 AI时代大模型的应用已经渗透到日常的角角落落,同时算力变成了普遍的需求,在购买显卡或者租用GPU云算力的时候,如何选择合适的显卡呢,需要关注哪些参数?
本文以最常见的英伟达显卡为例,来说说显卡的各种参数是如何影响算力性能的。
AI时代大模型的应用已经渗透到日常的角角落落,同时算力变成了普遍的需求,在购买显卡或者租用GPU云算力的时候,如何选择合适的显卡呢,需要关注哪些参数?
本文以最常见的英伟达显卡为例,来说说显卡的各种参数是如何影响算力性能的。AI时代大模型的应用已经渗透到日常的角角落落,同时算力变成了普遍的需求,企业或者个人在购买显卡或者租用GPU云算力的时候,如何选择合适的显卡呢,需要关注哪些参数?
下面以最常见的英伟达显卡为例,来说说显卡的各种参数是如何影响算力性能的。
Nvidia显卡比较
先看看英伟达官网是怎么比较自己的显卡产品线的:
Nvidia GeForce 显卡比较
随着显卡技术的不断革新,最重要的是架构和平台的革新,新的架构带来更多的特性,比如光追、AI加速等,同时提供更强大的算力,英伟达最新架构Blackwell 单芯片的算力性能、带宽都大幅提升,带来AI推理性能的10倍级飞跃。
显卡架构是产品线升级带来的代差,再来看看具体的产品线的显卡对比,如最新的50系显卡比较了哪些参数:
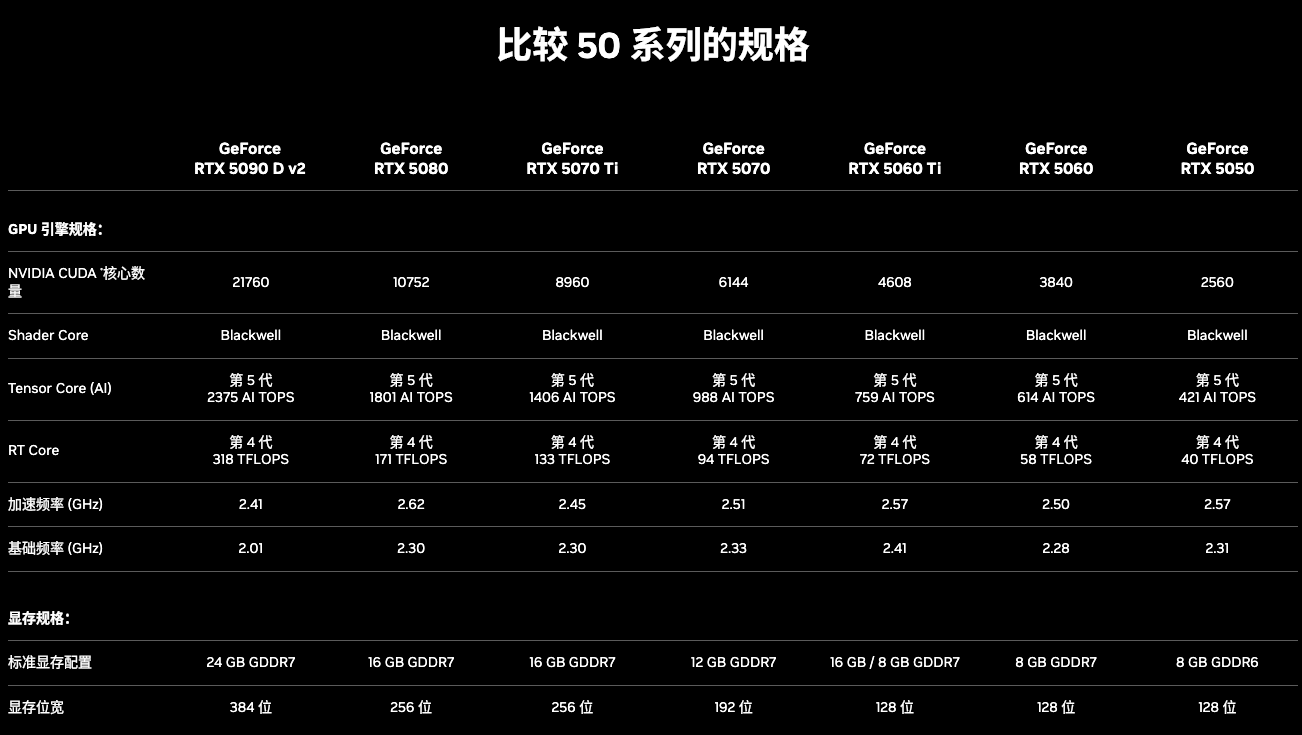
显卡参数
显卡最主要的组成部分就是核心及显存。
1. 显卡核心
核心直接决定显卡的计算能力。
1.1 CUDA核心数(流处理器数量)
GPU的核心计算单元,核心越多,并行计算能力越强。
1.2 Shader Core
渲染核心,负责像素点的渲染工作。
1.3 Tensor Core
AI加速核心,用于加速深度学习中神经网络训练和推理的矩阵计算。
1.4 RT Core
光追核心,用作于光线追踪效果。
1.5 基础频率
类似CPU主频,每个核心默认的运行频率。
1.6 加速频率
核心可以达到的最大频率。
2. 显存(VRAM)
显存决定加载模型、图像纹理的速度和大小上限。
2.1 显存类型
类似于内存,显存的类型叫GDDR,比50系基本用的GDDR7,40系用的GDDR6,越新的显存类型拥有更高的带宽和更快的速率。
2.2 显存容量
显存容量决定了一张显卡同时能处理的数据大小,在模型加载、模型训练的各种应用场景中显存的大小也是选择显卡的关键因素。
2.3 显存带宽
其实显存的数据通道大小叫位宽,显存位宽决定GPU核心一次能从显存中读取多少数据;位宽 × 频率 = 显存带宽,显存的带宽决定了显存数据吞吐速率。
3. 其他
3.1 功耗(TDP)
不同显卡功耗不同,高功耗的显卡需要消耗更多的电力成本,也需要更好的散热,比如4090的功耗是450W,5090的功耗是575W。
3.2 接口
PCIe 3.0 / 4.0 / 5.0 / NVLink 等,使用的接口类型决定了显卡与主板CPU之间的通信带宽,比如更高版本的PCIe会有更大的带宽;而NVLink则帮我们解决GPU之间数据传输的问题,NVLink支持两个GPU之间直接进行数据传输。
云算力平台
当前很多的云算力租赁平台都显示了很多显卡的算力参数,比如 晨涧云 平台的首页就显示了各类显卡的显存及TFLOPS(每秒浮点运算次数)的算力值:
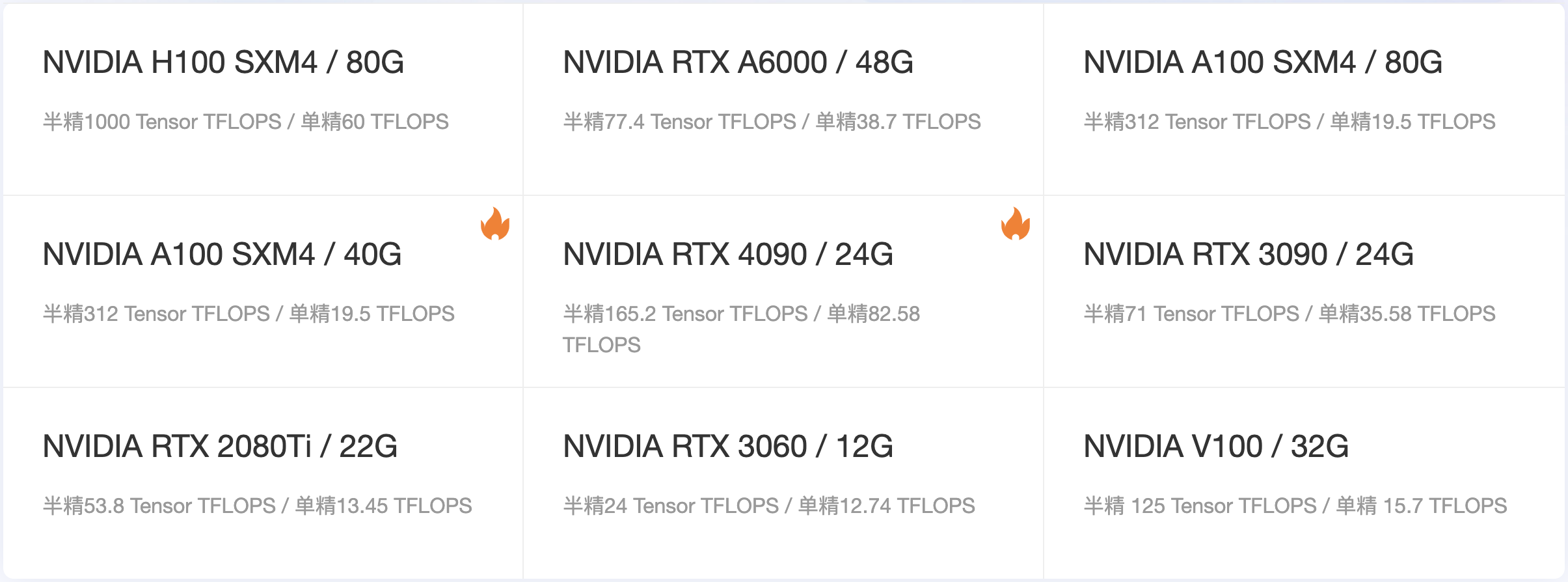
综合来说,我们在选择显卡的时候需要先确定应用场景,比如是渲染、模型训练、AI推理还是科学计算等,然后确定需要的显存大小,因为显存不够就没法进行相应的计算,而核心的计算性能会影响总体的运算速度和响应能力;同时需要综合考虑其他参数,权衡成本和收益。