概览:表设计
创建表
- 使用 CREATE TABLE 语句在 Doris 中创建一个表,也可以使用 CREATE TABKE LIKE 或 CREATE TABLE AS 子句从另一个表派生表定义。
表名
- Doris 中表名默认是大小写敏感的,可以在第一次初始化集群时配置lower_case_table_names为大小写不敏感的。默认的表名最大长度为 64 字节,可以通过配置table_name_length_limit更改,不建议配置过大。创建表的语法请参考CREATE TABLE。
表属性
-
Doris 的建表语句中可以指定建表属性,包括:
-
分桶数 (buckets):决定数据在表中的分布;
-
存储介质 (storage_medium):控制数据的存储方式,如使用 HDD、SSD 或远程共享存储;
-
副本数 (replication_num):控制数据副本的数量,以保证数据的冗余和可靠性;
-
冷热分离存储策略 (storage_policy) :控制数据的冷热分离存储的迁移策略;
这些属性作用于分区,即分区创建之后,分区就会有自己的属性,修改表属性只对未来创建的分区生效,对已经创建好的分区不生效,关于属性更多的信息请参考修改表属性。动态分区 可以单独设置这些属性。
注意事项
- 选择合适的数据模型:数据模型不可更改,建表时需要选择一个合适的数据模型;
- 选择合适的分桶数:已经创建的分区不能修改分桶数,可以通过替换分区来修改分桶数,可以修改动态分区未创建的分区分桶数;
- 添加列操作:加减 VALUE 列是轻量级实现,秒级别可以完成,加减 KEY 列或者修改数据类型是重量级操作,完成时间取决于数据量,大规模数据下尽量避免加减 KEY 列或者修改数据类型;
- 优化存储策略:可以使用层级存储将冷数据保存到 HDD 或者 S3 / HDFS。
表类型
模型概述
- 在 Doris 中建表时需要指定表模型,以定义数据存储与管理方式。
- 在 Doris 中提供了明细模型、聚合模型以及主键模型三种表模型,可以应对不同的应用场景需求。
- 不同的表模型具有相应的数据去重、聚合及更新机制。选择合适的表模型有助于实现业务目标,同时保证数据处理的灵活性和高效性。
表模型分类
- 在 Doris 中支持三种表模型:
- 明细模型(
Duplicate Key Model):允许【指定的 Key 列重复】,Doirs 存储层保留所有写入的数据,适用于必须保留所有原始数据记录的情况;- 主键模型(
Unique Key Model):每一行的 Key 值【唯一】,可确保给定的 Key 列不会存在重复行,Doris 存储层对每个 key 只保留最新写入的数据,适用于数据更新的情况;- 聚合模型(
Aggregate Key Model):可根据 Key 列聚合数据,Doris 存储层保留聚合后的数据,从而可以减少存储空间和提升查询性能;通常用于需要汇总或聚合信息(如总数或平均值)的情况。
- 在建表后,表模型的属性已经确认,无法修改。
针对业务选择合适的模型至关重要:
Duplicate Key:适合任意维度的Ad-hoc查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。Unique Key:针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用ROLLUP等预聚合带来的查询优势。Aggregate Key:可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对count(*)查询很不友好。同时因为固定了Value列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
- 部分列更新:请查阅文档主键模型部分列更新与聚合模型部份列更新获取相关使用建议。
排序键
- 在 Doris 中,数据以列的形式存储,一张表可以分为
key列与value列。
- 其中,
key列用于分组与排序,value列用于参与聚合。Key列可以是一个或多个字段,在建表时,按照各种表模型中,Aggregate Key、Unique Key和Duplicate Key的列进行数据排序存储。
- 不同的表模型都需要在建表时指定
Key列,分别有不同的意义:
- 对于
Duplicate Key模型,Key 列表示排序,没有唯一键的约束。- 在
Aggregate Key与Unique Key模型中,会基于 Key 列进行聚合,Key 列既有排序的能力,又有唯一键的约束。
- 合理使用排序键可以带来以下收益:
- 加速查询性能:排序键有助于减少数据扫描量。对于范围查询或过滤查询,可以利用排序键直接定位数据的位置。对于需要需要进行排序的查询,也可以利用排序键进行排序加速;
- 数据压缩优化:数据按排序键有序存储会提高压缩的效率,相似的数据会聚集在一起,压缩率会大幅度提高,从而减小数据的存储空间。
- 减少去重成本:当使用 Unique Key 表时,通过排序键,Doris 能更有效地进行去重操作,保证数据唯一性。
- 选择排序键时,可以遵循以下建议:
Key列必须在所有Value列之前。尽量选择整型类型
因为整型类型的计算和查找效率远高于字符串。
- 对于不同长度的整型类型的选择原则,遵循够用即可。
- 对于 VARCHAR 和 STRING 类型的长度,遵循够用即可原则。
表模型能力对比
| 明细模型 | 主键模型 | 聚合模型 | |
|---|---|---|---|
| Key 列唯一约束 | 不支持,Key 列可以重复 | 支持 | 支持 |
| 同步物化视图 | 支持 | 支持 | 支持 |
| 异步物化视图 | 支持 | 支持 | 支持 |
| UPDATE 语句 | 不支持 | 支持 | 不支持 |
| DELETE 语句 | 部分支持 | 支持 | 不支持 |
| 导入时整行更新 | 不支持 | 支持 | 不支持 |
| 导入时部分列更新 | 不支持 | 支持 | 部分支持 |
明细模型
模型介绍
- 明细模型是 Doris 中的默认建表模型,用于保存每条原始数据记录。
在建表时,通过
DUPLICATE KEY指定数据存储的排序列,以优化常用查询。
一般建议选择三列或更少的列作为【排序键】,具体选择方式参考排序键。
- 明细模型的特点:
保留原始数据:明细模型保留了全量的原始数据,适合于存储与查询原始数据。对于需要进行详细数据分析的应用场景,建议使用明细模型,以避免数据丢失的风险;
不去重也不聚合:与聚合模型与主键模型不同,明细模型不会对数据进行去重与聚合操作。即使两条相同的数据,每次插入时也会被完整保留;
灵活的数据查询:明细模型保留了全量的原始数据,可以从完整数据中提取细节,基于全量数据做任意维度的聚合操作,从而进行元数数据的审计及细粒度的分析。
使用场景
一般明细模型中的数据只进行追加,旧数据不会更新。明细模型适用于需要存储全量原始数据的场景:
- 日志存储:用于存储各类的程序操作日志,如访问日志、错误日志等。每一条数据都需要被详细记录,方便后续的审计与分析;
- 用户行为数据:在分析用户行为时,如点击数据、用户访问轨迹等,需要保留用户的详细行为,方便后续构建用户画像及对行为路径进行详细分析;
- 交易数据:在某些存储交易行为或订单数据时,交易结束时一般不会发生数据变更。明细模型适合保留这一类交易信息,不遗漏任意一笔记录,方便对交易进行精确的对账。
建表说明
- 在建表时,可以通过
DUPLICATE KEY关键字指定明细模型。
明细表必须指定数据的
Key列,用于在存储时对数据进行排序。下例的明细表中存储了日志信息,并针对于 log_time、log_type 及 error_code 三列进行了排序:
CREATE TABLE IF NOT EXISTS example_tbl_duplicate
(log_time DATETIME NOT NULL,log_type INT NOT NULL,error_code INT,error_msg VARCHAR(1024),op_id BIGINT,op_time DATETIME
)
DUPLICATE KEY(log_time, log_type, error_code)
DISTRIBUTED BY HASH(log_type) BUCKETS 10;-- 修改表的注释
-- ALTER TABLE example_db.example_table COMMENT "更新后的用户信息表描述";-- 修改字段注释
-- ALTER TABLE example_db.example_table MODIFY COLUMN name COMMENT "更新后的用户姓名字段描述";
数据插入与存储
- 在明细表中,数据不进行去重与聚合,插入数据即存储数据。明细模型中 Key 列指做为排序。
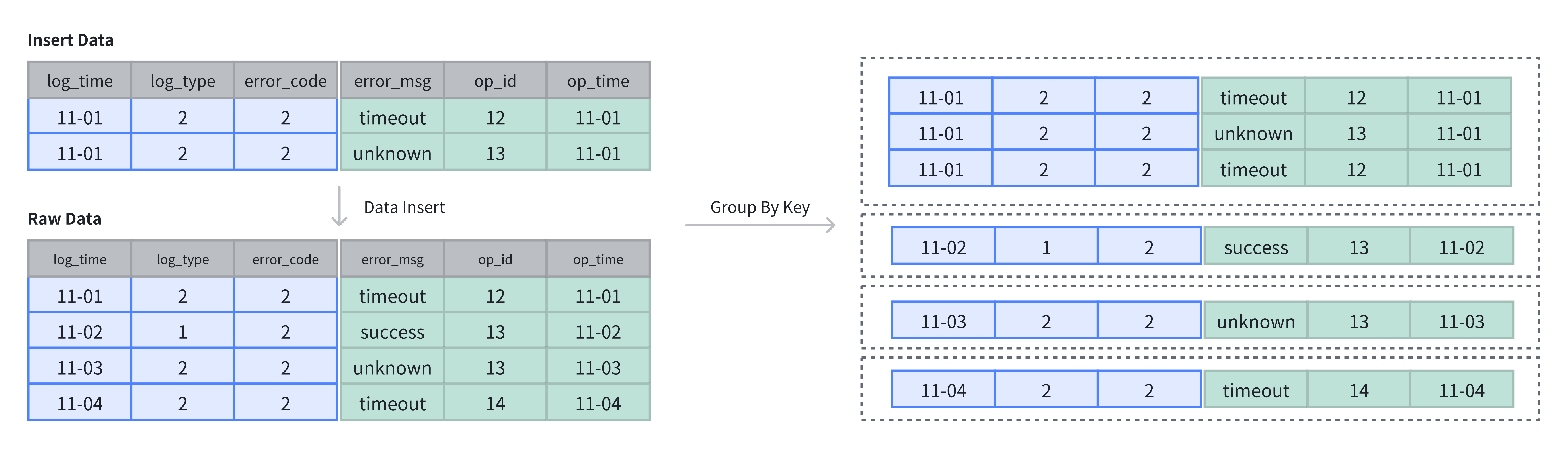
在上例中,表中原有 4 行数据,插入 2 行数据后,采用追加(APPEND)方式存储,共计 6 行数据:
-- 4 rows raw data
INSERT INTO example_tbl_duplicate VALUES
('2024-11-01 00:00:00', 2, 2, 'timeout', 12, '2024-11-01 01:00:00'),
('2024-11-02 00:00:00', 1, 2, 'success', 13, '2024-11-02 01:00:00'),
('2024-11-03 00:00:00', 2, 2, 'unknown', 13, '2024-11-03 01:00:00'),
('2024-11-04 00:00:00', 2, 2, 'unknown', 12, '2024-11-04 01:00:00');-- insert into 2 rows
INSERT INTO example_tbl_duplicate VALUES
('2024-11-01 00:00:00', 2, 2, 'timeout', 12, '2024-11-01 01:00:00'),
('2024-11-01 00:00:00', 2, 2, 'unknown', 13, '2024-11-01 01:00:00');-- check the rows of table
SELECT * FROM example_tbl_duplicate;
+---------------------+----------+------------+-----------+-------+---------------------+
| log_time | log_type | error_code | error_msg | op_id | op_time |
+---------------------+----------+------------+-----------+-------+---------------------+
| 2024-11-02 00:00:00 | 1 | 2 | success | 13 | 2024-11-02 01:00:00 |
| 2024-11-01 00:00:00 | 2 | 2 | timeout | 12 | 2024-11-01 01:00:00 |
| 2024-11-03 00:00:00 | 2 | 2 | unknown | 13 | 2024-11-03 01:00:00 |
| 2024-11-04 00:00:00 | 2 | 2 | unknown | 12 | 2024-11-04 01:00:00 |
| 2024-11-01 00:00:00 | 2 | 2 | unknown | 13 | 2024-11-01 01:00:00 |
| 2024-11-01 00:00:00 | 2 | 2 | timeout | 12 | 2024-11-01 01:00:00 |
+---------------------+----------+------------+-----------+-------+---------------------+-- 对同一个 op_id 保留 op_time 最晚的那一行 (等价写法:GROUP BY + ANY_VALUE(Doris 0.15+))
SELECT log_time, log_type, error_code, error_msg, op_id, op_time, rank_no
FROM (select *, ROW_NUMBER() OVER (PARTITION BY op_id ORDER BY op_time desc) AS rank_nofrom example_tbl_duplicate-- order by op_time desc
) t1
WHERE rank_no = 1;log_time |log_type|error_code|error_msg|op_id|op_time |rank_no|
-------------------+--------+----------+---------+-----+-------------------+-------+
2024-11-04 00:00:00| 2| 2|unknown | 12|2024-11-04 01:00:00| 1|
2024-11-03 00:00:00| 2| 2|unknown | 13|2024-11-03 01:00:00| 1|
2024-11-02 00:00:00| 1| 2|success | 13|2024-11-02 01:00:00| 2|
2024-11-01 00:00:00| 2| 2|timeout | 12|2024-11-01 01:00:00| 2|
2024-11-01 00:00:00| 2| 2|unknown | 13|2024-11-01 01:00:00| 3|
2024-11-01 00:00:00| 2| 2|timeout | 12|2024-11-01 01:00:00| 3|
主键模型
-
当需要更新数据时,可以选择主键模型(Unique Key Model)。该模型保证 Key 列的唯一性,插入或更新数据时,新数据会覆盖具有相同 Key 的旧数据,确保数据记录为最新。与其他数据模型相比,主键模型适用于数据的更新场景,在插入过程中进行主键级别的更新覆盖。
-
主键模型的特点:
- 基于主键进行 UPSERT:在插入数据时,主键重复的数据会更新,主键不存在的记录会插入;
- 基于主键进行去重:主键模型中的 Key 列具有唯一性,会对根据主键列对数据进行去重操作;
- 高频数据更新:支持高频数据更新场景,同时平衡数据更新性能与查询性能。
使用场景
- 高频数据更新:适用于上游 OLTP 数据库中的维度表,实时同步更新记录,并高效执行 UPSERT 操作;
- 数据高效去重:如广告投放和客户关系管理系统中,使用主键模型可以基于用户 ID 高效去重;
- 需要部分列更新:如画像标签场景需要变更频繁改动的动态标签,消费订单场景需要改变交易的状态。通过主键模型部分列更新能力可以完成某几列的变更操作。
实现方式
在 Doris 中主键模型有两种实现方式:
-
写时合并(
merge-on-write):自 1.2 版本起,Doris 默认使用写时合并模式,数据在写入时立即合并相同 Key 的记录,确保存储的始终是最新数据。写时合并兼顾查询和写入性能,避免多个版本的数据合并,并支持谓词下推到存储层。大多数场景推荐使用此模式; -
读时合并(
merge-on-read):在 1.2 版本前,Doris 中的主键模型默认使用读时合并模式,数据在写入时并不进行合并,以增量的方式被追加存储,在 Doris 内保留多个版本。查询或 Compaction 时,会对数据进行相同 Key 的版本合并。读时合并适合写多读少的场景,在查询是需要进行多个版本合并,谓词无法下推,可能会影响到查询速度。 -
在 Doris 中基于主键模型更新有两种语义:
- 整行更新:Unique Key 模型默认的更新语义为整行UPSERT,即 UPDATE OR INSERT,该行数据的 Key 如果存在,则进行更新,如果不存在,则进行新数据插入。在整行 UPSERT 语义下,即使用户使用 Insert Into 指定部分列进行写入,Doris 也会在 Planner 中将未提供的列使用 NULL 值或者默认值进行填充。
- 部分列更新:如果用户希望更新部分字段,需要使用写时合并实现,并通过特定的参数来开启部分列更新的支持。请查阅文档部分列更新。
写时合并
- 在建表时,使用
UNIQUE KEY关键字可以指定主键表。通过显示开启enable_unique_key_merge_on_write属性可以指定写时合并模式。自 Doris 2.1 版本以后,默认开启写时合并:
CREATE TABLE IF NOT EXISTS example_tbl_unique
(user_id LARGEINT NOT NULL,user_name VARCHAR(50) NOT NULL,city VARCHAR(20),age SMALLINT,sex TINYINT
)
UNIQUE KEY(user_id, user_name)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES ("enable_unique_key_merge_on_write" = "true"
);
读时合并
- 在建表时,使用
UNIQUE KEY关键字可以指定主键表。通过显示关闭enable_unique_key_merge_on_write属性可以指定读时合并模式。在 Doris 2.1 版本之前,默认开启读时合并:
CREATE TABLE IF NOT EXISTS example_tbl_unique
(user_id LARGEINT NOT NULL,username VARCHAR(50) NOT NULL,city VARCHAR(20),age SMALLINT,sex TINYINT
)
UNIQUE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES ("enable_unique_key_merge_on_write" = "false"
);
数据插入与存储
- 在主键表中,Key 列不仅用于排序,还用于去重,插入数据时,相同 Key 的记录会被覆盖。
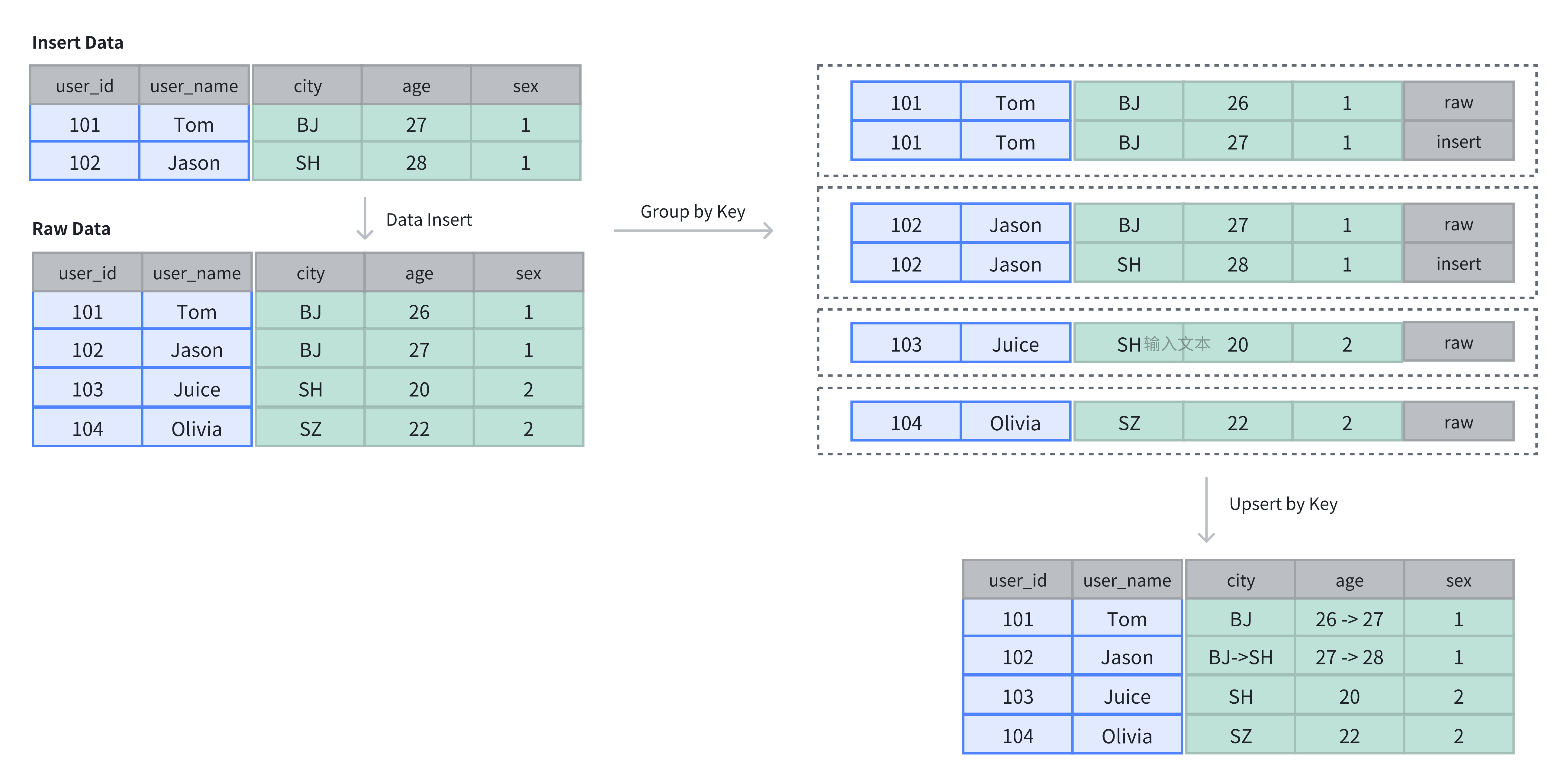
如上例所示,原表中有 4 行数据,插入 2 行后,新插入的数据基于主键进行了更新:
-- insert into raw data
INSERT INTO example_tbl_unique VALUES
(101, 'Tom', 'BJ', 26, 1),
(102, 'Jason', 'BJ', 27, 1),
(103, 'Juice', 'SH', 20, 2),
(104, 'Olivia', 'SZ', 22, 2);-- insert into data to update by key
INSERT INTO example_tbl_unique VALUES
(101, 'Tom', 'BJ', 27, 1),
(102, 'Jason', 'SH', 28, 1);-- check updated data
SELECT * FROM example_tbl_unique;
+---------+----------+------+------+------+
| user_id | username | city | age | sex |
+---------+----------+------+------+------+
| 101 | Tom | BJ | 27 | 1 |
| 102 | Jason | SH | 28 | 1 |
| 104 | Olivia | SZ | 22 | 2 |
| 103 | Juice | SH | 20 | 2 |
+---------+----------+------+------+------+
注意事项
-
Unique 表的实现方式只能在建表时确定,无法通过 schema change 进行修改;
-
在整行
UPSERT语义下,即使用户使用 insert into 指定部分列进行写入,Doris 也会在 Planner 中将未提供的列使用 NULL 值或者默认值进行填充; -
部分列更新。如果用户希望更新部分字段,需要使用写时合并实现,并通过特定的参数来开启部分列更新的支持。请查阅文档部分列更新获取相关使用建议;
-
使用 Unique 表时,为了保证数据的唯一性,分区键必须包含在 Key 列内。
聚合模型
- Doris 的聚合模型专为高效处理大规模数据查询中的聚合操作设计。它通过预聚合数据,减少重复计算,提升查询性能。聚合模型只存储聚合后的数据,节省存储空间并加速查询。
使用场景
- 明细数据进行汇总:用于电商平台的月销售业绩、金融风控的客户交易总额、广告投放的点击量等业务场景中,进行多维度汇总;
- 不需要查询原始明细数据:如驾驶舱报表、用户交易行为分析等,原始数据存储在数据湖中,仅需存储汇总后的数据。
原理
- 每一次数据导入会在聚合模型内形成一个版本,在 Compaction 阶段进行版本合并,在查询时会按照主键进行数据聚合:
- 数据导入阶段:数据按批次导入,每批次生成一个版本,并对相同聚合键的数据进行初步聚合(如求和、计数);
- 后台文件合并阶段(Compaction):多个版本文件会定期合并,减少冗余并优化存储;
- 查询阶段:查询时,系统会聚合同一聚合键的数据,确保查询结果准确。
建表说明
使用 AGGREGATE KEY 关键字在建表时指定聚合模型,并指定 Key 列用于聚合 Value 列。
CREATE TABLE IF NOT EXISTS example_tbl_agg
(user_id LARGEINT NOT NULL,load_dt DATE NOT NULL,city VARCHAR(20),last_visit_dt DATETIME REPLACE DEFAULT "1970-01-01 00:00:00",cost BIGINT SUM DEFAULT "0",max_dwell INT MAX DEFAULT "0",
)
AGGREGATE KEY(user_id, load_dt, city)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
上例中定义了用户信息和访问行为表,将 user_id、load_date、city 及 age 作为 Key 列进行聚合。数据导入时,Key 列会聚合成一行,Value 列会按照指定的聚合类型进行维度聚合。
- 在聚合表中支持以下类型的维度聚合:
| 聚合方式 | 描述 |
|---|---|
| SUM | 求和,多行的 Value 进行累加。 |
| REPLACE | 替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。 |
| MAX | 保留最大值。 |
| MIN | 保留最小值。 |
| REPLACE_IF_NOT_NULL | 非空值替换。与 REPLACE 的区别在于对 null 值,不做替换。 |
| HLL_UNION | HLL 类型的列的聚合方式,通过 HyperLogLog 算法聚合。 |
| BITMAP_UNION | BITMAP 类型的列的聚合方式,进行位图的并集聚合。 |
- 提示:
如果以上的聚合方式无法满足业务需求,可以选择使用
agg_state类型。
数据插入与存储
- 在聚合表中,数据基于主键进行聚合操作。数据插入后及完成聚合操作。
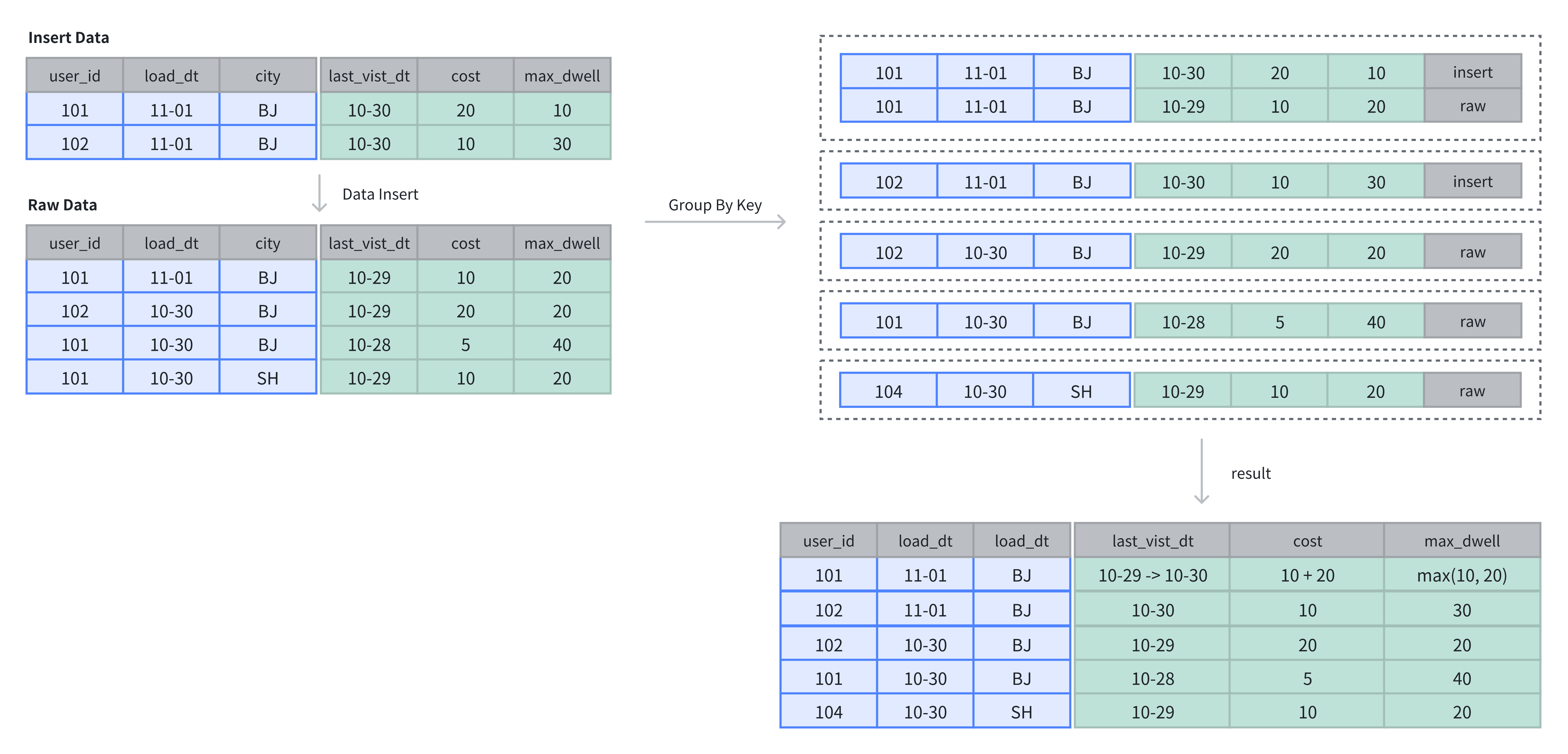
- 在上例中,表中原有 4 行数据,在插入 2 行数据后,基于 Key 列进行维度列的聚合操作:
-- 4 rows raw data
INSERT INTO example_tbl_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-29', 10, 20),
(102, '2024-10-30', 'BJ', '2024-10-29', 20, 20),
(101, '2024-10-30', 'BJ', '2024-10-28', 5, 40),
(101, '2024-10-30', 'SH', '2024-10-29', 10, 20);-- insert into 2 rows
INSERT INTO example_tbl_agg VALUES
(101, '2024-11-01', 'BJ', '2024-10-30', 20, 10),
(102, '2024-11-01', 'BJ', '2024-10-30', 10, 30);-- check the rows of table
SELECT * FROM example_tbl_agg;
+---------+------------+------+---------------------+------+----------------+
| user_id | load_date | city | last_visit_date | cost | max_dwell_time |
+---------+------------+------+---------------------+------+----------------+
| 102 | 2024-10-30 | BJ | 2024-10-29 00:00:00 | 20 | 20 |
| 102 | 2024-11-01 | BJ | 2024-10-30 00:00:00 | 10 | 30 |
| 101 | 2024-10-30 | BJ | 2024-10-28 00:00:00 | 5 | 40 |
| 101 | 2024-10-30 | SH | 2024-10-29 00:00:00 | 10 | 20 |
| 101 | 2024-11-01 | BJ | 2024-10-30 00:00:00 | 30 | 20 |
+---------+------------+------+---------------------+------+----------------+
AGG_STATE
- 提示:
AGG_STATE是实验特性,建议在开发与测试环境中使用。
AGG_STATE不能作为Key列使用,建表时需要同时声明聚合函数的签名。不需要指定长度和默认值。实际存储的数据大小与函数实现有关。
set enable_agg_state = true;
CREATE TABLE aggstate(k1 int NULL,v1 int SUM,v2 agg_state<group_concat(string)> generic
)
AGGREGATE KEY(k1)
DISTRIBUTED BY HASH(k1) BUCKETS 3;
在此示例中,agg_state 用于声明数据类型,
sum/group_concat为聚合函数签名。
- agg_state 是一种数据类型,类似于 int、array、string。
agg_state 只能与 state、mergeunion 函数组合器配合使用。
- 它表示聚合函数的中间结果,例如 group_concat 的中间状态,而非最终结果。
agg_state类型需要使用state函数来生成,对于当前的这个表,需要使用 group_concat_state:
类比 clickhouse 的聚合表、聚合函数。
insert into aggstate values(1, 1, group_concat_state('a'));
insert into aggstate values(1, 2, group_concat_state('b'));
insert into aggstate values(1, 3, group_concat_state('c'));
insert into aggstate values(2, 4, group_concat_state('d'));
此时表内计算方式如下图所示:

- 在查询时,可以使用 merge 操作合并多个 state,并且返回最终聚合结果。因为 group_concat 对于顺序有要求,所以结果是不稳定的。
select group_concat_merge(v2) from aggstate;
+------------------------+
| group_concat_merge(v2) |
+------------------------+
| d,c,b,a |
+------------------------+
- 如果不想要最终的聚合结果,而希望保留中间结果,可以使用
union操作:
insert into aggstate select 3,sum_union(k2),group_concat_union(k3) from aggstate;
此时表中计算如下:

查询结果如下:
mysql> select sum_merge(k2) , group_concat_merge(k3)from aggstate;
+---------------+------------------------+
| sum_merge(k2) | group_concat_merge(k3) |
+---------------+------------------------+
| 20 | c,b,a,d,c,b,a,d |
+---------------+------------------------+mysql> select sum_merge(k2) , group_concat_merge(k3)from aggstate where k1 != 2;
+---------------+------------------------+
| sum_merge(k2) | group_concat_merge(k3) |
+---------------+------------------------+
| 16 | c,b,a,d,c,b,a |
+---------------+------------------------+
使用注意
建表时列类型建议
- Key 列必须在所有 Value 列之前。
- 尽量选择整型类型。因为整型类型的计算和查找效率远高于字符串。
- 对于不同长度的整型类型的选择原则,遵循够用即可。
- 对于 VARCHAR 和 STRING 类型的长度,遵循够用即可。
聚合模型的局限性
- 这里针对 Aggregate 模型,来介绍下聚合模型的局限性。
- 在聚合模型中,模型对外展现的,是最终聚合后的数据。也就是说,任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。
举例说明。
假设表结构如下:
| ColumnName | Type | AggregationType | Comment |
|---|---|---|---|
| user_id | LARGEINT | 用户 id | |
| date | DATE | 数据灌入日期 | |
| cost | BIGINT | SUM | 用户总消费 |
假设存储引擎中有如下两个已经导入完成的批次的数据:
batch 1
| user_id | date | cost |
|---|---|---|
| 10001 | 2017/11/20 | 50 |
| 10002 | 2017/11/21 | 39 |
batch 2
| user_id | date | cost |
|---|---|---|
| 10001 | 2017/11/20 | 1 |
| 10001 | 2017/11/21 | 5 |
| 10003 | 2017/11/22 | 22 |
可以看到,用户 10001 分属在两个导入批次中的数据还没有聚合。但是为了保证用户只能查询到如下最终聚合后的数据:
| user_id | date | cost |
|---|---|---|
| 10001 | 2017/11/20 | 51 |
| 10001 | 2017/11/21 | 5 |
| 10002 | 2017/11/21 | 39 |
| 10003 | 2017/11/22 | 22 |
我们在查询引擎中加入了【聚合算子】,来保证【数据对外的一致性】。
另外,在聚合列(Value)上,执行与聚合类型不一致的聚合类查询时,要注意语意。比如在如上示例中执行如下查询:
SELECT MIN(cost) FROM table;
得到的结果是 5,而不是 1。
同时,这种一致性保证,在某些查询中,会极大地降低查询效率。
以最基本的 count(*) 查询为例:
SELECT COUNT(*) FROM table;
在其他数据库中,这类查询都会很快地返回结果。
因为在实现上,我们可以通过如“导入时对行进行计数,保存 count 的统计信息”,或者在查询时“仅扫描某一列数据,获得 count 值”的方式,只需很小的开销,即可获得查询结果。但是在 Doris 的聚合模型中,这种查询的开销非常大。
以刚才的数据为例:
batch 1
| user_id | date | cost |
|---|---|---|
| 10001 | 2017/11/20 | 50 |
| 10002 | 2017/11/21 | 39 |
batch 2
| user_id | date | cost |
|---|---|---|
| 10001 | 2017/11/20 | 1 |
| 10001 | 2017/11/21 | 5 |
| 10003 | 2017/11/22 | 22 |
因为最终的聚合结果为:
| user_id | date | cost |
|---|---|---|
| 10001 | 2017/11/20 | 51 |
| 10001 | 2017/11/21 | 5 |
| 10002 | 2017/11/21 | 39 |
| 10003 | 2017/11/22 | 22 |
所以,select count(*) from table; 的正确结果应该为 4。但如果只扫描 user_id 这一列,如果加上查询时聚合,最终得到的结果是 3(10001, 10002, 10003)。而如果不加查询时聚合,则得到的结果是 5(两批次一共 5 行数据)。可见这两个结果都是不对的。
为了得到正确的结果,必须同时读取 user_id 和 date 这两列的数据,再加上查询时聚合,才能返回 4 这个正确的结果。也就是说,在 count() 查询中,Doris 必须扫描所有的 AGGREGATE KEY 列(这里就是user_id date),并且聚合后,才能得到语意正确的结果。 当聚合列非常多时,count() 查询需要扫描大量的数据。
因此,当业务上有频繁的 count() 查询时,建议用户通过增加一个值恒为 1 的,聚合类型为 SUM 的列来模拟 count()。如刚才的例子中的表结构,我们修改如下:
| ColumnName | Type | AggregateType | Comment |
|---|---|---|---|
| user_id | BIGINT | 用户 id | |
| date | DATE | 数据灌入日期 | |
| cost | BIGINT | SUM | 用户总消费 |
| count | BIGINT | SUM | 用于计算 count |
增加一个 count 列,并且导入数据中,该列值恒为 1。则 select count(*) from table; 的结果等价于 select sum(count) from table;。而后者的查询效率将远高于前者。不过这种方式也有使用限制,就是用户需要自行保证,不会重复导入 AGGREGATE KEY 列都相同地行。否则,select sum(count) from table; 只能表述原始导入的行数,而不是 select count(*) from table; 的语义。
另一种方式,就是将如上的 count 列的聚合类型改为 REPLACE,且依然值恒为 1。那么 select sum(count) from table; 和 select count(*) from table; 的结果将是一致的。并且这种方式,没有导入重复行的限制。
Unique 模型的写时合并实现
Unique 模型的写时合并实现没有聚合模型的局限性,还是以刚才的数据为例,写时合并为每次导入的 rowset 增加了对应的 delete bitmap,来标记哪些数据被覆盖。第一批数据导入后状态如下
batch 1
| user_id | date | cost | delete bit |
|---|---|---|---|
| 10001 | 2017/11/20 | 50 | FALSE |
| 10002 | 2017/11/21 | 39 | FALSE |
当第二批数据导入完成后,第一批数据中重复的行就会被标记为已删除,此时两批数据状态如下
batch 1
| user_id | date | cost | delete bit |
|---|---|---|---|
| 10001 | 2017/11/20 | 50 | TRUE |
| 10002 | 2017/11/21 | 39 | FALSE |
batch 2
| user_id | date | cost | delete bit |
|---|---|---|---|
| 10001 | 2017/11/20 | 1 | FALSE |
| 10001 | 2017/11/21 | 5 | FALSE |
| 10003 | 2017/11/22 | 22 | FALSE |
在查询时,所有在 delete bitmap 中被标记删除的数据都不会读出来,因此也无需进行做任何数据聚合,上述数据中有效地行数为 4 行,查询出的结果也应该是 4 行,也就可以采取开销最小的方式来获取结果,即前面提到的“仅扫描某一列数据,获得 count 值”的方式。
在测试环境中,count(*) 查询在 Unique 模型的写时合并实现上的性能,相比聚合模型有 10 倍以上的提升。
Duplicate 模型
Duplicate 模型没有聚合模型的这个局限性。因为该模型不涉及聚合语意,在做 count(*) 查询时,任意选择一列查询,即可得到语意正确的结果。
Key 列的不同意义
Duplicate、Aggregate、Unique 模型,都会在建表指定 Key 列,然而实际上是有所区别的:对于 Duplicate 模型,表的 Key 列,可以认为只是 "排序列",并非起到唯一标识的作用。而 Aggregate、Unique 模型这种聚合类型的表,Key 列是兼顾 "排序列" 和 "唯一标识列",是真正意义上的 "Key 列"。
模型选择建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
- Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
- Unique 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势。对于聚合查询有较高性能需求的用户,推荐使用自 1.2 版本加入的写时合并实现。
- Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。
- 如果有部分列更新的需求,请查阅文档主键模型部分列更新 与 聚合模型部份列更新 获取相关使用建议。
Z 案例实践
CASE 明细表的创建、数据存写
create database bdp_device_dev;-- 创建 设备【状态信号】的明细表
-- show create table `bdp_device_dev`.`dwd_device_status_signal_ri`;
-- DROP TABLE IF EXISTS `bdp_device_dev`.`dwd_device_status_signal_ri`;
CREATE TABLE IF NOT EXISTS `bdp_device_dev`.`dwd_device_status_signal_ri` (device_id VARCHAR(64) NOT NULL COMMENT '机器人设备ID(SN码)',sampling_time BIGINT NOT NULL COMMENT '数据采样时间(13位毫秒级时间戳)',signals STRING COMMENT '状态信号信息(JSON String)',sampling_interval INT NOT NULL COMMENT '大数据采样周期(单位:s)',sampling_date DATETIME NOT NULL COMMENT '大数据采样日期(按天分区)',report_time BIGINT NOT NULL COMMENT '报文上报时间',trace_id VARCHAR(64) COMMENT '跟踪ID',gateway_message_time BIGINT COMMENT '中台设备网关转发到KAFKA的时间',ingest_time BIGINT COMMENT '大数据接收报文数据的时间',parse_time BIGINT COMMENT '大数据解析处理报文的时间',data_version DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '数据版本号/数据的入库时间'
)
DUPLICATE KEY(sys_code, device_id, sampling_time) -- 针对于 sys_code, device_id, sampling_time 3列进行了排序
-- DISTRIBUTED BY HASH(device_id) BUCKETS 10; -- device_id 是分桶键,数据将根据 device_id 的哈希值分布到 n 个分桶中, 每个分桶对应一个物理存储单元(Tablet),这些分桶均匀分布在集群的不同节点上。哈希值相同的数据会被分配到同一个分桶中。
DISTRIBUTED BY HASH(device_id) BUCKETS AUTO
PROPERTIES("estimate_partition_size" = "10G"); -- 默认情况下,estimate_partition_size 的值为 10GB,每个分桶对应一个 Tablet,建议 Tablet 的大小控制在 1GB 至 10GB 之间,以确保性能最佳。/** 插入数据的样例语句
INSERT INTO `bdp_device_dev`.`dwd_device_status_signal_ri`(sys_code, device_id, sampling_time, signals, sampling_interval, sampling_date, report_time, trace_id, gateway_message_time, ingest_time, parse_time
) VALUES
( 'xxxx', 2, 2, '{}',, 1, '2022-09-09 16:14:00', unix_timestamp( '2022-09-09 16:14:00' )*1000, '4645345-464-46456-54635df54', unix_timestamp( '2022-09-09 16:14:01' )*1000, unix_timestamp( '2022-09-09 16:14:02' )*1000 , unix_timestamp( '2022-09-09 16:14:03' )*1000
);
**/
Y 推荐文献
-
[数据库] MySQL之数据库管理篇 - 博客园/千千寰宇
-
Apache Doris
- https://doris.apache.org
- https://github.com/apache/doris
- https://doris.apache.org/zh-CN/docs/3.0/gettingStarted/what-is-apache-doris
- https://doris.apache.org/zh-CN/docs
X 参考文献
- 使用指南-数据表设计-表类型-模型概述 - Doris
