一、开篇引言
京东零售从9月开始对技术风险系统性地跟踪汇报,以故障数、监控发现率、故障发现时间、故障恢复时间等多个指标进行统计和跟踪汇报,相比于之前线上小故障杖责二十、大故障发配宁古塔,有了向惩前毖后、治病救人方向的转变。我也有机会参与到其中部分问题的复盘,发现问题的原因要不是因为需求变更过程中理解有误,要不是因为需求变更中原程序圈复杂度高而衍生的错误。
2024年,跨进21世纪已经两个轮回,这些计算机技术基础问题似乎并没有因为软件工程和计算机相关专业的发展,而有所改善。需求在各个域中表现千差万别,问题在各处代码中也似乎毫无规律,本文说代码之美是希望大家认识代码的美,化繁为简,创造出美好的产品。
代码之美有很多方面,可以谈高级编程语言以及各语言的框架/类库,也可以聊算法和数据结构,还可以谈操作系统内核或是层出不穷的中间件,不过这里我们看最不起眼的代码整洁之道。
|
|
 |
|---|
从上面两个建筑的对比可以看出:系统整洁度与系统规模非强相关,一切从心开始。
二、整洁之道
说起代码整洁之道,不得不提到人称Bob大叔的Robert C. Martin,以及他写的《Clean Code》一书。

《Clean Code》告诉我们,糟糕的代码也能运行,但如果代码不整洁会使整个团队深陷泥潭,让系统危如累卵,让每一次修改都如履薄冰,每年耗费难以计数的时间、资源和士气。然而这一切并非不可避免。
2.1 什么是整洁代码?
可能有人觉得谈代码太基础,有点low,不够高大上,应该谈谈设计、模型、算法,亦或是业务域;或者也有人觉得随着AI技术发展,代码可以自动生成了;我也曾一度觉得代码包括整洁代码,对于以此为生的专业人士,应该人人已经掌握。现实的世界却是啪啪地打脸,我们的注册应用系统数量以万记,没听说一个系统的代码是靠AI自动生成,而每个月的故障汇总中都有代码引起的问题,要解决这些基础问题,还是要从基础说起。
《Clean Code》中引用了数位知名程序员的话,Bjarne Stroustrup,C++之父提到的核心词:“优雅”、“高效”、“只做好一件事”。《面向对象分析与设计》的作者Grady Booch比喻“整洁的代码如同优美的散文”,《修改代码的艺术》的作者Michael Feathers指出整洁代码的关键在于代码作者在意代码。
整洁代码我总结为以下4点:
2.2 概念对比
2.2.1 整洁代码vs.设计模式
整洁代码是为了代码可读性,让代码的读者易于理解和维护代码;设计模式是为了系统具有良好的可扩展性。当然他们之间也有联系,如果你能够恰当的运用设计模式,可以提高系统代码的可读性,降低了系统复杂度。但如果你过度设计,为功能相对简单的应用抽象出一堆接口、工厂、策略、代理,反而增加了应用复杂度。所以整洁代码和设计模式是两个不同维度的概念,有关联但侧重点不同。
2.2.2 整洁代码vs.整洁架构
整洁代码关注的是代码层面的整洁,整洁架构关注的是设计层面的整洁,设计反映在代码逻辑应该写在哪个服务或者模块更为合理,服务之间的接口如何定义可以减少服务间的依赖。所以整洁代码和整洁架构有相似之处,但关注的粒度完全不同。
2.2.3 整洁代码vs.快速代码
理想情况下,一个新项目,从开始你就可以写下完美的整洁代码,但现实中你的编程水平在进步,项目的需求在变更,你需要不断地质疑并重构已有的代码。项目中的整洁代码往往不是一个完美的不变的代码,而是一个不断调整的精进的代码。
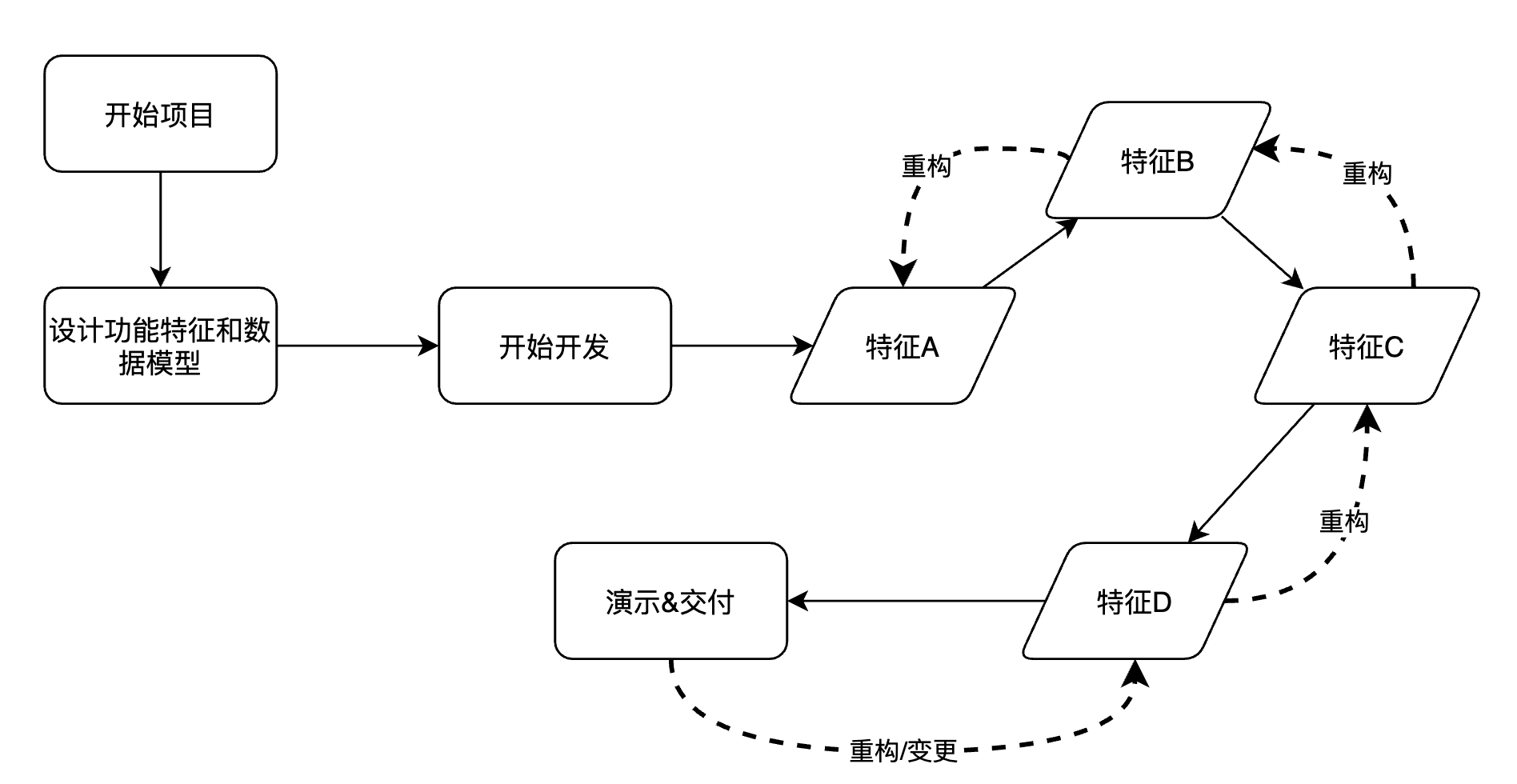
项目开发过程中,重构是一个非常正常的事情,如果你可以做到不断质疑和改进代码,你才可以在系统演进的过程中保持代码的整洁,保持系统的可维护性,加快明天的速度。
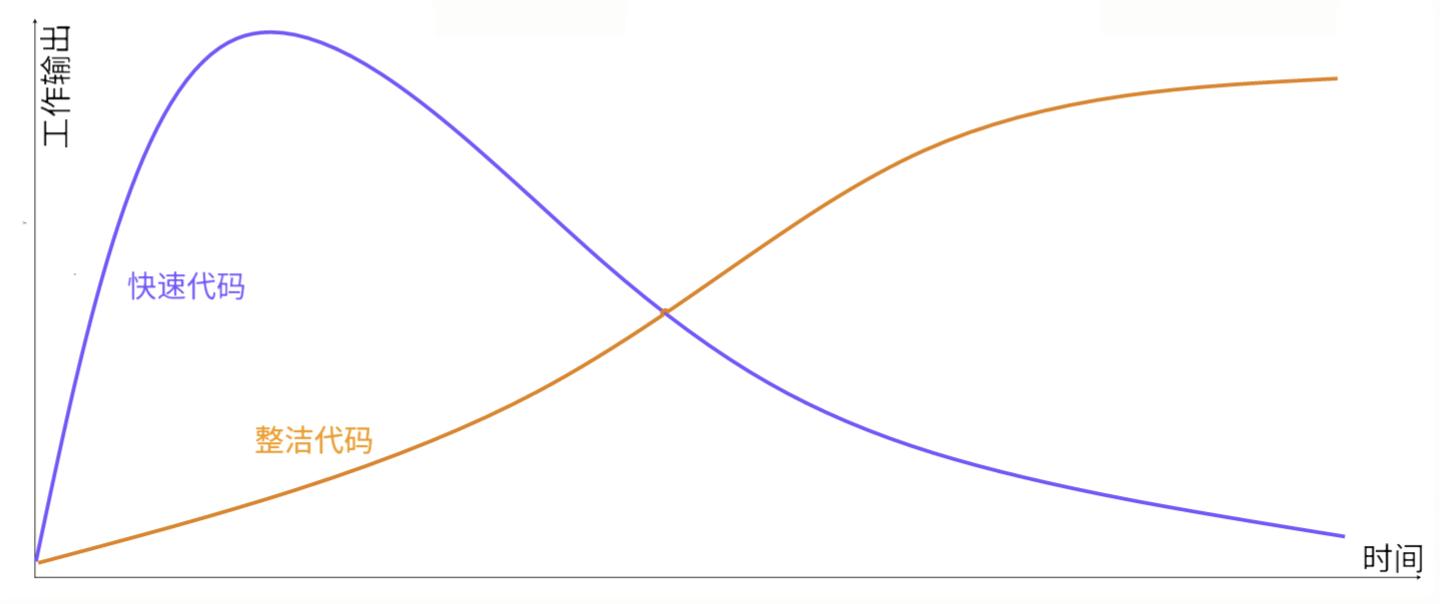
相对而已,如果你从项目开始,只是快速的开发功能,输出大量的代码和功能特性。但随着时间的推移,代码库成为一种负担,不论是bugfix还是新增特性开发都变得异常困难,最终不得不在某个时候新建一个下一代系统来替代它。这不是臆测,下图是业界的研究分析,我也在几家企业中见证了数个大型系统的轮回,其中几家欢喜几家愁,对于组织系统的不断推倒重建无疑是个巨大的损失。
2.3 如何实现整洁代码?
要实现整洁代码,手段有多种,可以是前面提到的设计模式的运用、代码的重构,也可以通过集体code review来发现代码中的bad smell,团队的代码规范、检查工具等。这里将整洁代码中的关键点列举出来,你可以在写代码或重构时加以关注。
代码真正 “读” 的成分比 “写” 多得多,读与写花费时间的比例超过 10:1。写新代码时,我们一直在读旧代码,所以我们要让读的过程变得轻松,即便这会对写代码提出更高的要求。
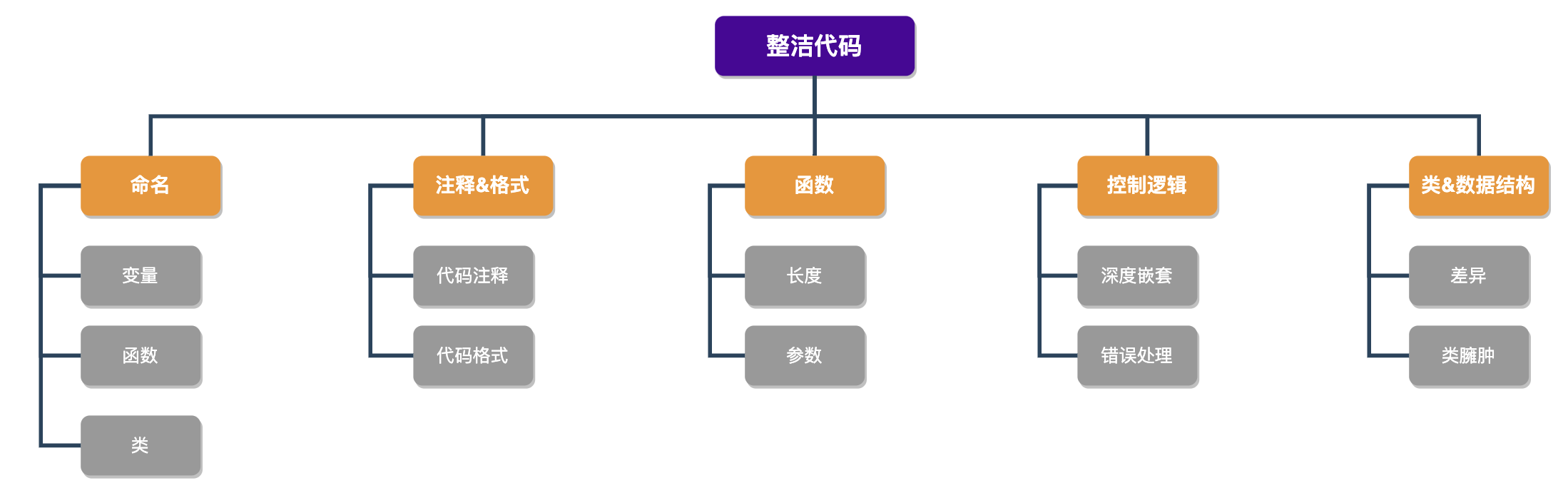
代码格式在本文不再赘述,Java代码可以参考《Java代码之美,从遵循样式规范开始》,c++代码可以使用clang-format,go代码可以使用gofmt,团队只需要选择统一的规范配置即可。
2.3.1 命名
软件应用中命名随处可见,我们给变量、函数、类命名,我们给代码文件、目录、模块、应用服务命名,这里范围且限定在代码里面的变量、函数、类命名,对于其它命名规则和道理是相通的。
命名是如此常见,常常被技术人所轻视,认为命名没有什么技术含量。我的态度恰恰相反,命名是如此的重要,可以说是整洁代码的基石。code review中能看到有意义的命名,不论是类、函数还是变量,都会让我对这段代码信任度提高,对代码开发者也有很好的印象。通常能把命名这种基本功做好的人,逻辑的全面性一般不会差,质量就有了保障。
命名有意义
看左侧的这段代码,它可能是任何对象,做了一个不知道什么操作的处理动作。再看右侧的代码段,即使没有任何注释,也能明白用户保存操作。
| 一段有逻辑没有意义的代码const us = new MainEntity(); us.process();if (login) {// ... } | 一段自描述有意义的代码const user = new User(); user.save();if (isLoggedIn) {// ... } |
|---|
命名基本规则
| 分类 | 简短定义 | 命名规则 | 示例 |
|---|---|---|---|
| 变量 | 数据存储的容器 | 使用名词或有限定词的短语 | const userData = {...} bool isValid = ... |
| 函数/方法 | 完成某项特定功能 | 使用动词或动宾结构的短语 | sendData() inputIsValid() |
| 类 | 一类事物的抽象描述,用来创建对象 | 使用名词或名词短语 | class User {...} class RequestMessage {...} |
变量命名
| 存储的数据描述 | 糟糕的命名 | 可接受的命名 | 好的命名 |
|---|---|---|---|
| 一个用户对象 | u data | userData person | user customer |
| 没有意义,"u"或"data"可以存储任何数据 | "userData"有点啰嗦,"person"指向不明确 | "user"是自描述的 "customer"指向明确 | |
| 检查用户输入是否有效(boolean) | v val | correct validatedInput | isCorrect isValid |
| "v"可能表达任何数据,"val"可能是value的缩写 | 这两个不能表示boolean值(true/false) | 自描述的,且数据类型清晰 |
函数命名
| 功能描述 | 糟糕的命名 | 可接受的命名 | 好的命名 |
|---|---|---|---|
| 保存用户数据到数据库 | process(...) handle(...) | save(...) storeData(...) | saveUser(...) user.store(...) |
| 两个都没有含义,没有回答对什么东西做了什么处理 | 执行动作是存储,但什么东西被存储没有明确 | 从命名看到明确的意图 | |
| 检查用户的输入 | process(...) save(...) | validateSave(...) check(...) | validate(...) isValid(...) |
| "process"动作不明确 "save"有误导性 | 两个都不太明确 | 两个都有明确意义的,可根据情况选择 |
类命名
| 事物描述 | 糟糕的命名 | 可接受的命名 | 好的命名 |
|---|---|---|---|
| 一个用户 | class UEntity class ObjA | class UserObj class AppUser | class User class Admin |
| 两个都没有含义 | 两个都有冗余信息 | "User"中规中矩 "Admin"用户类型更为明确 | |
| 一个数据库 | class Data class DataStorage | class Db class Data | class Database class SQLDatabase |
| 两个都指代不明确 | 不够具体,缩写易有歧义 | 数据库指代明确,"SQLDatabase"限定类型更好 |
命名大忌
代码的变量、函数、类的命名有几大忌讳:
| 忌讳 | 示例 | 建议命名 | 说明 |
|---|---|---|---|
| 中文拼音缩写 | long hlUserId; | long goldProcessUserId; | 黄流缩写为hl,在没有注释的情况让阅读者抓狂 |
| 俚语 | item.gotoDie() | item.delete() | 国内用英语俚语的少 |
| 不明确的英文缩写 | ymdt = '20241218CST' | dateWithTZ='20241218CST' | 可以接受的缩写,如:ts(timestamp) |
| 误导性名字 | userList = {u1: ..., u2: ...} uniqueNames = {a, b, b, ... } | userMap = {u1: ..., u2: ...} nameList = {a, b, b, ... } | 误导性名字会被其他开发者误用 |
2.3.2 注释
如果你的代码本身就是自描述的,让阅读者可以清晰地识别代码意图,注释是不必要的。注释是为了弥补代码表达意图的失败,如果有能力尽量把你的代码收拾的整洁点,其次才是使用注释来解释。
糟糕的注释比代码还让人困惑,因为注释存在的时间越久,会越偏离代码的本意,因为程序员在修改代码时很少维护注释。
坏注释
注释和代码表示的是一个意思,且代码已经足够自描述,这时的注释是多余的

使用大段的块注释作为分隔标记,全局变量、类这些关键字就足够标记,这些注释也是多余的

注释和代码的意思不一致,明明是插入一条数据,注释偏偏写成更新

将代码块注释掉,担心有朝一日这块还会再次被使用。其实不论哪种代码仓库(git、svn...)都可以保证代码的修改历史,注释掉的代码块无形中给代码阅读者带来认知负担。

好注释
上面是对正则表达式的解释,并给出正则匹配的示例,这对不熟悉正则的人非常友好。下面的例子是一个警示信息,提醒方法适用的工作环境,补充代码难以表达的信息。

2.3.3 函数
在《Clean Code》中,Bob说了十多项原则,我这里只提两点:函数长度和函数参数。
函数长度
基本原则:函数应该短小。Bob无法证实小函数更好的研究成果,我也不能给出一个科学的解释。回到整洁代码的问题上,短小的函数可读性更强,一个函数只负责一件事,在阅读时不需要背负过多的上下文信息,读代码时心情更轻松愉快,维护修改代码时也不容易犯错。
一个函数应该做一件事,做好这件事,只做这一件事。
"这个函数只做一件事,但这件事逻辑比较复杂,有很多步骤,要把这件事做完整就会写很长。"解决这个问题,就需要对函数内部操作分层抽象,函数内只写这一层的操作。
就如经典笑话"要把大象装冰箱,总共分几步?三步,第一步,把冰箱门打开;第二步,把大象装进去;第三部,把冰箱门盖上。"这里三个步骤就是很好的抽象,它也适用于把长颈鹿装冰箱,把骆驼装冰箱。而测量大象大小、检查冰箱大小是否足够,就不是这个问题下的三个步骤同层抽象。
下面再看一个javascript的函数示例,这个函数只做了一件事,但看上去还是有点杂乱。因为它把内容检查、渲染内容构建和最后的渲染动作一一平铺上这个函数内。
function renderContent(renderInformation) {const element = renderInformation.element;if (element === 'script' || element === 'SCRIPT') {throw new Error('Invalid element.');}let partialOpeningTag = '<' + element;const attributes = renderInformation.attributes;for (const attribute of attributes) {partialOpeningTag = partialOpeningTag + ' ' + attribute.name + '="' + attribute.value + '"';}const openingTag = partialOpeningTag + '>';const closingTag = '</' + element + '>'