一:流量暴增的挑战
随着互联网的不断发展,企业面对的流量压力越来越大。突发性的流量暴增可能来自促销活动、热门事件或者恶意攻击等情况。性能测试人员必须提前预见到这些场景,并在系统设计阶段做好应对措施。流量的突然激增不仅可能导致系统性能严重下降,甚至会因为资源消耗过大而导致系统崩溃。
流量暴增的常见影响:
吞吐量下降:系统在流量暴增时,可能会超出其处理能力,导致响应时间延迟,吞吐量显著下降。
系统崩溃:没有充分准备的系统,可能会因为资源耗尽(如 CPU、内存、数据库连接等)导致崩溃。
雪崩效应:微服务架构下,某个服务宕机可能会引发其他服务的连锁反应,最终导致整个系统不可用。
二:如何应对流量暴增?
为了应对流量暴增,系统需要做出合理的设计与调优。以下是几种关键策略:
- 压力测试与容量规划
压力测试是检验系统在极端流量条件下是否能够稳定运行的重要手段。通过模拟流量暴增场景,测试系统的最大承载能力,提前识别潜在的瓶颈,确保系统能在高并发环境中稳定运行。
容量规划需要考虑以下几个方面:
计算每个系统组件的最大负载
确保有足够的冗余,避免单点故障
结合业务增长趋势,进行横向扩展
2. 熔断降级与服务保护
当系统遭遇极限流量时,服务的响应时间会急剧增加,甚至会导致某些服务宕机。熔断机制可以有效防止单个服务故障引发雪崩效应。熔断器的工作原理类似于家用电器的保险丝,当某个服务响应过慢或发生异常时,熔断器会启动,避免继续调用该服务,从而保护系统整体的可用性。
熔断机制的状态:
Closed(关闭):服务正常,继续处理请求。
Open(开启):失败率超过阈值,迅速返回失败,避免资源浪费。
Half-Open(半开启):在一定休眠时间后,尝试恢复服务,判断是否恢复正常。
熔断降级实现框架:
Hystrix
Resilience4j
Sentinel
通过合理配置熔断降级策略,可以确保在极端流量场景下,系统能够自动降级,保证关键业务的正常运行。
- 弹性扩容
弹性扩容是应对流量暴增的另一关键策略。针对无状态应用(如 Web 服务),可以通过 Kubernetes HPA(Horizontal Pod Autoscaler)自动扩展 Pod 数量。对于有状态中间件(如 MySQL、Redis),可以通过读写分离、从库扩展等方式实现横向扩展,从而缓解数据库的读写瓶颈。
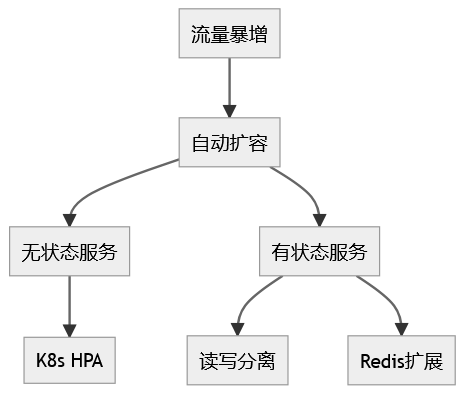
三:监控与预警
在流量暴增时,系统的实时监控至关重要。性能测试人员需要提前配置好日志监控和指标监控,及时发现潜在的瓶颈并采取措施。
- 日志监控分析
通过集成 ELK(Elasticsearch、Logstash、Kibana)或 Loki 等日志系统,测试人员可以实现高效的日志收集与存储。系统日志能够提供详尽的请求信息,帮助我们快速定位性能瓶颈。
日志采样:对于高流量的接口,可以采用采样策略,减轻系统负担。
日志内容分析:通过分析日志中的请求参数、响应状态码等,可以判断哪些接口成为瓶颈,进一步优化。
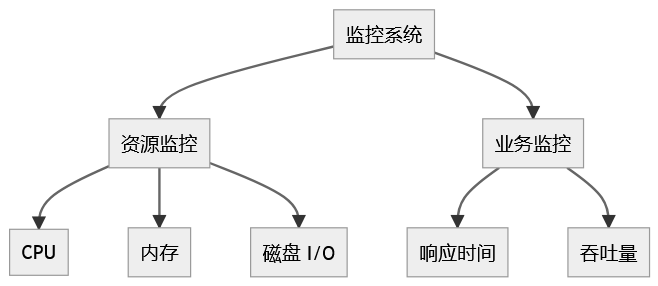
2. 指标监控分析
采用 Prometheus + Grafana 进行系统的资源监控。关键的资源指标包括:
CPU 使用率
内存占用
磁盘 I/O
网络流量
当监控指标达到预设的阈值时,自动触发扩容或优化措施。
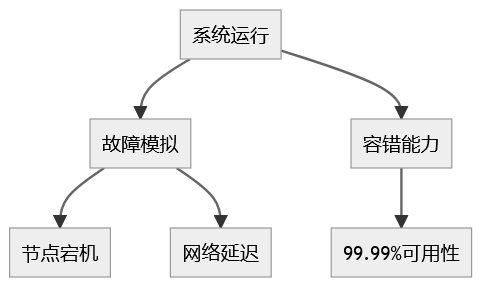
四:混沌工程与容错能力
混沌工程是一种通过故意引入故障的方式,来验证系统在局部故障或分区故障情况下的容错能力。通过模拟网络延迟、服务宕机等场景,测试系统的弹性和可恢复能力。目标是确保系统即使在出现部分故障时,依然能够保持99.99%的可用性。
预防为主,持续优化
性能测试人员不仅要应对现有的流量,还应为未来可能的流量暴增做好充分的准备。通过合理的架构设计、系统优化和压力测试,系统才能在流量激增时保持稳定与高效。
如果你是一个测试从业者,本文为你提供了关于流量暴增时如何应对的系统化思路。无论是熔断机制、弹性扩容,还是监控预警,都是确保系统在高并发场景下稳定运行的关键措施。若你在日常工作中遇到特定的技术难题或痛点,欢迎与我分享,我会进一步补充解决方案。
推荐学习
如果你:
做测试/开发,想突破功能测试瓶颈;
想掌握大厂级别性能测试能力;
想成为团队中能解决“线上性能问题”的关键角色;
👉 那么 高级性能测试训练营,就是为你准备的!
欢迎加入 霍格沃兹测试开发学社,一起真正搞懂 亿级用户系统的性能挑战!
