Yarn资源调度器
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
Y****arn基本架构
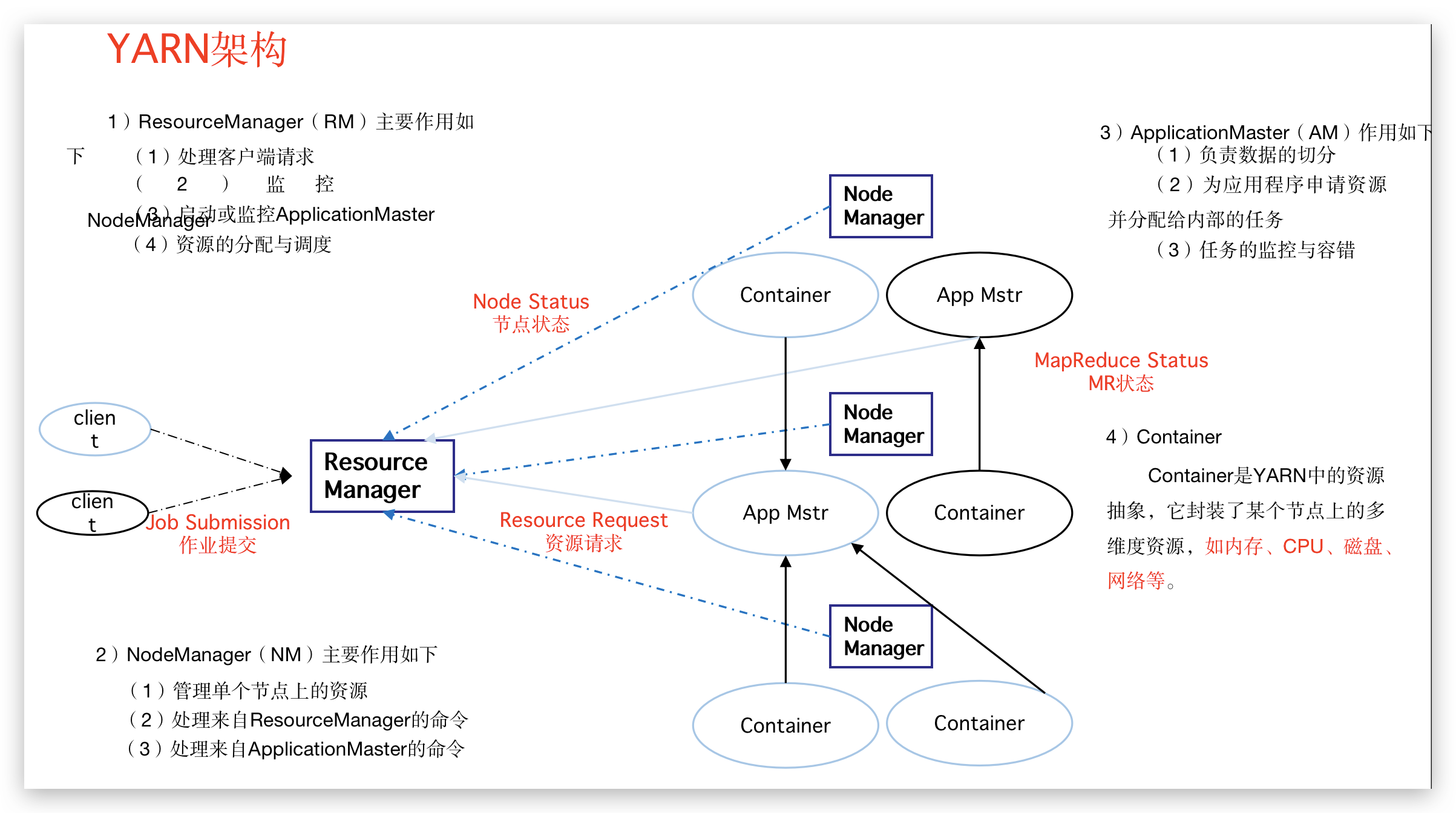
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。
Y****arn工作机制
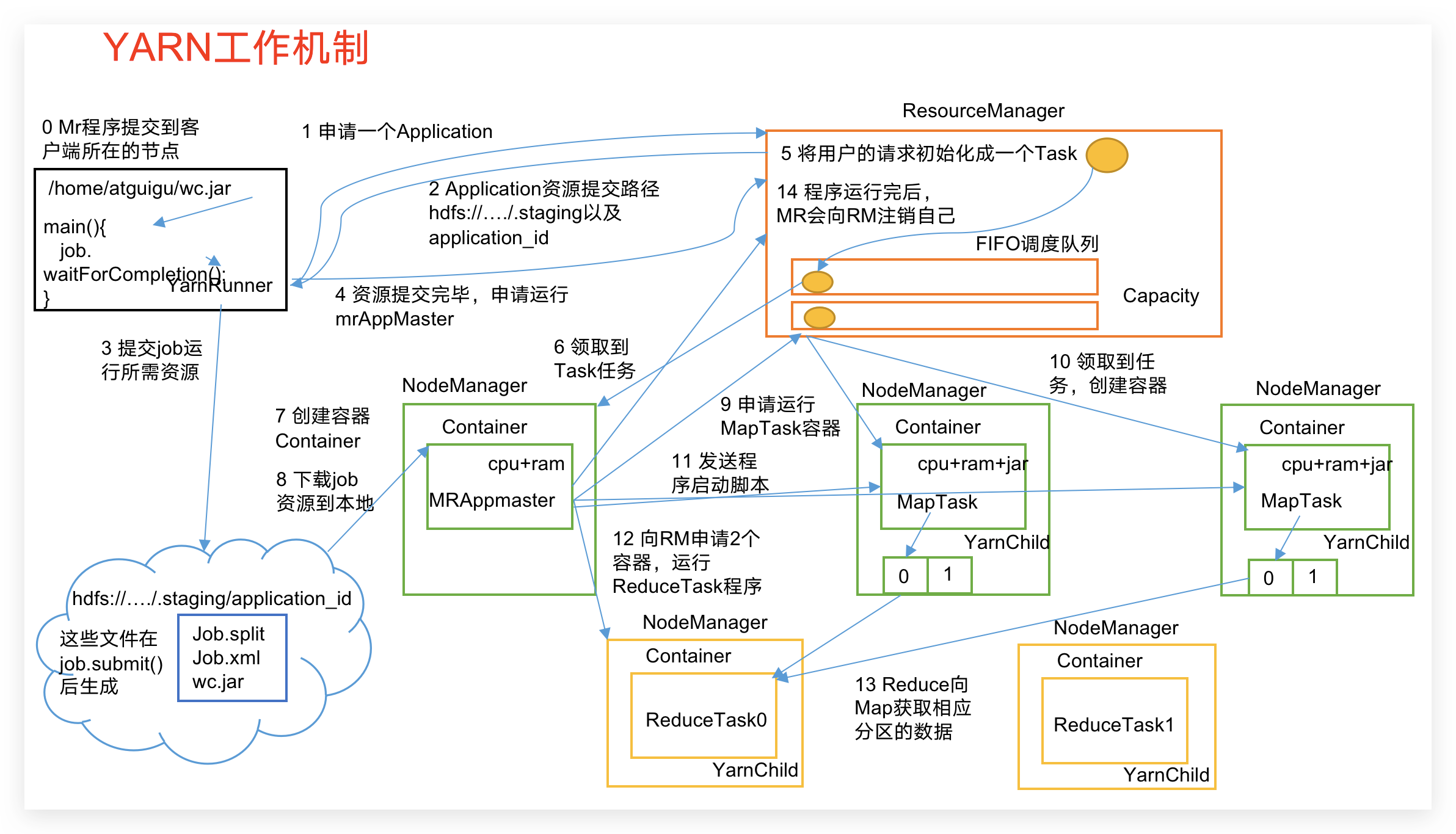
(1)MR程序提交到客户端所在的节点。
(2)YarnRunner向ResourceManager申请一个Application。
(3)RM将该应用程序的资源路径返回给YarnRunner。
(4)该程序将运行所需资源提交到HDFS上。
(5)程序资源提交完毕后,申请运行mrAppMaster。
(6)RM将用户的请求初始化成一个Task。
(7)其中一个NodeManager领取到Task任务。
(8)该NodeManager创建容器Container,并产生MRAppmaster。
(9)Container从HDFS上拷贝资源到本地。
(10)MRAppmaster向RM 申请运行MapTask资源。
(11)RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(12)MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
(13)MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
(14)ReduceTask向MapTask获取相应分区的数据。
(15)程序运行完毕后,MR会向RM申请注销自己。
作业提交全****过程
作业提交全过程详解
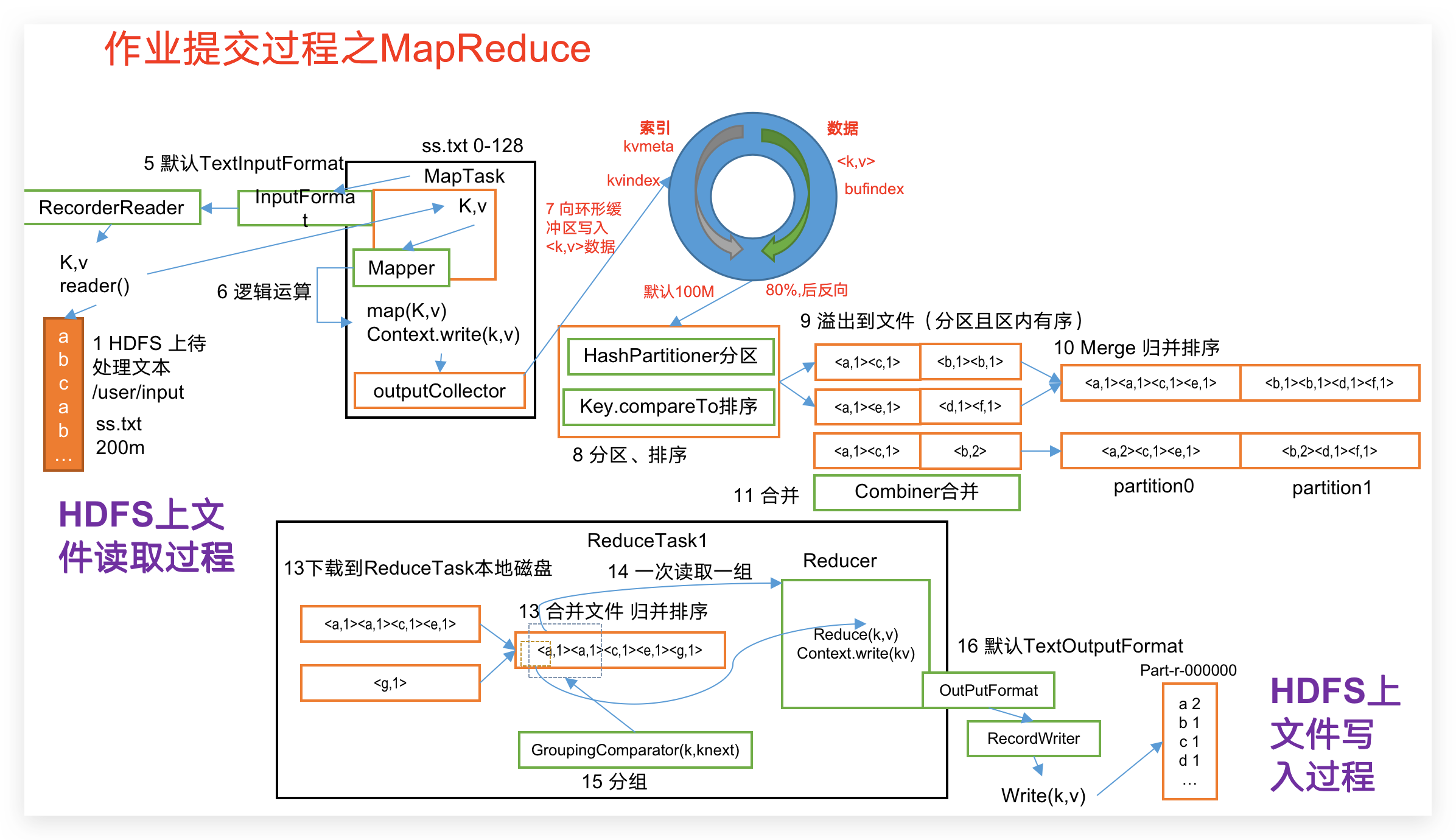
(1)作业提交
第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
第2步:Client向RM申请一个作业id。
第3步:RM给Client返回该job资源的提交路径和作业id。
第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
第5步:Client提交完资源后,向RM申请运行MrAppMaster。
(2)作业初始化
第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
第7步:某一个空闲的NM领取到该Job。
第8步:该NM创建Container,并产生MRAppmaster。
第9步:下载Client提交的资源到本地。
(3)任务分配
第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
(4)任务运行
第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
第14步:ReduceTask向MapTask获取相应分区的数据。
第15步:程序运行完毕后,MR会向RM申请注销自己。
(5)进度和状态更新
YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
(6)作业完成
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
资源调度器
目前,Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop3.1.3默认的资源调度器是Capacity Scheduler。
具体设置详见:yarn-default.xml文件
1****)先进先出调度器(FIFO)
2)容量调度器(Capacity Scheduler)
3)公平调度器(Fair Scheduler)
容量调度器多队列提交案例
Yarn默认的容量调度器是一条单队列的调度器,在实际使用中会出现单个任务阻塞整个队列的情况。同时,随着业务的增长,公司需要分业务限制集群使用率。这就需要我们按照业务种类配置多条任务队列。
配置多队列的容量调度器
默认Yarn的配置下,容量调度器只有一条Default队列。在capacity-scheduler.xml中可以配置多条队列,并降低default队列资源占比:
The queues at the this level (root is the root queue).
同时为新加队列添加必要属性:
在配置完成后,重启Yarn,就可以看到两条队列:
向Hive队列提交任务
默认的任务提交都是提交到default队列的。如果希望向其他队列提交任务,需要在Driver中声明:
public class WcDrvier {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
configuration.set("mapred.job.queue.name", "hive");
//1. 获取一个Job实例
Job job = Job.getInstance(configuration);
//2. 设置类路径
job.setJarByClass(WcDrvier.class);
//3. 设置Mapper和Reducer
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
//4. 设置Mapper和Reducer的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setCombinerClass(WcReducer.class);
//5. 设置输入输出文件
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//6. 提交Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
这样,这个任务在集群提交时,就会提交到hive队列:
常见错误及****解决方案
1)导包容易出错。尤其Text和CombineTextInputFormat。
2)Mapper中第一个输入的参数必须是LongWritable或者NullWritable,不可以是IntWritable. 报的错误是类型转换异常。
3)java.lang.Exception: java.io.IOException: Illegal partition for 13926435656 (4),说明Partition和ReduceTask个数没对上,调整ReduceTask个数。
4)如果分区数不是1,但是reducetask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。
5)在Windows环境编译的jar包导入到Linux环境中运行,
hadoop jar wc.jar com.atguigu.mapreduce.wordcount.WordCountDriver /user/atguigu/ /user/atguigu/output
报如下错误:
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/atguigu/mapreduce/wordcount/WordCountDriver : Unsupported major.minor version 52.0
原因是Windows环境用的jdk1.7,Linux环境用的jdk1.8。
解决方案:统一jdk版本。
6)缓存pd.txt小文件案例中,报找不到pd.txt文件
原因:大部分为路径书写错误。还有就是要检查pd.txt.txt的问题。还有个别电脑写相对路径找不到pd.txt,可以修改为绝对路径。
7)报类型转换异常。
通常都是在驱动函数中设置Map输出和最终输出时编写错误。
Map输出的key如果没有排序,也会报类型转换异常。
8)集群中运行wc.jar时出现了无法获得输入文件。
原因:WordCount案例的输入文件不能放用HDFS集群的根目录。
9)出现了如下相关异常
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:609)at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977)
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:356)at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:371)at org.apache.hadoop.util.Shell.<clinit>(Shell.java:364)
解决方案:拷贝hadoop.dll文件到Windows目录C:\Windows\System32。个别同学电脑还需要修改Hadoop源码。
方案二:创建如下包名,并将NativeIO.java拷贝到该包名下
10)自定义Outputformat时,注意在RecordWirter中的close方法必须关闭流资源。否则输出的文件内容中数据为空。
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
if (atguigufos != null) {atguigufos.close();}if (otherfos != null) {otherfos.close();}
}