ThreadLocal原理与使用详解
一、ThreadLocal 介绍
1.1 定义与核心特性
- 定义:Java 官方文档描述,ThreadLocal 类用于提供线程内部的局部变量,多线程环境下通过
get()和set()方法访问时,能保证各线程变量相对独立于其他线程变量,实例通常为private static类型,用于关联线程与线程上下文。 - 核心特性:
- 线程安全:在多线程并发场景下,确保线程访问变量时无数据安全问题。
- 传递数据:同一线程内,不同组件可通过 ThreadLocal 共享公共变量,避免参数直接传递导致的代码耦合。
- 线程隔离:每个线程拥有独立的变量副本,线程间变量互不干扰。
1.2 基本使用
1.2.1 常用方法
| 方法声明 | 描述 |
|---|---|
ThreadLocal() |
创建 ThreadLocal 对象 |
public void set(T value) |
设置当前线程绑定的局部变量 |
public T get() |
获取当前线程绑定的局部变量 |
public void remove() |
移除当前线程绑定的局部变量 |
1.2.2 案例对比
- 未使用 ThreadLocal:多线程访问同一变量时,数据混乱(如 “线程 0” 输出 “线程 1 的数据”),无法实现线程隔离。
- 使用 ThreadLocal:通过
private static ThreadLocal<String> threadLocal = new ThreadLocal<>()定义变量,线程调用set()设值、get()取值后,每个线程仅能获取自身绑定的数据(如 “线程 0” 输出 “线程 0 的数据”),完美解决隔离问题。
1.3 与 synchronized 的区别
| 对比维度 | synchronized | ThreadLocal |
|---|---|---|
| 原理 | 采用 “以时间换空间” 方式,仅提供 1 份变量,让线程排队访问 | 采用 “以空间换时间” 方式,为每个线程提供 1 份变量副本,支持同时访问且无干扰 |
| 侧重点 | 解决多个线程之间访问资源的同步问题 | 解决多线程中各线程数据相互隔离的问题 |
- 说明:两者均可处理并发问题,但 ThreadLocal 能提升程序并发性,更适用于需线程隔离的场景。
1.4 优势与应用
- 优势:
- 传递数据:保存线程绑定数据,需用时直接获取,降低代码耦合。
- 线程隔离:保障线程数据独立的同时具备并发性,避免同步方式的性能损失。
- Spring 事务应用:Spring 从数据库连接池获取
Connection后,将其存入 ThreadLocal 与线程绑定;事务提交 / 回滚时,直接从 ThreadLocal 中获取Connection操作。该设计解决了三层架构中,Service 调用多个 DAO 时无法共享连接、难以控制事务边界的问题,避免了显式传递Connection的麻烦。
二、ThreadLocal 内部结构
2.1 常见误解
早期 ThreadLocal 设计为:每个 ThreadLocal 维护一个 Map,以线程为 key、变量为 value;但当前 JDK(如 JDK8)已优化,设计相反。
2.2 现设计方案
- 每个
Thread内部维护一个ThreadLocalMap对象。 ThreadLocalMap的 key 是 ThreadLocal 实例本身,value 是线程需存储的变量副本。ThreadLocalMap由 ThreadLocal 负责维护,ThreadLocal 提供set()/get()等方法操作 Map 中的数据。- 不同线程访问时,仅能获取自身 ThreadLocalMap 中的副本,实现隔离。
2.3 设计优势
- 减少 Entry 数量:Entry 数量由 ThreadLocal 数量决定(通常少于 Thread 数量),相比早期设计更节省空间。
- 降低内存占用:Thread 销毁时,其对应的
ThreadLocalMap也会随之销毁,避免无用内存占用。
三、ThreadLocal 核心方法源码
3.1 set () 方法
public void set(T value) {Thread t = Thread.currentThread();ThreadLocalMap map = getMap(t);if (map != null)map.set(this, value);elsecreateMap(t, value);
}
3.1.1 源码逻辑
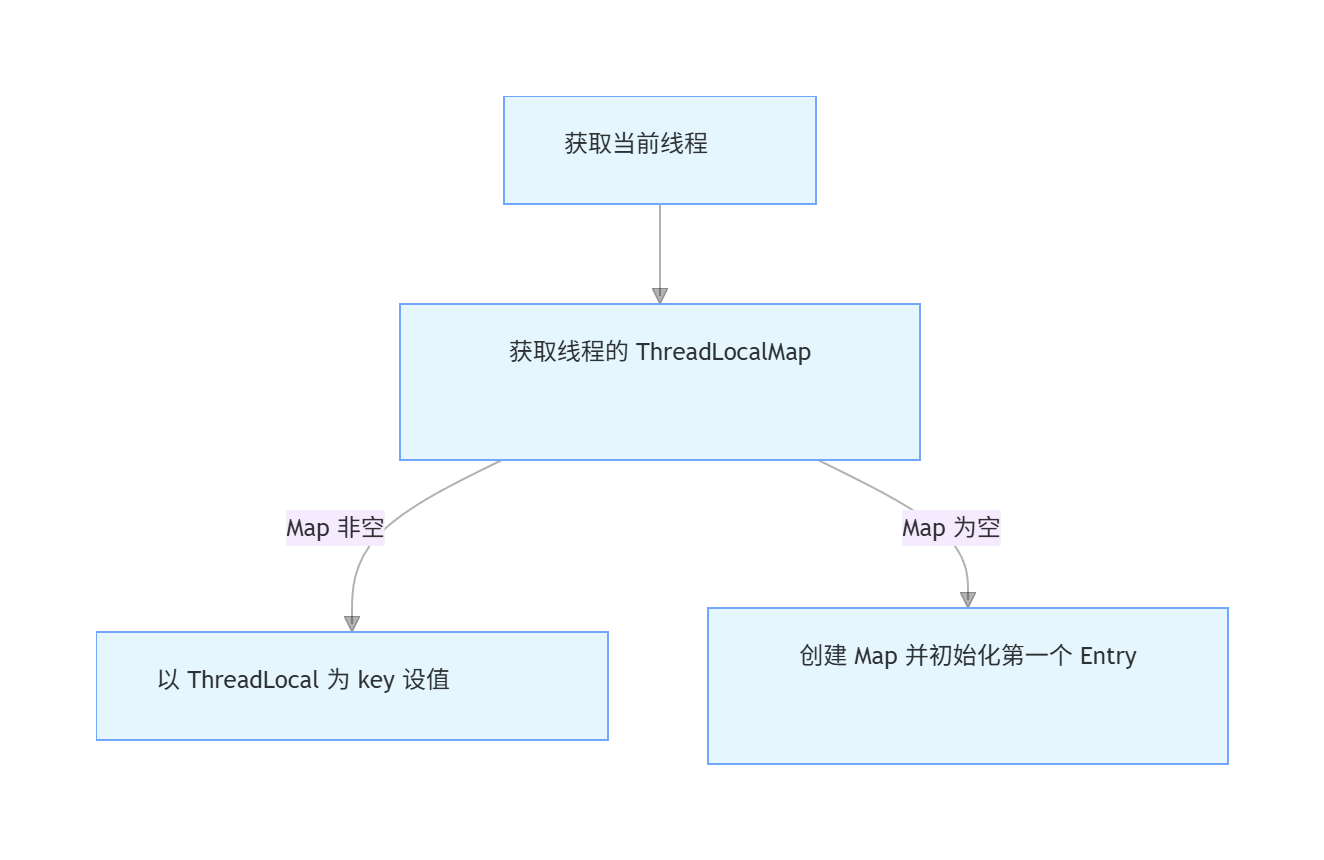
- 获取当前线程:
Thread t = Thread.currentThread()。 - 获取线程的
ThreadLocalMap:ThreadLocalMap map = getMap(t)(getMap()返回线程的threadLocals属性)。 - 若 Map 不为 null:调用
map.set(this, value),以当前 ThreadLocal 为 key 设值。 - 若 Map 为 null:调用
createMap(t, value)创建 Map,将当前线程和初始值作为第一个 Entry 存入。
3.1.2 执行流程
3.2 get () 方法
3.2.1 源码逻辑
- 获取当前线程及对应的
ThreadLocalMap。 - 若 Map 不为 null:以当前 ThreadLocal 为 key 获取 Entry(
ThreadLocalMap.Entry e = map.getEntry(this)),若 Entry 非空则返回e.value。 - 若 Map 为空或 Entry 为空:调用
setInitialValue()初始化(调用initialValue()获取初始值,创建 Map 并设值),返回初始值。
3.2.2 关键说明
initialValue()是延迟调用方法,仅在未调用set()却调用get()时执行,且每个线程仅执行 1 次,默认返回 null,可重写以设置非 null 初始值。
3.3 remove () 方法
- 获取当前线程的
ThreadLocalMap。 - 若 Map 不为 null:调用
map.remove(this),移除当前 ThreadLocal 对应的 Entry。
3.4 initialValue () 方法
- 作用:返回线程局部变量的初始值。
- 特性:
- 延迟调用,仅在特定场景(未
set()先get())执行 1 次。 - 默认返回 null,需通过子类继承或匿名内部类重写以实现自定义初始值。
- 延迟调用,仅在特定场景(未
四、ThreadLocalMap 源码分析
4.1 基本结构
4.1.1 类属性
ThreadLocalMap 是 ThreadLocal 的内部类,未实现 Map 接口,核心成员变量如下:
| 成员变量 | 描述 | 关键值 / 要求 |
|---|---|---|
INITIAL_CAPACITY |
初始容量 | 16,必须是 2 的整次幂 |
table |
存储数据的数组 | 类型为 Entry[],长度需为 2 的整次幂 |
size |
数组中 Entry 的个数 | - |
threshold |
扩容阈值 | 默认为容量的 2/3,超过则扩容 |
4.1.2 Entry 结构
- 定义:
static class Entry extends WeakReference<ThreadLocal<?>>,key 为 ThreadLocal 实例(弱引用),value 为线程变量值。 - 目的:key 设计为弱引用,是为了将 ThreadLocal 生命周期与线程生命周期解绑,降低内存泄漏风险。
4.2 弱引用与内存泄漏
4.2.1 核心概念
- 内存溢出(Memory Overflow):无足够内存供程序使用。
- 内存泄漏(Memory Leak):堆内存中存在GC无法回收的对象,导致内存浪费。
- 强引用:普通对象引用,只要存在强引用,GC 不回收对象。
- 弱引用:GC 发现仅存在弱引用的对象时,无论内存是否充足,都会回收该对象。
4.2.2 内存泄漏原因分析
| key 引用类型假设 | 问题场景 | 泄漏风险 |
|---|---|---|
| 强引用 | ThreadLocal 被回收后,Entry 因强引用 key 无法回收,且线程未销毁时,threadRef->currentThread->threadLocalMap->entry 强引用链存在,导致 Entry 泄漏 |
无法避免 |
| 弱引用 | ThreadLocal 被回收后,key 变为 null,但线程未销毁且未调用 remove() 时,threadRef->currentThread->threadLocalMap->entry->value 强引用链存在,导致 value 泄漏 |
可通过后续操作(set/get/remove)降低 |
-
根源:
ThreadLocalMap生命周期与 Thread 一致,若未手动调用remove()且 Thread 未销毁,value 或 Entry 会一直占用内存,导致泄漏。在线程池中,thread长时间存活,一定要remove不然就会内存泄漏
-
弱引用优势:key 被回收后,下次调用 ThreadLocal 的
set()/get()/remove()方法时,会清理 key 为 null 的 Entry,释放 value 内存,降低泄漏风险。
static class Entry extends WeakReference<ThreadLocal<?>> {/** The value associated with this ThreadLocal. */Object value;Entry(ThreadLocal<?> k, Object v) {super(k);value = v;}
}
从Entry构造方法看出,他调用了父类构造方法将key包装为弱引用,而value则是一个强引用
4.3 哈希冲突解决
- 解决方式:线性探测法。
- 具体逻辑:
- 计算索引:通过
key.threadLocalHashCode & (len-1)计算 Entry 在table中的索引(len为table长度,该算法等价于hashCode % len,更高效,要求len为 2 的整次幂)。 - 探测过程:若索引位置 Entry 已存在且 key 不匹配,则按
nextIndex(i, len)(i+1,超过长度则回到 0)依次探测下一个位置,直到找到空位置插入或发现 key 为 null 的陈旧 Entry(调用replaceStaleEntry()替换并清理)。
- 计算索引:通过
- 哈希码优化:ThreadLocal 的
threadLocalHashCode通过AtomicInteger累加HASH_INCREMENT(0x61c88647,斐波那契数列相关值)生成,确保哈希码均匀分布,减少冲突。
关键问题
问题 1:ThreadLocal 实现线程隔离的核心原理是什么?与 synchronized 处理并发的思路有何本质区别?
答案:
- ThreadLocal 线程隔离原理:每个
Thread内部维护一个ThreadLocalMap,该 Map 以 ThreadLocal 实例为 key、线程需存储的变量为 value;当线程调用 ThreadLocal 的set()方法时,会将变量存入当前线程的ThreadLocalMap,调用get()方法时仅从自身的ThreadLocalMap中取值;由于每个线程的ThreadLocalMap独立存在,因此实现了变量的线程隔离。 - 与 synchronized 的本质区别:
- 资源占用方式:synchronized 采用 “以时间换空间” 思路,仅维护 1 份变量,通过让线程排队获取锁实现同步,牺牲并发效率换取空间节省;
- ThreadLocal 采用 “以空间换时间” 思路,为每个线程创建 1 份变量副本,线程无需等待可直接访问自身副本,牺牲空间换取更高的并发性;
- 核心目标:synchronized 侧重解决 “多线程访问同一资源的同步问题”,ThreadLocal 侧重解决 “多线程间数据的隔离问题”。
问题 2:ThreadLocal 为何会发生内存泄漏?key 设计为弱引用能完全解决内存泄漏问题吗?如何避免内存泄漏?
答案:
- 内存泄漏原因:ThreadLocal 内存泄漏的根源是 ThreadLocalMap 的生命周期与 Thread 一致:若线程未销毁(如线程池中的核心线程),且未手动调用 ThreadLocal 的
remove()方法清除对应 Entry,Entry 中的 value 会一直被threadRef->currentThread->threadLocalMap->entry强引用链持有,无法被 GC 回收,最终导致内存泄漏。 - 弱引用 key 不能完全解决问题:key 设计为弱引用仅能保证 ThreadLocal 实例被回收后,key 会变为 null(避免 ThreadLocal 实例本身泄漏);但 value 仍会被 Entry 强引用,若未清理该 Entry 且线程未销毁,value 依然会泄漏。不过弱引用可提供一层保障:后续调用 ThreadLocal 的
set()/get()/remove()方法时,会自动清理 key 为 null 的 Entry,释放 value 内存。 - 避免内存泄漏的方式:
- 手动调用
remove():在使用完 ThreadLocal 后(如方法结束、请求处理完成时),主动调用threadLocal.remove()清除当前线程的 Entry,切断 value 的强引用链; - 控制线程生命周期:确保使用 ThreadLocal 的线程在任务结束后能正常销毁(如非线程池场景),使
ThreadLocalMap随线程一同被回收。
- 手动调用
问题 3:ThreadLocalMap 如何解决哈希冲突?其哈希码生成方式有何特殊之处?
答案:
- 哈希冲突解决方式:ThreadLocalMap 采用 线性探测法 解决哈希冲突,具体流程如下:
- 计算初始索引:通过
key.threadLocalHashCode & (len-1)计算 Entry 在table中的初始索引(len为table长度,需为 2 的整次幂,该算法等价于取模运算,更高效); - 探测插入位置:若初始索引位置的 Entry 已存在且 key 与当前 key 不匹配,则调用
nextIndex(i, len)计算下一个索引(i+1,若超过table长度则回到 0,形成环形数组); - 处理特殊情况:若探测过程中发现 key 为 null 的陈旧 Entry,会调用
replaceStaleEntry()替换该 Entry 并清理其他陈旧 Entry;若找到空位置,则直接插入新 Entry。
- 计算初始索引:通过
- 哈希码生成特殊之处:ThreadLocal 的
threadLocalHashCode生成依赖两个关键组件:- 原子类计数:通过
private static AtomicInteger nextHashCode保证多线程环境下哈希码生成的线程安全; - 黄金分割增量:每次生成哈希码时,通过
nextHashCode.getAndAdd(HASH_INCREMENT)累加HASH_INCREMENT(值为0x61c88647,与斐波那契数列相关,接近黄金分割比例);该增量能确保哈希码在table(长度为 2 的整次幂)中均匀分布,大幅降低哈希冲突的概率。
- 原子类计数:通过
代码实现:定义 3 个 ThreadLocal 实例
单个线程内ThreadLocalMap存在多个ThreadLocal(Entry)实例的场景模型
通常项目中会把 ThreadLocal 封装成工具类,避免散落在业务代码中,示例如下:
/*** 线程局部变量工具类:存储当前线程需要共享的多类变量*/
public class ThreadLocalUtils {// 1. 存储“用户身份信息”的 ThreadLocal 实例(类型:UserInfo)private static final ThreadLocal<UserInfo> USER_INFO_THREAD_LOCAL = new ThreadLocal<>();// 2. 存储“数据库事务连接”的 ThreadLocal 实例(类型:Connection)private static final ThreadLocal<Connection> DB_CONN_THREAD_LOCAL = new ThreadLocal<>();// 3. 存储“请求追踪ID”的 ThreadLocal 实例(类型:String)private static final ThreadLocal<String> TRACE_ID_THREAD_LOCAL = new ThreadLocal<>();// ------------------- 用户信息相关方法 -------------------public static void setUserInfo(UserInfo userInfo) {USER_INFO_THREAD_LOCAL.set(userInfo);}public static UserInfo getUserInfo() {return USER_INFO_THREAD_LOCAL.get();}public static void removeUserInfo() {USER_INFO_THREAD_LOCAL.remove();}// ------------------- 数据库连接相关方法 -------------------public static void setDbConn(Connection conn) {DB_CONN_THREAD_LOCAL.set(conn);}public static Connection getDbConn() {return DB_CONN_THREAD_LOCAL.get();}public static void removeDbConn() {DB_CONN_THREAD_LOCAL.remove();}// ------------------- 请求追踪ID相关方法 -------------------public static void setTraceId(String traceId) {TRACE_ID_THREAD_LOCAL.set(traceId);}public static String getTraceId() {return TRACE_ID_THREAD_LOCAL.get();}public static void removeTraceId() {TRACE_ID_THREAD_LOCAL.remove();}// 防止外部实例化private ThreadLocalUtils() {}
}
三层架构中如何使用这 3 个 ThreadLocal 实例
1. Controller 层:初始化变量并存入 ThreadLocal
Controller 接收请求后,先解析请求中的 Token、生成 TraceId,然后把这些变量存入对应的 ThreadLocal:
@RestController
@RequestMapping("/order")
public class OrderController {@Autowiredprivate OrderService orderService;@Autowiredprivate UserService userService;@Autowiredprivate ConnectionPool connectionPool;@PostMapping("/create")public Result createOrder(@RequestHeader("Token") String token) {// 1. 生成请求追踪ID,存入 ThreadLocalString traceId = UUID.randomUUID().toString();ThreadLocalUtils.setTraceId(traceId);log.info("【Controller】接收下单请求,TraceId:{}", ThreadLocalUtils.getTraceId());// 2. 解析Token获取用户信息,存入 ThreadLocalUserInfo userInfo = userService.parseToken(token);ThreadLocalUtils.setUserInfo(userInfo);log.info("【Controller】当前用户:{},TraceId:{}", ThreadLocalUtils.getUserInfo().getUserName(), ThreadLocalUtils.getTraceId());// 3. 从连接池获取数据库连接(用于事务),存入 ThreadLocalConnection conn = connectionPool.getConnection();ThreadLocalUtils.setDbConn(conn);try {// 4. 调用Service层处理业务(无需传UserInfo、Conn、TraceId,Service可直接从ThreadLocal取)orderService.createOrder();return Result.success("下单成功");} catch (Exception e) {log.error("【Controller】下单失败,TraceId:{}", ThreadLocalUtils.getTraceId(), e);return Result.fail("下单失败");} finally {// 5. 请求结束,清理ThreadLocal(避免内存泄漏)ThreadLocalUtils.removeUserInfo();ThreadLocalUtils.removeDbConn();ThreadLocalUtils.removeTraceId();}}
}
2. Service 层:直接从 ThreadLocal 获取变量
Service 层不需要 Controller 传参,直接通过 ThreadLocalUtils 取到 UserInfo、Connection、TraceId,处理业务逻辑:
@Service
public class OrderService {@Autowiredprivate OrderDAO orderDAO;public void createOrder() {// 1. 直接从ThreadLocal获取TraceId,用于日志串联log.info("【Service】开始处理下单业务,TraceId:{}", ThreadLocalUtils.getTraceId());// 2. 直接从ThreadLocal获取用户信息,判断权限UserInfo userInfo = ThreadLocalUtils.getUserInfo();if (!"VIP".equals(userInfo.getUserType())) {throw new RuntimeException("非VIP用户无法下单");}log.info("【Service】当前用户类型:{},权限校验通过,TraceId:{}", userInfo.getUserType(), ThreadLocalUtils.getTraceId());// 3. 直接从ThreadLocal获取数据库连接,开启事务Connection conn = ThreadLocalUtils.getDbConn();try {conn.setAutoCommit(false); // 关闭自动提交,开启事务// 调用DAO层执行SQL(无需传Conn,DAO可直接从ThreadLocal取)orderDAO.insertOrder(userInfo.getUserId());conn.commit(); // 提交事务} catch (SQLException e) {try {conn.rollback(); // 回滚事务} catch (SQLException ex) {ex.printStackTrace();}throw new RuntimeException("下单失败");}}
}
3. DAO 层:直接从 ThreadLocal 获取连接执行 SQL
DAO 层不需要 Service 传 Connection,直接从 ThreadLocal 取,执行数据库操作:
@Repository
public class OrderDAO {public void insertOrder(Long userId) throws SQLException {// 1. 直接从ThreadLocal获取数据库连接Connection conn = ThreadLocalUtils.getDbConn();// 2. 直接从ThreadLocal获取TraceId,用于日志log.info("【DAO】执行插入订单SQL,用户ID:{},TraceId:{}", userId, ThreadLocalUtils.getTraceId());// 执行SQL(用ThreadLocal中的Connection,保证和Service层是同一个连接,事务生效)String sql = "INSERT INTO `order` (user_id, create_time) VALUES (?, NOW())";PreparedStatement pstmt = conn.prepareStatement(sql);pstmt.setLong(1, userId);pstmt.executeUpdate();}
}
项目中需要多个 ThreadLocal 实例的核心场景是:线程需要同时存储 “多类不同类型、不同用途” 的局部变量。就像上面的例子,用户信息、数据库连接、请求 TraceId 是三类完全不同的变量,必须用三个独立的 ThreadLocal 实例分别绑定,才能实现 “类型安全、低耦合、线程隔离” 的效果。
这也解释了为什么 Spring 框架中会有多个 ThreadLocal 实例 —— 比如存储事务连接的 TransactionSynchronizationManager(内部用多个 ThreadLocal 存储连接、事务状态等),本质就是因为需要同时管理多类线程局部变量。