斯坦福和SambaNova AI最近联合发了一篇论文,Agentic Context Engineering (ACE)。核心思路:不碰模型参数,专注优化输入的上下文。让模型自己生成prompt,反思效果,再迭代改进。
可以把这个过程想象成模型在维护一本"工作手册",失败的尝试记录成避坑指南,成功的案例沉淀为可复用的规则。
数据表现
论文给出的数字:
AppWorld任务准确率比GPT-4驱动的agent高10.6%
金融推理任务提升8.6%
成本和延迟降低86.9%
这个全程不需要人工标注,只靠反馈循环就能完成优化
有个违反常识的点:现在主流观点都在追求简洁prompt、精炼指令,ACE反倒构建了一个信息密集、持续增长的"操作手册"。随着时间推移,这个手册会越来越厚,但有效性也在累积。大模型似乎并不需要简洁——它们需要的是足够的上下文密度。(我个人也觉得prompt不需要过于简洁,要精练和提供足够的信息)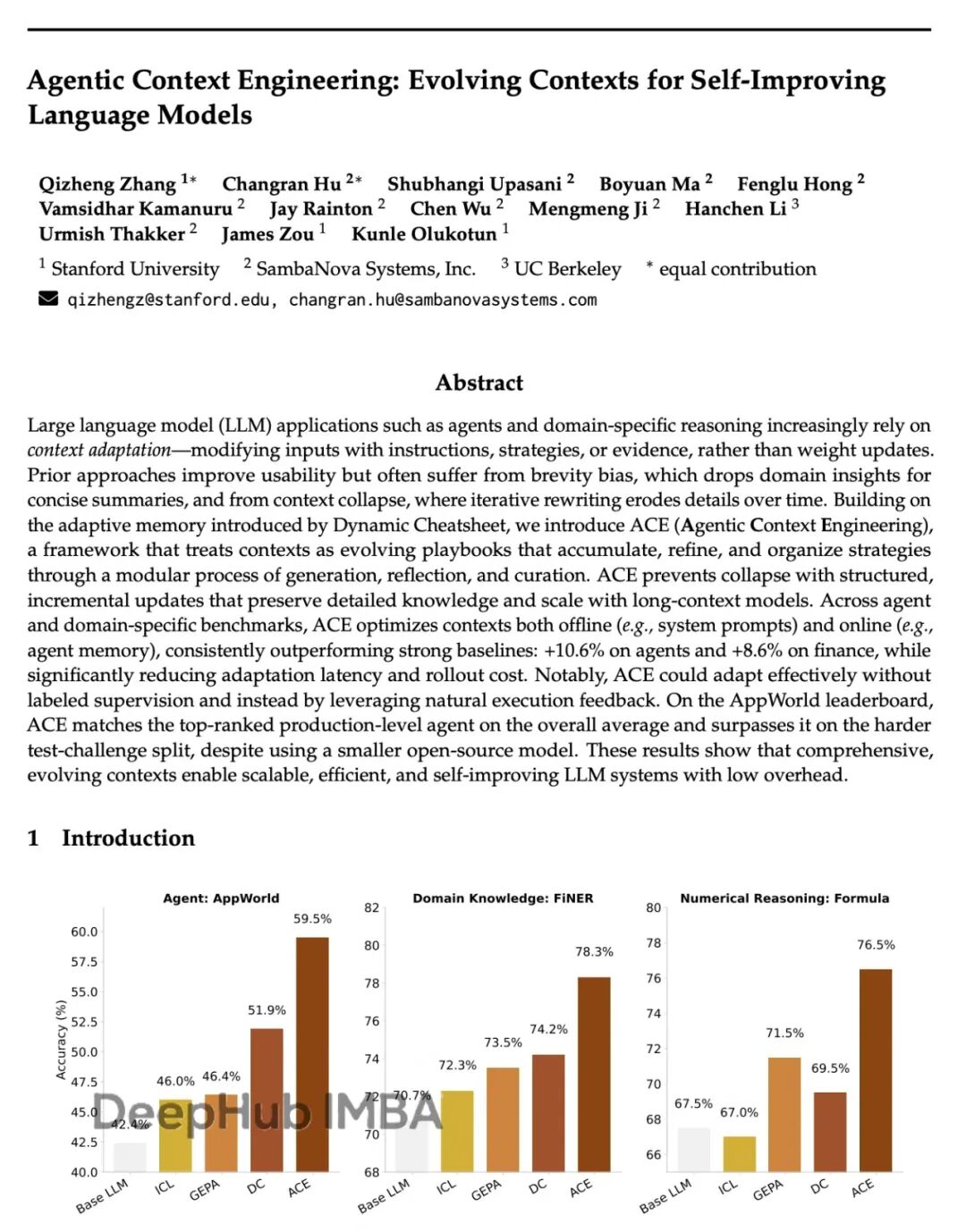
ACE指向的方向是:可能我们过于关注模型本身,而忽略了如何更有效地与它对话。这不仅是技术层面的问题,也是思维方式的转变。
https://avoid.overfit.cn/post/abfeda257e2749ebbcaab86e7d8a2c74