详细介绍:Transformer学习记录与CNN思考
Transformer学习与CNN思考
文章目录
- Transformer学习与CNN思考
- 1 结构
- 2 Transformer输入
- 2.1 Embedding(嵌入)
- 2.2 位置编码
- 2 编码
- 2.1 注意力机制
- 2.1.1 注意力机制运行原理
- 2.1.2 注意力函数(注意力汇聚实现方式)
- 2.1.3 注意评分函数
- 2.1.4 例子
- 2.1.5 多头注意力
- 2.2 Add & Norm
- 2.3 Feed Forward
- 2.4 encode block
- 3 解码
- 3.1 decode block
- 3.2 第一个Multi-Head Attention
- 3.2 第二个Multi-Head Attention
- 4 Transformer输出
- 5 CNN vs Transformer
- 6 关于CNN思考
- 参考
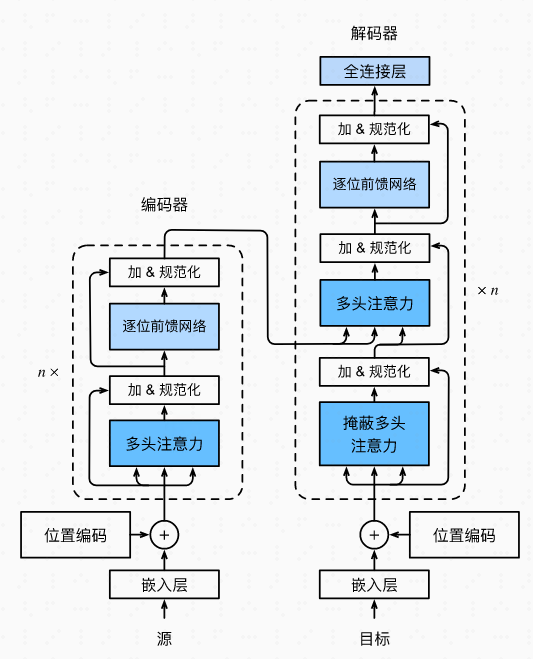
1 结构
标准的 Transformer 模型主要由两个模块构成: Encoder(左边):负责理解输入文本,为每个输入构造对应的语义表示(语义特征); Decoder(右边):负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列。
纯 Encoder 模型(例如 BERT),又称自编码模型,适用于只需要理解输入语义的任务,例如句子分类、命名实体识别;纯 Decoder 模型(例如 GPT),又称自回归模型,适用于生成式任务,例如文本生成;Encoder-Decoder 模型(例如 BART、T5),又称 Seq2Seq 模型。适用于需要基于输入的生成式任务,例如翻译、摘要。
如何区分这个编码–解码器
| 特征 | 编码器(Encoder) | 解码器(Decoder) |
|---|---|---|
| 自-attention | 有,且通常允许全向上下文关注(如图像中所有位置互相关) | 有,但常使用因果掩码(causal mask),防止“看未来” |
| Cross-attention | 无 | ✅ 有,用于关注编码器输出的特征 |
| 输入来源 | 原始输入(如图像、文本) | 上一时刻的输出 + 编码器的上下文特征 |
| 层数堆叠 | 多层自-attention 提升特征提取能力 | 多层自-attention + cross-attention,逐步生成输出 |
关键点:Cross-attention 是解码器的标志性结构。如果某模块明确使用 query 去“查询”另一个特征序列(如图像特征图、历史BEV特征),那就是在做解码任务。
Transformer是一种自监督学习。自监督学习(Self-Supervised Learning, SSL)将无监督学习的框架与监督学习的目标结合,借助从数据本身自动生成标签(无需人工标注),学习通用的数据表示。
2 Transformer输入
2.1 Embedding(嵌入)
Embedding(嵌入)是机器学习和深度学习中的核心概念,指将高维、离散或复杂的数据(如文字、图像、类别等)转换为低维、连续的数值向量表示的过程。这种表示能保留原始数据的语义或结构信息,便于计算机处理。
类似序列化数据的过程,像protobuf一样,把数据打包成计算机认识的模样。但Embedding核心价值在于保留语义关系。例如,在词嵌入中,"猫"和"狗"的向量距离会比"猫"和"汽车"更近。Protobuf等序列化工具的目标是无损还原数据,而Embedding是有损转换——它更注重保留资料间的潜在关系(如语义相似性),而非精确存储原始信息。
除此,Embedding通常是通过模型动态学习得到的,而非静态的编码规则。对于文本输入,Embedding就是用BERT这种,如果是图像输入,可以利用Resnet网络提取特征向量
1. 文本Embedding(如BERT)
- 输入:离散的单词序列(如"深度学习")
- 处理方式:
- 通过
Transformer网络学习上下文感知的表示 - 输出固定长度的向量(如768维),其中相近语义的文本向量距离更近
- 例如:
"猫"和"喵星人"的向量余弦相似度会很高
- 通过
2. 图像Embedding(如ResNet)
- 输入:高维像素矩阵(如
224x224x3的图片) - 处理方式:
- 用
CNN的卷积层逐级提取局部特征(边缘→纹理→物体部件) - 最终通过全局池化得到紧凑向量(如
2048维) - 例如:不同角度的猫图片会映射到向量空间的邻近区域
- 用
2.2 位置编码
对于文本序列
显式地告诉模型每个 token(或像素/点)在序列中的位置,使 Transformer 能够建模顺序关系。
p i , 2 j = sin ( i 1000 0 2 j / d ) , p i , 2 j + 1 = cos ( i 1000 0 2 j / d ) . \begin{align*} p_{i,2j} &= \sin\left(\frac{i}{10000^{2j/d}}\right), \\ p_{i,2j+1} &= \cos\left(\frac{i}{10000^{2j/d}}\right). \end{align*}pi,2jpi,2j+1=sin(100002j/di),=cos(100002j/di).
对于图像序列,
CNN不需要显式位置编码,如
- 操作:
将CNN输出的特征图(假设为H×W×D)展平为(H×W)×D的序列,每个空间位置(共H×W个)对应一个可学习的嵌入向量(类似BERT的[POS]token)。 - 例子:
Vision Transformer(ViT)将图像分块为16×16的patch,每个patch视为一个"词",并添加可学习的位置编码。
2 编码
2.1 注意力机制
2.1.1 注意力机制运行原理
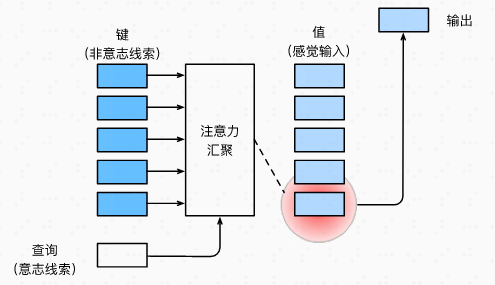
首先声明几个名词,用来描述人类的注意力行为,自主性提示是人主动意识,而非自主性提示是非主观意识
查询
query:自主性提示键
key:非自主性提示值
value:感官输入
注意力机制的框架如下图所示,注意力机制通过注意力汇聚 将 查询query和键key结合在一起,实现对 值 的选择倾向。注意力汇聚就是用神经网络表征选择倾向这一行为的过程。
2.1.2 注意力函数(注意力汇聚实现方式)
下图展示整个注意力函数过程:
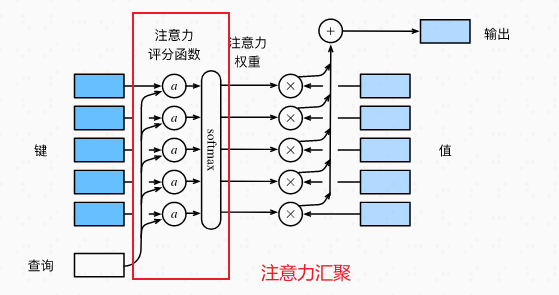
“”注意力机制通过注意力汇聚 将查询query和键key结合在一起,实现对值value的选择倾向。“”----这一过程可以用注意力函数表示:
f ( q , ( k 1 , v 1 ) , … , ( k m , v m ) ) = ∑ i = 1 m α ( q , k i ) v i ∈ R u , f(\mathbf{q}, (\mathbf{k}_1, \mathbf{v}_1), \ldots, (\mathbf{k}_m, \mathbf{v}_m)) = \sum_{i=1}^{m} \alpha(\mathbf{q}, \mathbf{k}_i) \mathbf{v}_i \in \mathbb{R}^u,f(q,(k1,v1),…,(km,vm))=i=1∑mα(q,ki)vi∈Ru,
注意力函数的本质就是对值value的加权和!注意力汇聚通过 注意力评分函数a ( q , k i ) a(q,k_{i})a(q,ki) + softmax 组成,汇聚query和key,生成对应值value的注意力权重,如图中红色框选部分。权重公式如下:
α ( q , k i ) = softmax ( a ( q , k i ) ) = exp ( a ( q , k i ) ) ∑ j = 1 m exp ( a ( q , k j ) ) ∈ R . \alpha(\mathbf{q}, \mathbf{k}_i) = \text{softmax}(a(\mathbf{q}, \mathbf{k}_i)) = \frac{\exp(a(\mathbf{q}, \mathbf{k}_i))}{\sum_{j=1}^{m} \exp(a(\mathbf{q}, \mathbf{k}_j))} \in \mathbb{R}.α(q,ki)=softmax(a(q,ki))=∑j=1mexp(a(q,kj))exp(a(q,ki))∈R.
补充:
softmax公式
y ^ = softmax ( o ) 其中 y ^ j = exp ( o j ) ∑ k exp ( o k ) \hat{y} = \text{softmax}(\mathbf{o}) \quad \text{其中} \quad \hat{y}_j = \frac{\exp(o_j)}{\sum_{k} \exp(o_k)}y^=softmax(o)其中y^j=∑kexp(ok)exp(oj)
2.1.3 注意评分函数
使用点积得到计算效率更高的评分函数,但是点积操作要求查询query和键value具有相同的长度d。
a ( q , k ) = q ⊤ k / d . a(\mathbf{q}, \mathbf{k}) = \mathbf{q}^\top \mathbf{k} / \sqrt{d}.a(q,k)=q⊤k/d.
softmax ( Q K ⊤ d ) V ∈ R n × v . \text{softmax}\left(\frac{\mathbf{QK}^\top}{\sqrt{d}}\right)\mathbf{V} \in \mathbb{R}^{n \times v}.softmax(dQK⊤)V∈Rn×v.
2.1.4 例子
注意力就是不同位置之间关联有多紧密的权重。两个向量点积,模的最大值产生于向量夹角为0。也就是说,如果两个word意义相近,embedding向量也就相近,那自然注意力就大。这是最简单的一种情况,不用考虑位置向量。
原始论文中图示-----缩放的点积注意力机制
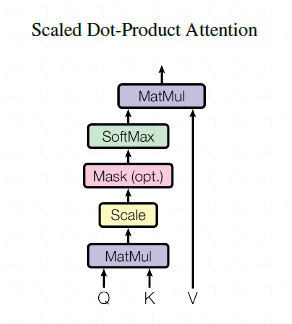
①
Q,K,V是由原始输入经过Embedding(嵌入)以及位置编码后,成为一个行向量x,长度为d,然后x乘以相应的权重得到的。注意,X,Q,K,V每一行都代表一个单词,或者说特征。
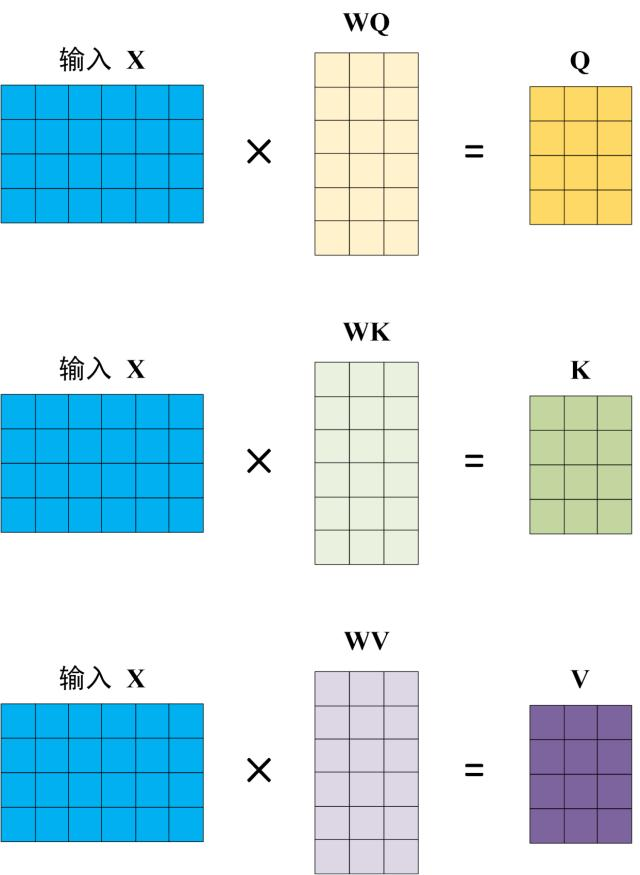
通过② 继而,大家就能够基于上面提到的注意力函数实现注意力机制!
首先计算注意力得分,基于2.3节公式,公式中计算矩阵Q和K每一行向量的内积,同时为了防止内积过大,会除以向量长度d的平方根。得到的这个矩阵维度都是n,n就是单词数量(特征数量),也就是说,这个矩阵表示了单词之间的
attention强度!(相关联度)
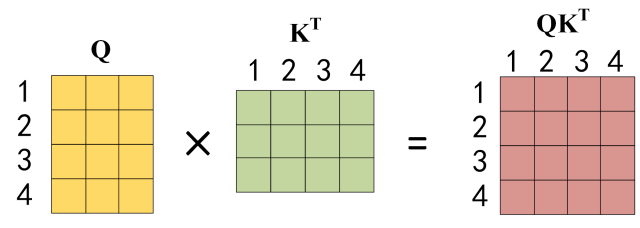
③ 对每一行向量进行
softmax计算,即每一行总和都为1
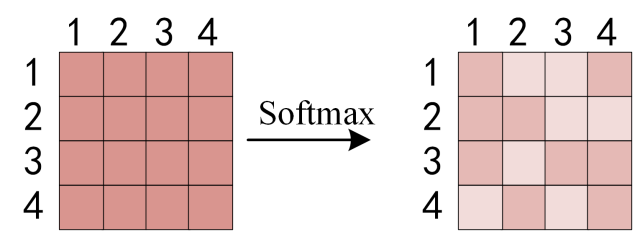
④ 与值
value相乘,得到输出Z
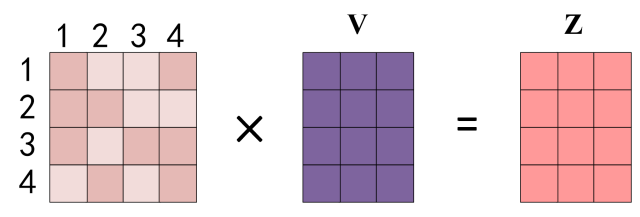
而且,
Z每一行可以拆分如下,单词1的输出Z 1 Z_{1}Z1等于所有单词i的值V i V_{i}Vi根据attention的系数比例加在一起。
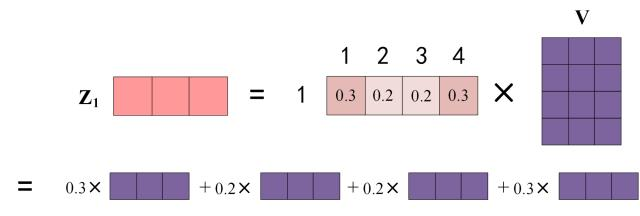
2.1.5 多头注意力
多头注意力其实就是给定相同的
Q、K、V时,基于相同的注意力机制学习到不同的行为,然后把不同的行为线性组合,捕获序列内各种范围的依赖关系。
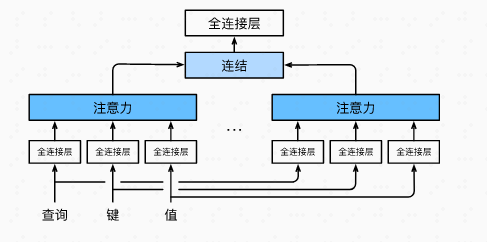
公式如下
h i = f ( W i ( q ) q , W i ( k ) k , W i ( v ) v ) ∈ R p v , \mathbf{h}_i = f(\mathbf{W}_i^{(q)} \mathbf{q}, \mathbf{W}_i^{(k)} \mathbf{k}, \mathbf{W}_i^{(v)} \mathbf{v}) \in \mathbb{R}^{p_v},hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv,
[ ∣ h 1 ∣ ⋮ ∣ h h ∣ ] ∈ R p o . \begin{bmatrix} | h_1 | \\ \vdots \\ | h_h | \end{bmatrix} \in \mathbb{R}^{p_o}.∣h1∣⋮∣hh∣∈Rpo.
如图所示,在
h个注意力机制下,会生成h个输出z,称为头
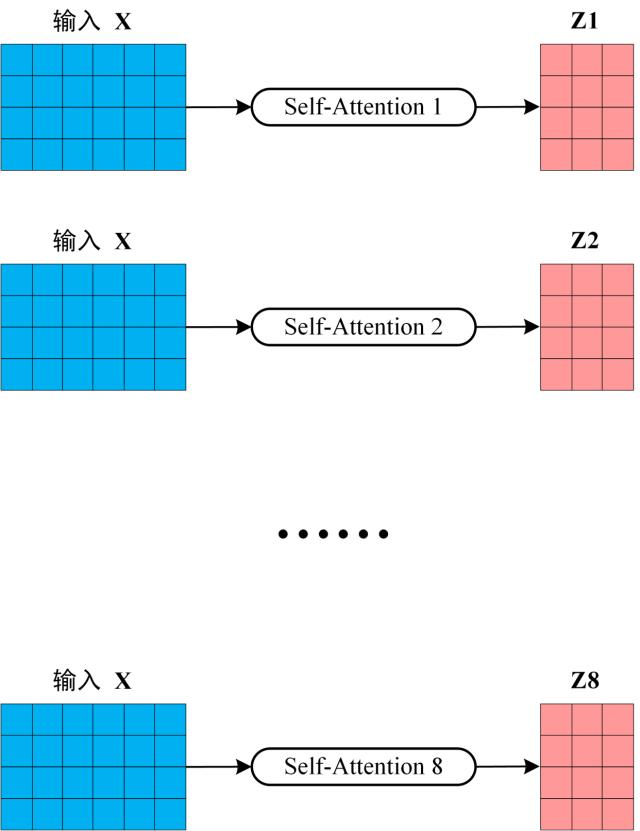
将每个头叠加后,基于全连接层(线性变换,无激活函数)生成最终的输出
Z
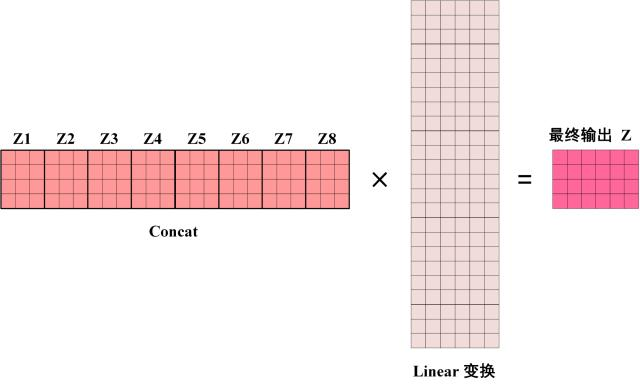
2.2 Add & Norm
① 首先,
Add是一种残差结构,类似于Resnet,改善了深层网络的训练效率,包括收敛速度和模型性能。从transformer结构图来看,是X + MultiHeadAttention(X)或者X + FeedForward(X)。而且,从上面的例子可以看出,输入X和经过变换后的输出是可以直接相加的,它们维度一致。

②
Norm类似于批量归一化BN,对每一层神经元输入转换到同一个均值和方差下,加速收敛
2.3 Feed Forward
Feed Forward是一个两层的全连接层(MLP无隐藏),第一层使用Relu激活函数,第二层不使用激活函数
max ( 0 , X W 1 + b 1 ) W 2 + b 2 \max(0, XW_1 + b_1) W_2 + b_2max(0,XW1+b1)W2+b2
2.4 encode block
通过上面描述的 Multi-Head Attention, Feed Forward, Add & Norm 就可以构造出一个Encoder block, Encoder block 接收输入矩阵 X ( n × d ) X_{(n×d)}X(n×d), 并输出一个矩阵O ( n × d ) O_{(n×d)}O(n×d) 。通过多个 Encoder block 叠加就可以组成 Encoder。
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵C ( n × d ) C_{(n×d)}C(n×d) ,这一矩阵后续会在 Decoder 中的多头注意力机制中,生成对应的K、V。
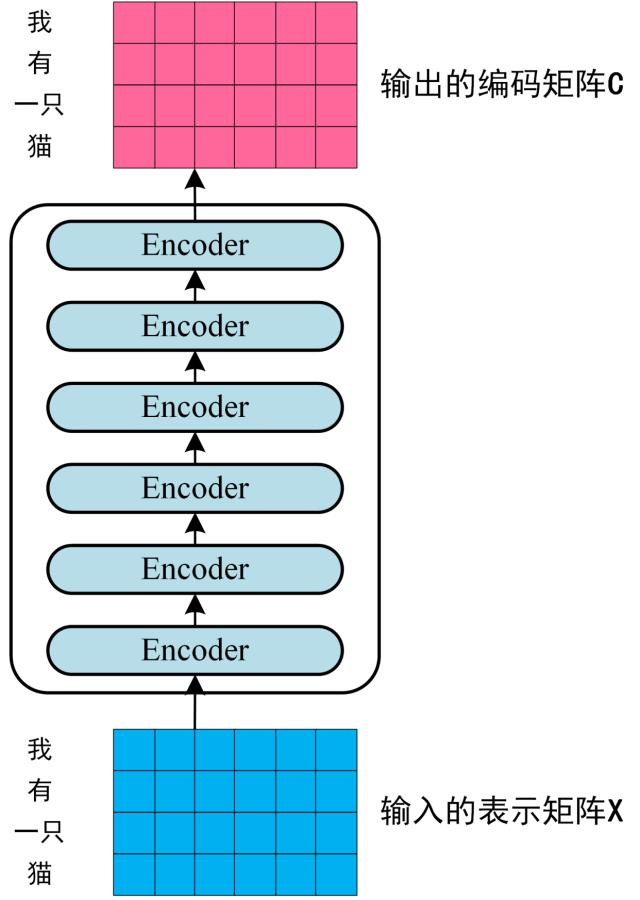
3 解码
3.1 decode block
- 包含两个
Multi-Head Attention层。 - 第一个
Multi-Head Attention层采用了Masked操作。 - 第二个
Multi-Head Attention层的K、V矩阵使用Encoder的编码信息矩阵C进行计算,而Q使用上一个Decoder block的输出计算。
3.2 第一个Multi-Head Attention
通过每一行表示一个单词向量,所以时候是遮挡是对于每一行来讲的,比如说,第一行只有0,那么后面只能有0;第二行存在0,1,那么这一行对应列就允许存在0,1;以此类推,就能够得到掩膜
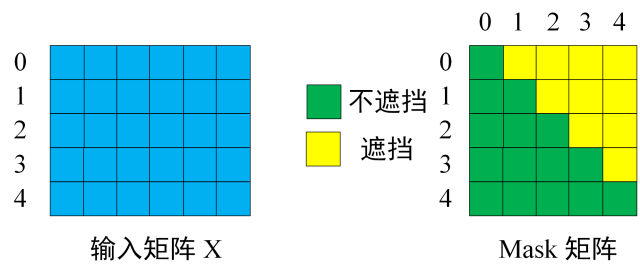
然后就是同样的
QK相乘
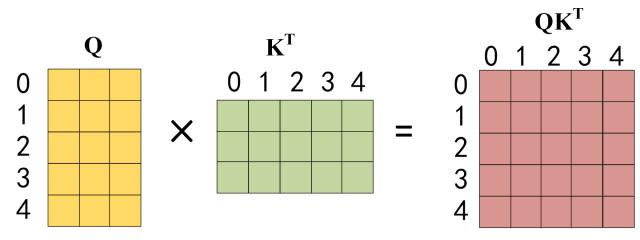
乘以掩膜矩阵
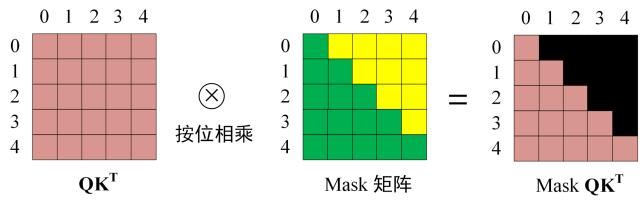
获取最终输出Z
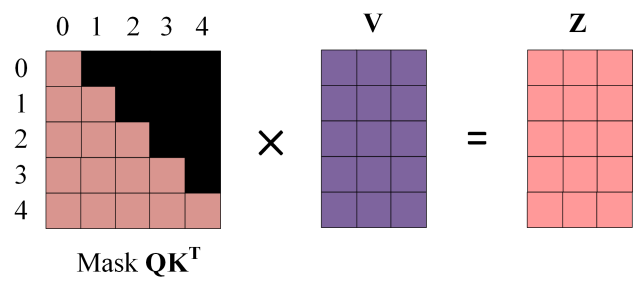
3.2 第二个Multi-Head Attention
Decoder block 第二个 Multi-Head Attention 变化不大,主要的区别在于其中 Self-Attention 的 K, V 矩阵不是使用上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
根据 Encoder 的输出 C 计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q(如果是第一个 Decoder block 则使用输入矩阵 X 进行计算)。这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息(这些信息无需 Mask)。
4 Transformer输出
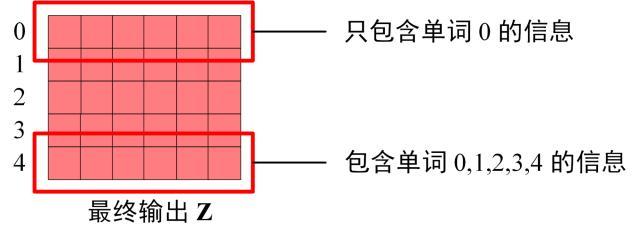
因为掩膜的存在,单词0的输出
Z0只包含单词0的信息
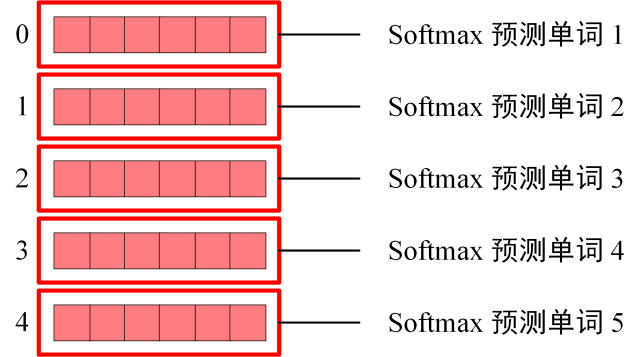
根据输出矩阵每一行预测下一个单词
5 CNN vs Transformer
CNN优点:
- 适合并行计算
- 适合视觉
- 参数少(比MLP)
CNN缺点:
- 没有全局联系,只能靠最后的全连接层(MLP),但MLP不能太深
- 不适合做(时间)序列,不像RNN,所以滤波什么的不擅长。
Transformer优点:
- 适合并行计算(和CNN差不多)
- 适合做(时间)序列,所以BEV有了该能力
- 对于大模型容易训练(因为参数冗余多,不容易陷入局部最优),CNN也比较容易训练(自动驾驶适用大小的模型)。
- 许可建立长距离的联系(CNN不行,MLP能够但是太臃肿)
Transformer缺点:
- 不适合视觉。所以backbone还是CNN
所以说,CNN+Transformer可以利用图像序列的时空信息
6 关于CNN思考
目标检测和语义分割任务通常许可用相同的CNN网络结构实现,区别主要在于标签形式(如检测用边界框,分割用像素级掩码)。这一现象的本质是否源于标签差异?
回答:① 底层特征的通用性
- CNN的层次化特征提取:无论是检测还是分割,底层网络(如ResNet、VGG)的作用都是提取通用视觉特征(边缘、纹理、形状等)。这些特征对两类任务均适用。
- 共享Backbone通过:现代网络设计(如Mask R-CNN)通常用同一Backbone(如ResNet)同时支持检测和分割,仅通过不同任务头(Head)适配不同输出。Yolo-v8也能够同时检测与分割。
回答:② 任务差异与标签形式
标签形式的区别 :
- 检测边界框(Bounding Box)+类别,输出需回归坐标和分类。就是:标签
- 分割像素级类别掩码(Mask),输出需密集预测每个像素的类别。就是:标签
本质差异:检测关注物体实例的定位与分类,分割关注像素级语义或实例区分。标签形式反映了任务目标的不同,但二者共享对物体和场景的理解需求。
最后,感觉NN本质就是一种优化模型,类似最小二乘优化,里面的参数远大于大家拟合一条线这种情况,不停的梯度下降去找到最优解。从线性回归到拥有非线性激活函数的MLP以及更艰难的网络,本质就是利用强大算力+巨额参数寻找非线性问题最优解的过程。
直接仍一堆图片,等待CNN去提取。就是不过,不同之处,CNN强大的还是其学习特征的能力,对于常规非线性问题,特征x是已知的,而基于网络,都
参考
知乎参考链接1
知乎参考链接2
原始论文Attention Is All You Need
李沐大神《动手深度学习》