论文信息
论文标题:AutoGCL: automated graph contrastive learning via learnable view generators
论文作者:尹一航、王庆忠、黄思宇、熊浩怡、张翔
论文来源:AAAI 2022
发布时间:2022-01-02
论文地址:link
论文代码:link
1 Introduction
1.1 研究背景:图神经网络(GNNs)的发展与局限
1.1.1 GNNs 的核心价值与应用场景
- 核心机制:通过 “递归邻域聚合”(recursive neighborhood aggregation)生成节点嵌入,k 层 GNN 可聚合节点 k 跳范围内的信息,最终通过 READOUT 函数与 MLP 得到图级表示,用于下游任务。
- 应用领域:在点云(Shi and Rajkumar, 2020)、社交网络(Fan et al., 2019)、化学分析(De Cao and Kipf, 2018)等领域展现出强大的表示能力。
1.1.2 传统 GNN 训练的关键瓶颈
- 监督训练的依赖:多数现有 GNN 采用端到端监督训练,需大量精细标注数据;而图数据标注需领域知识(如化学分子、蛋白质结构),成本极高。
- 早期无监督 / 自监督尝试的不足:
- 朴素无监督预训练:如 GAE(Kipf and Welling, 2016b)通过重构节点邻接信息、GraphSAGE(Hamilton et al., 2017)通过学习邻域聚合函数实现无监督嵌入,但泛化能力有限。
- 早期自监督预训练:如 Hu et al. (2019)、You et al. (2020b) 提出的策略虽提升泛化性,但仍未突破性能瓶颈。
1.2 对比学习:图表示学习的新方向
1.2.1 对比学习的跨领域启发
- 视觉与 NLP 的成功经验:对比多视图学习在计算机视觉(He et al., 2020; Chen et al., 2020a)、自然语言处理(Yang et al., 2019; Logeswaran and Lee, 2018)中取得突破,部分自监督预训练方法性能持平甚至超越监督方法。
- 核心逻辑:通过数据增强生成多个视图,使同一输入的视图(正样本对)在表示空间中靠近,不同输入的视图(负样本对)远离。
1.2.2 图对比学习的现有尝试与缺陷
现有方法虽将对比学习引入图领域,但存在 “无法适配语义”“增强策略固定” 的关键问题,具体如下:
|
方法
|
核心思路
|
局限性
|
|
DGI (Veličković et al., 2018)
|
将同一图的 “图级表示” 与 “节点级表示” 作为正样本对,对齐局部与全局特征
|
未涉及显式数据增强,视图多样性不足
|
|
CMRLG (Hassani and Khasahmadi, 2020)
|
将邻接矩阵(局部特征)与扩散矩阵(全局特征)作为正样本对
|
增强策略固定,无法自适应不同图数据的语义结构
|
|
GCA (Zhu et al., 2020b)
|
结合结构先验的子图采样 + 节点属性随机掩码生成正样本对
|
依赖预定义先验,增强策略无学习能力
|
|
GraphCL (You et al., 2020a)
|
提供节点删除、边扰动等多种预定义增强策略
|
策略固定,无法根据输入图语义调整,易破坏关键结构
|
1.3 关键挑战:图数据增强的特殊性
1.3.1 与图像数据增强的本质差异
- 图像增强的优势:图像语义在旋转、裁剪等变换下具有不变性,数据增强易生成有效对比视图(Cubuk et al., 2019)。
- 图增强的难点:图的拓扑结构与语义强绑定(如分子键、社交关系),简单变换(如随机删边)易严重破坏语义,导致增强视图无效。
1.3.2 现有图生成模型的局限
- InfoMin 的启发与迁移困难:InfoMin(Tian et al., 2020)为视觉任务提出 “基于流生成模型的视图生成”,但图生成模型(如 VGAE)存在性能差、场景受限(如仅适配分子数据)的问题,难以直接复用。
1.4 本文解决方案:AutoGCL 框架的核心目标
-
-
可学习视图生成:通过学习 “基于输入图的概率分布” 生成视图,而非依赖预定义策略,实现语义自适应;
-
语义保留与多样性平衡:在保留原图核心语义结构的同时,引入足够的视图方差,满足对比学习需求;
-
端到端联合训练:将视图生成器、图编码器、分类器联合训练,确保增强视图的 “拓扑异质性” 与 “语义相似性”;
-
1.5 本文贡献预告
- 提出首个 “节点级可学习增强策略” 的图对比学习框架,通过自动增强策略协调多个可学习视图生成器。
- 设计端到端联合训练策略,协同优化视图生成器、编码器与分类器。
- 在无监督、半监督、迁移学习任务上全面验证性能,通过可视化证明可学习视图生成器的语义保留优势。
2 Methodology
2.1优质图视图生成器的评判标准(What Makes a Good Graph View Generator?)
2.1.1 核心目标
2.1.2 优质图视图生成器的 5 大核心属性
- 拓扑与节点特征双增强:需同时支持对图拓扑结构(如节点 / 边的增减)和节点属性(如特征掩码)的增强,覆盖图数据的核心信息维度。
- 标签保留(Label-preserving):增强后的视图需维持原图的语义信息,确保对比学习的正样本对具有一致的类别标签,避免因增强导致语义偏移。
- 自适应与可扩展性:能适配不同数据分布(如分子图、社交网络图),且可高效扩展到大规模图数据(如节点数上万的图)。
- 足够的视图方差(Variance):生成的视图需具有多样性,为对比学习提供有效负样本区分度,避免视图同质化导致的学习失效。
- 端到端可微与高效反向传播(Differentiable & Efficient BP):支持梯度通过生成器反向传播,且计算成本低,适配大规模训练。
2.1.3 现有方法的属性对比
|
方法 |
拓扑增强 |
节点特征增强 |
标签保留 |
自适应 |
方差 |
可微 |
高效 BP |
|
CMRLG (Hassani et al., 2020) |
✔️(扩散核改拓扑) |
❌ |
❌ |
❌ |
❌ |
❌ |
✔️ |
|
GRACE (Zhu et al., 2020a) |
✔️(随机删边) |
✔️(属性掩码) |
❌ |
❌ |
❌ |
❌ |
✔️ |
|
GCA (Zhu et al., 2020b) |
✔️(子图采样) |
✔️(属性掩码) |
❌ |
❌(依赖固定先验) |
❌ |
❌ |
✔️ |
|
GraphCL (You et al., 2020a) |
✔️(删节点 / 边、子图) |
✔️(属性掩码) |
❌ |
❌(预定义策略) |
✔️ |
❌ |
✔️ |
|
JOAO (You et al., 2021) |
✔️(复用 GraphCL 策略) |
✔️(复用 GraphCL 策略) |
❌ |
❌(仅优化采样分布) |
✔️ |
❌ |
✔️ |
|
AD-GCL (Suresh et al., 2021) |
✔️(可学习删边) |
❌ |
❌ |
✔️(仅边级) |
❌ |
✔️ |
✔️ |
|
AutoGCL(本文) |
✔️(可学习删节点) |
✔️(可学习属性掩码) |
✔️ |
✔️(节点级学习) |
✔️ |
✔️ |
✔️ |
2.1.4 AutoGCL 的视图生成器设计取舍
- 不包含边扰动的原因:若通过可学习方法(如 VGAE)生成边,需预测 $O(N^2)$ 规模的邻接矩阵(N 为节点数),对大规模图的反向传播造成极大计算负担,故优先聚焦节点级增强(计算复杂度 $O(N)$ )。
- 节点级增强的灵活性:同时支持 “节点删除” 和 “属性掩码”,且以节点为单位动态选择操作,无需人工调优 “增强比例”(如 GraphCL 的 0.2 固定比例),适配不同节点的语义重要性。
2.2 可学习图视图生成器(Learnable Graph View Generator)
2.2.1 核心设计思路
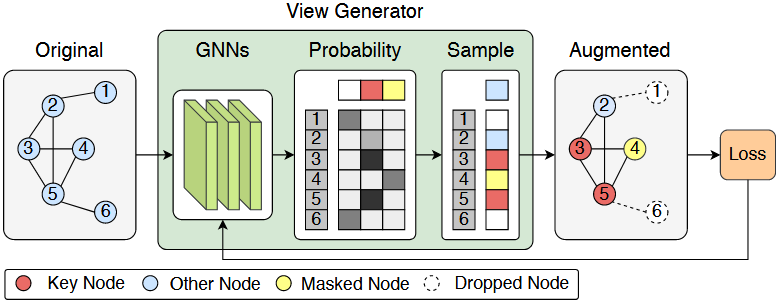
2.2.2 数学建模与关键步骤
步骤 1:节点嵌入生成(基于 GIN)
-
-
第 $k-1$ 层聚合后节点状态: $h_{v}^{(k-1)}=COMBINE^{(k)}\left(h_{v}^{(k-2)}, a_{v}^{(k-1)}\right)$
-
第 $k$ 层邻域聚合: $a_{v}^{(k)}=AGGREGATE^{(k)}\left(\left\{h_{u}^{(k-1)}: u \in \mathcal{N}(v)\right\}\right)$
-
步骤 2:增强操作概率采样(Gumbel-Softmax)
- 概率分布输出:GIN 第 $k$ 层输出 $a_{v}^{(k)}$ 的维度等于 “可选增强操作数”(本文为 3:删除、保留、掩码),直接作为各操作的概率权重。
- 可微分采样:通过 Gumbel-Softmax(Jang et al., 2016)对概率分布采样,得到 one-hot 向量 $f_{v}$ ,表示节点 $v$ 的增强操作选择,公式为:
$f_{v}= GumbelSoftmax\left(a_{v}^{(k)}\right)$
步骤 3:增强视图生成
- 节点属性更新:通过 $Aug(x_{v}, f_{v})$ 函数应用增强操作(如 $f_{v}$ 为 “掩码” 则将 $x_{v}$ 置零,“删除” 则标记节点),得到增强后节点特征 $x_{v}'$ ,且 $Aug$ 函数采用可微分操作(如乘法),确保梯度传递。
- 边表更新:删除所有与 “被标记为删除的节点” 相连的边,无需可微分(边表仅用于 GNN 邻域聚合,不参与梯度计算)。
2.2.3 核心优势
- 端到端可微:GIN 嵌入 + Gumbel-Softmax 采样 + 可微分 Aug 函数,确保视图生成器可与编码器、分类器联合训练。
- 高效扩展:节点级操作复杂度低,可适配大规模图数据集;且支持增加增强操作类型(如节点特征扰动),扩展性强。
2.3 Contrastive Pre-training Strategy(对比预训练策略)
2.3.1 整体框架组件
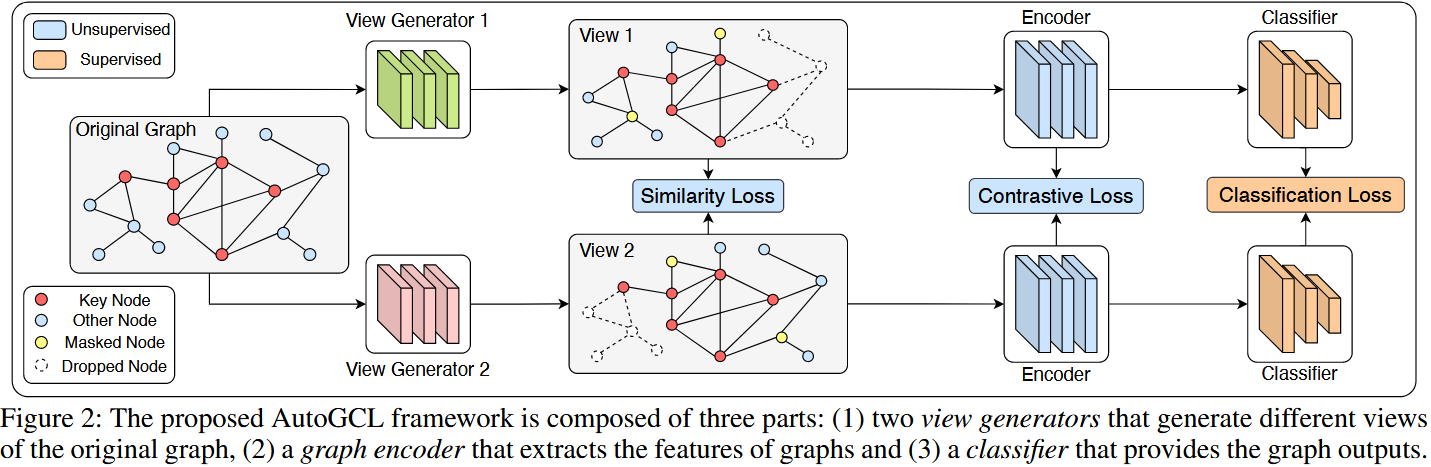
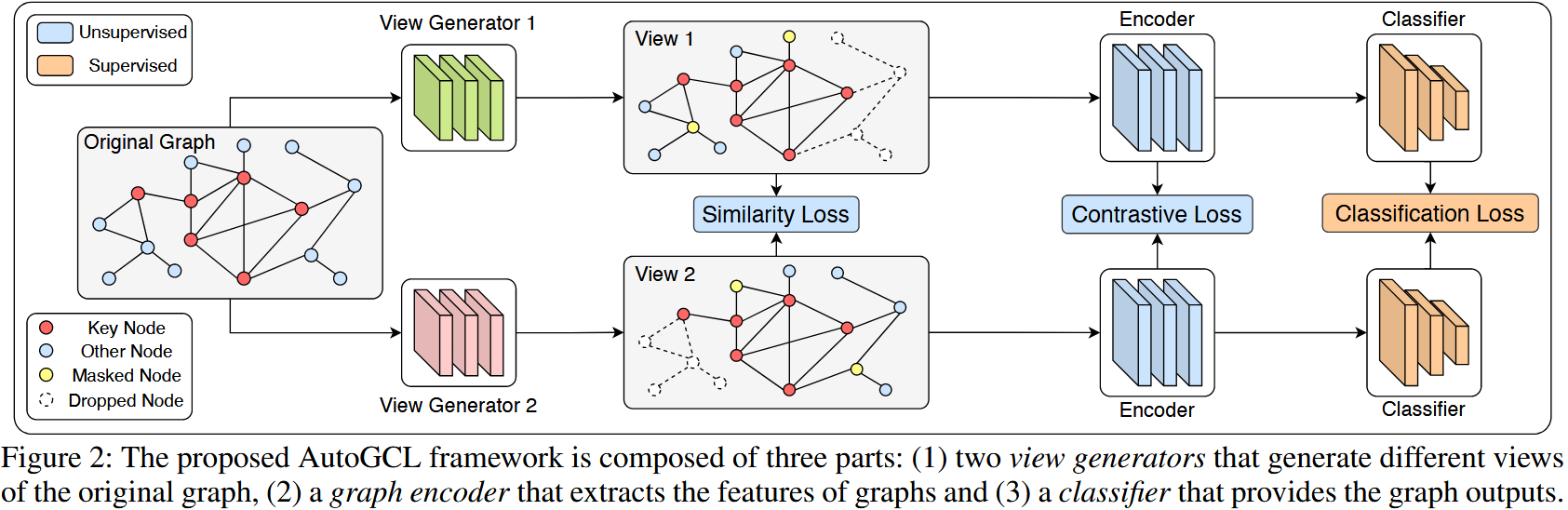
AutoGCL 包含2 个独立视图生成器(G1、G2)、1 个图编码器(如 GIN/ResGCN)、1 个分类器,核心目标是生成 “语义相似、拓扑异质” 的视图对,遵循 InfoMin 原则:最大化视图对的标签相关信息,最小化视图间冗余(互信息)。
2.3.2 三大损失函数定义
1. 对比损失( $L_{cl}$ ):对齐正样本、区分负样本
- 相似度计算:采用余弦相似度衡量图级表示的相似性,公式为:
$sim\left(z_{1}, z_{2}\right)=\frac{z_{1} \cdot z_{2}}{\left\| z_{1}\right\| _{2} \cdot\left\| z_{2}\right\| _{2}}$
- NT-XEnt 损失(Sohn, 2016):适用于批量对比学习,公式为:
单个正样本对 $(i,j)$ 的损失:
$\ell_{(i, j)}=-log \frac{exp \left(sim\left(z_{i}, z_{j}\right) / \tau\right)}{\sum_{k=1}^{2 N} \mathbb{1}_{[k \neq i]} exp \left(sim\left(z_{i}, z_{k}\right) / \tau\right)}$
批量损失(N 为批量内图数量,2N 为视图数量):
$\mathcal{L}_{cl}=\frac{1}{2 N} \sum_{k=1}^{N}[\ell(2 k-1,2 k)+\ell(2 k, 2 k-1)]$
2. 相似度损失( $L_{sim}$ ):减少视图间冗余
- 核心逻辑:通过最小化两个视图生成器的 “增强操作矩阵” 相似度,确保视图拓扑异质性。
- 数学表达:设 G1、G2 生成的增强操作矩阵为 $A_1、A_2$ (每行对应一个节点的操作选择),则:
3. 分类损失( $L_{cls}$ ):确保语义保留
- 核心逻辑:通过交叉熵损失,使原图与增强视图的分类结果一致,强制视图保留语义标签。
- 数学表达:设原图为 $g$ ,增强视图为 $g_1、g_2$ ,分类器为 $F$ ,标签为 $y$ ,则:
$\mathcal{L}_{cls}=\ell_{cls}(F(g), y)+\ell_{cls}\left(F\left(g_{1}\right), y\right)+\ell_{cls}\left(F\left(g_{2}\right), y\right)$
2.3.3 两种训练策略(任务自适应)
1. 朴素策略(Naive-strategy):适用于无监督 / 迁移学习

- 适用场景:无标签数据,无法通过 $L_{cls}$ 约束语义,需避免 “盲目追求视图多样性而破坏语义”。
- 核心流程(对应 Algorithm 1):
- 初始化视图生成器(G1、G2)、分类器(F)权重;
- 批量迭代无标签数据:
- 生成增强视图 $x_1=G1(x)、x_2=G2(x)$ ;
- 从 $\{x, x_1, x_2\}$ 中采样 2 个视图作为正样本对;
- 最小化 $L_{cl}$ ,联合更新 G1、G2、F 权重;
- (迁移学习额外步骤):在目标数据集上微调分类器。
- 关键改进:对比 GraphCL 仅用 “两个增强视图” 对比,AutoGCL 加入 “原图与增强视图” 的对比,引导生成器保留语义。
2. 联合策略(Joint-strategy):适用于半监督学习

- 核心痛点:传统 “预训练(对比损失)+ 微调(分类损失)” 易过拟合 —— 预训练过度拉近样本导致分类边界模糊,微调时难以区分。
- 创新设计:交替进行 “无监督对比训练” 与 “有监督联合训练”,平衡对比学习与语义约束,流程对应 Algorithm 2:
- 初始化 G1、G2、F 权重;
- 批量迭代(交替无标签 / 有标签数据):
- 无监督阶段:固定 G1、G2,用无标签数据生成视图,最小化 $L_{cl}$ 更新 F(优化编码器与分类器的对比能力);
- 有监督阶段:用有标签数据生成视图,最小化 $L_{cls} + \lambda \cdot L_{sim}$ ( $\lambda=1$ 实验效果最优),联合更新 G1、G2、F(约束语义保留与视图多样性);
- 重复迭代至收敛。
- 优势:避免预训练 - 微调的过拟合,通过标签监督快速对齐语义,提升半监督分类性能。