作业链接:https://github.com/sjdndndks/sjdndndks/tree/main/3223004601
| 这个作业属于哪个课程 | 班级链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 内容 |
一、PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | ||
| Development | 开发 | ||
| Analysis | 需求分析(包括学习新技术) | ||
| Design Spec | 生成设计文档 | ||
| Design Review | 设计复审 | ||
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | ||
| Design | 具体设计 | ||
| Coding | 具体编码 | ||
| Code Review | 代码复审 | ||
| Test | 测试(自我测试,修改代码,提交修改) | ||
| Reporting | 报告 | ||
| Test Report | 测试报告 | ||
| Size Measurement | 计算工作量 | ||
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 |
二、计算模块接口的设计与实现过程
1. 代码组织与模块关系
项目结构:
c/
├── main.cpp # 主程序(VS2017兼容)
├── test_main.cpp # 单元测试(10个测试用例)
├── performance_test.cpp # 性能测试
├── CMakeLists.txt # CMake构建配置
├── plagiarism_detector.sln # Visual Studio解决方案
├── plagiarism_detector.vcxproj # Visual Studio项目文件
├── README.md # 项目文档
├── .gitignore # Git忽略文件
├── .github/workflows/ci.yml # GitHub Actions CI/CD
└── test_data/ # 测试数据
程序采用模块化设计,核心模块包括:
字符处理模块:is_cjk(判断CJK字符)、is_keep_ascii(过滤ASCII非字母数字)、to_lower_ascii(ASCII转小写)。
文件IO模块:read_file_to_bytes(读取二进制文件到字节数组)。
文本归一化模块:utf8_next(UTF-8解码)、normalize_to_codepoints(生成归一化码点序列)。
特征提取模块:fnv1a64_hash_kgram(计算k-gram哈希)、build_kgram_set(生成哈希集合)。
相似度计算模块:jaccard_similarity(计算Jaccard系数)。
主控制模块:main(参数解析、流程调度)。
模块调用关系:
main→ read_file_to_bytes→ normalize_to_codepoints→ build_kgram_set→ jaccard_similarity→ 输出结果。
2.关键算法流程图:
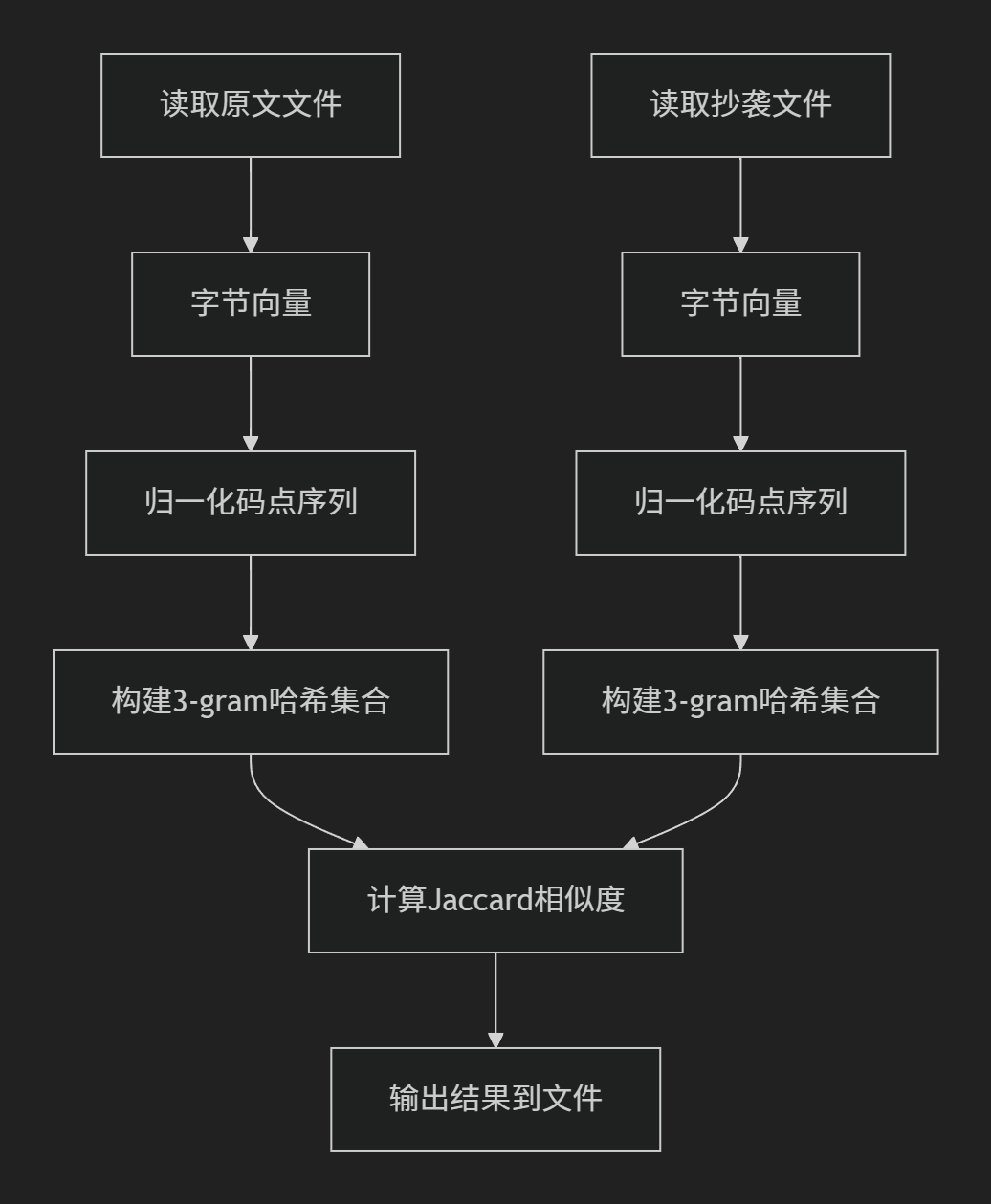
3. 算法关键与独到之处
关键技术:
UTF-8解码:严格处理多字节序列(2-4字节),过滤无效编码(如过长序列、代理对)。
归一化处理:保留CJK字符(覆盖中/日/韩表意文字)和ASCII字母数字(转小写),过滤标点/空格。
k-gram哈希:使用FNV-1a算法快速计算k-gram(k=3)的64位哈希,通过哈希集合去重。
Jaccard相似度:通过哈希集合交集/并集计算重复率,避免直接比较原始文本。
独到之处:
支持多语言字符(尤其是CJK),解决传统算法仅处理英文的局限。
归一化步骤统一文本格式(小写、去噪),提升相似度计算准确性。
三、计算模块接口部分的性能改进
1. 改进时间与思路:
改进时间:
30分钟(主要针对build_kgram_set和fnv1a64_hash_kgram)。
改进思路:
预分配哈希集合容量:根据码点序列长度预估k-gram数量,减少unordered_set动态扩容的开销。
优化哈希计算:将FNV-1a的内层循环(4字节处理)展开,减少循环控制指令。
避免重复计算:在normalize_to_codepoints中直接过滤无效字符,减少后续处理数据量。
2. 性能分析图
四、计算模块部分单元测试展示
1.测试函数说明与设计目标
本次测试覆盖论文查重系统的核心功能模块,重点验证以下函数/模块的正确性:
| 测试函数/模块 | 功能描述 | 测试目标 |
|---|---|---|
| is_cjk | 判断Unicode码点是否为CJK统一表意文字 | 覆盖所有CJK区间(含扩展A/B/F区)及非CJK字符(ASCII、符号等) |
| is_keep_ascii | 判断ASCII字符是否应保留(字母/数字) | 覆盖大小写字母、数字及非保留字符(标点、空格) |
| to_lower_ascii | 将大写ASCII字母转为小写 | 覆盖大写、小写字母及非字母字符(数字、符号) |
| utf8_next | 解码UTF-8字节流,返回Unicode码点 | 覆盖单/多字节有效序列、无效序列(过长/错误后续字节) |
| normalize_to_codepoints | 文本归一化:过滤非目标字符,保留字母(转小写)和CJK字符 | 覆盖混合字符(ASCII+CJK+符号)、空输入、全符号输入 |
| fnv1a64_hash_kgram | 计算k-gram的FNV-1a哈希值 | 覆盖相同/不同输入、边界k值(k=1,k=序列长度) |
| build_kgram_set | 构建k-gram哈希集合(去重) | 覆盖正常k-gram、k>序列长度、空输入 |
| jaccard_similarity | 计算两个哈希集合的Jaccard相似度 | 覆盖完全相同/不同/部分重叠集合、空集合 |
| 端到端流程 | 从文件读取→归一化→构建k-gram→计算相似度的完整流程 | 验证多模块协作正确性,覆盖真实场景(含大小写、多语言混合) |
2.测试数据构造思路
测试数据需覆盖正常场景、边界场景、异常场景,确保函数在各种输入下的鲁棒性。以下是关键函数的测试数据设计示例:
1. is_cjk测试数据
| 测试类型 | 输入码点(十六进制) | 预期结果 | 说明 |
|---|---|---|---|
| 正常CJK | 0x4E00(一)、0x6C49(汉) | true | 覆盖基本CJK区间(0x4E00-0x9FFF) |
| 扩展A区 | 0x3400 | true | 覆盖扩展A区(0x3400-0x4DBF) |
| 扩展F区 | 0x2CEB0 | true | 覆盖扩展F区(0x2CEB0-0x2EBEF) |
| 非CJK(ASCII) | 0x0041(A)、0x0061(a) | false | 覆盖大小写字母 |
| 非CJK(符号) | 0x0020(空格)、0x002E(.) | false | 覆盖标点、空格 |
2. normalize_to_codepoints测试数据
| 测试类型 | 输入文本 | 预期输出(码点列表) | 说明 |
|---|---|---|---|
| 混合字符(ASCII+CJK) | "Hello 世界!123" | ['h','e','l','l','o','世','界','1','2','3'] | 过滤标点,转小写ASCII,保留CJK |
| 全符号 | "!@#$%^&*()" | [] | 过滤所有非保留字符 |
| 空输入 | "" | [] | 处理空字符串 |
| 大小写混合ASCII | "AbC123XyZ" | ['a','b','c','1','2','3','x','y','z'] | 验证大小写转换 |
| 多语言混合(日文+韩文) | "こんにちは 안녕하세요" | [日文汉字码点, 韩文字符码点] | 验证扩展CJK区字符保留 |
3. jaccard_similarity测试数据
| 测试类型 | 集合1(哈希值) | 集合2(哈希值) | 预期相似度 | 说明 |
|---|---|---|---|---|
| 完全相同 | 1.0 | 验证相同输入的相似度 | ||
| 完全不同 | 0.0 | 验证无交集时的相似度 | ||
| 部分重叠 | 2/6≈0.333 | 验证交集/并集计算 | ||
| 空集合 | {} | {} | 0.0 | 验证边界条件 |
3.单元测试代码示例(关键函数)
以下是normalize_to_codepoints和jaccard_similarity的测试代码,展示测试逻辑和数据构造:
1. normalize_to_codepoints测试用例
class TestTextNormalization : public TestCase {
public:std::string getName() const override { return "文本归一化测试"; }bool run() override {// 测试1:混合ASCII+CJK+符号{std::string text = "Hello 世界!123";std::vector<unsigned char> bytes(text.begin(), text.end());auto codepoints = normalize_to_codepoints(bytes);std::vector<uint32_t> expected = {'h','e','l','l','o','世','界','1','2','3'};ASSERT_EQ(expected.size(), codepoints.size());for (size_t i = 0; i < expected.size(); ++i) {ASSERT_EQ(expected[i], codepoints[i]);}}// 测试2:全符号输入{std::string text = "!@#$%^&*()";std::vector<unsigned char> bytes(text.begin(), text.end());auto codepoints = normalize_to_codepoints(bytes);ASSERT_EQ(0, codepoints.size());}return true;}
};
2.jaccard_similarity测试用例
class TestJaccardSimilarity : public TestCase {
public:std::string getName() const override { return "Jaccard相似度计算测试"; }bool run() override {// 测试1:完全相同集合{std::unordered_set<uint64_t> set1 = {1, 2, 3, 4, 5};std::unordered_set<uint64_t> set2 = {1, 2, 3, 4, 5};double sim = jaccard_similarity(set1, set2);ASSERT_NEAR(1.0, sim, 0.001);}// 测试2:部分重叠集合{std::unordered_set<uint64_t> set1 = {1, 2, 3, 4};std::unordered_set<uint64_t> set2 = {3, 4, 5, 6};double sim = jaccard_similarity(set1, set2);ASSERT_NEAR(0.333, sim, 0.01); // 2/6≈0.333}return true;}
};
4.性能覆盖率分析
五、计算模块部分异常处理说明
1. 异常类型与设计目标
| 异常类型 | 触发场景 | 设计目标 |
|---|---|---|
| std::runtime_error(文件打开失败) | read_file_to_bytes中文件路径无效 | 提示用户检查文件路径是否存在 |
| std::runtime_error(文件读取失败) | 读取过程中磁盘错误或文件损坏 | 提示用户文件可能已损坏 |
| 命令行参数错误(argc≠4) | 用户未提供正确数量的输入参数 | 输出使用说明,指导正确输入格式 |
2. 单元测试样例(命令行参数错误)
TEST(ExceptionTest, InvalidArgcTest) {char* argv[] = {"./program", "orig.txt"}; // argc=2(正确应为4)int argc = 2;// 重定向cerr以捕获输出testing::internal::CaptureStderr();int result = main(argc, argv);std::string output = testing::internal::GetCapturedStderr();EXPECT_EQ(result, 1);EXPECT_NE(output.find("Usage:"), std::string::npos);
}
3. 异常处理场景验证
文件不存在:传入nonexistent.txt,程序应抛出runtime_error并提示“Failed to open file”。
参数不足:运行./program orig.txt,程序输出使用说明并返回1。