HKUST 25 Fall COMP 6411D Data Visualization 课堂笔记
可视化的可视化
当我第一眼看到 slide 中“chart taxonomies” ,我有两个反应:
- 图表数量也太多了
- 这个分类方式并不是很直观,Comparsion / Relationship / Distribution / Composition 这些术语都是一些很高层的抽象概念,并且分类本身比较繁琐,比如 Qlik 的分类是一个不规则的树结构,层层分类。并且分类方式并不唯一,比如可以看到 Bar Chart 在 Qlik 中出现多次
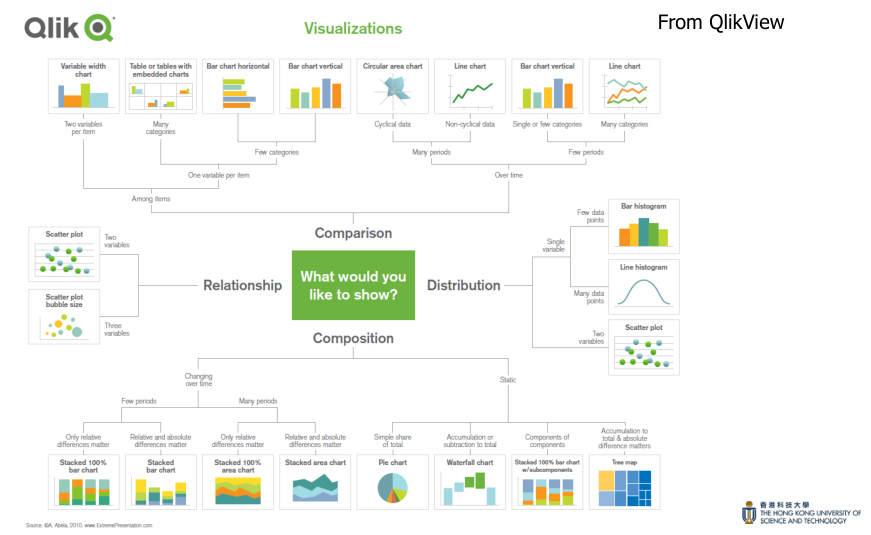
是否能够找到一个更加直观、客观、唯一的分类方式?
25-象限分类图
我对图形的分类通过三个性质判断
- 数据是“自变量”还是“因变量”
- 数据是可量化的 (value) 还是不可量化的 (label)
- 自变量/因变量的数量
比如 Single Line plot 就是 “单个自变量 value 到单个因变量 value” 的一种图像
可视化必然包括表达者和观众主观性
所谓“自变量”“因变量”并非出自数学函数的定义,而是出自观众的角度定义,大致来说“自变量”是观测前已知的,是观众的出发点,是切入数据的角度;而“因变量”是观测前未知的,是观众想要知道的,是观测的结果。一种简单的判断方式是自变量可以展示在图像的标题中,“1-12 月英伟达股价变化”,只看标题已经大概知道我们的自变量可能是月份,包含一月、二月、...,而具体股价是多少需要查看图表才能知道
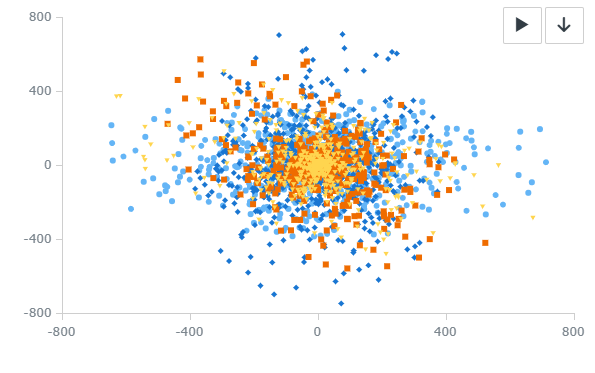
当然以上定义也是一种主观定义方式,即使是同一张图,观众也可能有多种观测的角度,比如如下的 Dot Chart,可能存在多个解释角度:
- 我可以将 x-y axis 当作两个自变量,即二维空间作为观测角度,去观测不同颜色/形状的 label 在二维空间的分布,此时是 “两个自变量 value 到两个因变量 label” 的图像;
- 同样也可以将 label 看作自变量,观察数据在二维空间的未知信息,此时是 “两个自变量 label 到两个因变量 value” 的图像
- 分布这个概念是一个高级的抽象概念,我还可以说以二维空间作为观测角度,去观测不同颜色/形状的 label 在二维空间的“数量”(尽管当点的数量很多时很难直观从 dot 图上得到具体的数值,只能直观感知个大概), 此时是“两个自变量 value 到三个因变量,两个 label 一个 value” 的一种图像
并且不仅和观众相关因人而异,和数据的具体数值也相关。当然如果存在切入角度较多的问题,也说明此时表达着应该尽可能调整作图方式确保呈现信息唯一确定。
数据是可量化/不可量化的同样存在这个问题,比如连续、密集的时间,毫无疑问是 value;是男性还是女性,毫无疑问是 label;那月份呢,似乎可以作为 label 写成一月、二月、...,也可以认作是以一个月为粒度的时间 value,随着可量化的数值离散化稀疏化,value 和 label 的界限会愈加模糊。
表达者/观众的主观性必然导致无法完全客观分类,但本文尽量朝着这个方向呈现。
分类结果
我根据前文提到的三个性质,将图表分为 5x 5=25 个种类,并将部分在课程中介绍过的表格放入对应象限中:

大致来说,此图左下角 “Single 自变量-Single 因变量” 是最直观、信息量最少的图表,左上、右下是信息量较多的图表,而右上是信息量最多的图表,这个分类方法具有局限性,难以归类表征数据结构的“图/网络结构”数据表格。其中 Box 图表因变量包含 value 和 label,其中 label 指的是“是否是 Outliner"
BTW,“25-象限分类图” 在 “25-象限分类图”中的位置属于 “单 label (图的种类)-多 label(自变量-因变量) ”
自动数据可视化
给这种分类方法设想了一个假想应用场景,在科研实验/写文章绘制图表时,我总要画一些时间思考到底使用什么图表,特别是对于有复杂变量的系统在做大量实验时,我需要花相当一部分时间思考从哪个角度观测系统找到相关性,然后再画一些时间思考用什么图表展示,最后告诉 Chat GPT 让他完成对应的 matplotlib 代码,如果不直观,可能还要多想几种呈现方式。
这种分类方法解耦了数据结构和图表之间的依赖关系,也许可以实现一个 Chart Compiler,输入数据并指定数据的分类,其就能自动识别找到有几种图表符合,自动返回几种不同的图表给用户评估。这或许能够节省做实验的时间
老师推荐了来自 UW Interactive Lab [1] 的工作 voyage[2] 和 dacro[3] 工作,该方向叫做 automated visualization design。其中将数据和图像解耦只是第一步,确认数据可以允许由什么 chart 呈现 (hard constraints),而 hard constraints 所允许的 design space 中仍存在大量的选项,第二步则是通过某种需要某种“评分机制”量化排序找到最佳的图表。这面临着两个问题:
- Design space 非常大
- 可视化判断标准相当主观,难以判断
靠用户收集的数据仅仅只是占 design space 中一小部分,所以“评分机制”需要某种泛化性。 voyager 的思想主要是用预先设定规则启发式搜索,而 draco 的方法采用了 learning based 方法尝试学习泛化判断标准。
https://idl.uw.edu/about ↩︎
https://idl.uw.edu/papers/voyager ↩︎
https://idl.uw.edu/draco/ ↩︎