详细介绍:集成学习算法简介
学习⽬标
集成学习就是了解什么
知道机器学习中的两个核⼼任务
了解集成学习中的boosting和bagging
什么是集成学习
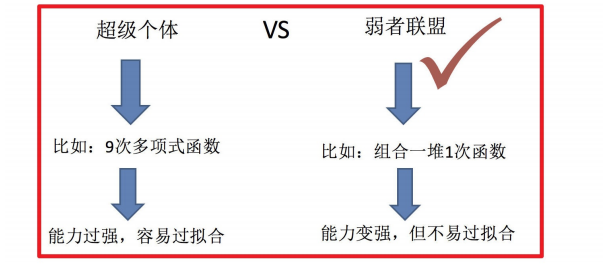
集成学习通过建⽴⼏个模型来解决单⼀预测问题。它的⼯作原理是⽣成多个分类器/模型,各⾃独⽴地学习和作出预
测。这些预测最后结合成组合预测,因此优于任何⼀个单分类的做出预测。
集成学习中boosting和Bagging
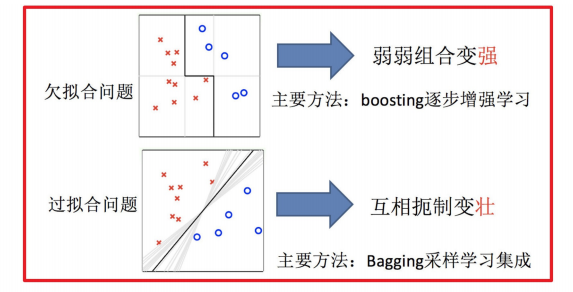
只要单分类器的表现不太差,集成学习的结果总是要好于单分类器的
Bagging和随机森林
学习⽬标
知道Bagging集成原理
知道随机森林构造过程
包外估计就是知道什么
知道RandomForestClassifier的使⽤
了解baggind集成的优点
Bagging集成原理
⽬标:把下⾯的圈和⽅块进⾏分类
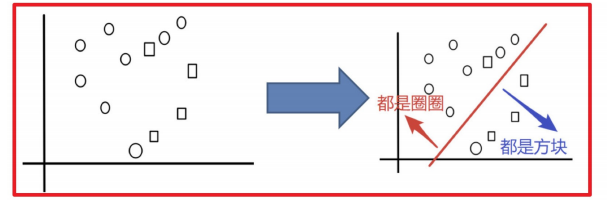
实现过程:
1) 采样不同信息集
2)训练分类器
3)平权投票,获取最终结果
4)首要实现过程⼩结
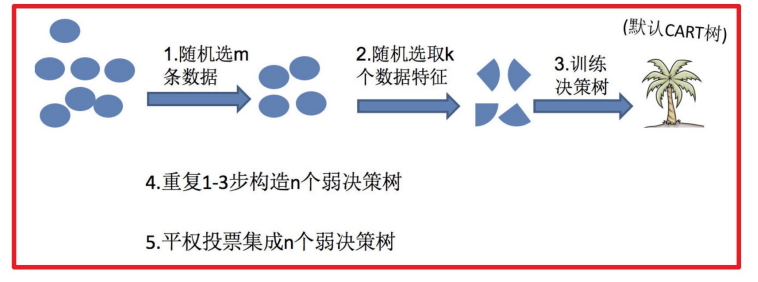
2 随机森林构造过程
在机器学习中,随机森林是⼀个包含多个决策树的分类器由个别树输出的类别的众数⽽定。就是,并且其输出的类别
随机森林 = Bagging +决策树
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个树的结果是False, 那么最终投票结果就是True
随机森林够造过程中的关键步骤(M表示特征数⽬):
1)⼀次随机选出⼀个样本,有放回的抽样,重复N次(有可能出现重复的样本)
2) 随机去选出m个特征, m <<M,建⽴决策树
思考
1.为什么要随机抽样训练集?
如果不进⾏随机抽样,每棵树的训练集都⼀样,那么最终训练出的树分类结果也是完全⼀样的
2.为什么要有放回地抽样?
有很⼤的差异的;⽽随机森林最后分类取决于多棵树(弱分类器)的投票表决。就是如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“⽚⾯的”(当然这样说可能不对),也就是说每棵树训练出来都
包外估计 (Out-of-Bag Estimate)
在随机森林构造过程中,如果进⾏有放回的抽样,我们会发现,总是有⼀部分样本我们选不到。
这部分数据,占整体数据的⽐重有多⼤呢?
这部分数据有什么⽤呢
包外估计的定义
随机森林的 Bagging 过程,对于每⼀颗训练出的决策树g ,与数据集 D 有如下关系:
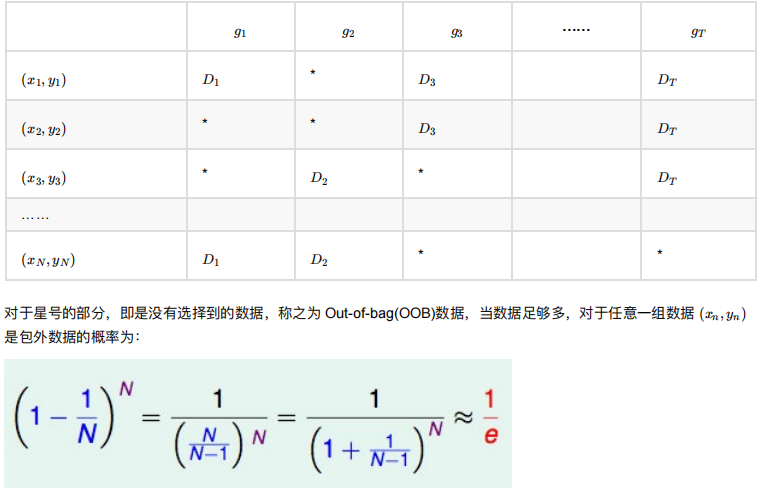
由于基分类器是构建在训练样本的⾃助抽样集上的,只有约 63.2% 原样本集出现在中,⽽剩余的 36.8% 的数据作为包
外数据,可以⽤于基分类器的验证集。
经验证,包外估计是对集成分类器泛化误差的⽆偏估计.
在随机森林算法中材料集属性的重要性、分类器集强度和分类器间相关性计算都依赖于袋外数据。
包外估计的⽤途
当基学习器是决策树时,可使⽤包外样本来辅助剪枝 ,或⽤于估计决策树中各结点的后验概率以辅助对零训练样
本结点的处理;
当基学习器是神经⽹络时,可使⽤包外样本来辅助早期停⽌以减⼩过拟合 。
随机森林api介绍
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True,
random_state=None, min_samples_split=2)
n_estimators:integer,optional(default = 10)森林⾥的树⽊数量120,200,300,500,800,1200
在利⽤最⼤投票数或平均值来预测之前,你想要建⽴⼦树的数量。
Criterion:string,可选(default =“gini”)
分割特征的测量⽅法
max_depth:integer或None,可选(默认=⽆)
树的最⼤深度 5,8,15,25,30
max_features="auto”,每个决策树的最⼤特征数量
If "auto", then max_features=sqrt(n_features) .
If "sqrt", then max_features=sqrt(n_features) (same as "auto").
If "log2", then max_features=log2(n_features) .
If None, then max_features=n_features .
bootstrap:boolean,optional(default = True)
是否在构建树时使⽤放回抽样
min_samples_split内部节点再划分所需最⼩样本数
这个值限制了⼦树继续划分的条件,假设某节点的样本数少于min_samples_split,则不会继续再尝试选择
最优特征来进⾏划分,默认是2。
如果样本量不⼤,不需要管这个值。如果样本量数量级⾮常⼤,则推荐增⼤这个值。
min_samples_leaf叶⼦节点的最⼩样本数
这个值限制了叶⼦节点最少的样本数,如果某叶⼦节点数⽬⼩于样本数,则会和兄弟节点⼀起被剪枝,
默认是1。
叶是决策树的末端节点。 较⼩的叶⼦使模型更容易捕捉训练数据中的噪声。
⼀般来说,我更偏向于将最⼩叶⼦节点数⽬设置为⼤于50。
min_impurity_split:节点划分最⼩不纯度
这个值限制了决策树的增⻓,假如某节点的不纯度(基于基尼系数,均⽅差)⼩于这个阈值,则该节点不再
⽣成⼦节点。即为叶⼦节点 。
⼀般不推荐改动默认值1e-7。
上⾯决策树参数中最重要的包括
最⼤特征数max_features,
最⼤深度max_depth,
内部节点再划分所需最⼩样本数min_samples_split
叶⼦节点最少样本数min_samples_leaf。
随机森林预测案例
实例化随机森林
# 随机森林去进⾏预测
rf = RandomForestClassifier()
定义超参数的选择列表
param = {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5, 8, 15, 25, 30]}
使⽤GridSearchCV进⾏⽹格搜索
# 超参数调优
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("随机森林预测的准确率为:", gc.score(x_test, y_test))注意
随机森林的建⽴过程
树的深度、树的个数等需要进⾏超参数调优
bagging集成优点
Bagging +决策树/线性回归/逻辑回归/深度学习… = bagging集成学习⽅法
经过上⾯⽅式组成的集成学习⽅法:
1. 均可在原有算法上提⾼约2%左右的泛化正确率
2. 简单, ⽅便, 通⽤
6 ⼩结
bagging集成过程【知道】
1.采样 — 从所有样本⾥⾯,采样⼀部分
2.学习 — 训练弱学习器
3.集成 — 使⽤平权投票
随机森林介绍【知道】
随机森林定义
随机森林 = Bagging + 决策树
流程:
1.随机选取m条数据
2.随机选取k个特征
3.训练决策树
4.重复1-3
5.对上⾯的若决策树进⾏平权投票
注意:
有放回的抽取就是1.随机选取样本,且
2.选取特征的时候吗,选择m<<M
M是所有的特征数
包外估计
假如进⾏有放回的对数据集抽样,会发现,总是有⼀部分样本选不到;
api
sklearn.ensemble.RandomForestClassifier()
Bagging + 决策树/线性回归/逻辑回归/深度学习… = bagging集成学习⽅法【了解】
bagging的优点【了解】
1.均可在原有算法上提⾼约2%左右的泛化正确率
2.简单, ⽅便, 通⽤
bagging集成与boosting集成的区别:
区别⼀:素材⽅⾯
Bagging:对数据进⾏采样训练;
Boosting:根据前⼀轮学习结果调整资料的重要性。
区别⼆:投票⽅⾯
Bagging:所有学习器平权投票;
Boosting:对学习器进⾏加权投票。
区别三:学习顺序
并⾏的,每个学习器没有依赖关系;就是Bagging的学习
Boosting学习是串⾏,学习有先后顺序。
区别四:主要作⽤
Bagging主要⽤于提⾼泛化性能(解决过拟合,也能够说降低⽅差)
Boosting主要⽤于提⾼训练精度 (解决⽋拟合,也行说降低偏差)
AdaBoost介绍
4.1 构造过程细节
步骤⼀:初始化训练数据权重相等,训练第⼀个学习器。
该假设每个训练样本在基分类器的学习中作⽤相同,这⼀假设可以保证第⼀步能够在原始数据上学习基
本分类器H (x)
步骤⼆:AdaBoost反复学习基本分类器,在每⼀轮m = 1, 2, ...,M顺次的执⾏下列操作:
(a) 在权值分布为D 的训练资料上,确定基分类器;
(b) 计算该学习器在训练素材中的错误率:
ε = P(h (x ) ≠ y )
(c) 计算该学习器的投票权重:

将下⼀轮学习器的注意⼒集中在错误数据上
重复执⾏a到d步,m次;
步骤三:对m个学习器进⾏加权投票
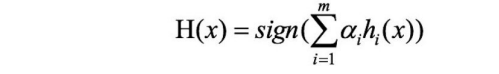
关键点剖析
如何确认投票权重?
如何调整数据分布?