原文链接
这篇文章是对于之前工作的改进,可能需要先说说之前他们干了啥
为 GPU 上的深度学习推荐模型训练构建性能模型
RM推荐模型大家应该都听说过,比如购物,搜索场景下都很常见,那这篇文章做的就是RM的其中一类叫深度学习推荐模型(DLRM),为这一类模型来构建他们的性能建模。
那么为什么需要性能建模?,性能建模是用来预测程序运行表现的,而在需求不断增长的动力下,为了提高预测率而训练这些模型已成为数据密集型和计算密集型的工作,涉及数百亿样本的训练数据、高达多个 TB 的模型大小,以及用于分布式训练的多个(通常是数百个)主机和设备,消耗太大了,因此一个能够根据其配置(例如,批量大小、数据分片、层数等)准确预测推荐模型训练性能(例如,速度、内存使用等)的性能模型非常有用。
那之前针对DL负载有啥问题?
其实我看下来感觉创新一般(毕竟这篇文章只发了个CCFC在HiPC 2022上),首先他说:
1.之前的工作主要关注CNN 和/或 NLP 模型,那我们针对的DLRM更复杂
2.之前的工作内核指标细粒度不够,那我们通过基于更细粒度预测内核运行时间和开销,与之前的工作相比减少了预测误差
3.之前的工作内核依赖图没有捕获数据依赖性,因此在发现和预测其他优化(如并发内核执行)的有效性方面存在局限性。那我们的执行图很好地捕获了数据依赖性
PS:
算子(Operator):计算图中的单个计算节点,对张量执行一次逻辑运算,如矩阵乘、卷积、ReLU。
内核(Kernel):在GPU上运行的具体并行程序,一次启动由多线程执行,用于实现算子的实际计算。

像 ResNet 和 Transformer 这样的一些视觉(CV)和自然语言处理(NLP)模型的 GPU 利用率接近 100%,而像 RMs(以 DLRM 为例)的 GPU 利用率则低得多。虽然 GPU 利用率高的工作负载的端到端(E2E)运行时间可以通过简单地将其组成内核运行时间相加来准确建模,但对于像 RMs 这样 GPU 利用率较低的工作负载,相同的方法则无效。
解决方法
我这主要看看方法论,反正主要思想就是将设备活动时间和空闲时间的预测分开,并使用基于关键路径的算法将这两部分与 CPU 和 GPU 的执行时间跟踪相结合。感兴趣的可以自己再看看。
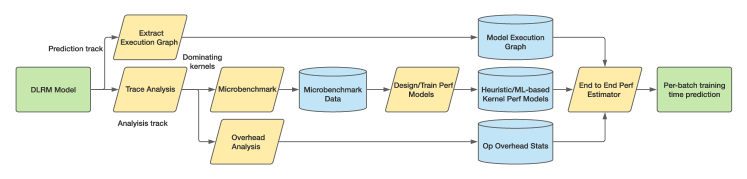
ok,上面就是22年做的单GPU上性能预测的工作,接下来可以进入这篇CCFA的正题了,升级为多GPU
面向多 GPU 平台机器学习训练的通用性能建模
为什么要做-需求
现代机器学习(ML)工作负载往往在规模和计算量上不断增长,通常超出了单个 GPU 的承载和训练能力。
比如之前的DLRM在分层计算系统上以分布式方式训练,例如 16 个节点 × 8 个 GPU,对于这样艰巨的多 GPU 训练任务,不仅需要关注训练性能(例如,迭代时间、每秒查询次数(QPS)、FLOPS 等),还关注如何加速训练以及如何最有效地使用硬件。
表征这类多 GPU 任务的性能行为是识别和优化性能瓶颈的关键。
主要有三个挑战:
1.通信集体操作,如跨各种网络介质(例如,NVLink、PCIe、网卡)和连接多个计算设备的拓扑结构进行的全互换和全归约,是多 GPU 训练中的关键操作,通常也是性能热点。
PS:
all to all 全互换:每个节点先有一块等长数据,做一次按位聚合(如求和/最大值),结果相同地返回给所有节点。
all reduce 全归约:每个节点把自己的数据按对等分片,分别发给所有其他节点,同时也从所有节点收对应分片;每个节点最终拿到不同的数据集合。
2.同一设备上或跨多个设备的多 GPU 流同步行为非常复杂
3.嵌入查找
做什么-创新
针对通信集体操作问题
在预测单 GPU 上每批训练和/或推理的 ML 工作负载执行时间方面,已有大量先前的技术,这些工作开发了在操作/内核级别准确建模性能的方法,但它们不适应现代多 GPU 或分布式训练,要准确预测就必须解决GPU之间通信建模的问题。
已有的多GPU方法把总时间近似为 max(数据, 计算, 通信),等价假设三者完美重叠;没有细刻 全规约/全互换 的算法,或者只是通过解析缩放因子估计计算-通信重叠。
改进:这种重叠通过基于关键路径的方法进行估计
针对GPU流同步问题
多GPU的分布式训练的同步有两种类型:
1.在通信集体核终止时发生的 inter-rank 同步
(inter-rank 同步:不同进程/不同 GPU(各称一个 rank)之间的对齐等待)
2.在计算/内存核启动时发生的 intra-rank 或 inter-stream 同步,该同步依赖于上一个通信核
(intra-rank:同一进程/同一块 GPU 发生的事或同步)
(inter-stream:不同 CUDA 流之间的事或同步(通常也在同一块 GPU 上) )
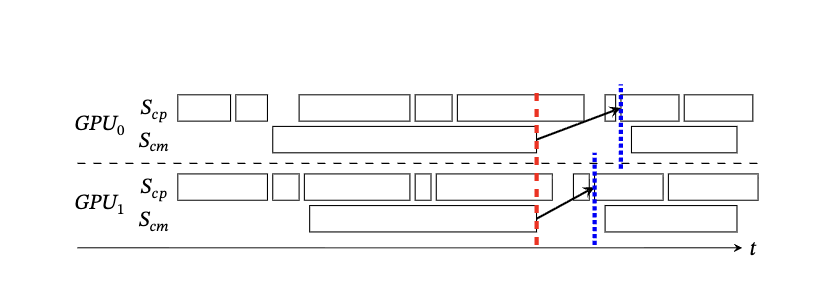
图片里有两个流,Scp和Scm分别表示计算和通信流,红色虚线是 inter-rank ,蓝色虚线是intra-rank/inter-stream,箭头指计算内核和通信内核之间的数据依赖关系。
过去的工作就是将每个 GPU 流的核心时间相加,并取最大值作为端到端预测结果,但这将忽略大量由数据依赖和其他可能的等待条件在执行过程中产生的 GPU 空闲时间(例如图中红色和蓝色线之间的差距)
改进:通过结合跨秩和同秩同步操作,将上文提出的基于关键路径的单 GPU 性能建模算法扩展到多 GPU 场景。
针对嵌入查找问题
现代推荐模型如工业 DLRMs 通常具有数百个嵌入查找表,每表包含多达数千万行,这些表太大无法存储在单个 GPU 上,因此必须分片并分配到多个 GPU,出现很多平衡这些分片表的负载的算法,那我们的性能模型能够评估多种分片算法的性能,并快速选择出最适合 DLRM 训练的最佳 E2E 执行时间的算法。
之前的工作比如上文的单GPU建模里只考虑了当 D(嵌入维度)、E(嵌入的数量)和 L(池化因子)对于每个表都是固定且输入数据分布均匀的情况下的性能建模
D(Embedding Dim):每条向量有几维;决定“每次取出来有多宽”。
E(Embeddings):表里有多少条目(行/ID);决定“表有多大”。
L(Pooling Factor / Bag Size):每个样本从这张表要取多少条并做聚合
改进:使用重用因子(RF)来描述 EL 的输入数据分布,该概念由 Meta 的开源 DLRM 数据集引入,当然也不是什么新东西,他们在 Zha 等人提出的成本模型上做了改进,Zha 等人创建了一个多头 MLP 成本模型,用于同时预测 EL 在多设备上整体分片方案的前向时间、后向时间和通信时间,作者的改进有两个:1.在算子粒度上分别处理这三个构成时间,因为将这三个时间整体考虑会错失解释计算-通信重叠的机会。2.不是使用每个表的 RF 值,而是使用每个批次的 RF 值。

(用“直方图的直方图”来描述嵌入索引在一个批次里的重复访问程度的向量化特征。)
怎么做
全预测流程概述

针对通信集合的建模
\(
t_{\mathrm{comm}} = t_{\mathrm{cold\_start}} + t_{\mathrm{per\_word}} \cdot m_{\mathrm{size}}
\)
这是传统的消息传递成本模型(2003),其中 \(t_{\mathrm{cold\_start}}\)表示数据传输的固定开销, \(t_{\mathrm{per\_word}}\)是通信媒介的每字节数据传输时间.
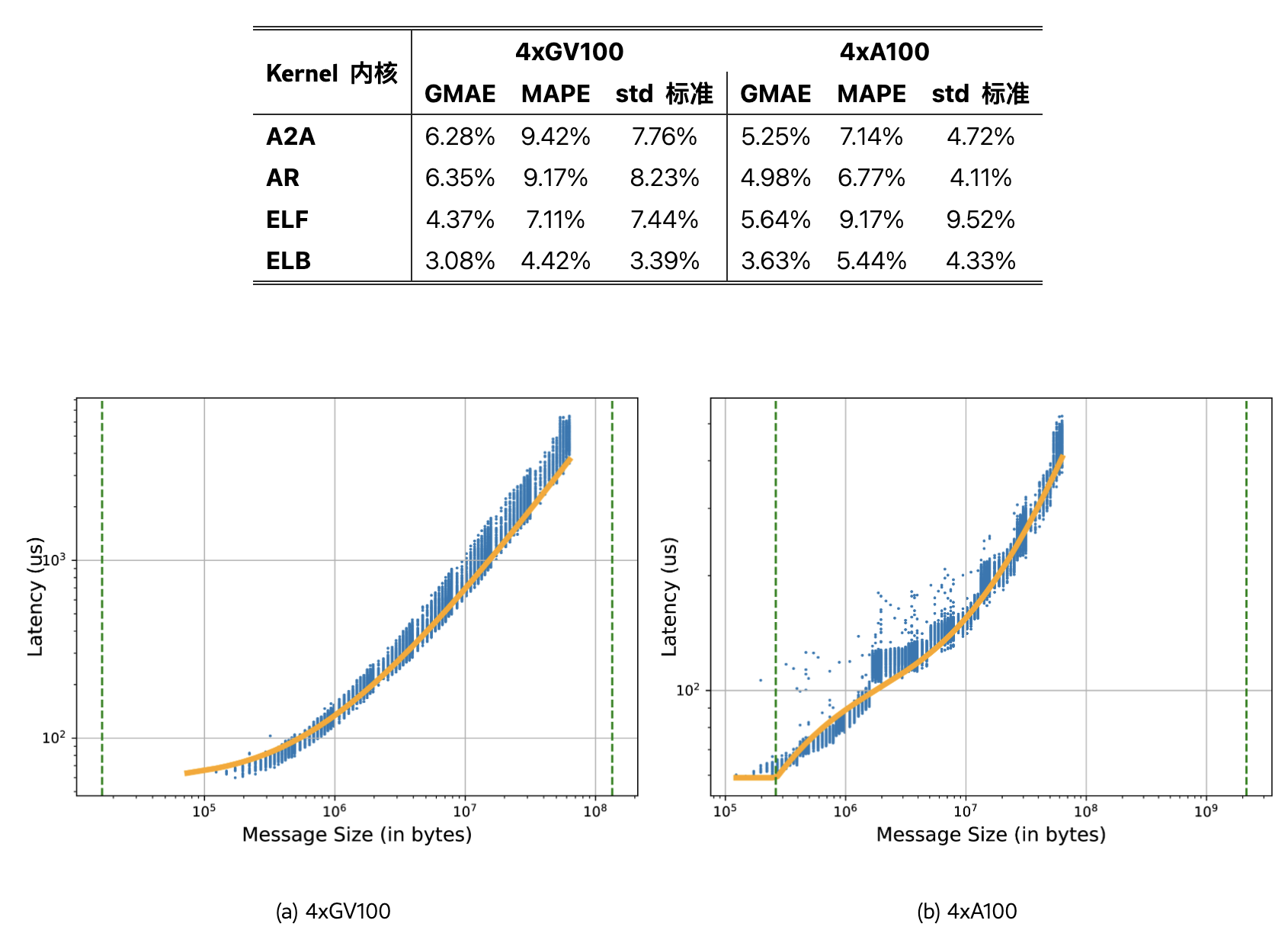
但是作者根据之前的研究(LogCA )发现:无论操作、网络连接模式和网络介质如何,如图 4 所示,随着消息大小的增加,消息大小与带宽的曲线始终可以分为三个区域:1) 具有恒定延迟的线性带宽;2) 具有非线性延迟的 S 形带宽曲线;3) 具有线性延迟的恒定(饱和)带宽。

\( t_{\mathrm{comm}} = \begin{cases} t_s, & \text{if } m \le m_1,\\[4pt] f(m,\mathrm{param}), & \text{if } m_1 \le m \le m_2,\\[6pt] t_s + \dfrac{m}{\mathrm{BW}_{\max}}, & \text{if } m \ge m_2. \end{cases} \)
\( f(m,\mathrm{param}) \;=\; \frac{\log_{2} m}{10^{\,\mathrm{sigmoid}(m,\mathrm{param})}} \)
\( \operatorname{sigmoid}(x) = \frac{L}{1 + e^{-k\,(x - x_0)}} + b. \)
针对GPU同步的建模
每个 rank(进程/GPU)有两条流:
通信流 :all-reduce / all-to-all 等通信核;
计算/内存流 :GEMM、EL、memcpy 等。
一份 执行踪迹 提供算子依赖(谁用到谁的输出)。
还跟踪五类 CPU 端开销 T1–T5(算子间隙、API 调用、kernel 启动间隙等),决定何时能发起下一个核。
同步规则一:秩内(intra-rank / inter-stream)同步
触发条件:
当前算子依赖上一次通信算子(用到通信结果),或当前算子本身是新通信算子,但尚未就绪。
同步措施
等到CPU排队完成、本流前一核结束,且若依赖通信结果,还要等上一通信核结束
或等到CPU排队完成、本通信流前一核结束,且等计算流把输入张量算好
同步规则二:秩间(inter-rank)同步
触发条件:
一次集合通信的末尾(该通信算子的所有 kernel 处理完之后)。
同步措施
计算每个 rank 的本次通信结束时间 ,做一次“全局对齐”,由最慢卡决定大家何时通信完成
针对嵌入查找核的建模
1.把“前向/反向/通信”拆开到算子粒度分别建模
旧:多头 MLP 一次性预测一个分片方案的总前向/反向/通信代价。
新:对 EL 的 前向、反向、通信分别做预测,再交给关键路径 E2E 仿真器调度,能显式捕捉计算–通信重叠与等待(而不是被总时长掩盖)。
2.RF 用“批级”而不是“全数据集级”
旧:用整库/表的 RF 训练。
新:使用每个批次的 RF 值,基于上一段的理由进行更好的预测
实验
嵌入查找内核的性能模型在单个 NVIDIA GV100 和 A100(40 GB)GPU 上进行了评估
通信内核和多 GPU 端到端的性能模型则在两个多 GPU 平台上进行评估,包括配备 48 核 Intel(R) Xeon(R) Gold 6146 CPU @ 3.20 GHz 的 4xGV100 平台,以及配备 GCP 的 a2-highgpu-4g、拥有 48 个 vCPU 的 4xA100 平台
核性能模型(全对全核,全规约核,嵌入查找核)
端到端性能模型
DLRM
NLP:BERT / GPT-2 / XLNet
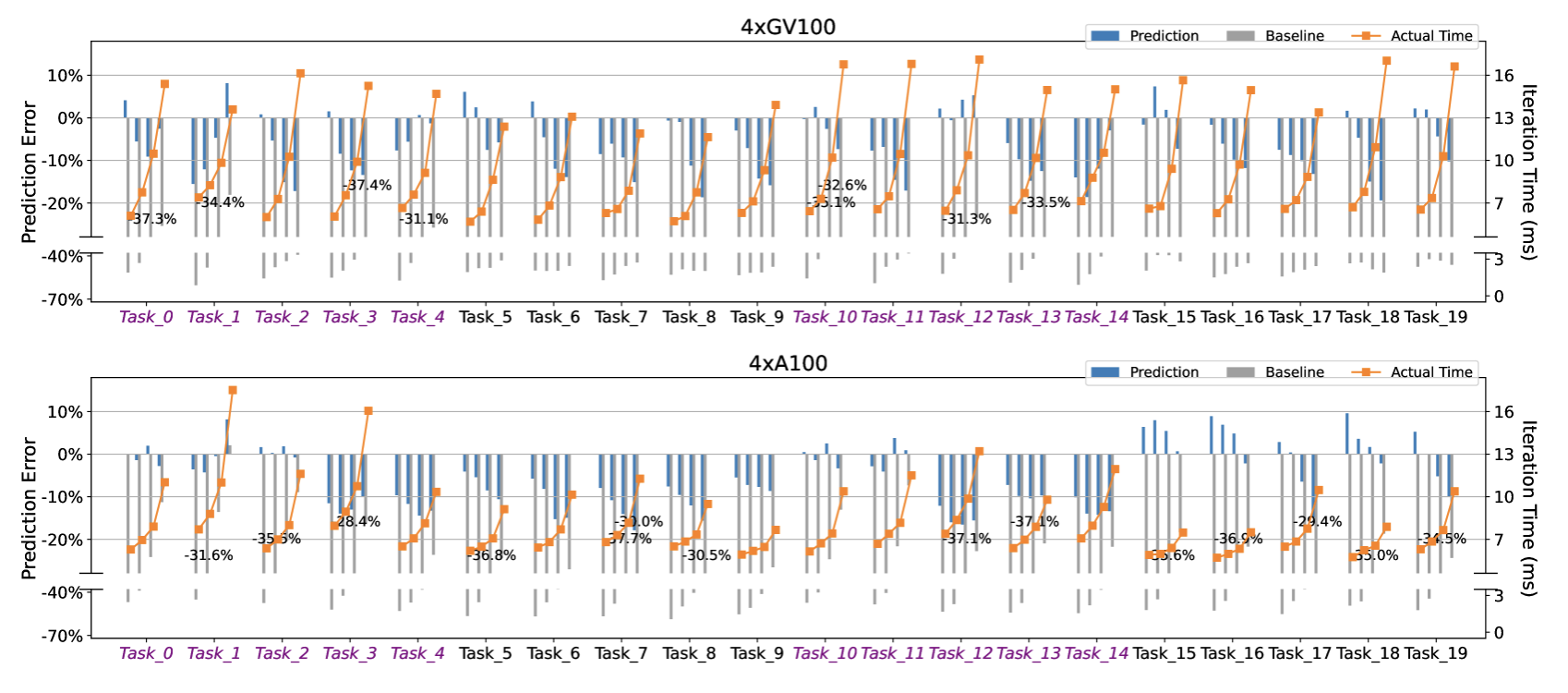
在两个多 GPU 平台上对 DLRM 多 GPU 训练性能的预测准