MySQL面试题汇总(写了一点,不知道后面有没时间写下去,就当是复习了)
- MySQL面试题汇总(写了一点,不知道后面有没时间写下去,就当是复习了)
- No.1:一条SQL查询语句是如何执行的?
- 你还知道哪些基本架构知识
- 连接器怎么用?
- 你怎么看待长连接?
- 那查询缓存呢?
- 最后一个问题:
- No.2:日志系统:一条SQL更新语句是如何执行的?
- 公司MySQL 可以恢复到半个月内任意一秒的状态,这是怎样做到的呢
- MySQL 里经常说到的 WAL 技术,你知道吗
- 哦哦,那你在说下redo log你还知道什么
- 你从上面的输出知道什么
- Server 层也有自己的日志,是binlog还是redo log。
- 你比如像某天下午两点发现中午十二点有一次误删表,需要找回数据,你会具体怎么做。
- redo log 和 binlog 是两个独立的逻辑,那你和上面回答的redo log什么关系?
- 那么在什么场景下,一天一备份会比一周一备份更有优势呢?或者说,它影响了这个数据库系统的哪个指标?
- No.3:事务隔离:为什么你改了我还看不见?
- 说下 ACID
- 事务隔离是为了处理什么问题?
- 你对事务隔离了解多少
- 你有改过事务隔离级别吗?
- 你会使用长事务吗
- 你平时是怎么启动事务的
- 好。。。。停停停,你说下你是怎么查询长事务的
- 你现在知道了系统里面应该避免长事务,如果你是业务开发负责人同时也是数据库负责人,你会有什么方案来避免出现或者处理这种情况呢?
- 其他东西
------编写于2025年10月6号,作者:“叫我贵祥”
留言:一共几道大题,我希望你可以认真看完并加以学习研磨
No.1:一条SQL查询语句是如何执行的?
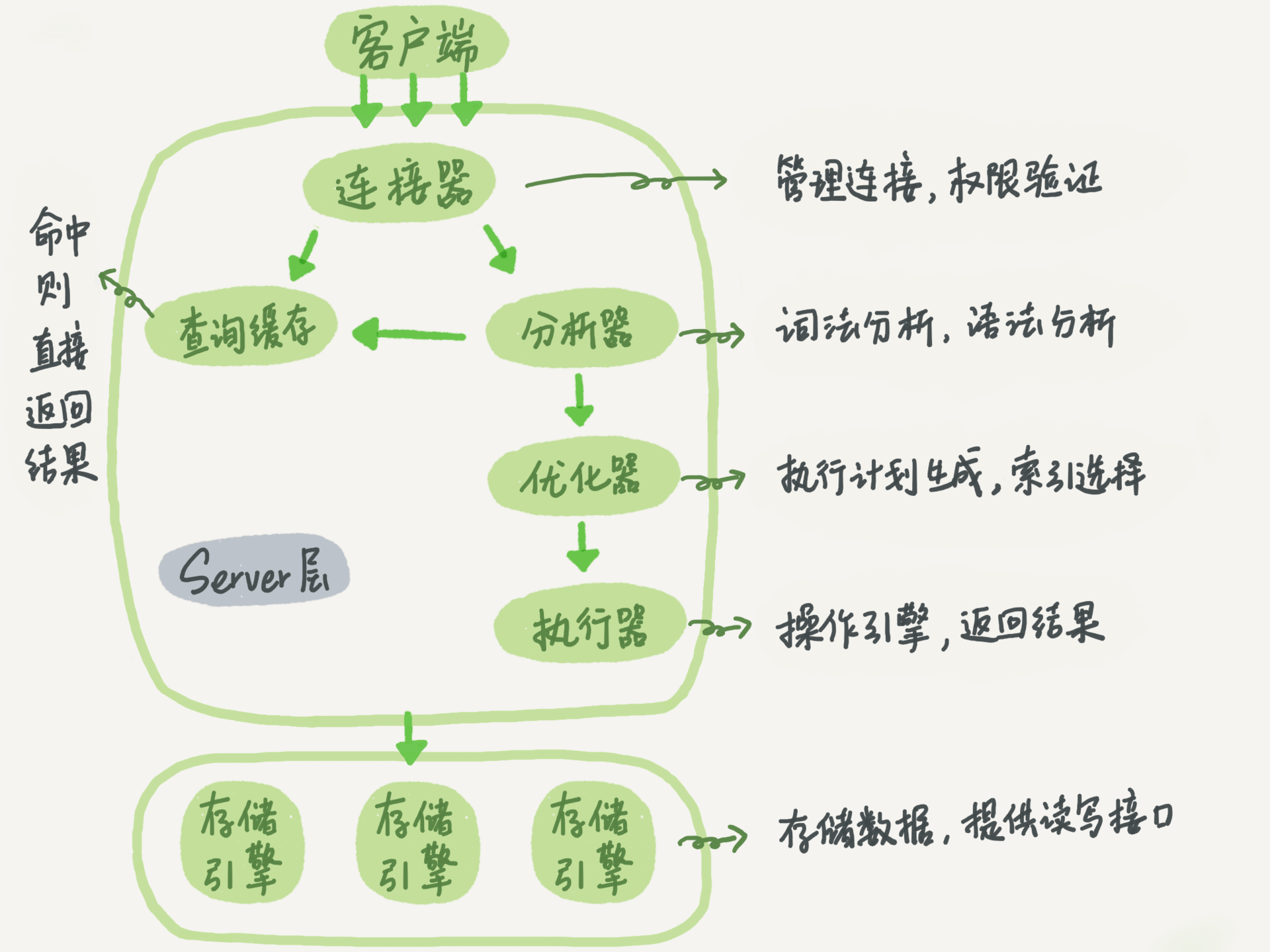
你还知道哪些基本架构知识
最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
可以分为 Server 层和存储引擎层两部分
连接器怎么用?
mysql -h$ip -P$port -u$user -p
你怎么看待长连接?
有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
那查询缓存呢?
查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空,弊大于利。在mysql8.0被弃用了
最后一个问题:
如果表 T 中没有字段 k,而你执行了这个语句 select * from T where k=1, 那肯定是会报“不存在这个列”的错误: “Unknown column ‘k’ in ‘where clause’”。你觉得这个错误是在我们上面提到的哪个阶段报出来的呢?
答案:执行器
No.2:日志系统:一条SQL更新语句是如何执行的?
公司MySQL 可以恢复到半个月内任意一秒的状态,这是怎样做到的呢
redo log(重做日志)和 binlog(归档日志)
MySQL 里经常说到的 WAL 技术,你知道吗
WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘
具体来说,当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做。
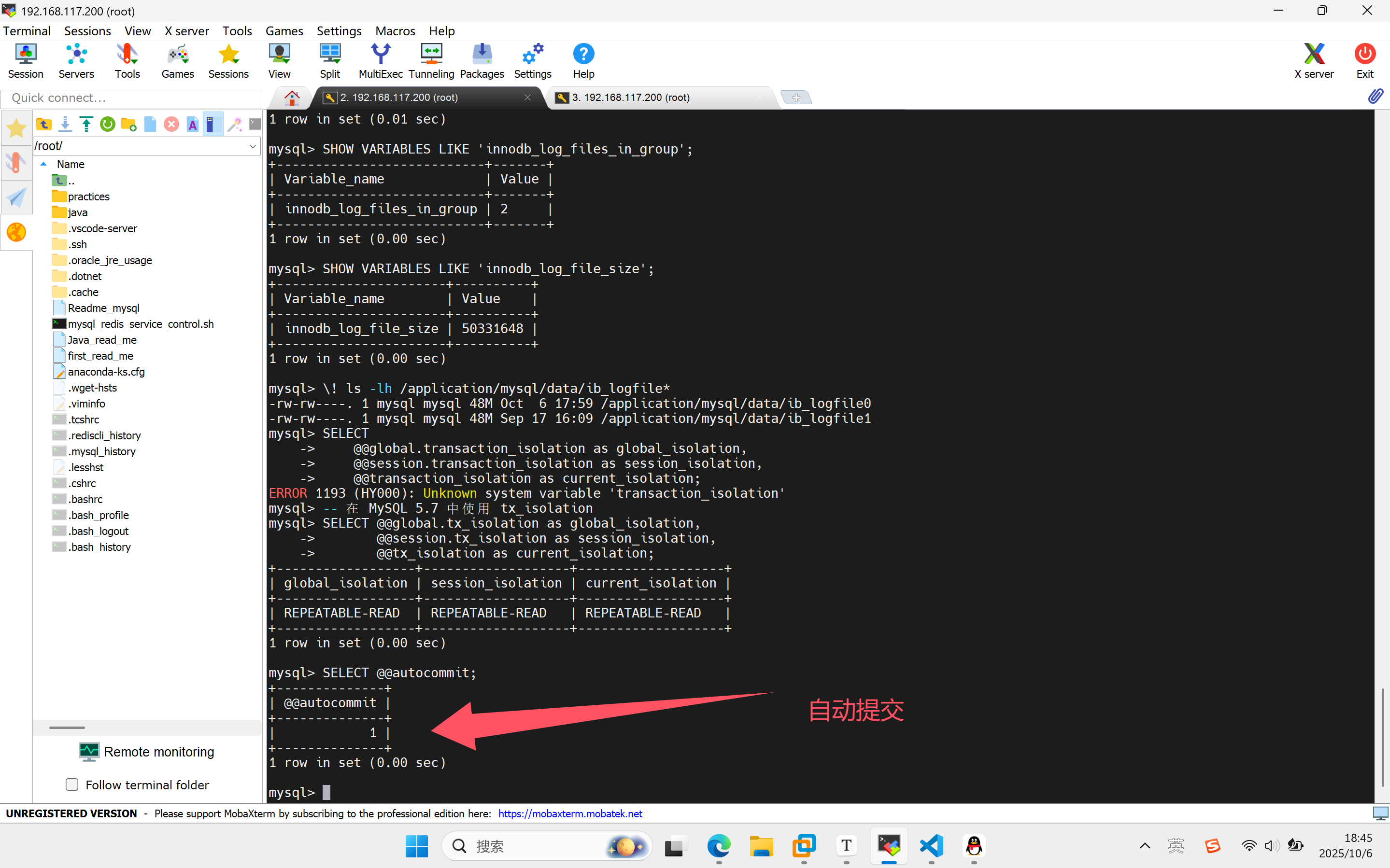
哦哦,那你在说下redo log你还知道什么
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写
-- 查看 redo log 文件位置和大小
SHOW VARIABLES LIKE 'innodb_log_files_in_group';
SHOW VARIABLES LIKE 'innodb_log_file_size';
-- 查看 redo log 使用情况
SHOW ENGINE INNODB STATUS\G
-- 查看数据目录和 redo log 文件位置
SHOW VARIABLES LIKE 'datadir';
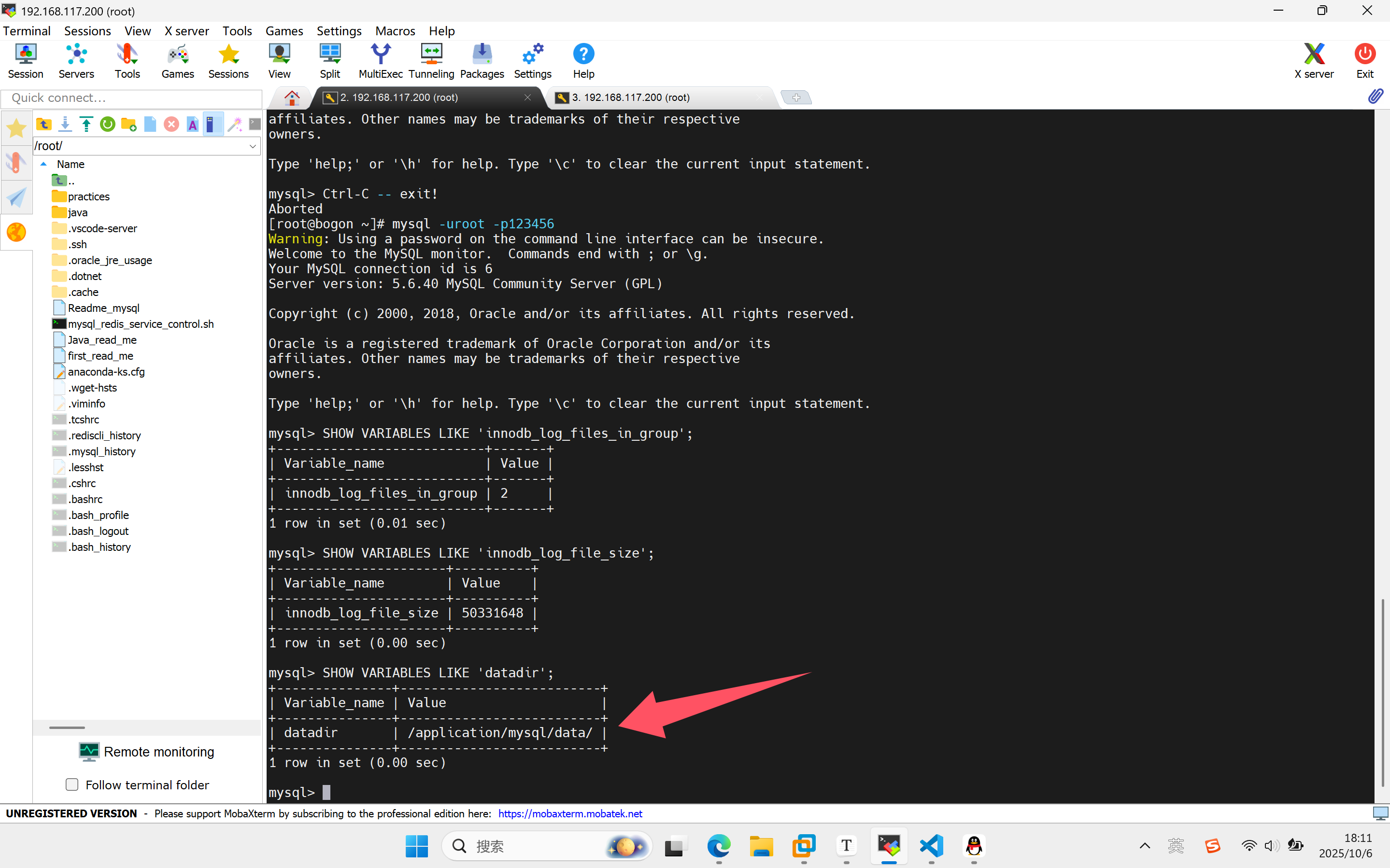
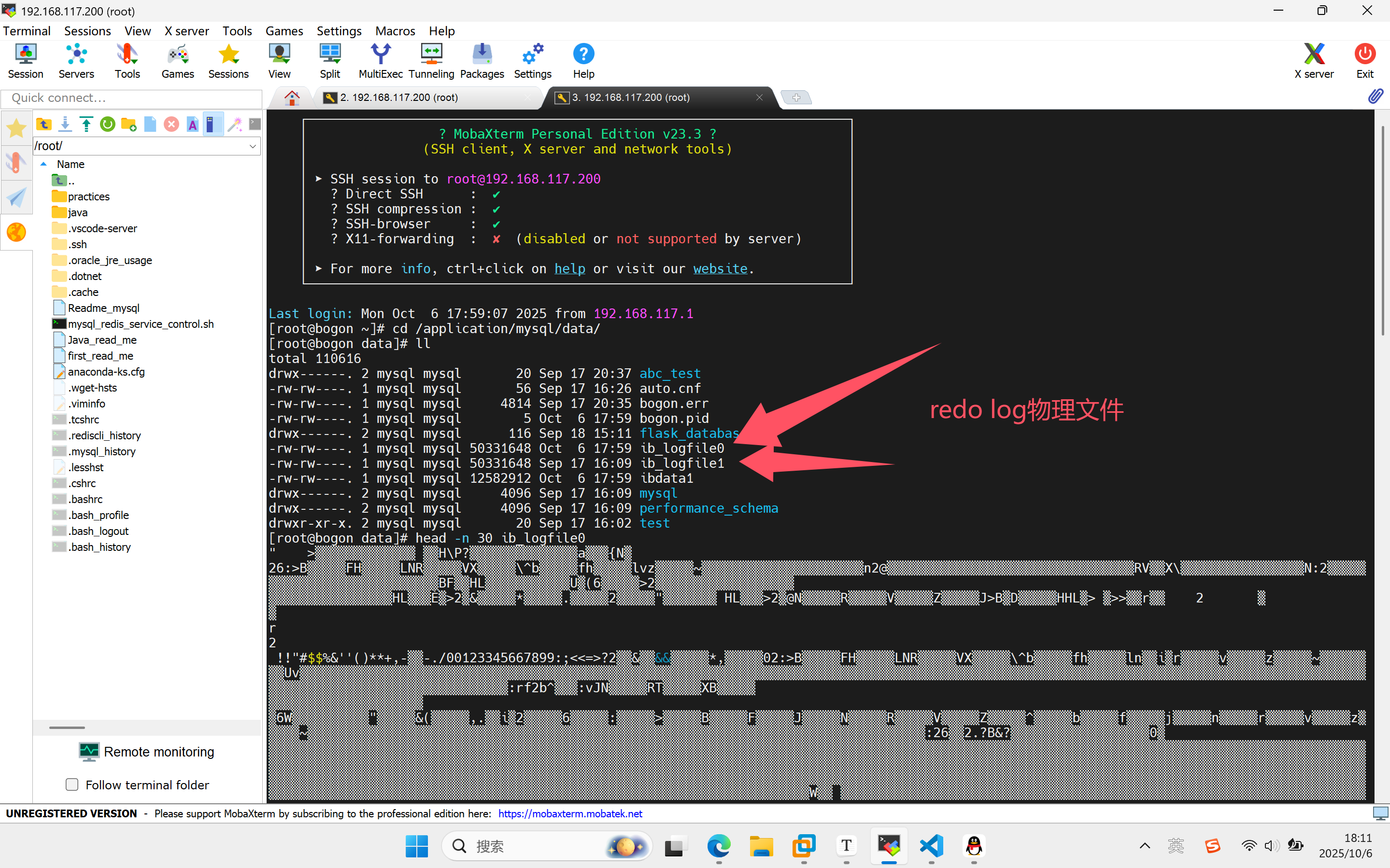
你从上面的输出知道什么
innodb_log_files_in_group = 2 -- 2个redo log文件
innodb_log_file_size = 50331648 -- 每个文件48MB (50331648 bytes)
#总redo log容量 = 2 × 48MB = 96MBib_logfile0: 48M (最近修改: Oct 6)
最近被写入过 - 10月6日有数据写入到这个文件当前活跃文件 - 可能是当前正在写入的redo log文件ib_logfile1: 48M (最近修改: Sep 17)
较久未被写入 - 最后一次修改是9月17日待用文件 - 当前没有被写入,等待轮换使用
Server 层也有自己的日志,是binlog还是redo log。
binlog(归档日志)。
你比如像某天下午两点发现中午十二点有一次误删表,需要找回数据,你会具体怎么做。
首先,找到最近的一次全量备份,如果你运气好,可能就是昨天晚上的一个备份,从这个备份恢复到临时库;然后,从备份的时间点开始,将备份的 binlog 依次取出来,重放到中午误删表之前的那个时刻。
redo log 和 binlog 是两个独立的逻辑,那你和上面回答的redo log什么关系?
两阶段提交知道吧。为了让两份日志之间的逻辑一致,将 redo log 的写入拆成了两个步骤:prepare 和 commit
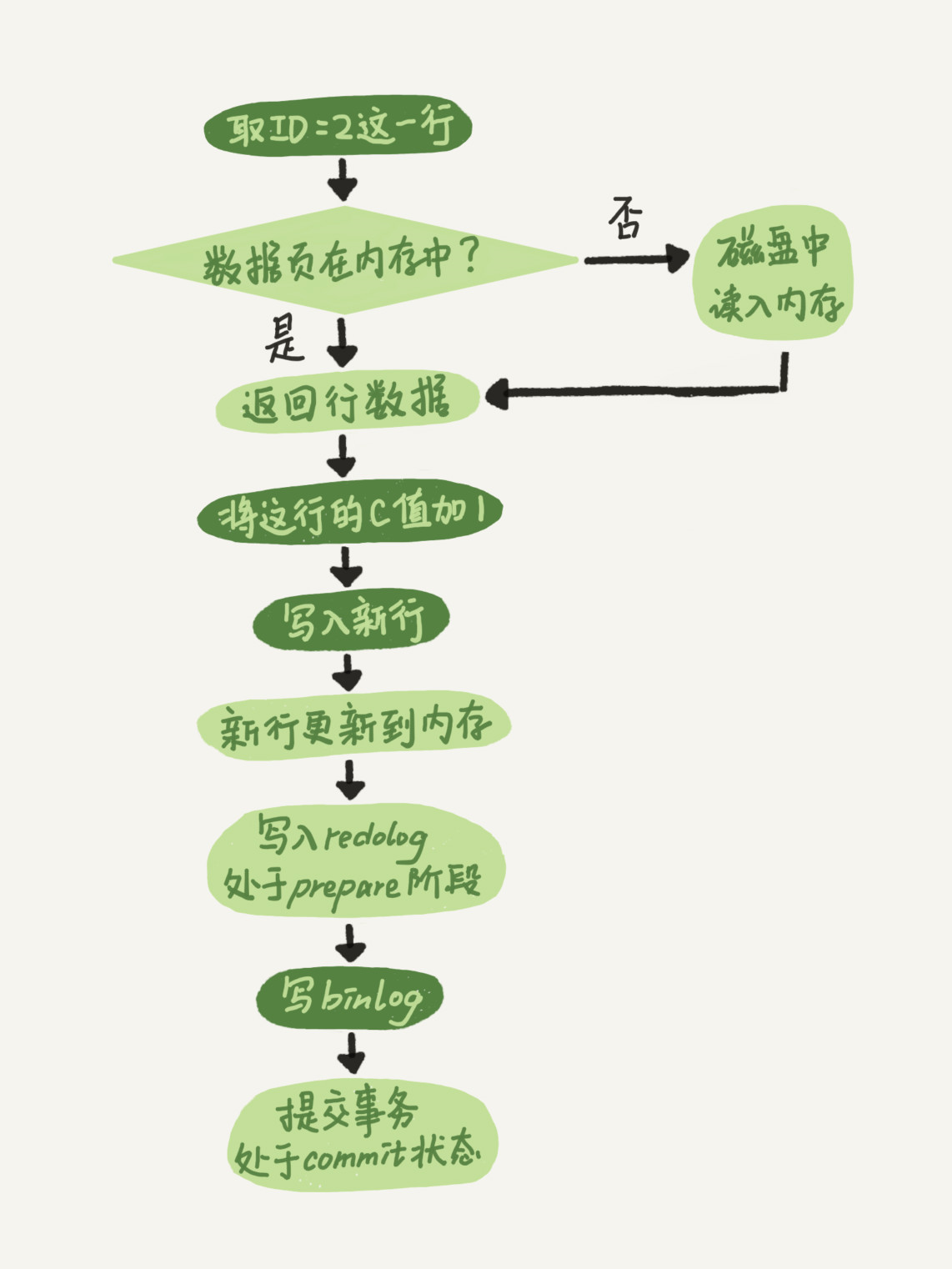
用redo log这是为了让两份日志之间的逻辑一致
如果不使用“两阶段提交”,那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。
那么在什么场景下,一天一备份会比一周一备份更有优势呢?或者说,它影响了这个数据库系统的哪个指标?
发散思维,好好想想,这是我留给你们的课堂作业。
No.3:事务隔离:为什么你改了我还看不见?
说下 ACID
Atomicity、Consistency、Isolation、Durability,即原子性、一致性、隔离性、持久性
事务隔离是为了处理什么问题?
脏读:读到其他事务未提交的数据; 不可重复读:前后读取的记录内容不一致; 幻读:前后读取的记录数量不一致。
你对事务隔离了解多少
读未提交是指,读提交,可重复读,串行化
你有改过事务隔离级别吗?
#查看全局隔离级别:
SHOW GLOBAL VARIABLES LIKE 'transaction_isolation';
#查看会话隔离级别:
SHOW SESSION VARIABLES LIKE 'transaction_isolation';
#查看当前连接的隔离级别:
SELECT @@transaction_isolation;#我是记下面的-- 查看全局和会话级别
SELECT @@global.transaction_isolation as global_isolation,@@session.transaction_isolation as session_isolation,@@transaction_isolation as current_isolation;
#修改事务隔离级别-- 临时修改当前会话
SET SESSION tx_isolation = 'READ-COMMITTED';-- 验证修改
SELECT @@tx_isolation;
注意:
| 版本 | 变量名 | 示例 |
|---|---|---|
| MySQL 5.7 及之前 | tx_isolation |
SET tx_isolation = 'READ-COMMITTED' |
| MySQL 8.0 及之后 | transaction_isolation |
SET transaction_isolation = 'READ-COMMITTED' |
你会使用长事务吗
不会:长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占用存储空间。
除了对回滚段的影响,长事务还占用锁资源,也可能拖垮整个库,
你平时是怎么启动事务的
显式启动事务语句, begin 或 start transaction。配套的提交语句是 commit,回滚语句是 rollback。
有时候我会set autocommit=0,会将这个线程的自动提交关掉。只执行一个 select 语句,这个事务就启动了,而且并不会自动提交。这个事务持续存在直到你主动执行 commit 或 rollback 语句,或者断开连接。
-- 查看当前autocommit设置
SELECT @@autocommit;
-- 设置不自动提交
SET autocommit = 0;
给你举个例子吧
-- 方法1:使用 BEGIN
BEGIN;
UPDATE account SET balance = balance + 100 WHERE name = '李四';
SELECT * FROM account WHERE name = '李四'; -- 查看修改
ROLLBACK; -- 回滚,修改取消-- 方法2:使用 START TRANSACTION
START TRANSACTION;
UPDATE account SET balance = balance + 200 WHERE name = '李四';
SELECT * FROM account WHERE name = '李四'; -- 查看修改
COMMIT; -- 提交,修改生效-- 设置不自动提交
SET autocommit = 0;-- 隐式事务开始
UPDATE account SET balance = 1500 WHERE name = '张三';-- 显式开始新事务(会提交之前的隐式事务)
START TRANSACTION;
UPDATE account SET balance = 1800 WHERE name = '李四';-- 此时两个更新都在未提交状态
-- 可以选择提交或回滚
COMMIT; -- 两个更新都提交
好。。。。停停停,你说下你是怎么查询长事务的
在 information_schema 库的 innodb_trx 这个表中查询
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
你现在知道了系统里面应该避免长事务,如果你是业务开发负责人同时也是数据库负责人,你会有什么方案来避免出现或者处理这种情况呢?
读者也要留有现象的空间,自行思考
其他东西
1. 查看当前死锁相关参数
sql
-- 查看死锁检测设置
SHOW VARIABLES LIKE 'innodb_deadlock_detect';-- 查看锁等待超时时间
SHOW VARIABLES LIKE 'innodb_lock_wait_timeout';-- 查看所有与锁相关的参数
SHOW VARIABLES LIKE '%lock%';
2. 设置死锁检测参数
临时设置(重启后失效)
sql
-- 开启死锁检测(默认通常是开启的)
SET GLOBAL innodb_deadlock_detect = ON;-- 关闭死锁检测
SET GLOBAL innodb_deadlock_detect = OFF;-- 设置锁等待超时时间(单位:秒)
SET GLOBAL innodb_lock_wait_timeout = 50;-- 对当前会话设置
SET SESSION innodb_lock_wait_timeout = 30;
永久设置(修改配置文件)
编辑MySQL配置文件 my.cnf 或 my.ini:ini[mysqld]
# 开启死锁检测(默认ON)
innodb_deadlock_detect = ON# 设置锁等待超时时间为50秒(默认50)
innodb_lock_wait_timeout = 50
然后重启MySQL服务:bashsystemctl restart mysql
死锁经典图

事务 A 和事务 B 在互相等待对方的资源释放,就是进入了死锁状态
死锁检测:每个新来的被堵住的线程,都要判断会不会由于自己的加入导致了死锁,这是一个时间复杂度是 O(n) 的操作。假设有 1000 个并发线程要同时更新同一行,那么死锁检测操作就是 100 万这个量级的。虽然最终检测的结果是没有死锁,但是这期间要消耗大量的 CPU 资源。因此,你就会看到 CPU 利用率很高,但是每秒却执行不了几个事务。
两阶段锁协议:在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
1.