 本文以Apache Flink实时流处理为核心,通过SocketWordCount示例,系统讲解实时流处理基础概念、Flink优势、代码实现与并行处理机制,助力读者掌握Flink流处理实战技能。
本文以Apache Flink实时流处理为核心,通过SocketWordCount示例,系统讲解实时流处理基础概念、Flink优势、代码实现与并行处理机制,助力读者掌握Flink流处理实战技能。在大数据处理领域,实时流处理正变得越来越重要。Apache Flink作为领先的流处理框架,提供了强大而灵活的API来处理无界数据流。本文将通过经典的SocketWordCount示例,深入探讨Flink实时流处理的核心概念和实现方法,帮助你快速掌握Flink流处理的实战技能。
一、实时流处理概述
1. 流处理的基本概念
流处理是一种持续处理无界数据的计算范式。与批处理不同,流处理系统需要在数据到达时立即处理,而不是等待完整数据集收集完毕。在Flink中,所有数据都被视为流,无论是有界的历史数据还是无界的实时数据流。
2. Flink流处理的优势
- 低延迟: 毫秒级的数据处理延迟
- 高吞吐: 能够处理大规模的数据流量
- 精确一次处理: 通过检查点机制确保数据只被处理一次
- 灵活的时间语义: 支持处理时间、事件时间和摄取时间
- 丰富的状态管理: 内置多种状态后端,支持大规模状态存储
二、环境准备与依赖配置
1. 版本说明
- Flink:1.20.1
- JDK:17+
- Gradle:8.3+
2. 核心依赖
dependencies {// Flink核心依赖implementation 'org.apache.flink:flink_core:1.20.1'implementation 'org.apache.flink:flink-streaming-java:1.20.1'implementation 'org.apache.flink:flink-clients:1.20.1'}
三、SocketWordCount示例详解
1. 功能介绍
SocketWordCount是Flink中的经典示例,它通过Socket接收实时数据流,对数据流中的单词进行计数,并将结果实时输出。这个示例虽然简单,但包含了Flink流处理的核心要素:数据源连接、数据转换、并行处理和结果输出。
2. 完整代码实现
package com.cn.daimajiangxin.flink;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.util.Collector;import java.time.Duration;public class SocketWordCount {public static void main(String[] args) throws Exception {// 1. 创建执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 启用检查点,确保容错性env.enableCheckpointing(5000); // 每5秒创建一次检查点// 设置并行度env.setParallelism(2);// 2. 从Socket读取数据String hostname = "localhost";int port = 9999;// 支持命令行参数传入if (args.length > 0) {hostname = args[0];}if (args.length > 1) {port = Integer.parseInt(args[1]);}DataStream<String> text = env.socketTextStream(hostname,port,"\n", // 行分隔符0); // 最大重试次数// 3. 数据转换DataStream<Tuple2<String, Integer>> wordCounts = text.flatMap(new Tokenizer()).keyBy(value -> value.f0)//添加基于处理时间的滚动窗口计算.window(TumblingProcessingTimeWindows.of(Duration.ofSeconds(5)))// 使用sum聚合算子.sum(1);// 4. 输出结果wordCounts.print("Word Count");// 5. 启动作业env.execute("Socket Word Count");}// 可选:使用传统的FlatMapFunction实现方式public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {private static final long serialVersionUID = 1L;@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) {String[] words = value.toLowerCase().split("\\W+");for (String word : words) {if (word.length() > 0) {out.collect(Tuple2.of(word, 1));}}}}
}
3. 代码解析
3.1 执行环境创建
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
这段代码创建了Flink的执行环境,并设置了并行度为2。执行环境是所有Flink程序的入口点,它负责管理作业的执行。
3.2 数据源连接
DataStream<String> text = env.socketTextStream(hostname, port);
这里使用socketTextStream方法从Socket连接中读取文本数据。这是Flink提供的一种内置数据源连接器,适用于测试和演示。
3.3 数据转换
DataStream<Tuple2<String, Integer>> wordCounts = text.flatMap(new Tokenizer()).keyBy(value -> value.f0) // 按单词分组.sum(1); // 累加计数
数据转换包含三个关键步骤:
- 分词: 使用
flatMap操作将每行文本分割成单词,并为每个单词生成(word, 1)的元组 - 分组: 使用
keyBy操作按单词进行分组 - 聚合: 使用
sum操作对每个单词的计数进行累加
3.4 结果输出
wordCounts.print("Word Count");
使用print方法将结果输出到控制台,这是一种内置的输出方式,非常适合调试和演示。
3.5 作业启动
env.execute("Socket Word Count");
最后,调用execute方法启动作业。注意,Flink程序是惰性执行的,只有调用execute方法才会真正触发计算。
四、Flink并行流处理机制
1. 并行度概念
并行度是指Flink程序中每个算子可以同时执行的任务数量。在SocketWordCount示例中,我们设置了全局并行度为2,这意味着每个算子都会有2个并行实例。
2. 数据流分区策略
Flink支持多种数据流分区策略,包括:
- Forward Partitioning: 保持数据分区,一个输入分区对应一个输出分区
- Shuffle Partitioning: 随机将数据分发到下游算子的分区
- Rebalance Partitioning: 轮询将数据分发到下游算子的分区
- Rescale Partitioning: 类似于rebalance,但只在本地节点内轮询
- Broadcast Partitioning: 将数据广播到所有下游分区
- Key Group Partitioning: 基于键的哈希值确定分区
在SocketWordCount中,keyBy操作使用了Key Group Partitioning策略,确保相同单词的数据被发送到同一个分区进行处理。
3. 并行执行图解
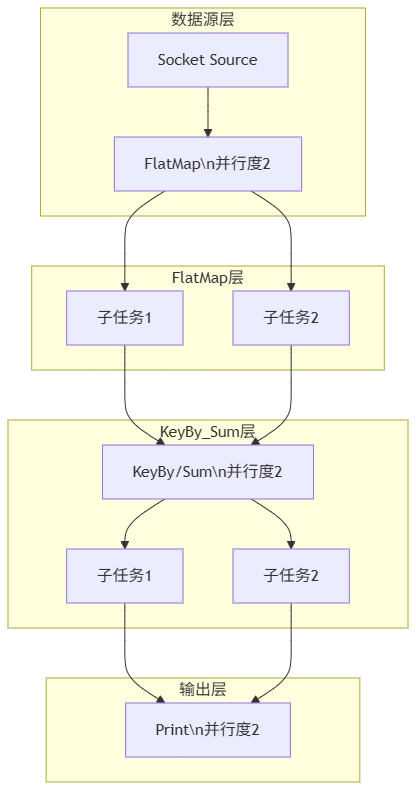
这个图清晰地展示了Flink并行执行的流程,包括:
- Socket数据源连接
- FlatMap操作(并行度为2)及其两个子任务
- KeyBy/Sum操作(并行度为2)及其两个子任务
- Print输出操作(并行度为2)
五、运行SocketWordCount
1. 准备Socket服务器
在运行SocketWordCount程序之前,我们需要先启动一个Socket服务器作为数据源。以下是几种常用的Socket服务器搭建方法:
1.1 使用netcat工具
Linux/Mac系统:
nc -lk 9999
参数说明:
- -l: 表示监听模式,等待连接
- -k: 表示保持连接,允许接受多个连接(对持续测试很有用)
- 9999: 端口号
Windows系统:
Windows有几种获取netcat的方式:
-
如果安装了Git,可以使用Git Bash:
nc -l -p 9999 -
如果安装了Windows Subsystem for Linux (WSL):
nc -lk 9999
参数说明:
- -l: 表示监听模式,等待连接
- -k: 表示保持连接,允许接受多个连接(对持续测试很有用)
- 9999: 端口号
1.2 使用Java实现Socket服务端
如果你想使用Java代码来创建一个更可控的Socket服务器,可以参考以下示例:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.ServerSocket;
import java.net.Socket;public class SimpleSocketServer {public static void main(String[] args) {int port = 9999;try (ServerSocket serverSocket = new ServerSocket(port)) {System.out.println("Socket服务器已启动,监听端口: " + port);while (true) {try (Socket clientSocket = serverSocket.accept();PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true);BufferedReader in = new BufferedReader(new InputStreamReader(System.in))) {System.out.println("客户端已连接,输入要发送的数据(输入'exit'退出):");String inputLine;while ((inputLine = in.readLine()) != null) {if (inputLine.equalsIgnoreCase("exit")) {break;}out.println(inputLine);}} catch (IOException e) {System.err.println("客户端连接异常: " + e.getMessage());}}} catch (IOException e) {System.err.println("无法启动服务器: " + e.getMessage());}}
}
这个Java实现的Socket服务器具有以下特点:
- 启动后持续监听9999端口
- 接受客户端连接并允许发送数据
- 支持通过输入'exit'退出当前客户端连接
- 异常处理更加完善
1.3 测试Socket连接
在启动Socket服务器后,你可以使用以下方法测试连接是否正常:
-
使用telnet客户端测试:
telnet localhost 9999 -
使用netcat作为客户端测试:
nc localhost 9999
1.4 常见问题与解决方法
-
端口被占用:
- 错误信息:
Address already in use或类似提示 - 解决方法:更换端口号,或使用
lsof -i :9999(Linux/Mac)查找占用端口的进程
- 错误信息:
-
防火墙阻止:
- 症状:服务器启动但客户端无法连接
- 解决方法:检查系统防火墙设置,确保端口9999已开放
-
权限问题(Linux/Mac):
- 症状:普通用户无法绑定低端口(<1024)
- 解决方法:使用sudo权限或选择1024以上的端口
-
Windows特殊情况:
- 如果nc命令不可用,可以使用上述PowerShell脚本或安装第三方netcat工具
- 确保Windows Defender防火墙允许连接
六、高级特性扩展
1. 添加窗口计算
添加基于处理时间的滚动窗口计算:
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;DataStream<Tuple2<String, Integer>> wordCounts = text.flatMap(new Tokenizer()).keyBy(value -> value.f0).window(TumblingProcessingTimeWindows.of(Duration.ofSeconds(5))).sum(1);
七、常见问题与解决方案
1. 连接被拒绝错误
问题:程序抛出Connection refused错误。
解决方案:确保Socket服务器已启动,并且监听在正确的端口上。
2. 结果不符合预期
问题:输出的单词计数结果不符合预期。
解决方案:检查分词逻辑是否正确,确保单词的大小写处理和分隔符使用得当。
3. 性能问题
问题:程序处理速度较慢。
解决方案:调整并行度,增加资源配置,或优化数据转换逻辑。
八、最佳实践
1. 生产环境配置
- 设置合适的并行度:根据集群资源和任务特性设置并行度
- 启用检查点:对于生产环境,启用检查点机制确保容错性
- 配置状态后端:根据数据量大小选择合适的状态后端
2. 代码优化建议
- 避免使用全局变量:确保函数是无状态的或正确管理状态
- 合理设置并行度:避免过度并行化导致的资源浪费
九、总结与展望
SocketWordCount虽然是一个简单的示例,但它涵盖了Flink流处理的核心概念和基本流程。通过这个示例,我们学习了如何创建Flink执行环境、连接数据源、进行数据转换、设置并行处理以及输出结果。
在实际应用中,Flink可以处理更复杂的流处理场景,如实时数据分析、欺诈检测、推荐系统等。后续我们还将深入学习Flink的窗口计算、状态管理、Flink SQL等高级特性,帮助你构建更强大的实时数据处理应用。
通过本文的学习,相信你已经对Flink实时流处理有了更深入的理解。实践是掌握技术的最好方法,不妨尝试修改SocketWordCount示例,添加更多功能,如窗口计算、状态管理等,进一步提升你的Flink技能!
源文来自:http://blog.daimajiangxin.com.cn
源码地址:https://gitee.com/daimajiangxin/flink-learning