最近一直没能抽出时间总结于是半年总结一直拖拖拖,距离上次半年复盘已过了九个月,这九个月发生了很多:
- 职业发展上经历了 idea 、实现、回片测试完整走完第一个加速器流片工作,切身体会了流片的血与泪;
- 第一次离开象牙塔经历数个月正式实习,公司架构、工作环境概念具象化,并且幸运地遇到一批可爱的同事,这段经历在未来就业时想必会反复想起回味;
- 学术上终于走完真正第一轮完整的科研周期,并开启 PhD 生涯。
不知不觉已经是第四篇半年总结[1][2][3],意味着自大三开始已经 cos 科研人员两个年头了,钻得弥深,愈发感觉知识的浅薄,于此向各位朋友分享汇报这段对行业方向、科研、人生不成熟的新想法,欢迎交流指教!
什么时候该按下“硬件”核按钮?
上一次总结 [3:1] 感慨工程科学和纯理论的不同,工程需要制造东西,不仅仅要东西足够好,还要计划可行能够制造出来,半导体的高成本投入更是加剧了天平的倾斜。领导曾经对我说:“要对流片持有敬畏之心。” 半导体就像核按钮,一旦按下就要“见血” —— 白花花的银子。而很多时候不同的技术路线其实是矛盾竞争关系,而社会又倾向于将资源投入 ROI 最高的地方,什么时候要用硬件这个牛刀?什么样的新型需求会驱动社会倾向投资新型硬件形态,而非其他技术路线? 我也没有确定的答案,但不妨将一些抉择、历史列举如下抛砖引玉。
新硬件的竞争对手自然包括传统硬件,mackler [4] 中提到“裁判”和“运动员”的比喻十分生动形象体现半导体行业巨大垄断特性以及行业惯性,这里沿用称作裁判硬件;而在 AI 这个大量资本投入,算法快速发展的领域,“新硬件-> 新算法”的反馈[5]被新算法的发展所压过,新硬件的竞争对手还包括上游算法。后文将聚焦这两个角度切入分析。
竞争裁判硬件:DSA
提及 DSA 概念,脑海中最典型的例子便是 CPU/GPU 以及 Amdahl's Law ,CPU 适合串行计算、GPU 适合并行计算,二者应用领域特性分化并且是对应市场下的幸存者,但对着成熟分化的市场分析颇有“对箭画靶”的嫌疑,即 mackler 所说的:
解决方案式的思维是目前在芯片领域竞争最常见的坑。实际上解决方案式的产品模式本身就是已经取得生态统治力的玩家收割各行各业的手段,是构建了生态统治力之后的果,而不是他们取得竞争力的因。今天有无数公司把端到端解决方案当作取得竞争力的方法论,但 NVidia 驾驭的整体解决方案是上述事实标准体系,而其他玩家自己从芯片到软件全栈打造解决方案,并期望通过软硬件整体解决方案的竞争力来构建自己的生态,属实搞错了因果。
最好例子应当拨回到早期优势并不明显的时刻,即“CPU+核显” vs "CPU+独显" 在图形市场的竞争,无论是哪种路线,都需要 both CPU and 显卡,因此将二者放在一起作为参考系比较才算公平。这两条路线分别对应将更多功能集成在一个芯片之上(通用集成),还是根据不同应用侧重构建不同的芯片,最终以异构芯片组形式处理完整任务(DSA)。
无论哪条路线,都能从历史上找出例子:
- 通用集成:南桥北桥芯片取消、SoC 芯片、苹果统一内存架构;
- DSA:独显的发展、最近比较火的将 LLM 异构需求(Prefill-Decode、Attention-FFN 乃至 MoE-FFN)硬化,比如 NVIDIA Rubin 机柜使用两种 GPU 处理 PD 分离[6]
我们先粗糙分析不同路线的代价收益。通用集成将更多功能晶体管封装在一个芯片内,避免了功能之间通讯通过代价高昂的片外带宽通信,但不同功能之间竞争晶体管面积占比,在先进芯片 die 面积已抵达最大光刻机曝光面积下更是如此,通用集成模块之间耦合可能会提高设计成本,而 DSA 的优势劣势则正好与前面所述相反。此外还有一些难以直观判断优缺的特点,比如虽然通用集成减少了单个功能片内分配的面积进而影响性能上限,但通用的适用性容易提高出货量分摊每个功能的固定成本,换取市场竞争优势。综上无论哪个路线都有劣和优,需要结合应用辩证分析,比如独显分离就是 “CPU-GPU 之间的数据同步成本” vs “GPU 内部计算的性能收益” 之间的 trade-off,一般来说需要将神经网络所有内部计算分配在 GPU 以及显存上,只把输入数据集和最终结果分配在 CPU-GPU 间数据搬运[7],如果假如 decode 阶段计算稀疏降低了 GPU 内部计算的性能收益,那是否又可以将部分网络放在 CPU 上呢?
接下来看看 AI 需求到底会带来什么样的硬件特性变更:
- 从训练/推理上细分,训练精度要求高以加速收敛(最近低精度训练工作越来越夸张,但总得说推理的所需的精度还是相对训练更低),伦次长需要更大的算力开销,反向需要更多存储存放梯度和优化器参数,进而强化存储节点和大集群互联问题侧重。
- 从云端/边缘端细分,个人感觉云端/边缘端划分实际是竞争收敛的结果而非需求侧出发,比如边缘手机处理 AI 任务可以采用云端 API 形式也可以采用本地集成 NPU 计算。那不妨假设硬件形态成立反推有什么需求,边缘端能耗限制芯片算力受限,避开网络传输延时影响某些场景抵过算力劣势可以达到更高实时性、在本地计算没有数据隐私问题。至于能效是否有优势并不好说,首先很多网络能耗不在传输请求/结果的数据而在大量的中间计算之上,并且云端有用户并发可以进一步提高能效优势,云端则需要更加弹性建设以在动态用户负载提高系统效率,比如这种情况下存储池化以及存算耦合两种路线是否会产生竞争十分有趣。
- 从视觉/NLP 出发,视觉 ViT/CNN 类模型更倾向 perfill 阶段密集计算性质,提高片内设计的侧重,而 NLP 比较火的自回归范式则更加看重片外访存。
竞争软件:Software-Hardware Co-design
软件发展和硬件发展存在步调不一致的特点,比如如下的学术加速器研发过程,来自业界的某个大厂发布了一个新开源模型,于是硬件设计者们开始准备算法进一步压缩优化并找硬件 idea 开始立项,经过漫长以年为单位的流片周期痛苦折磨,终于成功点亮芯片,但此时回头望算法已经发布了更好的模型,并且性能即使在“裁判”硬件上也比我们软硬件优化更优,最要命的是,还采用了不一样的技术,导致特化设计的 DSA 不兼容。
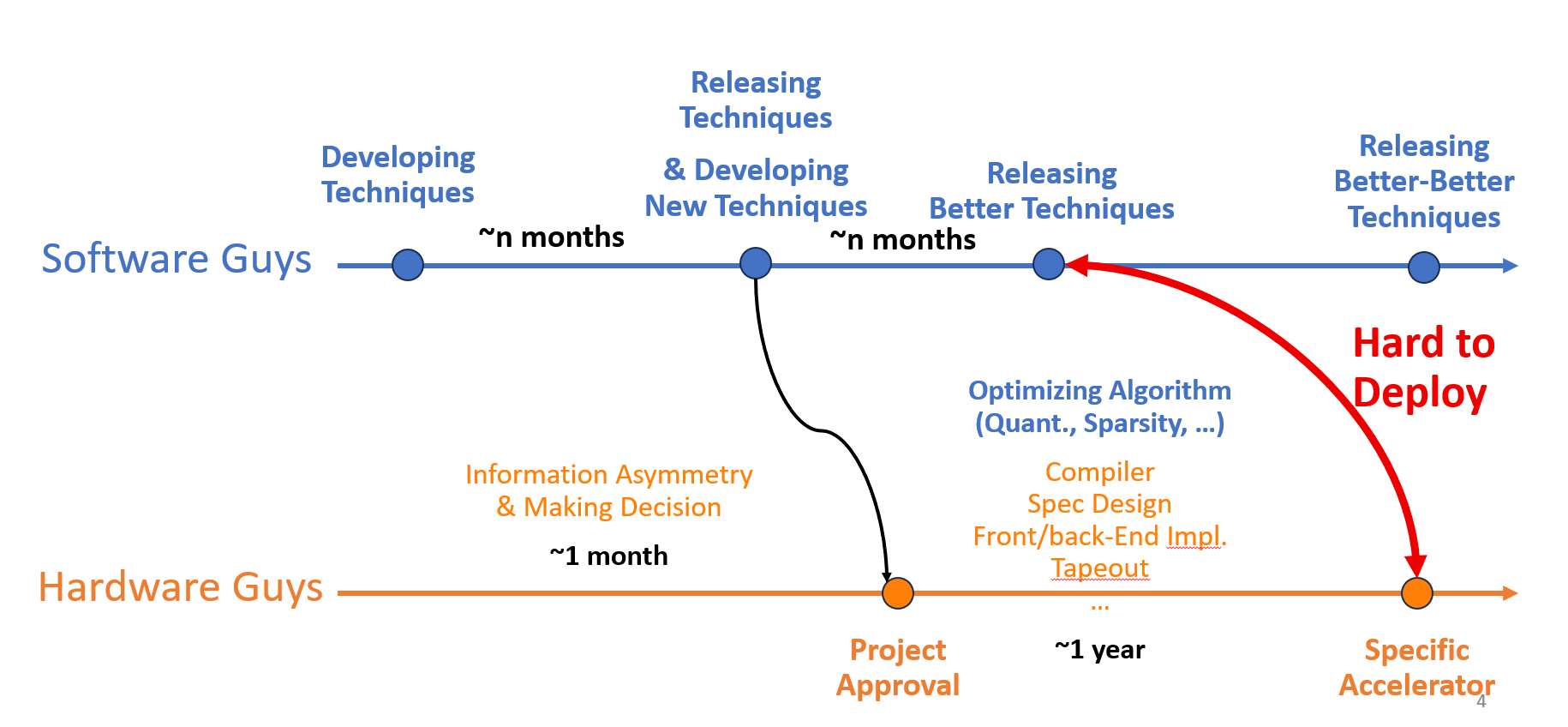
半导体超高的复杂度的研发成本匹配不上变动的算法需求,虽然现在模型研发也需要海量的计算资源投入不小,但资本对算法的投入比例更大,总体周期还是慢于研发。加之现在模型研发只有工业界顶尖大厂才能做,信息差又进一步加剧了步调的差距。本质问题是:“这个世界真的需要那么多的硬件设计投入吗?” 原本硬件+软件应当形成“合力”,甚至因为新硬件产生更好新算法的反馈,但高速发展的算法变动使得这个反馈变得缓慢而困难。
面对算法和硬件研发不匹配,之前大致有两种策略:
- 利用本身行业内的垄断地位,自然有开发者来帮我开发使用新特性,但这招只有裁判才能玩,如 NVIDIA;
- 采取保守研发策略,做通用性硬件,即 GPGPU。
架构研发实际上是以算法需求为第一性,以工艺条件为约束进行抉择。最近逐渐看到一个新玩法,算法研发者(互联网大厂)下局造芯,其有三个好处:一来本身即是客户,存在大量的需求不怕没订单,迅速克服生产的固有成本并从 GPU/NPU/各种 PU 厂商的毛利润中节省一笔;二来可以将算法-硬件当作整体看待制定发展战略,保证软硬件的兼容性形成合力;三来或许可以从源头上根据算法去除不需要的功能,高度定制化硬件降低开发复杂度加快硬件迭代周期。
架构:时间、整体的艺术
最近有两个思维深得我心:
- 复杂度不会消失,只会转移。这很符合架构 trade-off 的思维,并且有种类似“能量守恒”的美感
- 供应链/流水线思维。总成本 = 固定成本 + 数量 x 边际成本。供应链实际是边际成本向固定成本的转移,牺牲固定成本的代价换取边际成本的降低。
对于一件事情往往有两个抉择选项,一是付出劳动,以较高的边际成本以及几乎没有的固定成本;二是投资资本,远远高于前者的固定成本以及较低的边际成本。显然两个选项哪个成本更低取决于数量,存在一个平衡数量,当数量低于此时,劳动方法成本更低;数量高于此时,资本方法成本更低。对于研发,数量是某个需求出现的频次,比如对于 infra 研究而言,是靠人力写程序尽快交付产品,还是画更长时间写编译器造好处理此类问题的轮子;对于芯片产品销售,数量即是市场需求,固定成本是流片开工费用,而边际成本是单位面积晶体管流片、封装费用。
有意思的是供应链思维一旦遇上时间,随着时间各种需求变化,原本路线的平衡点可能被打破,而技术的实现存在惯性,在半导体这种制造业更是如此,原本选择较优的路线可能沦为难以承受的包袱,所以战略规划要有长视思维,进而选择即使当下可能收益并非最优,但综合长期最优可持续的路线。而复杂度只会转移,各种路线的不同可能只是在不同层次转移了复杂度,比如程序优化-编译器、编译器-硬件等等之间,而不同的技术路线在预测的未来需求变化下有着不同的成本,从 zarbot 借来一个词——“技术债务”十分恰当(原文忘记是哪篇了)。所谓做架构,即是根据某种假设演绎预测未来,并根据预测衡量不同的技术路线的技术债务,选择长期最优的一条路线。 例子可见先前 buffer 设计的文章[8]。
依此来看,架构存在两个特点:
- 架构是时间的艺术,架构的改进需要时间影响才能足够显著;
- 架构是整体的艺术,某些更优的解法可能是因为观察的领域不够全面,一年前我作过“一图概括芯片设计”的一个图[9],从 PPA (Power, Performance, Area)角度出发尝试将半导体各种特点联系起来看待,但后来仍然无法解释一些现有幸存架构的设计,后来将流片成本、软硬件开发成本囊括进来,以 PPAC (Power, Performance, Area, Cost) 角度看待,一些原来不能解释的现象自洽了。这或许可以解释 Linus Torvalds 评价 RISCV 会重蹈 ARM /x86 的覆辙,“So, it’s really hard to kind of work across this very wide gulf of things and I suspect the hardware designers, some of them have some overlap, but they will learn by doing mistakes — all the same mistakes that have been done before.”[10]一些从硬件设计角度看起来改进的功能也许会增加整体的软硬件成本。设计中一些 under-utilization 也可能是宝贵的财富,比如 GPU Tensor Core 会破坏原有的 SIMT 体系,引入额外的软硬件开发负担,但矩阵乘法占比高,其收益允许投入;而其他计算沿用 SIMT 统一结构而不是做成一些很 tricky 的 dataflow 电路,牺牲了 utilization 但是换取了研发成本的降低,在其他计算占比相对较小下牺牲可以接收。
这或许可以解释为什么硬件架构领域科研屠龙宝刀有而龙很少,一来未来难以预测,二来科研领域对成本角度的意义容易低估于其他指标(这可能也是科研的优势,后文在学术-工业界的思考详细展开)。正如前文,从现在的角度观察垄断行业优势可能掩盖架构设计的影响,观测时间应当拉回到各条路线混沌之时,learning from the history。
突破人类知识边界的代价
如果说早期学习看论文更多是培养自身知识的话,经过第一轮科研投稿,最深的收获是社区的“氛围”,别人在关心什么?别人在做什么?这个领域的问题是什么?这篇很有名的介绍 PhD 的漫画[11]现在看来还是十分精准形象:“PhD 是找到前人知识的边界,实践并将边界往前推一点点”
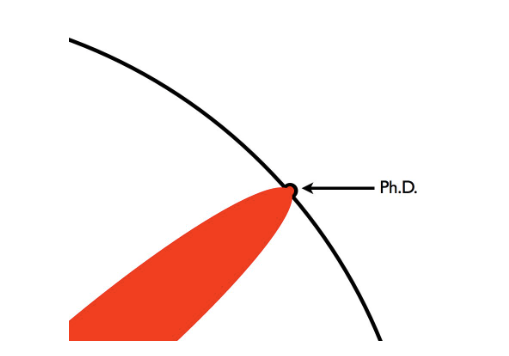
个人理解 PhD 包括两个核心组成:
- (前沿性)要求在前人知识的边界之上,这主要关注研究者和社区的关系 (inter-researcher);
- (进步性)在边界之上做出创新的突破,这主要关注研究者的研究能力 (intra-researcher)。
从脏数据中收敛到知识的边界
先前学习研究,重心往往放在进步性之上,而忽略了达到前沿性的困难。要突破知识的边界,哪里是边界?首先由于触及人类知识体系的前沿,概念体系大多是未定论或是碎片非结构化的,增加了吸收理解难度;其次获取信息大都从他人论文,虽然论文相比其他题材十分注重客观、完整、严谨,但光从发表的论文的获取信息对于“找到边界”要求还是远远不够,信息视角不够完整,这其中有学术界研究人力成本原因没时间做更详细实验、有为了中稿使用“写作的艺术”选择性报道原因、有为了知识产权保密关键数据方法的原因、也有前文提到跨领域视角不够完整导致“重蹈覆辙”的原因。所以一次科研周期大概率是一个启发式的过程,不断的实践复现获取更多“in-house”信息,再不断修正 insight 指导更多的实践方向。如果指望靠大量调研找到知识的边界,容易陷入局部的“鞍点”。这一个过程和所在社区特性息息相关,比如在相对保守封闭的半导体领域难以获取白盒-精准的数据,开源风气也远远比不过算法界,最后得到的可能是一个高度耦合的黑盒结果。而从长期科研生涯来看,也大概率是一个偏启发式过程,在一次次投稿 battle 中对社区的秉性更加了解。
对工程持有敬意
而大致确定边界之后“突破”的要求仍然够喝一壶,进步性包含两个要求:(1)创新性:要想出一个有效的创新 idea,(2)实践性:工程科学更要落于实物,实现出来。而实践性的意义又往往被轻视,ABCDE[12] 原则将 Execution 作为 PhD 第一年的基础要求。特别是流片工作性质又极极极大改变了创新-实践的天平,就拿 ISSCC AI Accelerator Session 举例,首先需要流片,就要克服流片环节整体超高的复杂度,而流片封闭的特性很多没有一个开源的 codebase,还需要花相当长时间从零开始搭建轮子[13];其次 Accelerator 本身属于处理器性质,不同于更侧重模块或者电路层次设计,是需要完整软硬件生态配合的,既要提前将整体协同指定策略,做利好生态的设计,亦要准备生态建设的投入成本;最后 ISSCC 是一个“刷分+实物” 性质的会议,意味着即使你的 idea 本身具有先进意义,但你仍然需要先复现前人的技术再将你的 idea 集成最后以流片指标的形式呈现,同样,复现过程也是没有开源生态的。
从个人而言,大部分时候“创新-实践”其实存在一个竞争关系,大比例的实践侧重投入会挤压创新探索的时间,毕竟再好的 idea 不能做出来价值就大打折扣;从社区评判标准而言,实践性其实也在最后的评判标准中有相当的比重,曾经不解 timeloop 为什么有如此高的影响力[14],多面体模型方法很早在编译器中运用,而 perfect nested loop 仅仅是其中一个子集,并且 timeloop 只是提供了一个建模方法,并没有给出问题的答案,仍然使用启发式探索,从创新角度意义似乎解释不了它的影响力。我拿这个问题问同学的回答是“timeloop 提供了一个开源工具,一个解决方案”,这或许是答案的一部分。
替工业界承担风险
另一个尝尝思考的问题则是学术和工业界的边界,比如模型的 scaling 暴力美学,更多算力更多资本就是能简单出更好的结果,很多时候不仅怀疑自己手头工作的价值。这个话题是“处理问题资本的重要程度-学界人力局限-业界投资比重” 三者的力量对比。 再拿 ISSCC AI 加速器举例,其规则是“刷分+实物”,而其实很多科研问题是要在特定的流片面积、工艺节点、接口 IP 资本投入下才会存在暴露出来,显然学界思想可以到领域的前沿,但资源相对滞后。
如果一个研究方向是学术热点但不是社会热点,没有这类烦恼;而如果研究方向本身是社会热点,能够吸引投资,业界必然会吸纳更多的研究力量和各种资本,在绝对的资本投入面前必然总体上会有更多产出。从发展周期上来看,研究只是工程落地早期占比非常小的一部分,如果研究方向确实有实际价值或者能够带来资本回报,必然会随着社区推进不断涌入更多资本投入,进而使得比重的天平朝着工业界方向倾斜。而现在搞 AI 科研很明显已经在工业力量远远强于学界的节点,而非以 AlexNet 标志之前的科研探索时期。
实际这个问题并不是一个传统问题,早期科研任务由科学院承担,第一批科学院大致于 17 世纪成立,科学院的赞助来自国家政府,主要是国家威望象征一部分而非注重实际生产价值,当时科研者大都是衣食无忧的贵族;而自 1810 年洪堡大学改革后,科研的一部分职责分散到研究性大学中,高等教育体制开始同时负担教育以及研究的职责;真正学界和业界结合则是二战后开始,企业开始与高校建立联合实验室。政府、社会对于学界、业界的定位还处于探索之中。
在研究方向已然身处投资热点情况下,个人观察针对“问题-学界-业界” 三角有相应三种策略:
- (问题)切换赛道,寻找是学术热点,但尚未成为投资热点的方向,缺点是可能干扰研究生涯连续性设计;
- (学界)学界提高资本投入,申请更多学校、政府、工业的 funding,缺点整个学界蛋糕就那么大,只能资助其几个这样的“大组”,只有很少部分课题组有这个资格;
- (业界)业界可以有资本投入是优势也是劣势,资本投入意味着可以集中更大的力量做事情,但这股力量同样也有代价,需要满足投资人回报期望,并收到公司技术路线抉择、产品交付、经济周期等许多因素影响。学界就是一种高风险投资方向,可以找到当下不满足投资规则但 promising 的方向切入,替工业界承担风险,缺点是不能局限学术界社区,需要对业界规则有更深的理解。
AI 加速器: 一手握着锤,一手捏着钉
研究是用方法解决问题,即找到个锤子敲钉子。一般来说,研究划分为锤子型和钉子型,专注于锤子技能的磨练寻找合适的钉子,或者洞悉某一个钉子特点总能找到最合适的锤子。从高中文理分科(or 物理/历史)到本科专业分流,教育其实都是以锤子型培养为导向。而我所处的 AI 加速器方向则同时规定了锤子和钉子,用“硬件加速器”的锤子去敲“AI 算法效率” 的钉子,直觉上来说研究方向作为整个 PhD 生涯最核心的关键参数,一旦变动就会引发连锁反应,带来超高的迭代成本代价,因此出发点应当就像 NV wrap 数量维持 32 一样 简单且铁打不动,很难同时把握锤子和钉子。
一般来说观察身边的同行,大都有两种思路,一种是向上找钉子,向上探到算法层面,扎根算法的优化特点作为第一性原理出发,设计定制化算法硬化,但此类方向本身虽然基于算法出发但以硬件形式呈现,面临前文提到软硬件竞争的问题,有时一个算法加速刚刚实现就已被取代,比如 nerf 到 GS;一种是向下造锤子,和先进工艺、电路技术结合,比如存算一体、高级封装和 3D 芯片、晶圆级芯片等等,扎根半导体特点作为第一性原理出发,好处是半导体本身演进相对硬件缓慢保证了课题连续性,但需要补充高层软硬件的视野。但是现在我感觉无论向上向下都没有很深的认知,还得再经历几轮启发式探索吧 : (
被托举的一份子
先前因不可抗力被动 GAP ,看着同龄人保研/考研/毕业/上班,生活有巨大的错位感,周边人的不理解,对前路的迷茫焦虑,慢慢落下夜间难以入眠的根,回想起那段时光总是感到切身痛苦。坦然而言,只靠我一个人的力量是无法度过走出来的,感谢老板收留和指导,感谢前辈、朋友的鼓励支持推荐,感谢领导对我职业和为人做事的指点教导以及包容,感谢合作者,感谢父母对我决定的支持,感谢感谢。每每回想,深感幸运。“要对流片有敬畏之心”,我魔改一下,“要对 PhD 有敬畏之心”。本身在人类知识的边界下凿开一个口就是极难极难的事情,而现有 PhD 体系下的幸存者大都曾受人恩惠,被众人托举向前。就这样承载他人恩惠,跌跌撞撞闯入了 PhD 的大门。
2025 年 10 月 6 日于清水湾
https://www.cnblogs.com/devil-sx/p/17823271 ↩︎
https://www.cnblogs.com/devil-sx/p/18271814 ↩︎
https://www.cnblogs.com/devil-sx/p/18653329 ↩︎ ↩︎
https://zhuanlan.zhihu.com/p/672689713 ↩︎
https://arxiv.org/abs/2009.06489 ↩︎
https://developer.nvidia.com/blog/nvidia-rubin-cpx-accelerates-inference-performance-and-efficiency-for-1m-token-context-workloads/ ↩︎
https://ieeexplore.ieee.org/document/1575717 ↩︎
https://www.cnblogs.com/devil-sx/p/19097688 ↩︎
https://zhuanlan.zhihu.com/p/717005019 ↩︎
https://www.tomshardware.com/tech-industry/linus-torvalds-says-risc-v-will-make-the-same-mistakes-as-arm-and-x86 ↩︎
https://matt.might.net/articles/phd-school-in-pictures/ ↩︎
https://fengbintu.github.io/advice/ ↩︎
https://www.cnblogs.com/devil-sx/p/19075937 ↩︎
https://github.com/NVlabs/timeloop ↩︎