问题复现
环境
- influxdb 1.8
- 单节点,8C 32G
- 基于docker compose部署,通过grafana + telegraf监控influxdb性能cpu和负载指标
- docker compose安装参考其他资料
模拟查询
通过Python脚本,查询influx数据
import requests, threadingdef query():while True:requests.get("http://localhost:8086/query", params={"db": "telegraf","q": "SELECT mean(usage_system) FROM cpu WHERE time > now() - 1h GROUP BY time(1s)"})for _ in range(50):threading.Thread(target=query).start()
- 当使用脚本运行的过程中,CPU飙升到80%
- 在停止脚步后,CPU恢复正常
![image]()
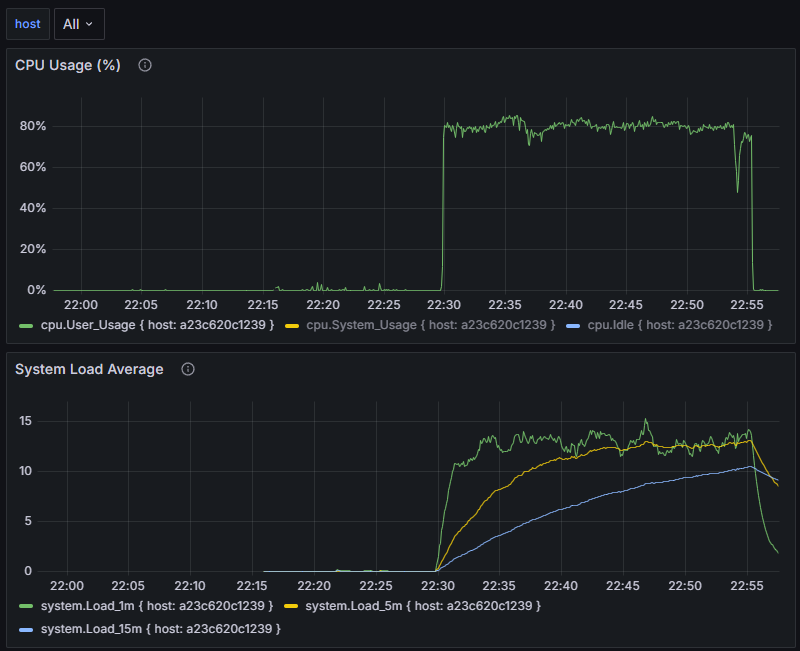
问题分析
InfluxDB 的查询引擎是 CPU 密集型的
InfluxDB 在执行聚合、过滤、分组等查询时,会:
- 从 TSM 文件读取大量数据块;
- 解压、反序列化;
- 在内存中计算聚合;
- 再返回结果。
当并发查询量大时,多个查询任务会争夺 CPU 核心,导致:
- 查询线程大量占用 CPU;
- 后台写入(tsm compaction、wal flush)得不到 CPU 时间;
- 写入延迟、超时,甚至 write failed: timeout。
查询与写入共享资源(CPU、IO、内存)
InfluxDB 的写入路径包括:
- 接收数据(HTTP/TCP)
- 写 WAL(Write Ahead Log)
- 刷新到 TSM 文件
当查询压力大时:
- IO 瓶颈被查询占用;
- 缓存写不进去,积压在内存;
- 后台 flush 线程被延迟。
解决方案
自建读写分离:
- 一主(负责写入)
- 多从(通过 influx-relay 或 replication)负责查询;
- 查询走从节点,主节点仅负责写入。
InfluxRelay 实现写入复制
InfluxRelay 是由 InfluxData 官方早期提供的一个轻量级代理,用于:
- 接收写入请求;
- 同步转发到多个后端 InfluxDB 实例。
✅ 优点:
- 简单、易实现;
- 数据强一致;
- 可水平扩展查询节点。
⚠️ 缺点:
- 所有节点存储冗余;
- relay 不会自动重试部分失败;
- 没有真正的异步复制或延迟写保护。
使用中间缓存层(Telegraf + Kafka + 多 InfluxDB)
- 所有写入先进入 Kafka;
- Telegraf Consumer 从 Kafka 读取并写入多个 InfluxDB;
- 主 InfluxDB 负责写;
- 从 InfluxDB 用于查询。
其他资料
docker环境安装
# 切换到清华源
sudo yum-config-manager --add-repo https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/docker-ce.repo# 清理缓存并安装
sudo yum clean all
sudo yum makecache# 安装
sudo yum install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin# 配置docker源
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.1panel.live",
"https://docker.1ms.run",
"https://docker.xuanyuan.me",
"https://docker.m.daocloud.io",
"https://mirror.ccs.tencentyun.com"
]
}
EOF# 重启docker
sudo systemctl daemon-reload
sudo systemctl restart docker
环境部署
docker-compose.yaml文件
version: "3.8"services:influxdb:image: influxdb:1.8container_name: influxdb_singlerestart: alwaysports:- "8086:8086"environment:- INFLUXDB_DB=telegraf- INFLUXDB_HTTP_AUTH_ENABLED=falsevolumes:- ./data/influxdb:/var/lib/influxdbtelegraf:image: telegraf:1.29container_name: telegrafdepends_on:- influxdbvolumes:- ./telegraf_single.conf:/etc/telegraf/telegraf.conf:ro- /var/run/docker.sock:/var/run/docker.sockgrafana:image: grafana/grafana:10.4.2container_name: grafanadepends_on:- influxdbports:- "3000:3000"
telegraf_single.conf文件
[agent]interval = "5s" # 采集间隔round_interval = true # 对齐采集时间到间隔边界metric_batch_size = 1000 # 批量发送的指标数量metric_buffer_limit = 10000 # 指标缓冲区大小collection_jitter = "0s" # 采集抖动时间flush_interval = "10s" # 刷新(写入)间隔flush_jitter = "0s" # 刷新抖动时间utc = true[[outputs.influxdb]]urls = ["http://influxdb:8086"] # InfluxDB 容器地址(同一网络可用服务名)database = "telegraf" # 目标数据库名retention_policy = "" # 保留策略(默认即可)write_consistency = "any" # 写入一致性级别timeout = "5s" # 超时时间username = "" # 你的配置中未启用认证,留空password = "" # 同上# 输入插件(保持你的配置,确保启用)
[[inputs.cpu]]percpu = truetotalcpu = truecollect_cpu_time = falsereport_active = false[[inputs.mem]][[inputs.disk]]mount_points = ["/"] # 监控根目录磁盘[[inputs.net]]interfaces = ["eth0", "lo"] # 监控常用网络接口
[[inputs.system]]
grafana配置
新建dashboard,面板sql
- 配置host变量(用于后面多host监控)
SHOW TAG VALUES FROM cpu WITH KEY = host
- 配置可视化
-- CPU
SELECT mean(usage_user) AS User_Usage, mean(usage_system) AS System_Usage, mean(usage_idle) AS Idle
FROM cpu
WHERE ("host" =~ /^$host$/ AND cpu='cpu-total') AND $timeFilter
GROUP BY time($__interval), host-- LOAD
SELECT mean(load1) AS Load_1m, mean(load5) AS Load_5m, mean(load15) AS Load_15m
FROM system
WHERE "host" =~ /^$host$/ AND $timeFilter
GROUP BY time($__interval), host