响应很慢,这种情况下, 是不是系统资源出现 了瓶颈。所以,先观察 CPU、内存和磁盘 I/O 等的使用情况肯定不会错。
应用程序记录大量日志
top ,来观察 CPU 和内存的使用情况

观察 top 的输出,你会发现,CPU0 的使用率非常高,它的系统 CPU 使用率(sys%)为 6%,而 iowait 超过了 90%。这说明 CPU0 上,可能正在运行 I/O 密集型的进程。
进程部分的 CPU 使用情况。python 进程的 CPU 使用率已经 达到了 6%,而其余进程的 CPU 使用率都比较低,不超过 0.3%。看起来 python 是个可疑 进程。记下 python 进程的 PID 号 18940
总内存 8G,剩余内存只有 730 MB,而 Buffer/Cache 占用内 存高达 6GB 之多,这说明内存主要被缓存占用。
CPU 使用率中的 iowait 是一个潜在瓶颈,而内存部分的缓存占比较大
iostat 命令,观察 I/O 的使用情况:
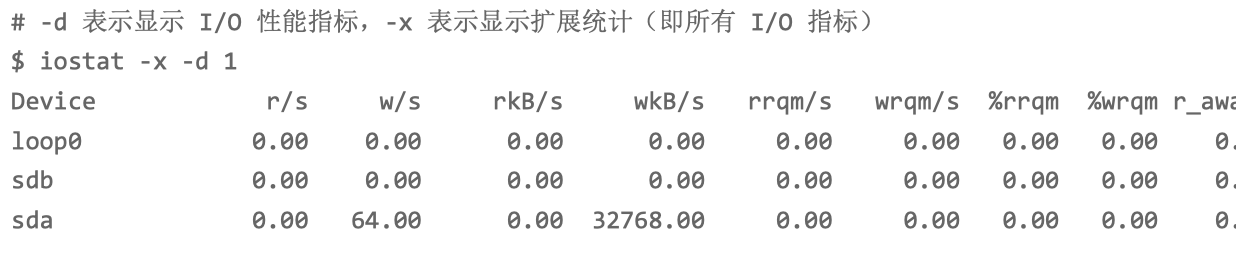
磁盘 sda 的 I/O 使用率已经高达 99%,很可能已经接 近 I/O 饱和。
每秒写磁盘请求数是 64 ,写大小是 32 MB,写请求的响应时间为 7 秒,而请求队列长度则达到了 1100。
超慢的响应时间和特长的请求队列长度,进一步验证了 I/O 已经饱和的猜想。此时,sda 磁盘已经遇到了严重的性能瓶颈。
iowait 高达 90% 了,这正是磁盘 sda 的 I/O 瓶颈导致的。
pidstat 或者 iotop ,观察进程的 I/O 情况
使用 pidstat 加上 -d 参数,就可以显示每个进程的 I/O 情况。
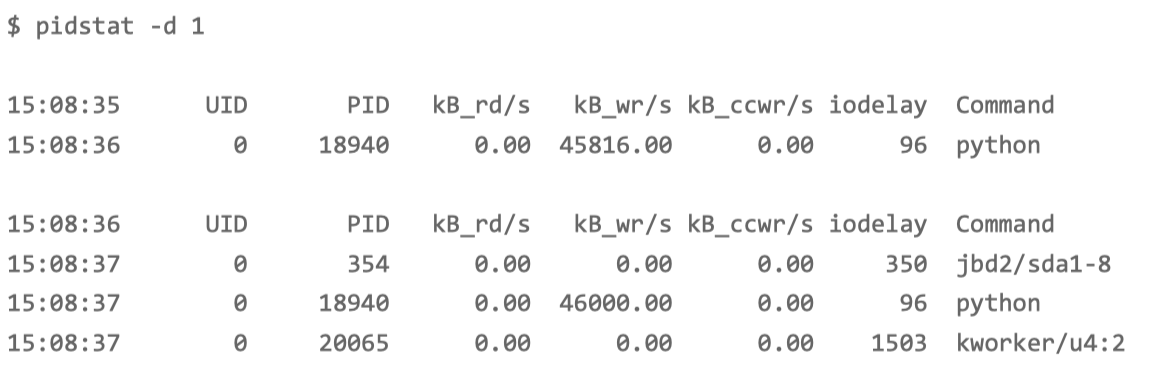
只有 python 进程的写比较大,而且每秒写的数据超过 45 MB,比上面 iostat 发现的 32MB 的结果还要大。很明显,正是 python 进程导致了 I/O 瓶颈。
再往下看 iodelay 项。有两个进程 (kworker 和 jbd2 )的延迟,居然比 python 进程还大很多。kworker 是一个内核线程,而 jbd2 是 ext4 文件系统中,用来保证数据完整性的内核线程。他们都是保证文件系统基本功能的内核线程
综合 pidstat 的输出来看,还是 python 进程的嫌疑最大。
首先留意一下 python 进程的 PID 号, 18940。前面在使用 top 时,在 top 中使用率最高,6%,并不算高。所以,以 I/O 问题为分析方向还是正确的。
strace -p pid 命令
读写文件必须通过系统调用完成。观察系统调用情况, 就可以知道进程正在写的文件。strace 正是我们分析系统调用时最常用的工具。
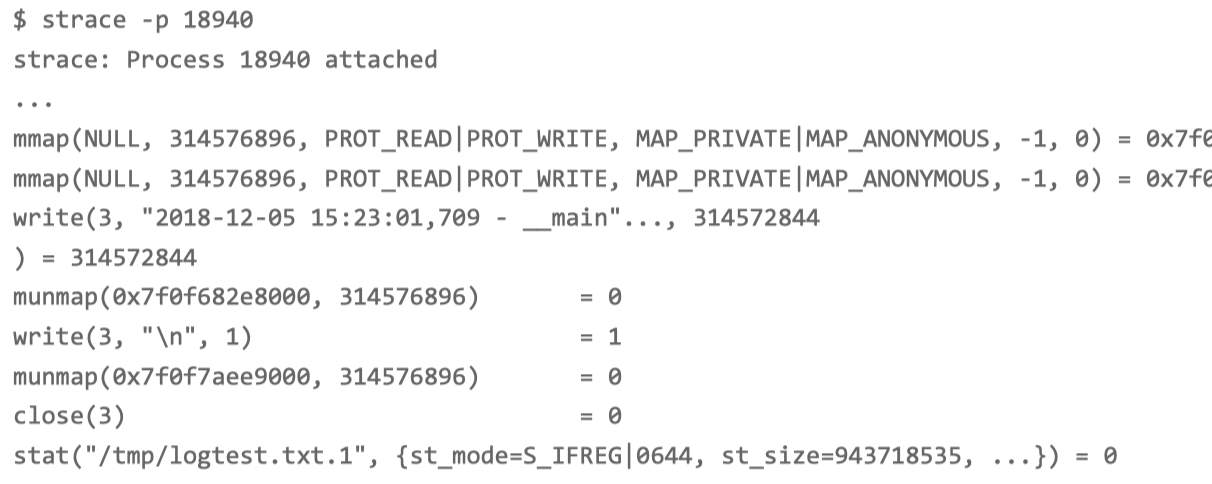
从 write() 系统调用上看到,进程向文件描述符编号为 3 的文件中,写入了 300MB 的数据。write() 调用中只能看到文件的描述符编号,文件名和路径还是未知的。
后面的 stat() 调用,你可以看到,它正在获取 /tmp/logtest.txt.1 的状态。 这 种“点 + 数字格式”的文件,在日志回滚中非常常见。我们可以猜测,这是第一个日志回 滚文件,而正在写的日志文件路径,则是 /tmp/logtest.txt。
lsof -p pid 命令看进程打开了哪些文件
lsof 用来查看进程打开文件列表,不过,这里的“文件”不只有普通文件,还包括了目录、 块设备、动态库、网络套接字等。

FD 表示文件描述符号,TYPE 表示文件类型, NAME 表示文件路径。
这个进程打开了文件 /tmp/logtest.txt,并且它的文件描述符是 3 号,而 3 后面的 w ,表示以写的方式打开。
进程 18940 以每次 300MB 的速度,在“疯狂”写日志,而日志文件的路径是 /tmp/logtest.txt。
查看源代码
在线上环境临时开启应用程序的调试日志。
没把线上的日志调高到警告级别,可能会导致 CPU 使用 率、磁盘 I/O 等一系列的性能问题,严重时,甚至会影响到同一台服务器上运行的其他应 用程序。
docker cp app:/app.py .
cat app.py磁盘I/O延迟很高
执行 df 命令,查看一下文件系统的使 用情况。奇怪的是,这么简单的命令,居然也要等好久才有输出。
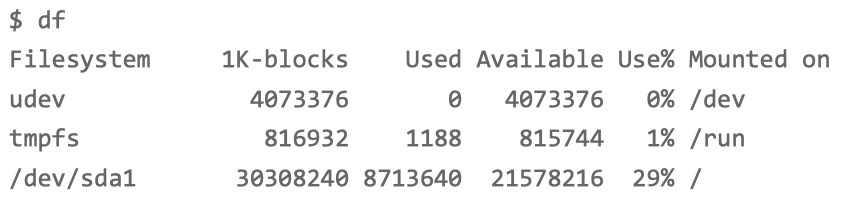
通过 df 我们知道,系统还有足够多的磁盘空间。
为了避免分析过程中 curl 请求突然结束,我们回到终端二,按 Ctrl+C 停止刚才的应用程 序;然后,把 curl 命令放到一个循环里执行;这次我们还要加一个 time 命令,观察每次 的执行时间:
while true; do time curl http://192.168.0.10:10000/popularity/word; sleep 1; done
top 来观察 CPU 和内存的

观察 top 的输出可以发现,两个 CPU 的 iowait 都非常高。特别是 CPU0, iowait 已经高 达 94 %,而剩余内存还有 3GB,看起来也是充足的。
进程部分有一个 python 进程的 CPU 使用率稍微有点高,达到了 14%。虽然 14% 并不能成为性能瓶颈,不过有点嫌疑——可能跟 iowait 的升高有关。

iostat 来观察磁盘的 I/O 情况。
-d 选项是指显示出 I/O 的性能指标;
-x 选项是指显示出扩展统计信息(即显示所有 I/O 指标)。

磁盘 sda 的 I/O 使用率已经 达到 98% ,接近饱和了。而且,写请求的响应时间高达 18 秒,每秒的写数据为 32 MB, 显然写磁盘碰到了瓶颈。
pidstat 命令,观察进程的 I/O 情况

strace 确认是不是在写文件

没有任何输出。
不能直接 lsof 找出文件描述符对应的文件
写文件是由子线程执行的,所以直接strace跟踪进程没有看到write系统调用,可以通过 pstree查看进程的线程信息,再用strace跟踪。或者,通过strace -fp pid 跟踪所有线程。
perf record -e 'fs:*' -ag
perf report
使用perf命令可以从kernel层级记录文件系统的内核事件,相对strace我觉得perf还有一个 优势就是对系统的消耗更低,更利于在生产环境使用。
perf report 更多的是统计上的分析,而 strace 则是可以看到每一个调用的细节。
filetop 属于 bcc 软件包
filetop。它是 bcc 软件包的一部分,基于 Linux 内核的 eBPF(extended Berkeley Packet Filters)机制,主要跟踪内核中文件的读写情况,并输 出线程 ID(TID)、读写大小、读写类型以及文件名称。
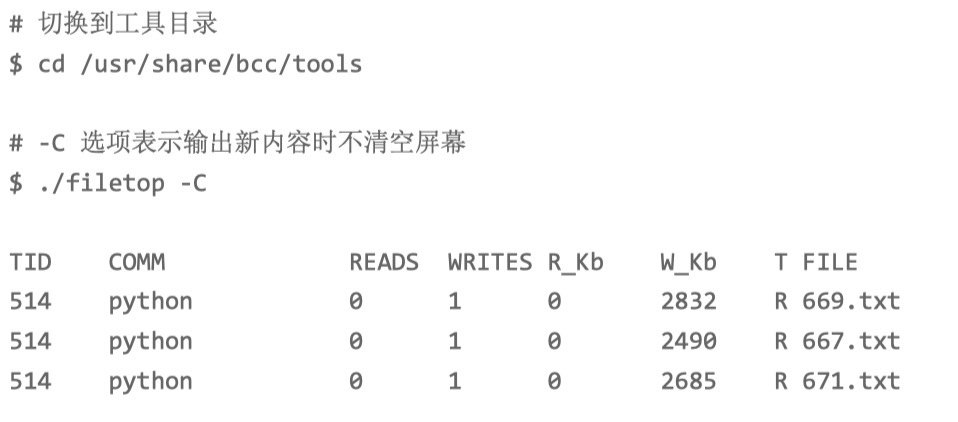
filetop 输出了 8 列内容,分别是线程 ID、线程命令行、读写次数、读写的大小 (单位 KB)、文件类型以及读写的文件名称。
每隔一段时间,线程号为 514 的 python 应用就会先写入大 量的 txt 文件,再大量地读。
filetop 只给出了文件名称,却没有文件路径
ps 命令查看
opensnoop 属于 bcc 软件包
动态跟踪内核中的 open 系统调用。这样,我们就可以找出这些 txt 文件的路径。

这些 txt 路径位于 /tmp 目录下。你还能看 到,它打开的文件数量,按照数字编号,从 0.txt 依次增大到 999.txt,这可远多于前面用 filetop 看到的数量。
猜测,案例应用在 写入 1000 个 txt 文件后,又把这些内容读到内存中进行处理。

没了,在看,目录换了

这时的路径已经变成了另一个目录。这说明,这些目录都是应用程序动态生成的,用 完就删了。
会动态生成一批文件,用来临时存储数 据,用完就会删除它们。但不幸的是,正是这些文件读写,引发了 I/O 的性能瓶颈,导致 整个处理过程非常慢。
把文件数据都放在内存的方法,解决了磁盘 I/O 的性能问题。
SQL 慢查询(28重点)
while true; do curl http://192.168.0.10:10000/products; sleep 5; done
随便执行一个命令,都得停顿一会儿才能看到输出。
top 命令,分析系统的 CPU 使用情况:

两个 CPU 的 iowait 都比较高,特别是 CPU0,iowait 已经 超过 60%。而具体到各个进程, CPU 使用率并不高,最高的也只有 1.7%。
既然 CPU 的嫌疑不大,那问题应该还是出在了 I/O 上。
iostat 命令,看看有没有 I/O 性能问题

磁盘 sda 每秒的读数据为 32 MB, 而 I/O 使用率高达 97% ,接近饱和,这说明,磁盘 sda 的读取确实碰到了性能瓶 颈。
pidstat 观察进程的 I/O 情况:
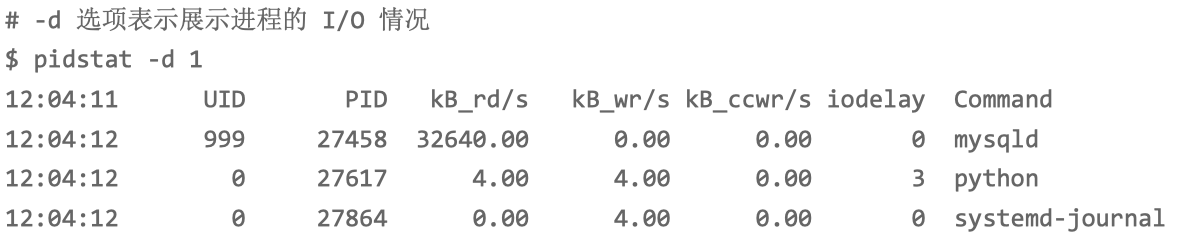
PID 为 27458 的 mysqld 进程正在进行大量的读,而且读取 速度是 32 MB/s,跟刚才 iostat 的发现一致。两个结果一对比,我们自然就找到了磁盘 I/O 瓶颈的根源,即 mysqld 进程。
为什么 mysqld 会去读取大量的磁盘数据 呢?按照前面猜测,我们提到过,这有可能是个慢查询问题。
慢查询的现象大多是 CPU 使用率高(比如 100% ),但这里看到的却是 I/O 问题。
strace+ lsof 组合
MySQL 是一个多线程的数据库应用,为了不漏掉这些线程的数据读取情况,你要记得在执行 stace 命令时,加上 -f 参数:


线程 28014 正在读取大量数据,且读取文件的描述符编号为 38。这 儿的 38 又对应着哪个文件呢?我们可以执行下面的 lsof 命令,并且指定线程号 28014 , 具体查看这个可疑线程和可疑文件:

lsof 并没有给出任何输出。实际上,如果你查看 lsof 命令的返回值,就会发 现,这个命令的执行失败了。
在 SHELL 中,特殊标量 $? 表示上一条命令退出时的返回值。echo $?查看这个特殊标 量,你会发现它的返回值是 1。在 Linux 中,返回值为 0 ,才表示命令执行 成功。返回值为 1,显然表明执行失败。-p 参数需要指定进程号,而我们刚才传入的是 线程号,所以 lsof 失败了。
mysqld 的进程号是 27458,而 28014 只是它的一个线程。而且,如果你 观察 一下 mysqld 进程的线程,你会发现,mysqld 其实还有很多正在运行的其他线程:

换成PID

mysqld 进程确实打开了大量文件,而 根据文件描述符(FD)的编号,我们知道,描述符为 38 的是一个路径为 /var/lib/mysql/test/products.MYD 的文件。这里注意, 38 后面的 u 表示, mysqld 以 读写的方式访问文件。
MYD 文件,是 MyISAM 引擎用来存储表数据的文件;文件名就是数据表的名字;而这个文件的父目录,也就是数据库的名字。换句话说,这个文件告诉我们,mysqld 在读取数据库 test 中的 products 表。
docker exec -it mysql ls /var/lib/mysql/test/
MYD 文件用来存储表的数据;
MYI 文件用来存储表的索引;
frm 文件用来存储表的元信息(比如表结构);
opt 文件则用来存储数据库的元信息(比如字符集、字符校验规则等)。

/var/lib/mysql/ 确实是 mysqld 正在使用的数据存储目录。刚才分析得出 的数据库 test 和数据表 products ,都是正在使用。
其实 lsof 的结果已经可以确认,它们都是 mysqld 正在访问的文件。再 查询 datadir ,只是想换一个思路,进一步确认一下。
慢查询处理--show all processlist
在 MySQL 命令行界面中,执行 show processlist 命令, 来查看当前正在执行的 SQL 语句。为了保证 SQL 语句不截断,这里我们可以执行** show full processlist** 命令。如果一 切正常,你应该可以看到如下输出:

**db 表示数据库的名字; Command 表示 SQL 类型; Time 表示执行时间; State 表示状态; **
而 Info 则包含了完整的 SQL 语句。
多执行几次 show full processlist 命令,第二条 SQL 语句的执行时间比较长。
慢查询处理--expalin sql语句
MySQL 的慢查询问题,很可能是没有利用好索引导致的,

- select_type 表示查询类型,而这里的 SIMPLE 表示此查询不包括 UNION 查询或者子查 询;
- table 表示数据表的名字,这里是 products;
- type 表示查询类型,这里的 ALL 表示全表查询,但索引查询应该是 index 类型才对;
- possible_keys 表示可能选用的索引,这里是 NULL;
- key 表示确切会使用的索引,这里也是 NULL;
- rows 表示查询扫描的行数,这里是 10000。
查询时,会扫描全 表,并且扫描行数高达 10000 行。响应速度那么慢也就难怪了。
慢查询处理--建索引
执行下面的 MySQL 命令,查询 products 表的结构,你会看到,它只有一个 id 主键,并 不包括 productName 的索引


productName 是 一个 BLOB/TEXT 类型,需要设置一个长度。所以,想要创建索引,就必须为 productName 指定一个前缀长度。
通过计算前缀长度的选择 性,来确定索引的长度。不过,我们可以稍微简化一下,直接使用一个固定数值(比如 64),执行下面的命令创建索引:

Redis响应严重延迟
while true; do curl http://192.168.0.10:10000/get_cache; done
响应很慢,这种情况下, 是不是系统资源出现 了瓶颈。所以,先观察 CPU、内存和磁盘 I/O 等的使用情况肯定不会错。
top 命令,分析系统的 CPU 使用情况:
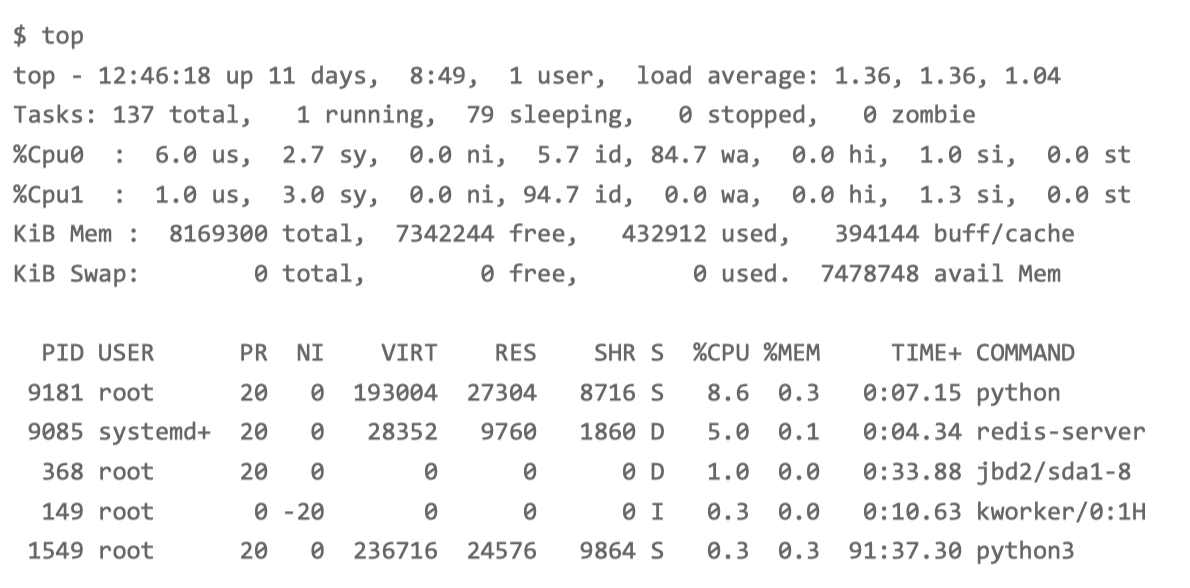
CPU0 的 iowait 比较高,已经达到了 84%;而各个进程的 CPU 使用率都不太高,内存也没啥问题。
综合 top 的信息,最有嫌疑的就是 iowait。所以,接下来还是要继续分析,是不是 I/O 问 题。
iostat 命令,查看 有没有 I/O 性能问题:

磁盘 sda 每秒的写数据(wkB/s)为 2.5MB,I/O 使用率 (%util)是 0。但并没导致磁盘的 I/O 瓶颈。
排查一圈儿下来,CPU 和内存使用没问题,I/O 也没有瓶颈,
到底是哪个 进程在写磁盘。要知道 I/O 请求来自哪些进程,
pidstat 命令,观察进程的 I/O 情况:

I/O 最多的进程是 PID 为 9085 的 redis-server,并且它也 刚好是在写磁盘。这说明,确实是 redis-server 在进行磁盘写。
strace+lsof 组合,看看 redis-server 到底在写什么。


epoll_pwait、read、write、fdatasync 这些系统调用都比较 频繁。那么,刚才观察到的写磁盘,应该就是 write 或者 fdatasync 导致的了。
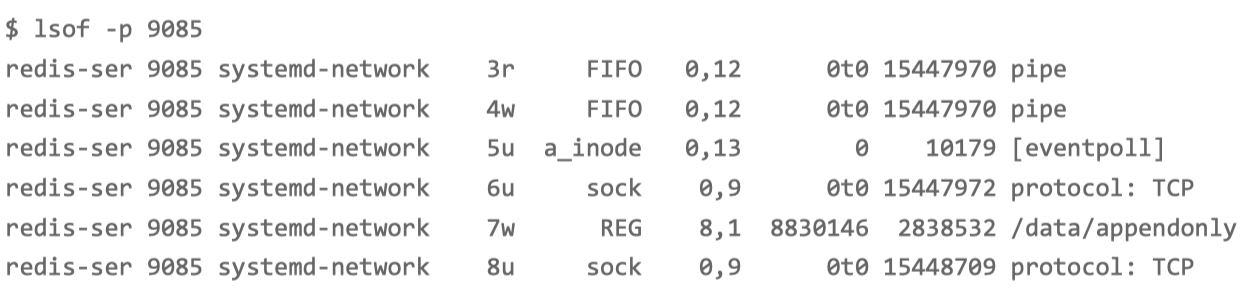
描述符编号为 3 的是一个 pipe 管道,5 号是 eventpoll,7 号是一个普通 文件,而 8 号是一个 TCP socket。
只有 7 号普通文件才会产生磁盘写,而它操作的文件路径 是 /data/appendonly.aof,相应的系统调用包括 write 和 fdatasync。
正是 Redis 持久化配置中的 appendonly 和 appendfsync 选项。 很可能是因为它们的配置不合理,导致磁盘写比较多。
查询 appendonly 和 appendfsync 的配置:
docker exec -it redis redis-cli config get 'append*'

Redis 提供了两种数据持久化的方式,分别是快照和追加文件。
- 快照方式,会按照指定的时间间隔,生成数据的快照,并且保存到磁盘文件中。为了避免阻 塞主进程,Redis 还会 fork 出一个子进程,来负责快照的保存。这种方式的性能好,无论是备份还是恢复,都比追加文件好很多。
- 缺点也很明显。在数据量大时,fork 子进程需要用到比较大的内存,保存数据也很耗时。所以,你需要设置一个比较长的时间间隔来应对,比如至少 5 分钟。这样,如 果发生故障,你丢失的就是几分钟的数据。
- 追加文件,则是用在文件末尾追加记录的方式,对 Redis 写入的数据,依次进行持久化, 所以它的持久化也更安全。还提供了一个用 appendfsync 选项设置 fsync 的策略,确保写入的数据都落到磁 盘中,具体选项包括 always、everysec、no 等。
- always 表示,每个操作都会执行一次 fsync,是最为安全的方式;
- everysec 表示,每秒钟调用一次 fsync ,这样可以保证即使是最坏情况下,也只丢失 1 秒的数据; 而 no 表示交给操作系统来处理。
appendfsync 配置的是 always,意味着每次写数据时,都会调用一次 fsync,从而造成比较大的磁盘 I/O 压力。
用 strace ,观察这个系统调用的执行情况。比如通过 -e 选项指定 fdatasync 后,你就会得到下面的结果:

每隔 10ms 左右,就会有一次 fdatasync 调用,并且每次调用本身也 要消耗 7~8ms。
不管哪种方式,都可以验证我们的猜想,配置确实不合理。
验证读时写
strace -f -T -tt -p 9085 的结果。
根据 lsof 的分析,文件描述符编号为 7 的是一个普通文件 /data/appendonly.aof,而编号为 8 的是 TCP socket。8 号对应的 TCP 读写,是一个标准的“请求 - 响应”格式,即:
从 socket 读取 GET uuid:53522908-… 后,响应 good;
再从 socket 读取 SADD good 535… 后,响应 1。
对 Redis 来说,SADD 是一个写操作,所以 Redis 还会把它保存到用于持久化的 appendonly.aof 文件中。
每当 GET 返回 good 时,随后都会有一个 SADD 操 作,这也就导致了,明明是查询接口,Redis 却有大量的磁盘写。
8 号 TCP socket 对应的 Redis 客户端,到底是不是我们的案例应用。
我们可以给 lsof 命令加上 -i 选项,找出 TCP socket 对应的 TCP 连接信息。不过,由于 Redis 和 Python 应用都在容器中运行,我们需要进入容器的网络命名空间内部,才能看到 完整的 TCP 连接。
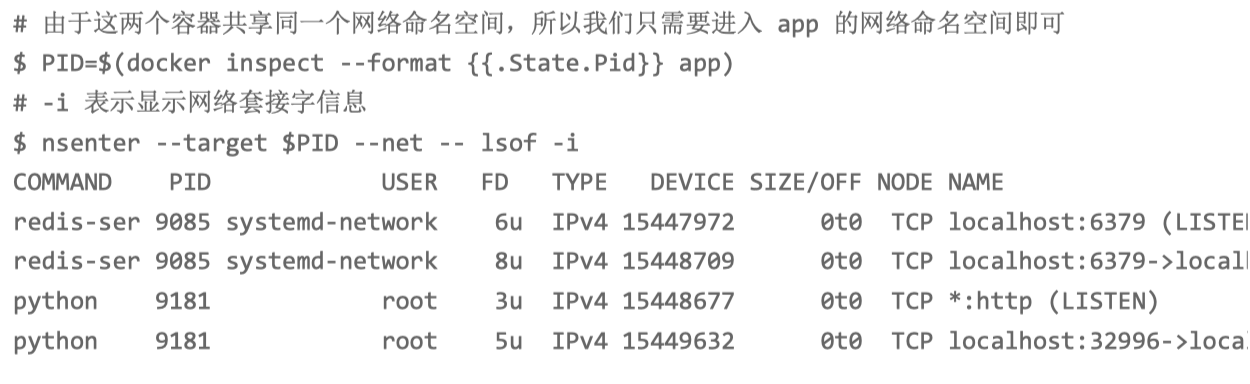
redis-server 的 8 号文件描述符,对应 TCP 连接 localhost:6379>localhost:32996。其中, localhost:6379 是 redis-server 自己的监听端口,自然 localhost:32996 就是 redis 的客户端。再观察最后一行,localhost:32996 对应的,正是 我们的 Python 应用程序(进程号为 9181)。
第一个问题,Redis 配置的 appendfsync 是 always,这就导致 Redis 每次的写操作,都 会触发 fdatasync 系统调用。今天的案例,没必要用这么高频的同步写,使用默认的 1s 时 间间隔,就足够了。
第二个问题,Python 应用在查询接口中会调用 Redis 的 SADD 命令,这很可能是不合理 使用缓存导致的。
修复
