事务, 无异常提交事务。
Spring事务在什么情况下会失效?
- 应用在非 public 修饰的方法上
之所以会失效是因为@Transactional 注解依赖于Spring AOP切面来增强事务行为,这个 AOP 是通过代理来实现的
而无论是JDK动态代理还是CGLIB代理,Spring AOP的默认行为都是只代理public方法。
- 被用 final 、static 修饰方法
和上边的原因类似,被用 final 、static 修饰的方法上加 @Transactional 也不会生效。
- static 静态方法属于类本身的而非实例,因此代理机制是无法对静态方法进行代理或拦截的
- final 修饰的方法不能被子类重写,事务相关的逻辑无法插入到 final 方法中,代理机制无法对 final 方法进行拦截或增强。
- 同一个类中方法调用
比如有一个类Test,它的一个方法A,A再调用本类的方法B(不论方法B是用public还是private修饰),但方法A没有声明注解事务,而B方法有。则外部调用方法A之后,方法B的事务是不会起作用的。
那为啥会出现这种情况?其实这还是由于使用Spring AOP代理造成的,因为只有当事务方法被当前类以外的代码调用时,才会由Spring生成的代理对象来管理。
但是如果是A声明了事务,A的事务是会生效的。
- Bean 未被 spring 管理
上边我们知道 @Transactional 注解通过 AOP 来管理事务,而 AOP 依赖于代理机制。因此,Bean 必须由Spring管理实例! 要确保为类加上如 @Controller、@Service 或 @Component注解,让其被Spring所管理,这很容易忽视。
- 异步线程调用
如果我们在 testMerge() 方法中使用异步线程执行事务操作,通常也是无法成功回滚的,来个具体的例子。
假设testMerge() 方法在事务中调用了 testA(),testA() 方法中开启了事务。接着,在 testMerge() 方法中,我们通过一个新线程调用了 testB(),testB() 中也开启了事务,并且在 testB() 中抛出了异常。此时,testA() 不会回滚 和 testB() 回滚。
testA() 无法回滚是因为没有捕获到新线程中 testB()抛出的异常;testB()方法正常回滚。
在多线程环境下,Spring 的事务管理器不会跨线程传播事务,事务的状态(如事务是否已开启)是存储在线程本地的 ThreadLocal 来存储和管理事务上下文信息。这意味着每个线程都有一个独立的事务上下文,事务信息在不同线程之间不会共享。
- 数据库引擎不支持事务
事务能否生效数据库引擎是否支持事务是关键。常用的MySQL数据库默认使用支持事务的innodb引擎。一旦数据库引擎切换成不支持事务的myisam,那事务就从根本上失效了。
- RollbackFor 没设置对,比如默认没有任何(设置 RuntimeException 或者 Error 才能捕获),则方法内抛出 IOException 则不会回滚,需要配置 @Transactional(rollbackFor=Exception.class)。
- 异常被捕获了,比如代码抛错,但是被 catch 了,仅打了 log 没有抛出异常,这样事务无法正常获取到错误,因此不会回滚。
Spring多线程事务 能否保证事务的一致性
在多线程环境下,Spring事务管理默认情况下无法保证全局事务的一致性。这是因为Spring的本地事务管理是基于线程的,每个线程都有自己的独立事务。
- Spring的事务管理通常将事务信息存储在ThreadLocal中,这意味着每个线程只能拥有一个事务。这确保了在单个线程内的数据库操作处于同一个事务中,保证了原子性。
- 可以通过如下方案进行解决:
- 编程式事务: 为了在多线程环境中实现事务一致性,您可以使用编程式事务管理。这意味着您需要在代码中显式控制事务的边界和操作,确保在适当的时机提交或回滚事务。
- 分布式事务: 如果您的应用程序需要跨多个资源(例如多个数据库)的全局事务一致性,那么您可能需要使用分布式事务管理(如2PC/3PC TCC等)来管理全局事务。这将确保所有参与的资源都处于相同的全局事务中,以保证一致性。
总之,在多线程环境中,Spring的本地事务管理需要额外的协调和管理才能实现事务一致性。这可以通过编程式事务、分布式事务管理器或二阶段提交等方式来实现,具体取决于您的应用程序需求和复杂性。
但在 Seata 框架中,事务一致性是通过分布式事务协调器(TC)来保证的。TC 负责协调分布式事务的各个参与者(RM),确保它们按照相同的顺序执行事务操作,从而保证事务的一致性。 具体来说,当一个事务开始时,TC 会生成一个全局事务 ID(XID),并将其传播给所有的 RM。每个 RM 在执行事务操作时,都会将自己的操作记录到本地事务日志中,并将 XID 和操作记录发送给 TC。TC 会根据 XID 和操作记录,协调各个 RM 的执行顺序,确保它们按照相同的顺序执行事务操作。如果在执行过程中出现异常,TC 会根据事务回滚策略,决定是否回滚事务。 通过这种方式,Seata 框架可以保证分布式事务的一致性,即使在多个节点之间进行事务操作,也可以确保数据的一致性和可靠性。(了解)
@Transactional(rollbackFor = Exception.class)注解了解吗?
Exception 分为运行时异常 RuntimeException 和非运行时异常。事务管理对于企业应用来说是至关重要的,即使出现异常情况,它也可以保证数据的一致性。
当 @Transactional 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。
@Transactional 注解默认回滚策略是只有在遇到RuntimeException(运行时异常) 或者 Error 时才会回滚事务,而不会回滚 Checked Exception(受检查异常)。这是因为 Spring 认为RuntimeException和 Error 是不可预期的错误,而受检异常是可预期的错误,可以通过业务逻辑来处理。
循环依赖
什么是循环依赖?
循环依赖(Circular Dependency)是指两个或多个模块,组件之间相互依赖形成一个闭环。简而言之,
模块A依赖模块B,而模块B又依赖于模块A。这会导依赖链的循环,无法确定加载或初始化的顺序。
Spring怎么解决循环依赖的问题?
解决步骤:
- Spring 首先创建 Bean 实例,并将其加入三级缓存中(Factory)。
- 当一个 Bean 依赖另一个未初始化的 Bean 时,Spring 会从三级缓存中获取 Bean 的工厂,并生成该 Bean 的对象(若有代理则是代理对象)代理对象存入二级缓存,解决循环依赖。
- 一旦所有依赖 Bean 被完全初始化,Bean 将转移到一级缓存中。
详细内容如下:
首先,有两种Bean注入的方式。
构造器注入和属性注入。
- 对于构造器注入的循环依赖,Spring处理不了,会直接抛出
BeanCurrentlylnCreationException异常。 - 对于属性注入的循环依赖(单例模式下),是通过三级缓存处理来循环依赖的。
而非单例对象的循环依赖,则无法处理。
下面分析单例模式下属性注入的循环依赖是怎么处理的:
首先,Spring单例对象的初始化大略分为三步:
createBeanInstance:实例化bean,使用构造方法创建对象,为对象分配内存。populateBean:进行依赖注入。initializeBean:初始化bean。
Spring为了解决单例的循环依赖问题,使用了三级缓存:
- 一级缓存
singletonObjects:完成了初始化的单例对象map,bean name --> bean instance,存完整单例bean。 - 二级缓存
earlySingletonObjects:完成实例化未初始化的单例对象map,bean name --> bean instance,存放的是早期的bean,即半成品,此时还无法使用(只用于循环依赖提供的临时bean对象)。 - 三级缓存
singletonFactories(循环依赖的出口,解决了循环依赖): 单例对象工厂map,bean name --> ObjectFactory,单例对象实例化完成之后会加入singletonFactories。它存的是一个对象工厂,用于创建对象并放入二级缓存中。同时,如果对象有Aop代理,则对象工厂返回代理对象。
这三个 map 是如何配合的呢?
- 首先,获取单例 Bean 的时候会通过 BeanName 先去 singletonObjects(一级缓存)查找完整的 Bean,如果找到则直接返回,否则进行步骤 2
- 看对应的 Bean 是否在创建中,如果不在直接返回找不到(返回null),如果是,则会去 earlySingletonObjects(二级缓存) 查找 Bean,如果找到则返回,否则进行步骤 3
- 去 singletonfactores(三级缓存)通过 BeanName查找到对应的工厂,如果存着工厂则通过工厂创建 Bean,并目放置到earlySingletonObjects 中
- 如果三个缓存都没找到,则返回 null
从上面的步骤我们可以得知,如果查询发现 Bean 还未创建,到第二步就直接返回 null,不会继续查二级和三级缓存。返回 null 之后,说明这个Bean 还未创建,这个时候会标记这个 Bean 正在创建中,然后再调用 createBean 来创建 Bean,而实际创建是调用方法 doCreateBean。
在调用createBeanInstance进行实例化之后,会调用addSingletonFactory,将单例对象放到singletonFactories中。
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {Assert.notNull(singletonFactory, "Singleton factory must not be null");synchronized (this.singletonObjects) {if (!this.singletonObjects.containsKey(beanName)) {this.singletonFactories.put(beanName, singletonFactory);this.earlySingletonObjects.remove(beanName);this.registeredSingletons.add(beanName);}}
}
假如A依赖了B的实例对象,同时B也依赖A的实例对象。
- A首先完成了实例化,并且将自己添加到singletonFactories中
- 接着进行依赖注入,发现自己依赖对象B,此时就尝试去get(B)
- 发现B还没有被实例化,对B进行实例化
- 然后B在初始化的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects和二级缓存earlySingletonObjects没找到,尝试三级缓存singletonFactories,由于A初始化时将自己添加到了singletonFactories,所以B可以拿到A对象,然后将A从三级缓存中移到二级缓存中
- B拿到A对象后顺利完成了初始化,然后将自己放入到一级缓存singletonObjects中
- 此时返回A中,A此时能拿到B的对象顺利完成自己的初始化
由此看出,属性注入的循环依赖主要是通过将实例化完成的bean添加到singletonFactories来实现的。而使用构造器依赖注入的bean在实例化的时候会进行依赖注入,不会被添加到singletonFactories中。比如A和B都是通过构造器依赖注入,A在调用构造器进行实例化的时候,发现自己依赖B,B没有被实例化,就会对B进行实例化,此时A未实例化完成,不会被添加到singtonFactories。而B依赖于A,B会去三级缓存寻找A对象,发现不存在,于是又会实例化A,A实例化了两次,从而导致抛异常。
总结:1、利用缓存识别已经遍历过的节点; 2、利用Java引用,先提前设置对象地址,后完善对象。
Spring有没有解决多例Bean的循环依赖?
- 多例不会使用缓存进行存储(多例Bean每次使用都需要重新创建)
- 不缓存早期对象就无法解决循环
Spring有没有解决构造函数参数Bean的循环依赖?
- 构造函数的循环依赖会报错
- 可以通过人工进行解决:@Lazy
- 就不会立即创建依赖的bean了
- 而是等到用到才通过动态代理进行创建
为什么必须都是单例
如果从源码来看的话,循环依赖的 Bean 是原型模式,会直接抛错:

所以 Spring 只支持单例的循环依赖,但是为什么呢?
按照理解,如果两个Bean都是原型模式的话,那么创建A1需要创建一个B1,创建B1的时候要创建一个A2,创建 A2又要创建一个B2,创建 B2又要创建一个A3,创建 A3 又要创建一个 B3.就又卡 BUG 了,是吧,因为原型模式都需要创建新的对象,不能跟用以前的对象。
如果是单例的话,创建 A 需要创建 B,而创建的 B 需要的是之前的个 A,不然就不叫单例了,对吧?
也是基于这点, Spring 就能操作操作了。
具体做法就是:先创建A,此时的A是不完整的(没有注入B),用个 map 保存这个不完整的A,再创建B,B需要A,所以从那个map 得到“不完整”的A,此时的B就完整了,然后A就可以注入B,然后A就完整了,B也完整了,且它们是相互依赖的。
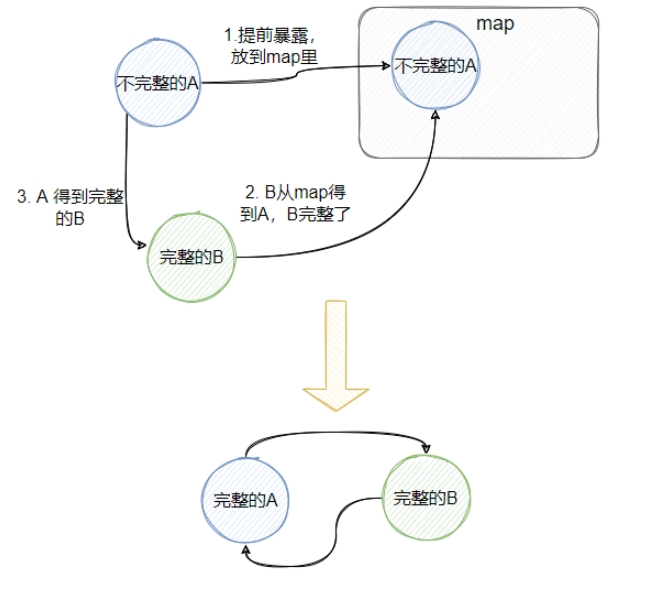
为什么不能全是构造器注入?一个set注入,一个构造器注入一定能成功?
为什么不能全是构造器注入?
在 Spring 中创建 Bean 分三步:
- 实例化,createBeanlnstance,就是 new 了个对象
- 属性注入,populateBean, 就是 set 一些属性值
- 初始化,initializeBean,执行一些 aware 接口中的方法,initMethod,AOP代理等
明确了上面这三点,再结合上面说的“不完整的”,我们来理一下。
如果全是构造器注入,比如A(B b),那表明在 new的时候,就需要得到B,此时需要 new B,但是B也是要在构造的时候注入A,即B(A a),这时候B需要在一个 map 中找到不完整的A,发现找不到。
为什么找不到?因为A 还没 new 完呢,所以找不到完整的 A,因此如果全是构造器注入的话,那么 Spring 无法处理循环依赖。
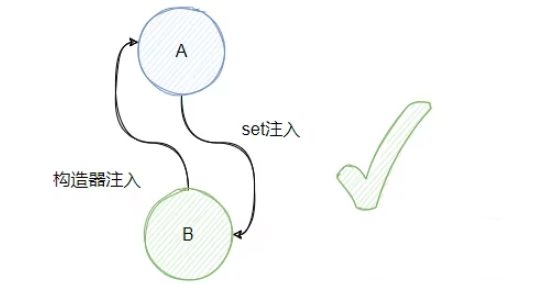
一个set注入,一个构造器注入一定能成功?
假设我们 A 是通过 set 注入 B,B 通过构造函数注入 A,此时是成功的。
我们来分析下:实例化A之后,此时可以在 map中存入A,开始为A进行属性注入,发现需要B,此时 new B,发现构造器需要A,此时从 map中得到A,B构造完毕,B进行属性注入,初始化,然后A注入B完成属性注入,然后初始化 A。
整个过程很顺利,没毛病。
假设 A 是通过构造器注入 B,B 通过 set 注入 A,此时是失败的。
我们来分析下:实例化A,发现构造函数需要B,此时去实例化B,然后进行B 的属性注入,从 map 里面找不到A,因为 A 还没 new 成功,所以B也卡住了,然后就 循环了。
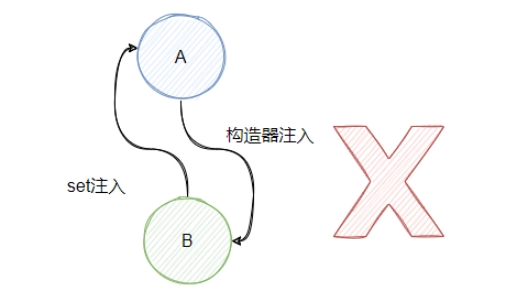
看到这里,仔细思考的小伙伴可能会说,可以先实例化 B,往 map 里面塞入不完整的 B,这样就能成功实例化 A 了。确实,思路没错但是 Spring 容器是按照字母序创建 Bean 的,A 的创建永远排在 B 前面。
现在我们总结一下:
- 如果循环依赖都是构造器注入,则失败
- 如果循环依赖不完全是构造器注入,则可能成功,可能失败,具体跟BeanName的字母序有关系,
二级缓存能不能解决循环依赖?
Spring 之所以需要三级缓存而不是简单的二级缓存,主要原因在于AOP代理和Bean的早期引用问题。
- 如果只是循环依赖导致的死循环的问题: 一级缓存就可以解决 ,但是无法解决在并发下获取不完整的Bean。
- 二级缓存虽然可以解决循环依赖的问题,但在涉及到动态代理(OP)时,直接使用二级缓存不做任问处理会导致我们拿到的 Bean 是未代理的原始对象。如果二级缓存内存放的都是代理对象,则违反了 Bean 的生命周期
Spring一二级缓存和MyBatis一、二级缓存有什么关系?
没有关系!
- MyBatis一、二级缓存是用来存储查询结果的, 一级缓存会在同一个SqlSession中的重复查询结果进行缓存, 二级缓存则是全局应用下的重复查询结果进行缓存。
- 而Spring的一、二级缓存是用来存储Bean的! 一级缓存用来存储完整最终使用的Bean,二级缓存用来存储早期临时bean。 当然还有个三级缓存用来解决循环依赖的。