也有论文专门提到金融领域的数据收集
将时序归一化之后离散化的效果会不会好一点(有些关系可以做差分来理解)
数据生成的内容有两个:时间序列和对齐的文本。时间序列的生成不是什么难的事情,所以研究主要集中在生成对齐文本上
现有技术大致可分为三类:Template-based、LLM-based以及Web-crawled
Template-based
这些方法通过将提取的时间序列特征填充到预定义模板中来生成文本描述
语言模型在处理数值数据时有局限性,所以时间序列的生成任务往往更倾向于模板化方法
-
TimeSeriesExam
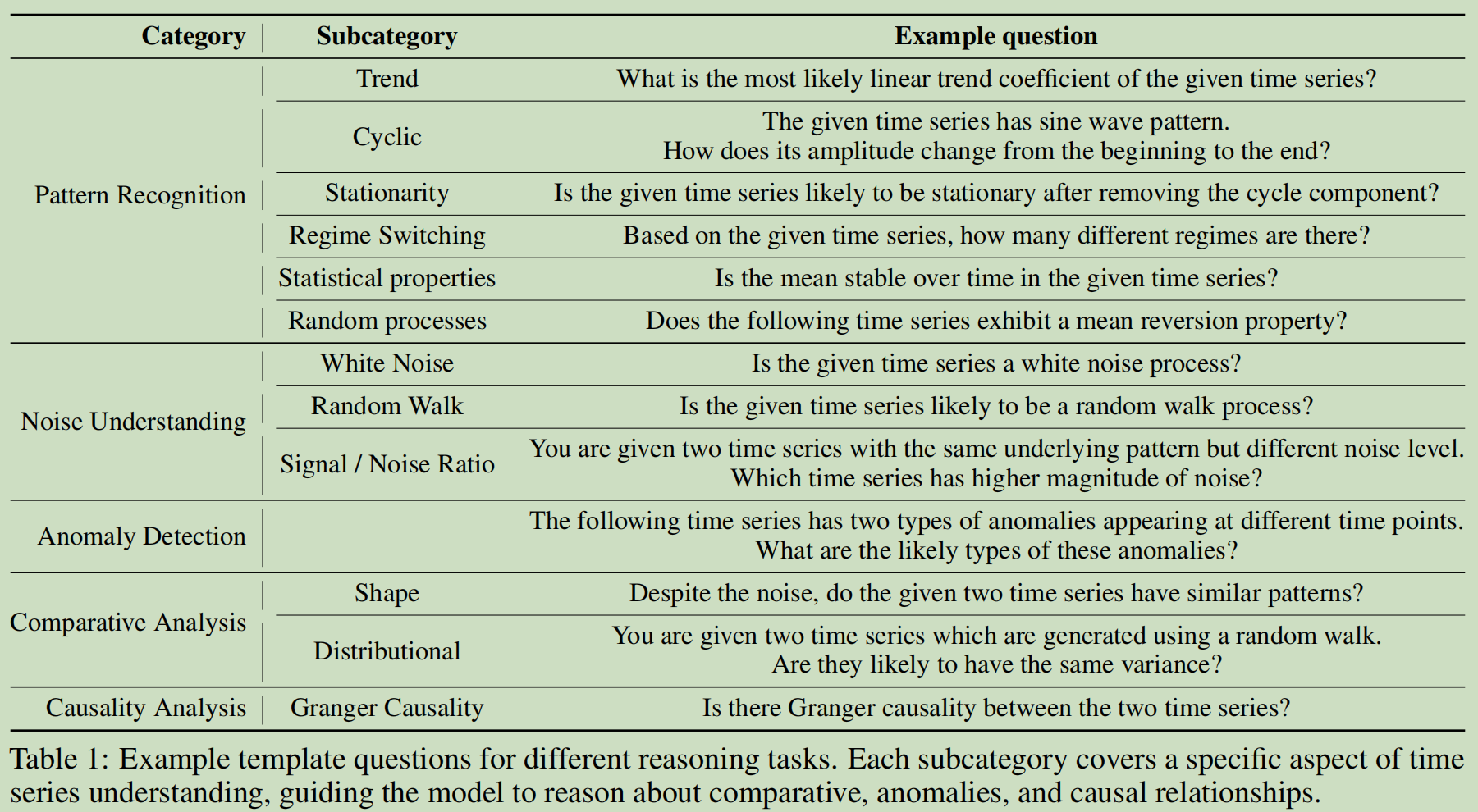
这篇工作创造了一个可拓展,可配置的数据集,主要目的是为了评测LLM理解时间序列基本模式的能力。这里的基本模式指的是:趋势、季节性以及噪声。之所以叫做基本模式,是因为理解一个时间序列还可以通过这个时间序列的来源来加强理解。比如现在知道了这个时间序列是一个心电图的时间序列,肯定比不知道这个时间序列是一个心电图的时间序列更好。而现有的很多工作对LLM的测试都不是只测试的基本能力(比如前面这个例子,假设大模型对时间序列的理解并不好,我们不能判断到底是对时间序列本身理解不好,还是对心电图这个概念不理解)
这篇工作还测试了LLM的推理能力:异常检测(也就是检测时间序列的不平滑的地方)、比较推理(比较两个时间序列的统计属性)以及推测因果关系(Granger Causality)
更具体的分类如下
![image]()
作者于TS专家一起手动创建了100多个模板。问题模板的组成如下- 选择上面提到的一个Category(可加上Subcategory)
- 包含一个问题和这个问题的若干个选项
- 一个QA对的例子,用作上下文学习(但是论文没有举出具体的例子,我也不是很理解这里到底是什么样子)
- 一个提示(类似于CoT)
- 对专业术语的解释(为了测试LLM的基本理解能力)
![image]()
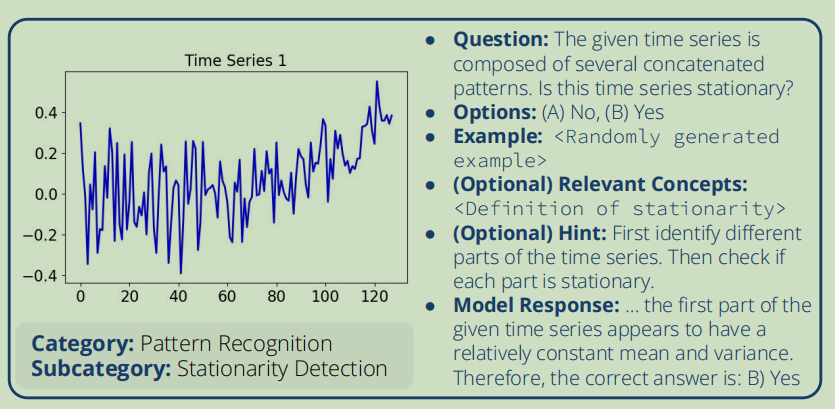
利用模板生成对应的时间序列的步骤:- 随机选择一个模板
- 随机确定这个模板中的正确答案
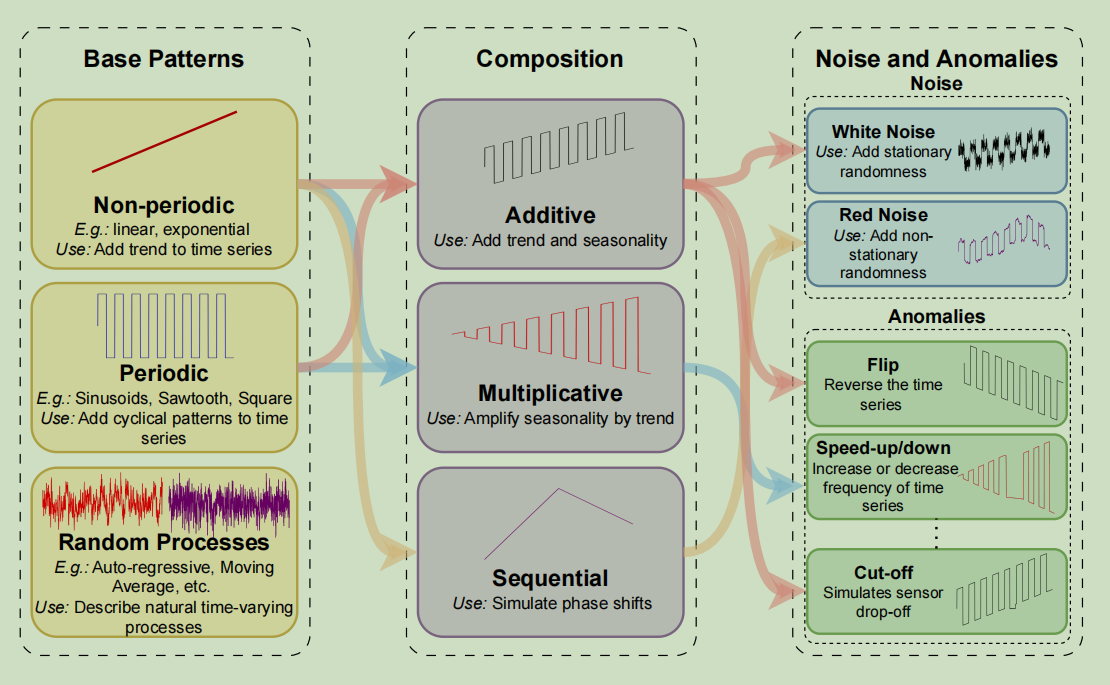
- 从预定义的Base Patterns中采样若干
- 周期性Base Patterns比如正弦函数
- 非周期性Base Patterns比如线性递增函数
- 随机时间变化过程比如自回归过程
- 将采样的Base Patterns进行某种运算来组合
- 添加噪声和异常点(用另一篇论文提到的方法)
![image]()
最后,论文通过一个叫做IRT的技术来对生成的数据进行打分。IRT是考试研究领域里面的一个工具,主要目的是拟合题目的难度、区分度以及参加考试的人的能力这三个变量 -
LLMTime
这篇论文的主要思路是评估LLM是否有预测时序的能力。作者从一些预定义的简单分布中采样,然后让GPT-4做选择题,说这个序列来自哪个分布;当然还用了已有的数据集去测评 -
ChatTime
这篇论文建立了一个文本时序模态输入输出模型。采样的过程:从若干数据集中,设定窗口长度,历史长度,预测长度以及步长进行采样;对应的文本信息的构建比较简单,会给出这个序列的来源以及时间点的信息(比如是星期几),还利用了KernalSynth这个方法 -
Towards Time-Series Reasoning with LLMs
这篇论文认为时序文本大模型要做好,关键有三步:(1) 感知 – 理解并识别时间序列数据中的关键特征。(2) 情境化 – 基于提供的文本上下文提取与任务相关的特征。(3) 演绎推理 – 基于观察得出结论。所以他们训练一个轻量级的时间序列编码器,并在经过思维链推理增强的任务上使用监督微调进行训练
生成数据的方法在附录C里面,但是非常泛泛而谈 -
ChatTS
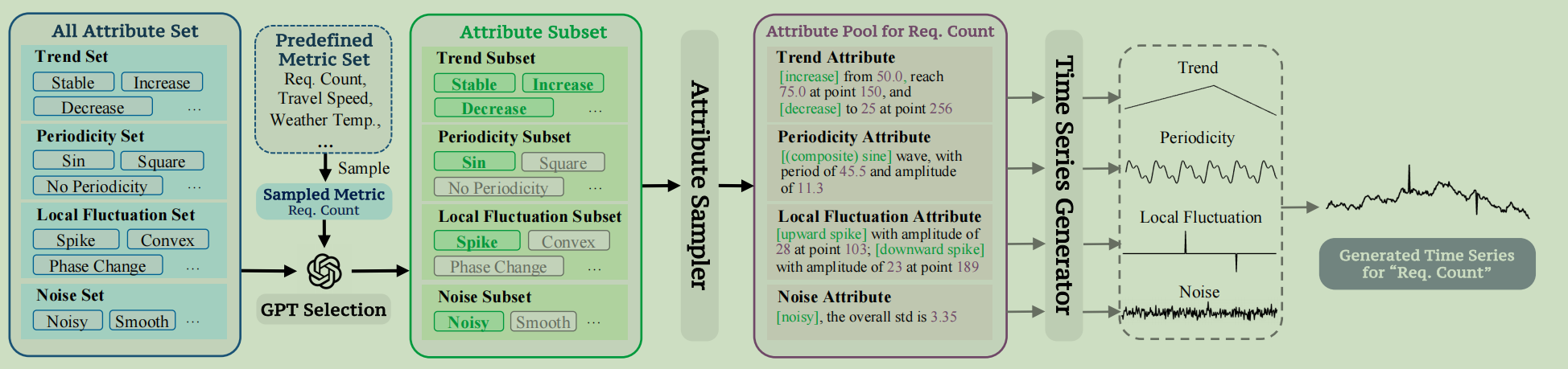
这篇研究提出了基于属性的数据生成的方法,这个样子可以精确地描述合成数据的属性。
作者将时间序列属性分为四个部分:趋势,周期性,噪声和局部波动
生成时序数据的步骤如下:- 定义All Attribute Set
- 四种趋势
- 七种周期性
- 三种噪声
- 十九种局部波动
- 从一个包含567种评估指标的Metric Set中随机选择一个评估指标
- 让GPT根据这个评估指标,从All Attribute Set中选择一个Attribute Subset(同一个属性中,可以选择多个子属性)
- 用Attribute Sampler根据Attribute Subset随机采样一种组合(一个时间序列可以包含多个趋势段和多个局部波动;通过组合正弦波,我们可以生成多种周期性波动模式),把结果存储在Attribute Pool中
- 最后Time Series Generator根据Attribute Pool生成时间序列
![image]()
生成时序文本对监督数据的思想借鉴了Evol-Instruct,叫做TSEvol:- 每次从一个生成的时间序列的Attribute Pool中随机抽取一个子集,加入到已经选择的集合A中
- 选择一个Evol Type,将Evol Type和集合A喂给大模型,让大模型生成QA
- 用一个基于属性的eliminator来保证生成的QA与时序的属性匹配
- 定义All Attribute Set
-
TempoGPT
- 采用白盒电路,观察六个变量(电源电压,电路电压以及电流)构成时间序列。为了模拟异常情况,在特定范围内随机调整了电路内部元件的固有参数(例如修改电压源的最大幅度和负载的电阻值)
- 由于是白盒系统,所以预训练阶段和微调阶段的文本就很容易给出来(有模板)
- 预训练阶段主要是询问关于六个变量的异常情况
- 微调阶段主要是利用CoT测试trend analysis, trend forecast, fault judgment, fault diagnosis, and fault analysis
- 最后有了QA中的Q之后,还可以让GPT拓展一下Q让Q变得更复杂
LLM-based
这些方法通过将TS输入给LLM来让LLM输出文本
-
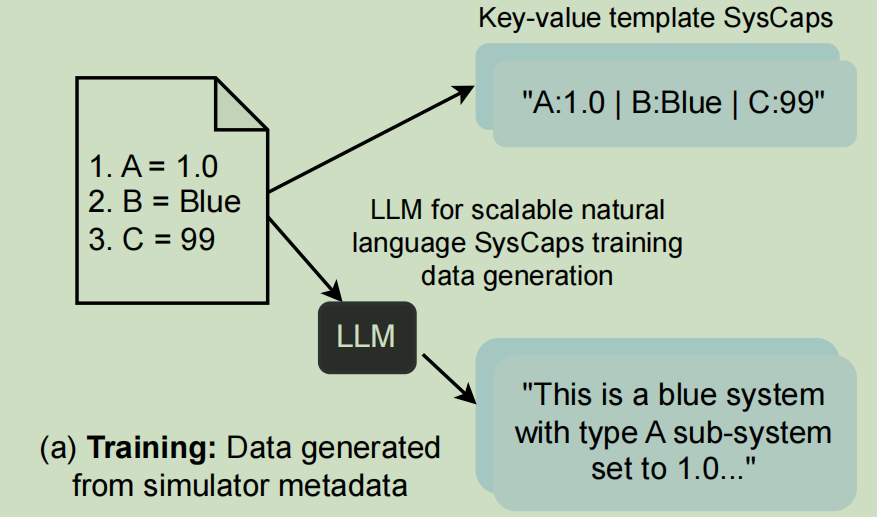
Syscaps
这篇工作已有的数据是结构化数据,利用两种方法将结构化数据转化- 键值对方法:将不同的键值对之间用
|连接 - LLM方法:把结构化数据输入给LLM,让其输出结构化数据的文本描述
![image]()
这篇工作还利用了已有的特征选择方法减少结构化数据的条目 - 键值对方法:将不同的键值对之间用
-
Insight Miner
这篇工作生成与传统的指令微调的数据格式相近的数据,主要询问时序的趋势,周期和残差方面的内容
![image]()
其中\(W_k\)是时序,\(L_k^Q,L_k^A\)是QA
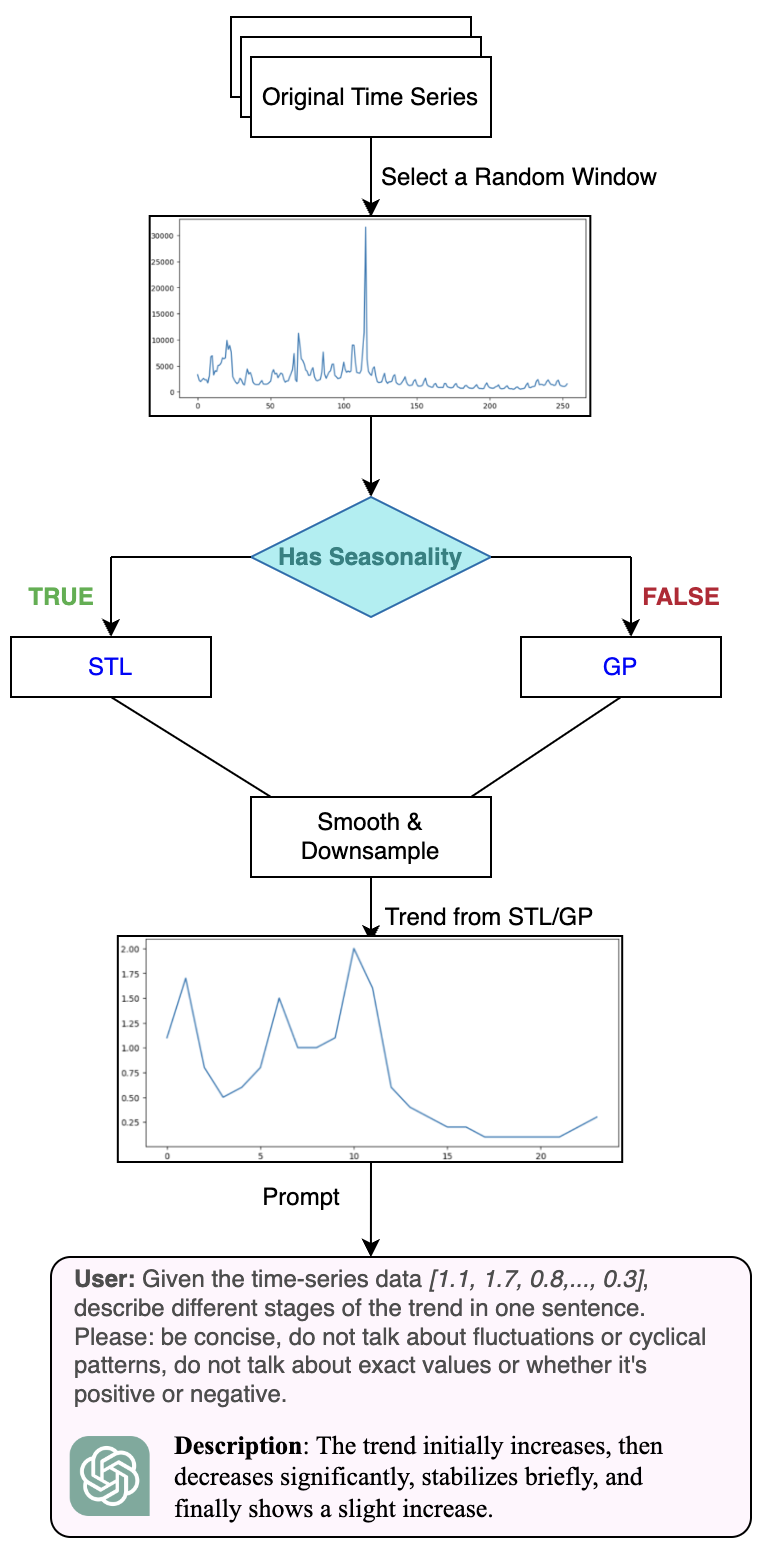
产生这个数据的步骤(以生成询问有关趋势的问题):- 从一个已有的时序数据中随机采样一个窗口
- 判断这个窗口是否有周期性
- 如果有周期性,使用STL Decomposition分解,将时序分解成“趋势+周期+残差”
- 如果没有周期性,使用高斯过程分解
- 进行平滑和下采样(平滑去噪,下采样降低成本)
- 送给GPT-4让其输出
![image]()
在数据产生之后,作者还有如下的后处理: - 周期的粒度不同(比如以天或者周为单位),于是为了适应不同的粒度,将多个时间步进行聚合
- 为了提高数据利用率,对时序或者文本进行修改
- 对时序采用随机增强,使得时序仍然满足对应文本的描述
- 用GPT-3.5-turbo对文本进行近义改写
-
TSLM
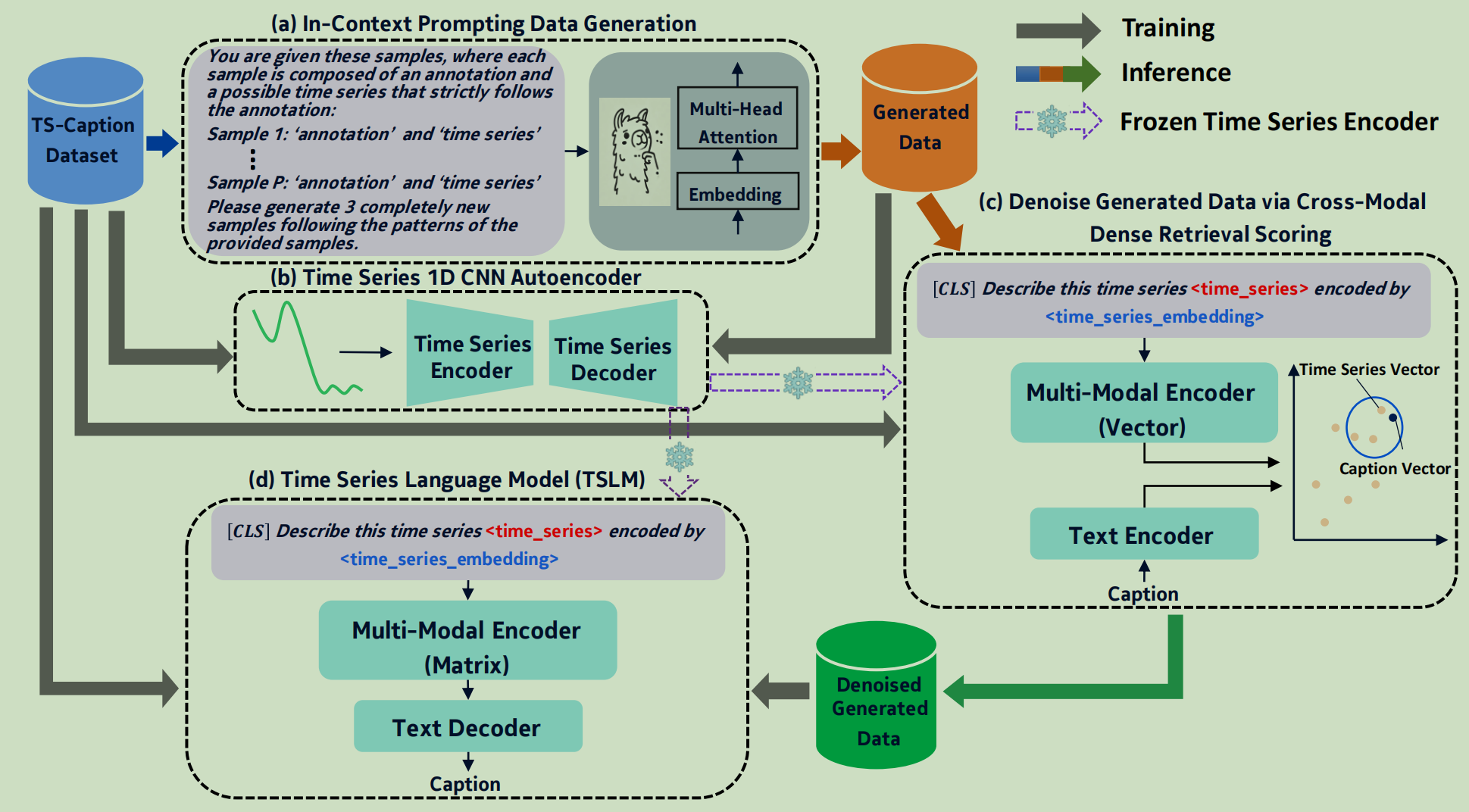
这篇工作在数据生成的贡献就是利用LLM生成时序文本对,然后再训练一个打分器,用来去除LLM生成的时序文本对中的噪声。生成时序文本对的时候,使用了少样本学习,并且利用Python的fuzzywuzzy库将文本相似的样本聚合在一起喂给LLM,可以减少噪声
![image]()
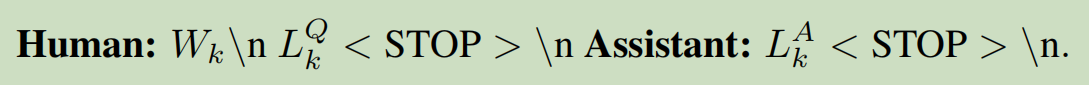
Web-crawled approaches
- Time-MMD
这篇工作就是比较普通的爬虫,但是考虑到的细节很多,很琐碎,有一丢丢新颖的地方还是利用LLM去筛选
提到的三个现有工作的缺陷我觉得挺重要的:(1) 数据领域狭窄。不同领域的数据特征和模式各不相同,例如数值数据的周期性和文本数据的稀疏性。然而,当前的多模态 TS 数据集 [15; 70; 11; 49; 6] 仅专注于金融领域的股票预测任务,无法代表多样化的数据领域。(2) 粗粒度的模态对齐。现有的多模态 TS 数据集仅确保文本和数值数据来自同一领域,例如通用的股票新闻和某只特定股票的价格。显然,大量不相关的文本会降低多模态 TSA 的有效性。(3) 固有的数据污染。现有的多模态 TS 数据集忽视了两个主要的数据污染原因:① 文本数据常常包含预测。例如,流感展望是流感报告中的一个常规部分。② 过时的测试集,特别是其中的文本数据,可能已经暴露于 LLM,而 LLM 是在海量语料库上预训练的。 - GPT4MTS
没啥很新的想法,就是有一个gdeltproject.org项目,上面的数据好像挺多的