1. 背景
在这里,我主要分享的是在应用层面大模型相关的技术,假如你已有一个现成的大模型接口,无论是符合OpenAI规范的,还是各家公司一些自己的接口,例如Gemini,Deepseek,通义千问,问心一言等,让用这些大模型来构建一些应用,可以选取下面的方案:
- 使用低代码大模型应用搭建平台,例如Coze,Dify, FastGPT等,这些平台带了流程编排,知识库,也很方便的和各种大模型对接,向量模型、向量库,有些还有了监控界面或者插件市场等,能满足我们的大部分需求
- 使用编程的方式来构建应用,这种可以使用公司现有的技术栈,提供更为灵活的使用,接入现有的系统等,或者从更高层面来说,定制自己的大模型应用规范,定制大模型应用构建平台,接入平台等;也可以把上面所说的低代码平台看作为自建大模型应用体系的一部分,即可以通过代码的方式灵活去构建应用,也通过平台更高效的去构建应用
我们后面讲的主要是使用第二种方式,我们选取一些现有的框架来实现,Python主要Langchain相关技术,Java也有一个对应的框架Langchain4j,也有SpringAI
这些框架帮我们做了很多事情:
- 封装一个通用的模型调用接口,屏蔽了底层不同公司大模型接口的差异
- 管理了会话和上下文,会话就是将用户之前问的问题和现在问的问题关联起来
- 结构化输出,将大模型的文本输出转为程序可以使用的结构化对象,例如JSON对象
- 工具/函数调用
- 可观测性
- 模型效果评估
一个框架LiteLLM专门把不同大模型接口适配为OpenAI格式的,这也是一种屏蔽差异的方式
2. 架构
 .png)
.png)
整体架构如上,下面主要介绍部分实现
- 模型框架层,SpringAI,Java大模型应用开发框架
- 模型推理能力,Ollama,利用本地CPU或GPU,和现有训练模型,实现模型推理能力,便于开发,生产环境需要替换
- 监控追踪,LangFuse,追踪大模型应用请求,例如输入输出,耗时、Token消耗等
3. 实现
3.1 安装
Ollama和LangFuse参照文档安装和启动
SpringAI通过pom导入,除此之外,还导入了springboot ollama、opentelemetry等相关包,后者是为了接入LangFuse
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.jd.jt</groupId><artifactId>ai-base</artifactId><version>1.0-SNAPSHOT</version><name>Archetype - ai-base</name><url>http://maven.apache.org</url><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.4.3</version><relativePath/> <!-- lookup parent from repository --></parent><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><maven.compiler.source>21</maven.compiler.source><maven.compiler.target>21</maven.compiler.target></properties><dependencyManagement><dependencies><dependency><groupId>io.opentelemetry.instrumentation</groupId><artifactId>opentelemetry-instrumentation-bom</artifactId><version>2.17.0</version><type>pom</type><scope>import</scope></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>1.0.1</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-ollama</artifactId></dependency><!-- Spring AI needs a reactive web server to run for some reason--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>io.opentelemetry.instrumentation</groupId><artifactId>opentelemetry-spring-boot-starter</artifactId></dependency><!-- Spring Boot Actuator for observability support --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><!-- Micrometer Observation -> OpenTelemetry bridge --><dependency><groupId>io.micrometer</groupId><artifactId>micrometer-tracing-bridge-otel</artifactId></dependency><!-- OpenTelemetry OTLP exporter for traces --><dependency><groupId>io.opentelemetry</groupId><artifactId>opentelemetry-exporter-otlp</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.38</version></dependency></dependencies>
</project>
3.2 起步示例
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;@RestController
@Slf4j
class MyController {private final ChatClient chatClient;public MyController(ChatClient.Builder chatClientBuilder) {this.chatClient = chatClientBuilder.build();}@GetMapping(value = "/ai-stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)Flux<String> generationStream(@RequestParam("userInput") String userInput) {return this.chatClient.prompt().user(userInput).stream().content();}@GetMapping("/ai")String generation(String userInput) {return this.chatClient.prompt().user(userInput).call().content();}
application.properties
spring.ai.ollama.chat.enabled=true
spring.ai.model.chat=ollama
spring.ai.ollama.chat.options.model=qwen3:8b
spring.ai.chat.observations.include-prompt=true
spring.ai.chat.observations.include-completion=true
management.tracing.sampling.probability=1.0
执行命令
curl --location 'http://localhost:8080/ai?userInput=%E4%BD%A0%E5%A5%BD'<think>
嗯,用户发来“你好”,我需要以自然的方式回应。首先,应该用中文回复,保持友好和亲切的语气。可以简单问候,比如“你好!有什么我可以帮助你的吗?”这样既回应了对方的问候,又主动询问是否需要帮助,符合我的设计原则。同时,要避免使用复杂或生硬的表达,让对话显得轻松。另外,考虑到用户可能有各种需求,保持开放式的提问可以引导他们进一步说明具体问题,这样我才能更好地提供帮助。确保回复简洁明了,符合日常交流的习惯。
</think>你好!有什么我可以帮助你的吗?😊
3.3 提示词
3.3.1 提示词模板
将变量嵌入提示词模板中,动态生成提示词
public String generateChildName() {PromptTemplate promptTemplate = new PromptTemplate("""男方姓:{maleName}女方姓:{femaleName}帮孩子起名""");Prompt prompt = promptTemplate.create(Map.of("maleName", "宋", "femaleName", "刘"));return chatClient.prompt(prompt).call().content();
}
执行命令
curl --location 'http://localhost:8080/get-name<think>
嗯,用户让我帮忙给孩子起名,男方姓宋,女方姓刘。首先,我需要了解用户的需求。他们可能想要一个结合双方姓氏的名字,或者更倾向于其中一个姓氏。不过通常在中国,孩子跟父姓,所以可能主要用宋姓,但有时候也会考虑双姓或者结合双方姓氏的元素。
...
提示词模板也可以通过Resource的方式使用,这样提示词可以存在任何地方了,工程文件、数据库、配置中心等,把提示词模板放在外部,更容易管理和实时变更,我们也可以通过第三方库来实现这个功能
3.3.2 提示词管理
提示词管理是将提示词单独存储在工程外部,提供一些易用的功能,例如版本控制,搜索提示词等。
我们这用了LangFuse,所以只要把它接入我们的项目即可
- 在界面上面创建提示词模板,并发布

- 在Java项目中接入,因为LangFuse没有Java的SDK,所以我们需要使用Api的方式
<dependency><groupId>com.github.lianjiatech</groupId><artifactId>retrofit-spring-boot-starter</artifactId><version>3.2.0</version></dependency>
创建LangFuseClient Http请求Client,改造之前写generateChildName方法,从LangFuse获取提示词
@RetrofitClient(baseUrl = "http://localhost:3000")
public interface LangFuseClient {@GET("api/public/v2/prompts/{promptName}")@Headers("Authorization: Basic cGstbGYtNDFmZjZkYjItZWZjNC00YTg4LTkyNmItZmMxZDE1ZGUwNGNiOnNrLWxmLTYzN2RmMDE0LWVkZDItNDdhNi1iNmUwLTE0N2U2MjMyOWYyMQ==")LFPrompt getPrompts(@Path("promptName") String promptName);
}public String generateChildName() {LFPrompt lfPrompt = langFuseClient.getPrompts("起名");PromptTemplate promptTemplate = new PromptTemplate(lfPrompt.getPrompt());Prompt prompt = promptTemplate.create(Map.of("maleName", "宋", "femaleName", "刘"));return chatClient.prompt(prompt).call().content();
}
- 执行命令,查看结果
curl --location 'http://localhost:8080/get-name'<think>嗯,用户让我帮忙给孩子起名,男方姓宋,女方姓刘。首先,我需要确认用户的需求。他们可能希望名字中包含双方的姓氏,或者结合两者的元素。不过,用户没有明确说明是否要双姓,所以可能需要考虑不同的可能性。接下来,我得考虑名字的寓意和音韵。中文名字通常讲究平仄搭配,读起来顺口,同时要有好的寓意。比如,宋和刘的组合,可能需要找一个字来连接,或者用两个字分别代表双方的姓氏。然后,用户要求输出在30个字以内,所以每个名字要简洁。可能需要列出多个选项,让用户有选择的余地。同时,要注意避免生僻字,确保名字的易读性和美观性。3.3.3 提示词工程
提示词工程是通过关注提示词开发和优化,提升大语言模型处理复杂任务场景的能力
具体可以参考提示工程指南
主要涉及了:
- 提示词的基本结构,例如包含指令、上下文,用户输入,输出指示
- 通用技巧
- 提示词技术,零样本提示,少样本提示,链式思考
如果有现成的提示词,可以直接拿过来用,开源的提示词awesome-chatgpt-prompts,商业的提示词promptbase,这样的网站很多,甚至可以使用大模型来生成提示词,通常会比自己从头开始写效率会高
3.4 结构化输出
将大模型的文本输出转化为固定结构
public List<String> generateChildName() {LFPrompt lfPrompt = langFuseClient.getPrompts("起名");PromptTemplate promptTemplate = new PromptTemplate(lfPrompt.getPrompt());Prompt prompt = promptTemplate.create(Map.of("maleName", "宋", "femaleName", "刘"));return chatClient.prompt(prompt).call().entity(new ListOutputConverter(new DefaultConversionService()));}
执行命令,可以看到返回结果变为了数组格式,但并不完美,通过提示词关闭think内容后,格式上面还是有一些问题,后续SpringAI会支持通过参数的方式关闭think过程
curl --location 'http://localhost:8080/get-name'["<think>\n\n</think>\n\n宋明轩","宋子涵","宋浩然","宋梓睿","宋俊熙","宋天宇","宋浩宇","宋梓豪",...
]
可以从提示词中,看到Spring AI为我们加了约束输出的提示词,输出结果也是按照这个格式,这个截图是LangFuse的监控的一部分,可以看到请求大模型的记录
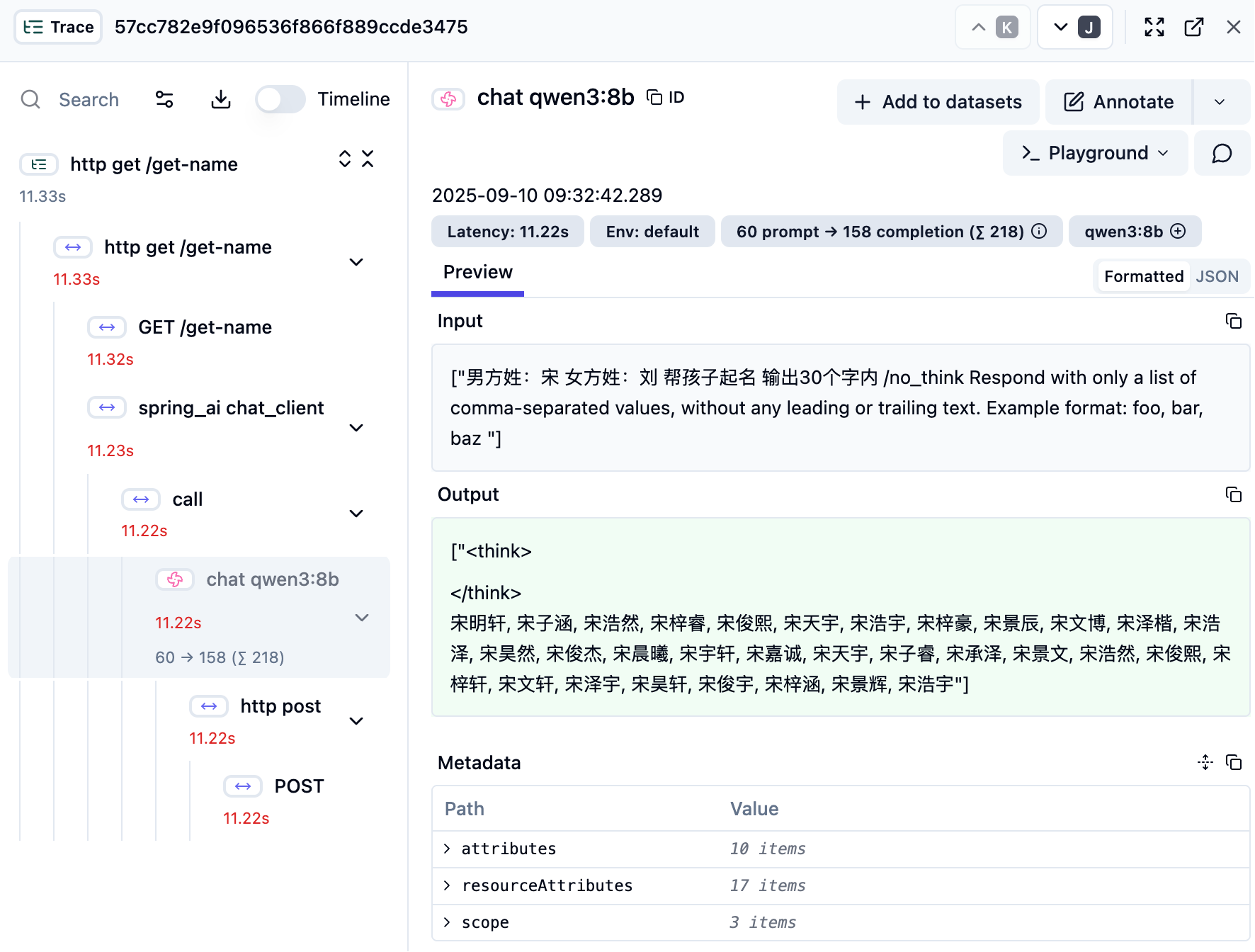

另外可以将结果转为Map或者Java的某个具体Class
3.5 会话和上下文
在使用大模型应用的过程中,通常会有两种模式
- 单轮对话,也就是一问一答,之前问过的问题不会再考虑
- 多轮对话,在整个对话周期呢,大模型会关联之前的问题,综合之后给出回复
要实现多轮对话的功能,就需要我们记录是否是一次会话和会话期间的上下文,因为大模型本身是无状态的,它自己不记录这些内容
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.converter.ListOutputConverter;
import org.springframework.core.convert.support.DefaultConversionService;
import org.springframework.stereotype.Service;import java.util.List;
import java.util.Map;@Service
public class ChatService {private final ChatClient chatClient;public ChatService(ChatClient.Builder chatClientBuilder) {ChatMemory chatMemory = MessageWindowChatMemory.builder().maxMessages(10).build();this.chatClient = chatClientBuilder.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build()).build();}public List<String> generateChildName(String conversationId, String surname, String gender) {// 系统提示词String systemMessage = "你是一个专业的起名专家,擅长根据中国传统文化和现代审美为孩子起名。请确保名字寓意美好、朗朗上口。";// 用户提示词模板String userMessageTemplate = """请为姓{surname}的{gender}孩子起名,要求:1. 输出不超过10个名字2. 每个名字都要有寓意说明3. 名字要符合现代审美""";PromptTemplate userPromptTemplate = new PromptTemplate(userMessageTemplate);Prompt userPrompt = userPromptTemplate.create(Map.of("surname", surname,"gender", gender));return chatClient.prompt().system(systemMessage) // 系统提示词.user(userPrompt.getContents()) // 用户提示词.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, conversationId)).call().entity(new ListOutputConverter(new DefaultConversionService()));}}
当发了两次请求之后,从回复的内容可以看看,大模型知道问了两次
["<think>\n好的,用户之前让我为姓宋的男孩起名,现在又发了一个类似的请求,但这次要求输出格式是逗号分隔的列表,没有其他文本。我需要仔细分析用户的需求。\n\n首先,用户可能是在测试我是否能按照新的格式要求输出,或者他们需要将名字直接用于某个系统,比如注册表单或应用程序,所以需要简洁的格式。之前的回复是中文名字和寓意,现在需要转换为只列出名字,用逗号分隔。\n\n接下来,我需要确保每个名字都符合现代审美,同时保持寓意美好。用户之前提供的例子中有“宋子墨”、“宋知远”等,这些名字都比较文雅,符合传统文化,同时又不失现代感。我需要保持这种风格,避免生僻字,确保名字朗朗上口。\n\n另外,用户可能希望名字有独特的寓意,同时避免重复。比如“宋明轩”中的“明”象征光明,“轩”有气度的意思,这样的组合既传统又现代。我需要检查每个名字的寓意是否明确,并且没有重复的字。\n\n还要注意名字的结构,姓氏“宋”是单姓,名字通常为两个字,所以每个名字都是两个字的组合。需要确保每个名字都符合这个结构,并且整体看起来协调。\n\n最后,用户要求不超过10个名字,所以我要控制数量,确保每个名字都经过筛选,符合所有要求。同时,输出格式必须严格遵循逗号分隔,没有其他文字,这可能需要在生成时特别注意格式的正确性,避免任何多余的字符或空格。\n</think>\n\n宋知远","宋云舟","宋景行","宋清晏","宋修远","宋墨言","宋怀瑾","宋承泽","宋明轩","宋致远"]
3.6 工具/函数调用
利用外部的工具,函数现有的能力,同时利用大模型的能力,结合起来完成复杂的任务,例如:
- 某些数学计算函数,天气查询服务,下单服务,订票服务,发邮件等,利用这些服务可以扩展大模型的能力
- 又例如通过数据库查询信息,文档库查询文档
工具类
import org.springframework.ai.tool.annotation.Tool;public class TicketUtil {@Tool(description = "输入出发地和目的地,购买火车票")public static void buyTicket(String source, String target) {System.out.println("已购买" + source + "到" + target + "的票");}
}
大模型请求时,使用tool方法
import com.jd.ai.util.TicketUtil;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.stereotype.Service;@Service
public class TicketService {private final ChatClient chatClient;public TicketService(ChatClient.Builder chatClientBuilder) {this.chatClient = chatClientBuilder.build();}public String buyTicket() {return chatClient.prompt("帮我买北京到晋城的车票").tools(new TicketUtil()).call().content();}}
大模型回复:
好的,用户让我帮忙买北京到晋城的车票。首先,我需要确认出发地和目的地是否正确。用户已经明确说明是北京到晋城,所以直接调用buyTicket函数,参数是source:北京,target:晋城。没有其他参数需要处理,比如日期或座位类型,所以直接生成工具调用。然后,系统返回“Done”,说明操作成功。接下来,我应该告诉用户购票成功,并询问是否需要进一步帮助,比如确认车次或办理乘车证。这样既完成了购票,又提供了后续支持,确保用户满意。 您的北京至晋城车票已成功购买!请问是否需要帮您查询具体车次信息或办理乘车证相关手续呢?控制台输出:
已购买北京到晋城的票
3.7 知识库和RAG
RAG(Retrieval Augmented Generation)是检索增强生成,简单来讲通过提前检索一些知识,将这些知识和用户的问题一起给大模型,会提高大模型回复的质量
3.7.1 知识库
对于通过分词的检索系统来讲,知识库一般是通过语义来检索的,要实现语义检索,需要对数据做向量化,所以需要向量模型和向量库
在这里我们用SimpleVectorStore来做向量库,这是一个内存库
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class VectorStoreConfiguration {@Beanpublic VectorStore vectorStore(EmbeddingModel embeddingModel) {return SimpleVectorStore.builder(embeddingModel).build();}
}
使用mxbai-embed-large作为向量模型,这个模型也使用了ollama的功能,且在SpringAI中不需要额外的配置就可以使用,当然也可以参照文档做一些定制配置,这里我们存了一些豆瓣的电影信息到里面
import jakarta.annotation.PostConstruct;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.MessageChatMemoryAdvisor;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.JsonReader;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.io.FileSystemResource;
import org.springframework.stereotype.Service;import java.util.List;@Service
public class MovieService {private final ChatClient chatClient;@AutowiredVectorStore vectorStore;@PostConstructvoid load() {String sourceFile = "/Users/songjiyang.3/Downloads/less_douban_movie.json";JsonReader jsonReader = new JsonReader(new FileSystemResource(sourceFile),"title", "year", "id", "role_desc", "original_title");List<Document> documents = jsonReader.get();this.vectorStore.add(documents);}public MovieService(ChatClient.Builder chatClientBuilder) {ChatMemory chatMemory = MessageWindowChatMemory.builder().maxMessages(10).build();this.chatClient = chatClientBuilder.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build()).build();}public List<Document> search(String query) {return this.vectorStore.similaritySearch(query);}下面是从向量库的搜索结果,搜索2013会出现2013年的电影,搜喜剧也出来一些电影,但并不是十分准确,因为我们这只存了电影的标题和演员名称,如果加入一些剧情文本,可能会匹配出来
http://localhost:8080/search-movie?query=2013[{"id":"9eb7a024-e1aa-45ef-921b-f565b45b4fd0","text":"title: 恐怖直播\nyear: 2013\nid: 21360417\nrole_desc: 金秉祐 / 河正宇 / 李璟荣 / 全慧珍\noriginal_title: 더 테러 라이브\n","media":null,"metadata":{"distance":0.4173857673321675},"score":0.5826142326678325},{"id":"b6a81d8a-bc6f-4eb1-921a-6a130f12b3eb","text":"title: 本命年\nyear: 1990\nid: 1296266\nrole_desc: 谢飞 / 蔡鸿翔 / 程琳 / 姜文\noriginal_title: \n","media":null,"metadata":{"distance":0.41915724341448546},"score":0.5808427565855145},{"id":"c5a67630-92ce-40b7-97c8-1ff989add62a","text":"title: 素媛\nyear: 2013\nid: 21937452\nrole_desc: 李濬益 / 薛景求 / 严志媛 / 李来\noriginal_title: 소원\n","media":null,"metadata":{"distance":0.4254743519837735},"score":0.5745256480162265},{"id":"d4d735e2-ac91-47e4-b241-dc7d86a32c6a","text":"title: 7号房的礼物\nyear: 2013\nid: 10777687\nrole_desc: 李焕庆 / 柳承龙 / 朴信惠 / 郑镇荣\noriginal_title: 7번방의 선물\n","media":null,"metadata":{"distance":0.4299756041030963},"score":0.5700243958969037}]http://localhost:8080/search-movie?query=喜剧
[{"id":"b8243634-9582-478f-ad61-69668af77d4d","text":"title: 熔炉\nyear: 2011\nid: 5912992\nrole_desc: 黄东赫 / 孔侑 / 郑有美 / 金贤秀\noriginal_title: 도가니\n","media":null,"metadata":{"distance":0.4354497256890415},"score":0.5645502743109585},{"id":"3a9d6a51-f99a-45cd-b6b3-36d868474b40","text":"title: 我能说\nyear: 2017\nid: 27000061\nrole_desc: 金炫锡 / 罗文姬 / 李帝勋 / 廉惠兰\noriginal_title: 아이 캔 스피크\n","media":null,"metadata":{"distance":0.44649545952808223},"score":0.5535045404719178},{"id":"7b21368e-4a78-4561-aa9a-dc3287b66372","text":"title: 可玛猫\nyear: 2009\nid: 2310047\nrole_desc: 合田经郎 / 合田经郎\noriginal_title: こま撮り映画・こまねこ\n","media":null,"metadata":{"distance":0.44757831325045716},"score":0.5524216867495428},{"id":"14c92297-f014-4b9d-8613-cfcdf9b2578c","text":"title: 红鳉鱼\nyear: 2015\nid: 26266892\nrole_desc: 高畑秀太 / 二宫和也 / 北野武 / 宫川大辅\noriginal_title: 赤めだか\n","media":null,"metadata":{"distance":0.4475958034962455},"score":0.5524041965037545}]
3.7.2 RAG
有了知识库之后,可以在此的基础上面,对大模型的问题做增强检索
public String suggestKnow(String query){return chatClient.prompt().system("你是一个电影推荐专家,请根据用户输入的查询词和知识库信息,推荐一部电影。").advisors(new QuestionAnswerAdvisor(vectorStore)).user(query).call().content();}public String suggest(String query){return chatClient.prompt().system("你是一个电影推荐专家,请根据用户输入的查询词,推荐一部电影。").user(query).call().content();}
推荐结果,可以看到有无知识库的区别,但是因为在这,这个知识库的质量不高,所以整体来讲,无知识库反而推荐的更好
http://localhost:8080/suggest-movie?query=喜剧好的,用户想要推荐一部喜剧电影。首先,我需要确定用户可能喜欢的喜剧类型,是轻松幽默的,还是带有讽刺或家庭元素的?不过用户只提到“喜剧”这个词,没有更多细节,所以我得选一部广受好评、适合大多数人的喜剧。 考虑到不同地区的观众,可能需要推荐一部国际知名的电影,比如美国或欧洲的。比如《疯狂的石头》是华语片,可能用户对中国电影感兴趣?或者选一部经典的老电影,比如《大话西游》?不过用户可能想要更现代的。 另外,用户可能希望电影有深度,不只是单纯的搞笑,比如《死亡诗社》虽然偏剧情,但也有幽默元素?或者像《伴我同行》这样的成长喜剧?不过用户明确要喜剧,可能更倾向于纯粹搞笑的。 再想想,像《疯狂动物城》这样的动画喜剧,适合各个年龄层,而且口碑不错。或者《触不可及》这样的法式喜剧,既有幽默又有温情。或者《人在囧途》这样的华语喜剧,比较贴近生活。 不过用户可能没有明确地区偏好,所以选一部国际认可的,比如《布达佩斯大饭店》虽然带点文艺,但也有喜剧元素。或者《银河护卫队》这样的超级英雄喜剧,比较受欢迎。 综合考虑,可能选一部广为人知、评价高的,比如《疯狂的石头》作为华语代表,或者《伴我同行》作为经典。不过用户可能想要更近期的,比如《人生遥控器》或者《疯狂动物城》。或者《大侦探福尔摩斯》虽然偏动作,但也有幽默。 再检查一下,用户可能需要一部适合推荐给朋友的,所以选一部口碑好、有笑点的,比如《人在囧途》或者《疯狂的石头》。或者《大话西游》作为经典,但可能用户已经看过。 最终决定推荐《疯狂的石头》,因为它是一部华语喜剧,剧情紧凑,有反转,适合喜欢黑色幽默的观众。同时也能展示中国电影的特色,可能用户对这方面感兴趣。或者再考虑其他选项,比如《让子弹飞》也是张艺谋的,但更偏剧情。可能还是《疯狂的石头》更合适。 根据您的需求,我推荐《疯狂的石头》(2006年,中国)。这部由徐峥自编自导自演的黑色幽默喜剧,以重庆火锅店为背景,通过多条故事线交织展开。影片将江湖恩怨、商战博弈与市井生活巧妙结合,既有荒诞的笑点,又暗含对人性的深刻剖析。其独特的叙事结构和对市井文化的刻画,使其成为华语喜剧中的经典之作。http://localhost:8080/suggest-movie-know?query=喜剧
好的,用户现在要找喜剧类的电影推荐。我需要根据提供的知识库里的信息来推荐。首先,我要看一下知识库里的电影列表,看看哪些是喜剧类型。 知识库里的电影有四部:熔炉(2011)、我能说(2017)、可玛猫(2009)、红鳉鱼(2015)。不过,这些电影的描述里没有明确提到类型,只有角色和导演等信息。比如,熔炉可能是一部剧情片或者社会剧,因为它的原名是“道加尼”,可能涉及社会问题。我能说的描述里也没有类型信息,但根据名字可能涉及语言或沟通的主题,可能不是喜剧。可玛猫的原名是“こま撮り映画・こまねこ”,看起来像是关于猫的电影,可能带有幽默元素,但不确定是否是喜剧。红鳉鱼的原名是“赤めだか”,可能和鱼类有关,但类型不明确。 问题在于,用户要求推荐喜剧,但提供的知识库中没有明确说明任何电影属于喜剧类型。因此,根据现有的信息,无法确定这些电影是否符合喜剧的要求。这时候应该告诉用户,根据提供的资料,无法推荐喜剧电影,因为没有相关类型的信息。需要确认是否有其他信息或者是否需要进一步补充。 根据提供的资料,这些电影的描述中未明确提及喜剧类型,因此无法直接推荐符合喜剧分类的影片。建议提供更多关于电影类型的细节或补充信息以便更精准推荐。
3.8 MCP
MCP(Model Context Protocol )是大模型应用和其他资源或者工具交互的一种标准协议,分为客户端和服务端
3.8.1 MCP服务端
引入依赖,webmvc这种方式会暴露一个http路径,其他mcp客户端通过这个路径来这个服务端交互,还有其他方式来实现MCP服务,例如STDIO
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
</dependency>
在原先的买票工具上面,加一个ToolCallbackProvider,这个会把工具类暴露出来
@Component
public class TicketUtil {@Tool(description = "输入出发地和目的地,购买火车票")public static void buyTicket(String source, String target) {System.out.println("已购买" + source + "到" + target + "的票");}@Beanpublic ToolCallbackProvider tools() {return MethodToolCallbackProvider.builder().toolObjects(this).build();}
}
增加配置
spring.ai.mcp.server.name=webmvc-mcp-server
spring.ai.mcp.server.version=1.0.0
spring.ai.mcp.server.type=SYNC
spring.ai.mcp.server.instructions=This server provides weather information tools and resources
spring.ai.mcp.server.sse-message-endpoint=/mcp/messages
spring.ai.mcp.server.capabilities.tool=true
spring.ai.mcp.server.capabilities.resource=true
spring.ai.mcp.server.capabilities.prompt=true
spring.ai.mcp.server.capabilities.completion=true
使用MCP客户端接入,这里使用了Cherry-Studio,首先在里面配置MCP服务
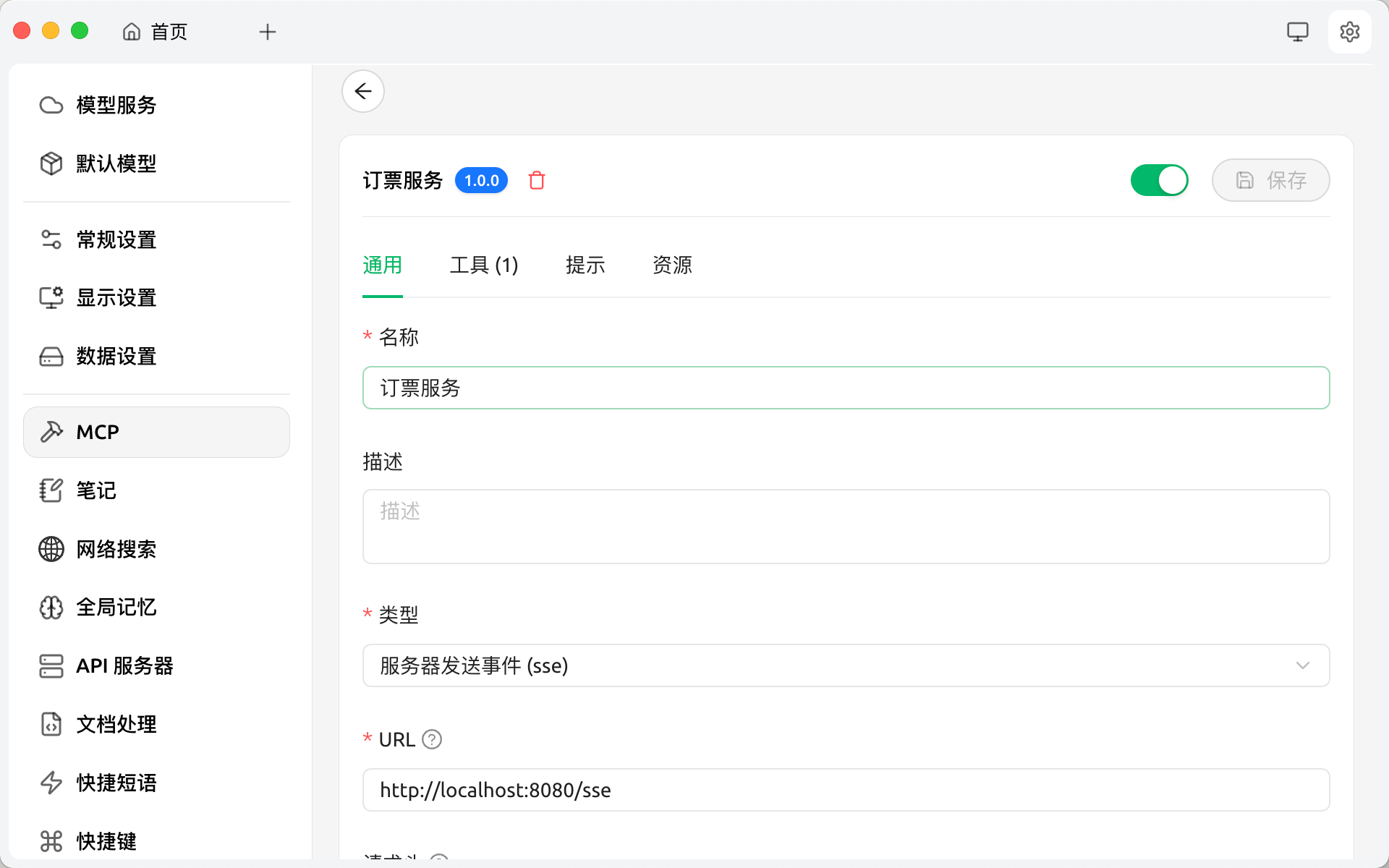

然后在对话问答中勾选MCP服务并提问,可以看到MCP调用

3.8.2 MCP客户端
MCP的客户端可以是一个IDE,或者大模型对话客户端(例如上面的Cherry-Studio),当然,也可以是一个程序,SpringAI也支持实现MCP客户端
引入依赖
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-mcp-client</artifactId></dependency>
SpirngBoot配置
spring.ai.ollama.chat.enabled=true
spring.ai.model.chat=ollama
spring.ai.ollama.chat.options.model=qwen3:8b
spring.ai.chat.observations.include-prompt=true
spring.ai.chat.observations.include-completion=true
management.tracing.sampling.probability=1.0
spring.ai.mcp.client.sse.connections.server1.url=http://localhost:8080
server.port=8081 //本地8080被MCP服务端占用了
在模型调用中加入MCP服务,注释的代码是上面使用本地工具的例子,MCP可以理解为远程或者外部的工具,MCP服务端就是刚刚在上一节中我们自己实现的服务端,我们通过配置的http://localhost:8080找到了它,并了解了它有哪些工具,这些都是SpringAI帮我们做的
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.mcp.SyncMcpToolCallbackProvider;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;@Service
public class TicketService {private final ChatClient chatClient;@Autowiredprivate SyncMcpToolCallbackProvider toolCallbackProvider;public TicketService(ChatClient.Builder chatClientBuilder) {this.chatClient = chatClientBuilder.build();}public String buyTicketMCP() {return chatClient.prompt("帮我买北京到晋城的车票").toolCallbacks(toolCallbackProvider).call().content();}// public String buyTicket() {
//
// return chatClient
// .prompt("帮我买北京到晋城的车票")
// .tools(new TicketUtil())
// .call()
// .content();
//
// }}
使用和结果,可以看到大模型的思考过程中是使用了mcp服务的
http://localhost:8081/buy-ticket-mcp?query=买北京的晋城的票好的,用户让我帮忙买北京到晋城的车票。首先,我需要确认用户的需求是否明确。用户提到的出发地是北京,目的地是晋城,这两个地点都是中国的城市,但需要确认是否有直达的火车线路,或者是否需要中转。不过,根据提供的工具函数,似乎只需要输入出发地和目的地即可,不需要考虑其他复杂因素。 接下来,我需要检查工具函数的参数。工具函数是spring_ai_mcp_client_server1_buyTicket,参数是arg0和arg1,都是字符串类型。根据描述,arg0应该是出发地,arg1是目的地。因此,正确的参数应该是arg0为“北京”,arg1为“晋城”。 不过,我需要确认用户是否已经提供了足够的信息。比如,是否有指定日期、座位类型或者车次偏好?但用户的问题中没有提到这些细节,所以可能只需要处理基本的出发地和目的地。如果用户后续有更多需求,可能需要进一步询问,但当前情况下,先按照提供的两个参数处理。 另外,要确保输入的格式正确,是否需要使用全称还是简称?比如,北京通常用“北京”表示,晋城也是全称。所以直接使用这两个城市名称作为参数应该是正确的。 最后,生成对应的工具调用,将参数填入函数中,返回正确的JSON结构。确保没有拼写错误,参数顺序正确,arg0是出发地,arg1是目的地。这样用户的需求就能被正确处理了。 车票购买请求已处理,北京至晋城的火车票已成功预订。请注意查收短信通知,确认车次和乘车时间。如有其他需求,请随时告知。
3.9 监控和指标
通过对大模型应用的监控,可以有以下好处:
- 方便调试、开发,了解大模型应用内部的执行流程
- 耗时分析
- Token成本分析
- 模型评估的前提
- 方便排查问题
这里我们主要用的是LangFuse,现在SpringAI已经可以很好的和LangFuse配合来监控大模型调用,但目前对于工具、MCP的调用还欠缺,需要自己来实现
下面是一个监控的示例,左边是一系列的请求,右边是某一个请求的详情,可以看到各个执行节点,各个节点入参和出参等

3.9.1 接入LangFuse
接入的依赖和配置参考3.1
另外需要配置的一个URL和秘钥,URL是LangFuse的启动的地址,秘钥需要通过LangFuse管理界面生成,配置以下环境变量
OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:3000/api/public/otel;OTEL_EXPORTER_OTLP_HEADERS=Authorization\\=Basic cGstbGYtNGFhYjdhNWEtNThjYi00MWQ2LWIyODktY2M1MDgyMmNiMDliOnNrLWxmLWYxM2YzMmMzLTlkMzItNGE5My1iZmI0LTMxODFiOTE1Yzg2Yw\\=\\=
详情见LangFuse文档
3.10 模型评估
很多时候,在开发大模型应用的时候,我们需要不断调整提示词,知识库,工作流,工具,模型、模型参数等,这些内容的变更,都会影响最终大模型的回复质量,为了保证大模型的回复质量满足我们的需求,所以需要有模型评估这个环节
下面是模型评估的一个基本流程
- 离线评估
- 准备数据集,也就是用户的问题和期望的回复
- 运行数据集测试
- 评估生成的结果,可以人工/大模型/自定义的方式评估
- 在线评估,在离线评估达到一个可以上线的水平之后
- 线上收集用户问题和实际的回复
- 评估生成的结果,可以人工/大模型/自定义的方式评估,同时也可以结合用户的反馈
- 根据实际的评估数据,找到现有流程的问题,更新原有流程,同时填加新的测试集数据
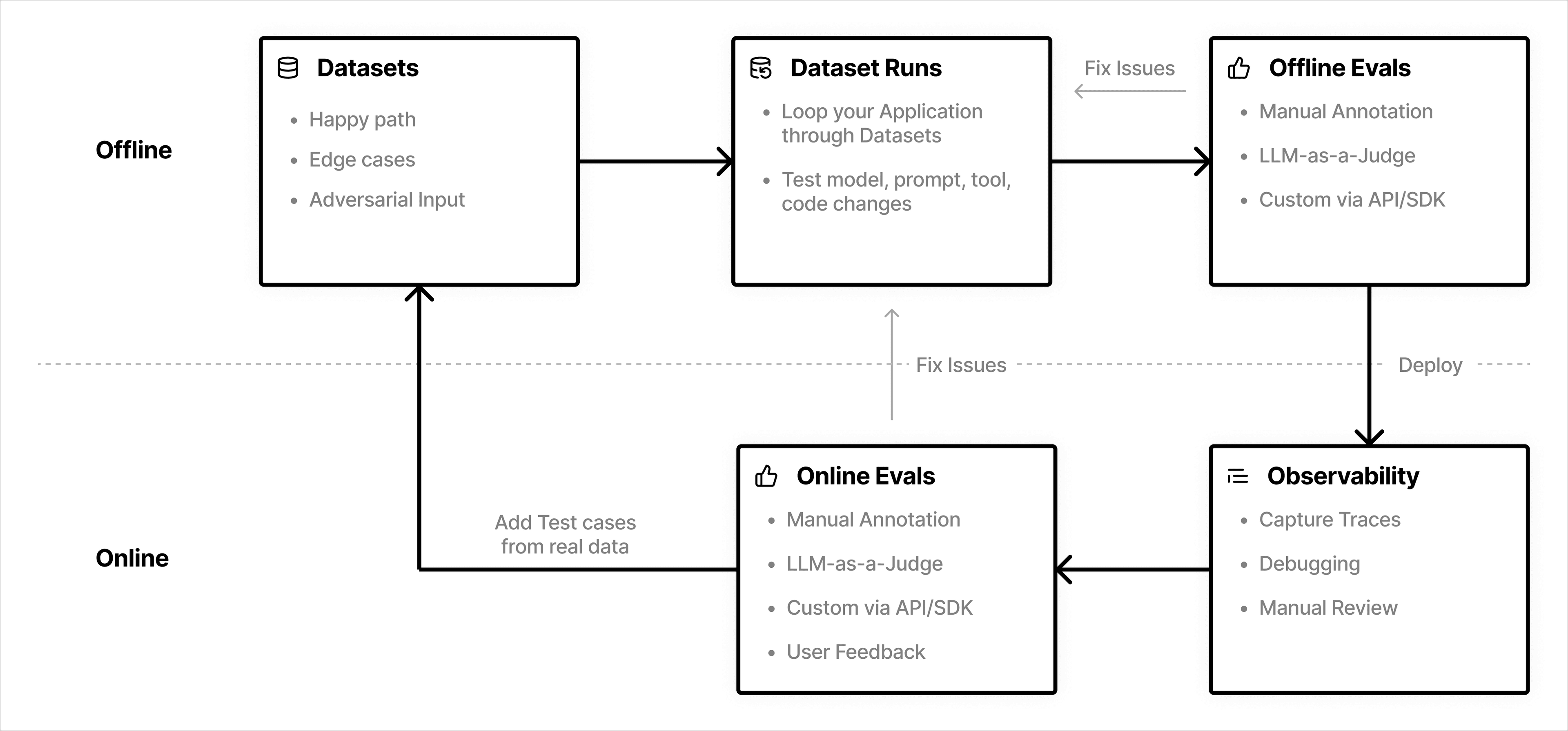
LangFuse可以帮助我们实现上面的评估,详情可以参考文档
3.11 多模态调用
更换ollama支持多模态的模型,这选用了llama3.2-vision:11b,支持图文
修改配置
spring.ai.ollama.chat.options.model=llama3.2-vision:11b
多模态调用
public String multiModality() {return chatClient.prompt().system("结果必须用中文回复").user(u -> u.text("解释图片的内容").media(MimeTypeUtils.IMAGE_PNG, new FileSystemResource("/Users/songjiyang.3/Downloads/OIP-C.jpeg"))).call().content();}
结果
该图片显示了一只猫的头部,猫的头部被一个白色毛毯包裹起来,猫的眼睛被毛毯的部分遮住了。
3.12 插件管理
我们在有些开源的大模型工具中,会看到插件,插件是一个工具集,一个插件内可以包含一个或多个工具(API)
看起来只是把多个工具整合起来,但配置插件市场,可以让工具变的像手机APP一样,安装即可使用,大量现成的工具可以供我们使用(可能需要付费)

对于Saas服务这个非常好用,也算是一种开源
4. 总结
本文介绍了使用SpringAI + Ollama + LangFuse 构建大模型应用,包括整体的架构,和使用SpringAI构建应用的各个细节,在实际项目中,每个部分都会更复杂
适用于企业级定制开发、复杂对话系统、RAG知识问答
5. 想法
大模型技术的底层是算力,现在互联网应用能给用户免费使用的原因是因为服务器以极低的成本被大量用户共享使用,而大量用户带来的流量的收益是高于这些成本的,一旦服务器的成本变高,公司就是使用某些手段,例如限速,订阅的方式来平衡支出。
而大模型的使用依赖算力,问一个问题的成本大概可以估计出来,如下表,虽然看起来成本不高,但用户体量一旦起来,算力成本非常高,现在之所以很多是免费使用,一是因为现在还处于抢占市场阶段,二是因为用户的输入可以成本大模型的训练数据。
| 厂商 | 免费政策 | 企业级API价格(输入/输出) | 适用场景 |
|---|---|---|---|
| 百度文心一言 | 全功能免费 | 0.004/0.016元/千tokens(4.5) | 个人/企业全场景 |
| 阿里通义千问 | 新用户免费额度 | 0.0003/0.0006元/千tokens(Turbo) | 性价比优先的企业应用 |
| 华为盘古 | 无免费额度 | 推理资源20元/小时起 | 工业级复杂任务 |
| 字节豆包 | 完全免费 | 未公开(当前免费) | 个人学习、轻量开发 |
基本上是不可能免费给用户使用,大胆猜测一下,后面算力会变为宽带,流量这样的基础设施,由用户自行购买使用来满足自己的需求
6. 附录
【1】SpringAI官方文档
【2】LangFuse官方文档
【3】Ollama官方文档
【4】CherryStudio官网