VGGT: Visual Geometry Grounded Transformer
VGGT(CVPR'25):基于预训练模型抽取特征,通过网络预测3D场景的多种信息。
代码仓库
注:笔者对3D场景重建相关领域工作并不熟悉,仅记录自己的理解。
动机
本文希望实现一个能够端到端从单图或多图预测多种3D场景信息的模型,输出结果包括相机参数、点云图、深度图和3D点轨迹。
方法
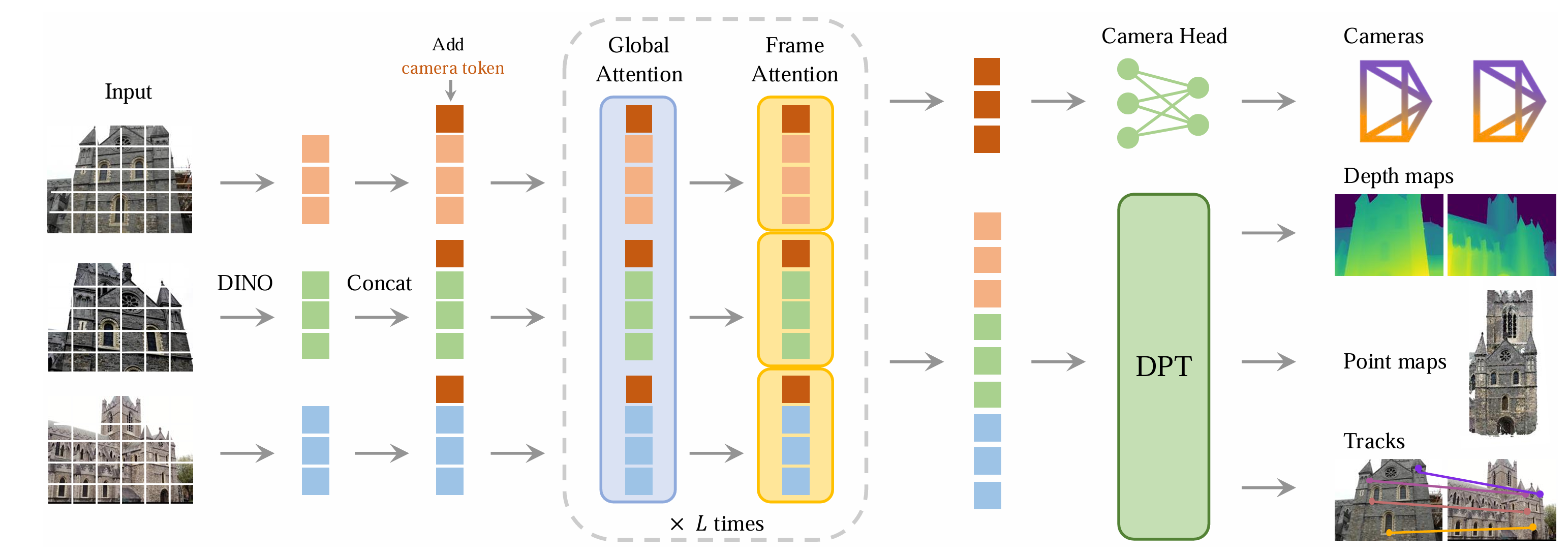
本文设定的场景为通过一个图片序列预测3D场景信息。该图片序列理论上是可以任意顺序输入,不过实际实现中是以第一帧为参考。
对于每帧图像,通过DINO提取特征,获得对应每帧图像的token序列。随后再在帧token序列上添加一个相机token和四个register token,作为可学习参数。
随后将组合的特征送入一个改装的自注意力模块,交替进行全局自注意力和帧内自注意力。输出的特征向量分解为相机token及图像特征,送入相应的后续网络完成后续任务。
训练方面似乎更多参照了已有工作,笔者对相关领域不太了解,详细内容请见原文。
实验

具有优秀的重建结果,在多种任务上达到了SOTA水平,详见原文。
总结
按照笔者的理解,本文的突出贡献主要在于完成了一个端到端的3D场景重建模型,能够输出多种信息。从技术角度理解,是利用自监督预训练模型提取的特征构建网络预测目标信息。