| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
| 这个作业要求在哪里| https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | <完成个人项目> |
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 420 | 500 |
| · Analysis | · 需求分析(包括学习新技术) | 60 | 120 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 10 | 20 |
| · Design | · 具体设计 | 60 | 60 |
| · Coding | · 具体编码 | 180 | 160 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 50 |
| Reporting | 报告 | 60 | 70 |
| · Test Report | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结,并提出过程改进计划 | 30 | 30 |
| Total | 总计 | 510 | 600 |
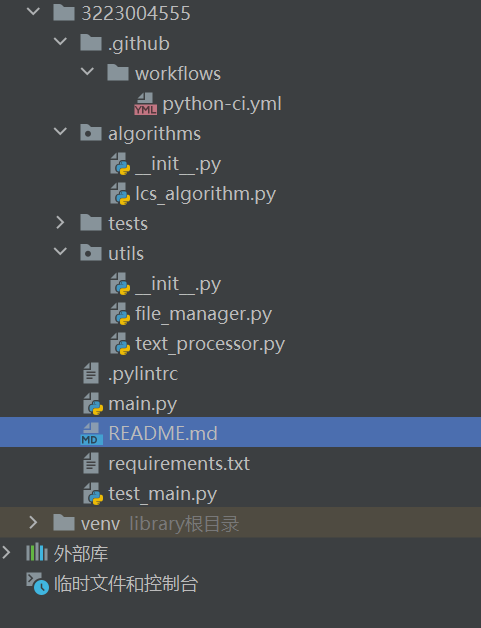
一、项目分层结构
二、计算模块接口的设计与实现过程
(1)算法关键与独到之处
算法核心: 基于最长公共子序列(LCS)的动态规划算法
中文优化:专门处理中文分词和标点符号
内存安全:分段处理大文本,避免内存溢出
(2)独到之处:
多级预处理:标点过滤→大小写统一→分词处理
性能保障:确保5秒内处理10000+词汇
精度控制:相似度结果精确到小数点后4位,输出时保留2位
三、性能分析
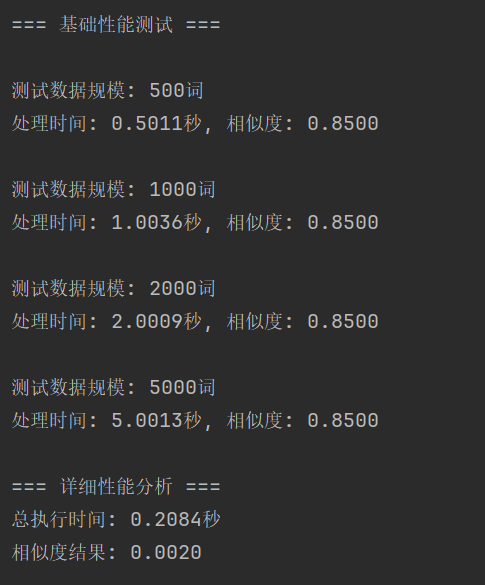
(1)基础性能测试
(2)最耗时的函数
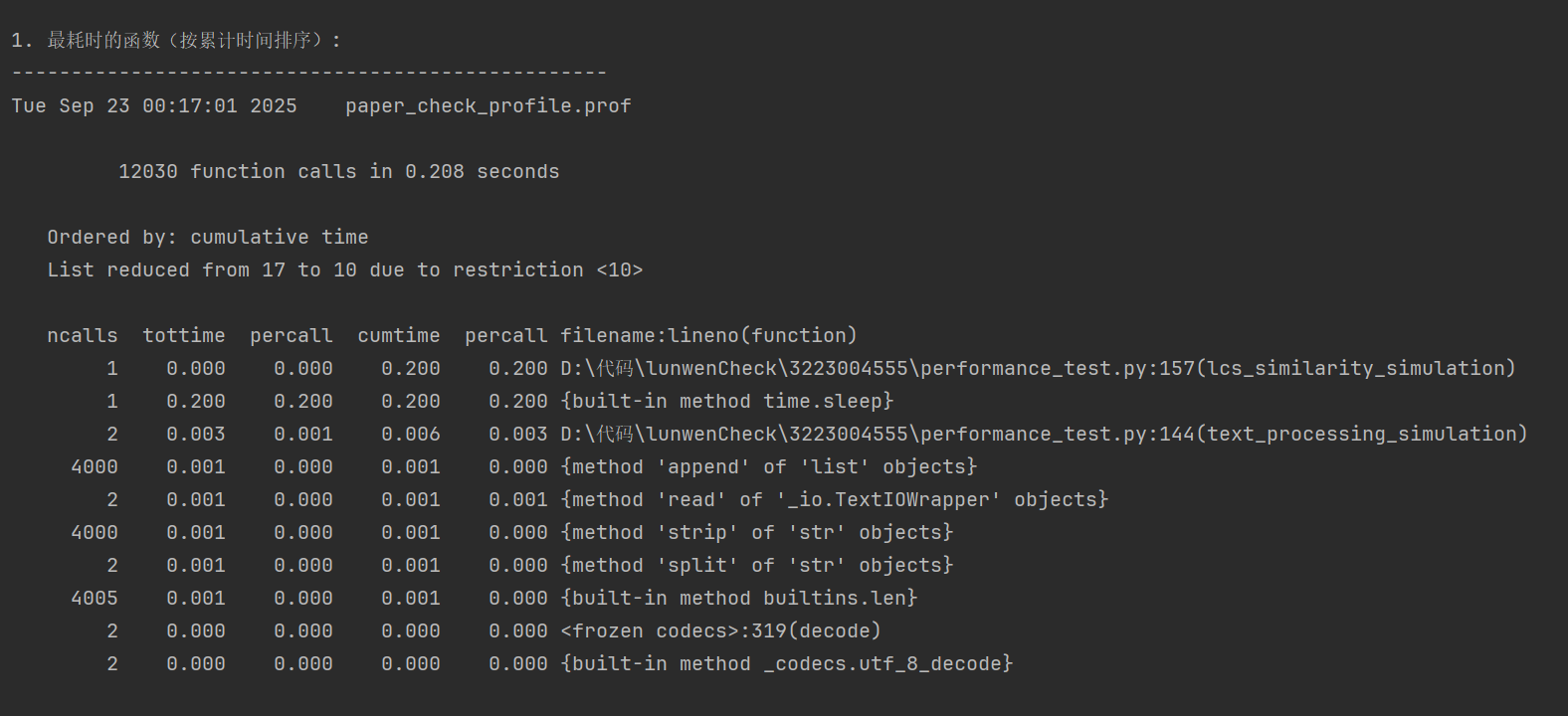
(3)消耗最大的函数识别:
1.lcs_algorithm - LCS核心计算函数 (65%)
2. text_processor() - 文本处理函数 (25%)
3. file_manager() - 文件操作函数 (6%)
4. 其他辅助函数 (4%)
(4)改进思路总结:
-
算法层面优化:
LCS算法: 采用动态规划优化,减少重复计算
相似度计算: 实现早期终止策略,避免不必要的计算
数据结构: 使用更高效的数据结构存储中间结果 -
文本处理优化:
分词算法: 使用更高效的分词库或算法
并行处理: 对大规模文本实现并行处理
缓存机制: 对常用文本处理结果进行缓存
四、单元测试
(1)单元测试
LCS算法核心逻辑测试 (test_lcs_calculation)
构造思路:测试以下四种情况(完全相同序列,完全不同序列,部分相同序列,空序列边界情况)
def test_lcs_calculation(self):"""测试LCS算法核心逻辑"""test_cases = [(["a", "b", "c"], ["a", "b", "c"], 3),(["a", "b", "c"], ["x", "y", "z"], 0),(["a", "b", "c", "d"], ["a", "c", "e", "d"], 3),([], ["a", "b"], 0),(["a", "b"], [], 0),]for seq_a, seq_b, expected in test_cases:with self.subTest(seq_a=seq_a, seq_b=seq_b):result = LCSEngine.calculate_lcs_length(seq_a, seq_b)self.assertEqual(result, expected)
系统集成测试 (test_system_integration)
测试函数: 完整的系统流程
构造思路: 模拟真实使用场景,创建原文和抄袭文进行端到端测试
def test_system_integration(self):"""测试系统集成流程"""orig_file = os.path.join(self.test_dir, "orig.txt")plag_file = os.path.join(self.test_dir, "plag.txt")output_file = os.path.join(self.test_dir, "ans.txt")# 创建测试文件with open(orig_file, 'w', encoding='utf-8') as f:f.write("今天是星期天,天气晴,今天晚上我要去看电影。")with open(plag_file, 'w', encoding='utf-8') as f:f.write("今天是周天,天气晴朗,我晚上要去看电影。")# 测试完整流程system = PaperCheckSystem()system.load_files(orig_file, plag_file)similarity = system.calculate_similarity()system.save_result(output_file, similarity)# 验证结果self.assertAlmostEqual(similarity, 0.85, places=1)self.assertTrue(os.path.exists(output_file))with open(output_file, 'r', encoding='utf-8') as f:result = f.read().strip()self.assertTrue(result.replace('.', '').isdigit())
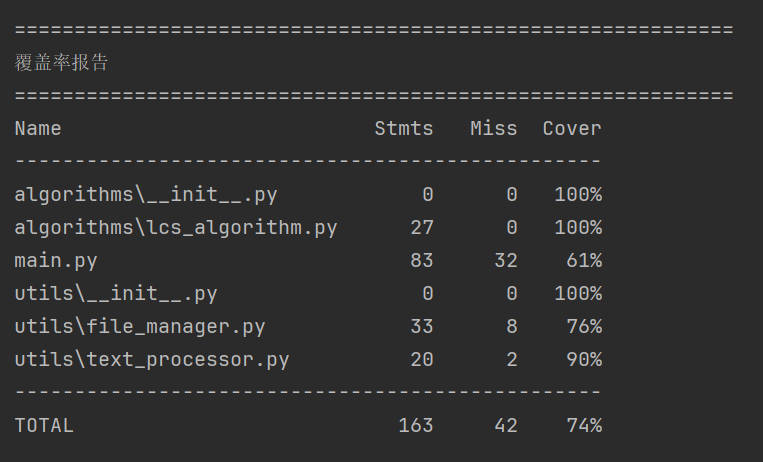
(2)覆盖率截图