- SAIL-Embedding Technical Report: Omni-modal Embedding Foundation Model
- TL;DR
- Data
- Recommendation-aware Data Construction
- Dynamic Hard Negative Mining
- Q:动态难负样本挖掘是什么原理?\(\lambda^*\)是如何动态确定的?
- Q:\(H\)与\(N\)这两个子集分别是如何确定的?
- 动态多源数据平衡
- Architecture
- Text Tokenizer
- Vision Encoding
- Audio Encoding
- Fusion
- 训练策略
- 策略
- Loss
- NCE Loss
- CoSENT Loss
- mICL Loss
- IF Loss
- Stochastic Specialization Training
- Collaboration-aware Recommendation Enhancement Training
- Experiment
- 总结与思考
- 相关链接
- Related works中值得深挖的工作
- 资料查询
SAIL-Embedding Technical Report: Omni-modal Embedding Foundation Model
link
时间:2025.10
单位:ByteDance SAIL
相关领域:多模态特征学习
TL;DR
SAIL-Embedding:
1.使多模态检索与分类支持任意模态;
2.引入动态难负样本挖掘与多数据源动态采样提升训练稳定性与规模;
同时,多阶段训练从多方面提升了多模态表征学习的有效性:
1.context-aware训练 -> 增强在各下游任务的动态适应性
2.collaboration-aware推荐训练 -> 通过sequence-to-item与ID-to-item embedding的蒸馏策略,提升推荐场景下多模态表征能力
SAIL-Embedding的功能
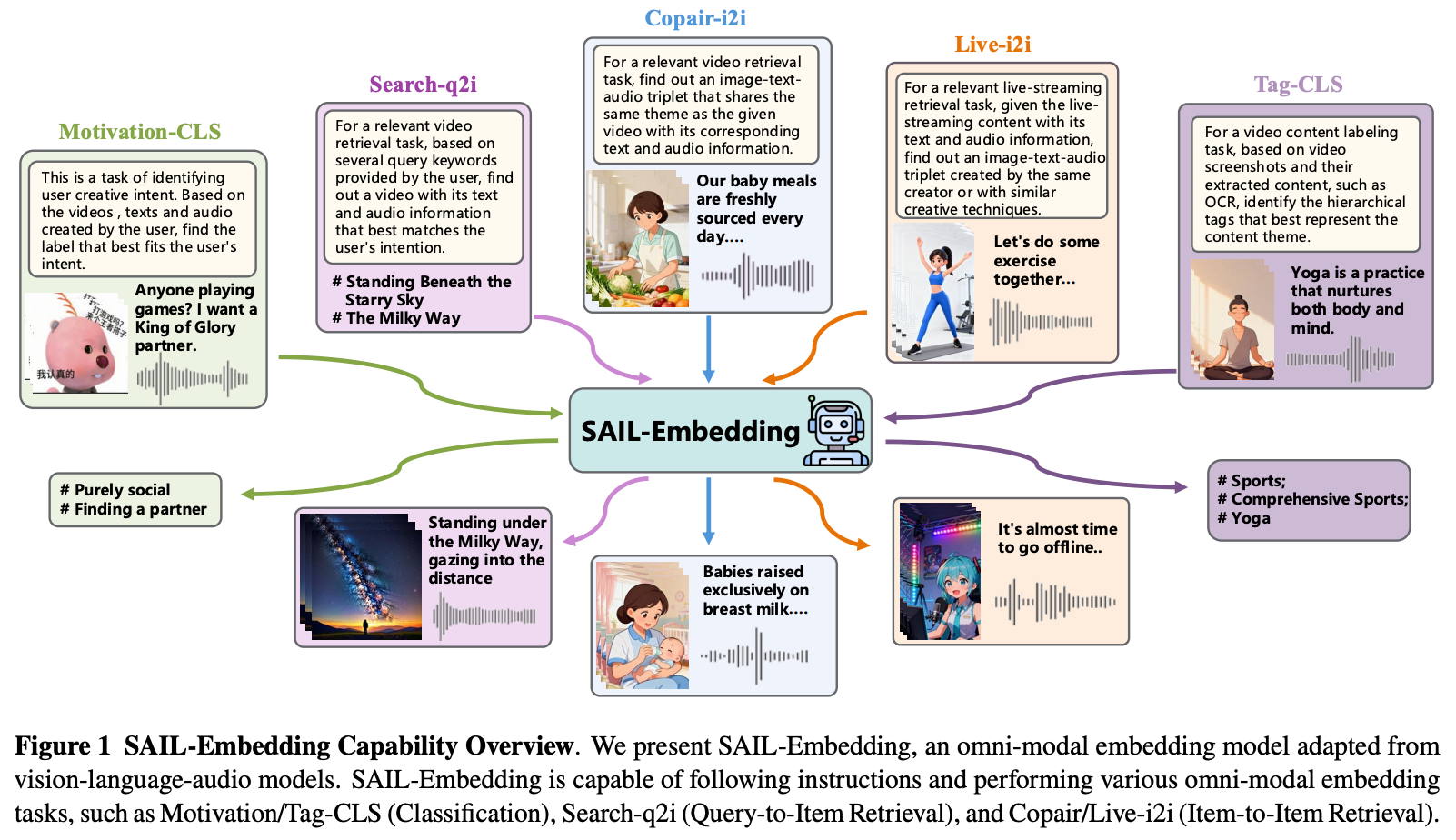
Data
SAIL-Embedding支持更多模态输入
Recommendation-aware Data Construction
- Item-to-Item检索:item=短视频,包括里面的多模态信息,对应应该被检索到的item有多种需求:用户行为、video summaries、semantics ID以及特定商业应用;
- Query-to-Item检索:通常,Query=text,target指得用户最有可能点击的视频。通常使用基于规则或者基于LLM来计算query与target之间的相似性;
- Classification:query=item, target指得是多级tag,我们将分类数据集转为item-label对,tag有多种维度,比如 用户动机、图文内容分类。
Dynamic Hard Negative Mining
Q:动态难负样本挖掘是什么原理?\(\lambda^*\)是如何动态确定的?
针对于所有[0, 1]之间的\(\lambda\),针所有样本对计算F1,并且F1的求和 (因为每个样本对是正的还是负的其实已知),找一个最大的F1对应的\(\lambda\)就是此时的动态阈值\(\lambda^*\)。

Q:\(H\)与\(N\)这两个子集分别是如何确定的?
\(s_{ij}\)是低于\(\lambda^*\),但与q有最高相似度的样本。
![]()
动态多源数据平衡
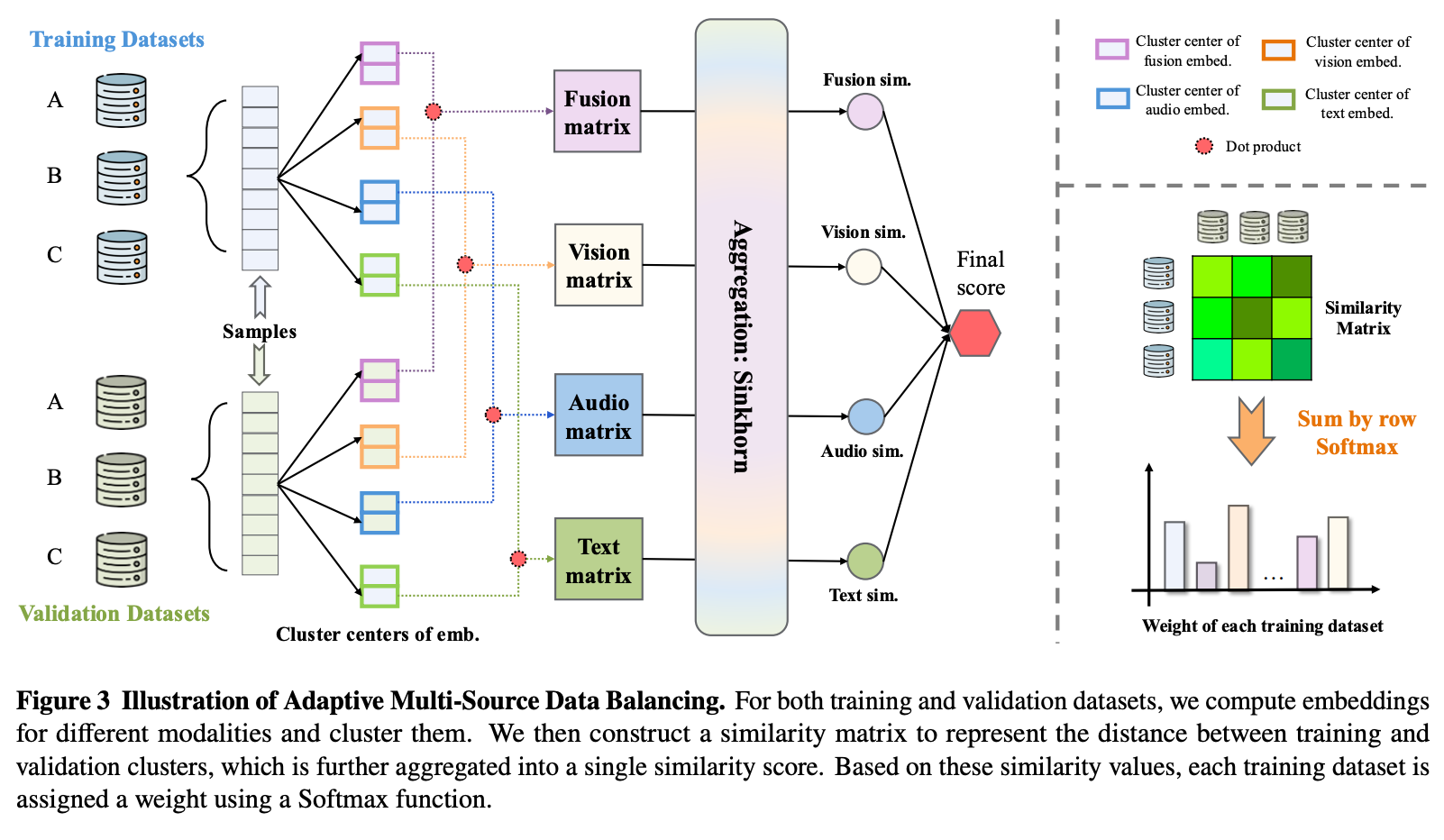
之前方法数据采样都是手工设定
动态多源采样处理方法:
- 从训练集摘出验证集并构造下游任务;
- 用当前阶段emb模型分别提取训练集与验证集特征,并聚类出中心特征;
- 计算train与val数据集间的相似度矩阵,并通过Sinkhorn算法将相似矩阵压缩为标量分数;
- 高相似度获得较大采样权重,低相似度获得较低采样权重;
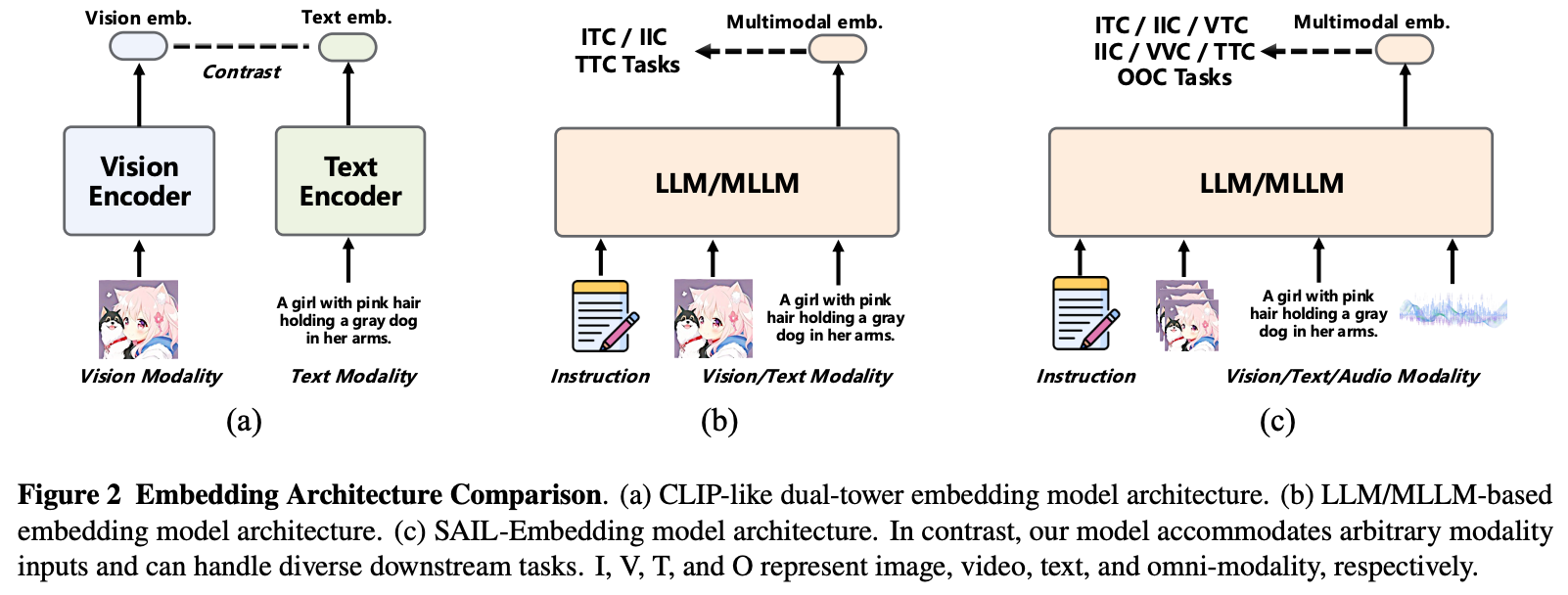
Architecture
整体架构图

Instruction模板
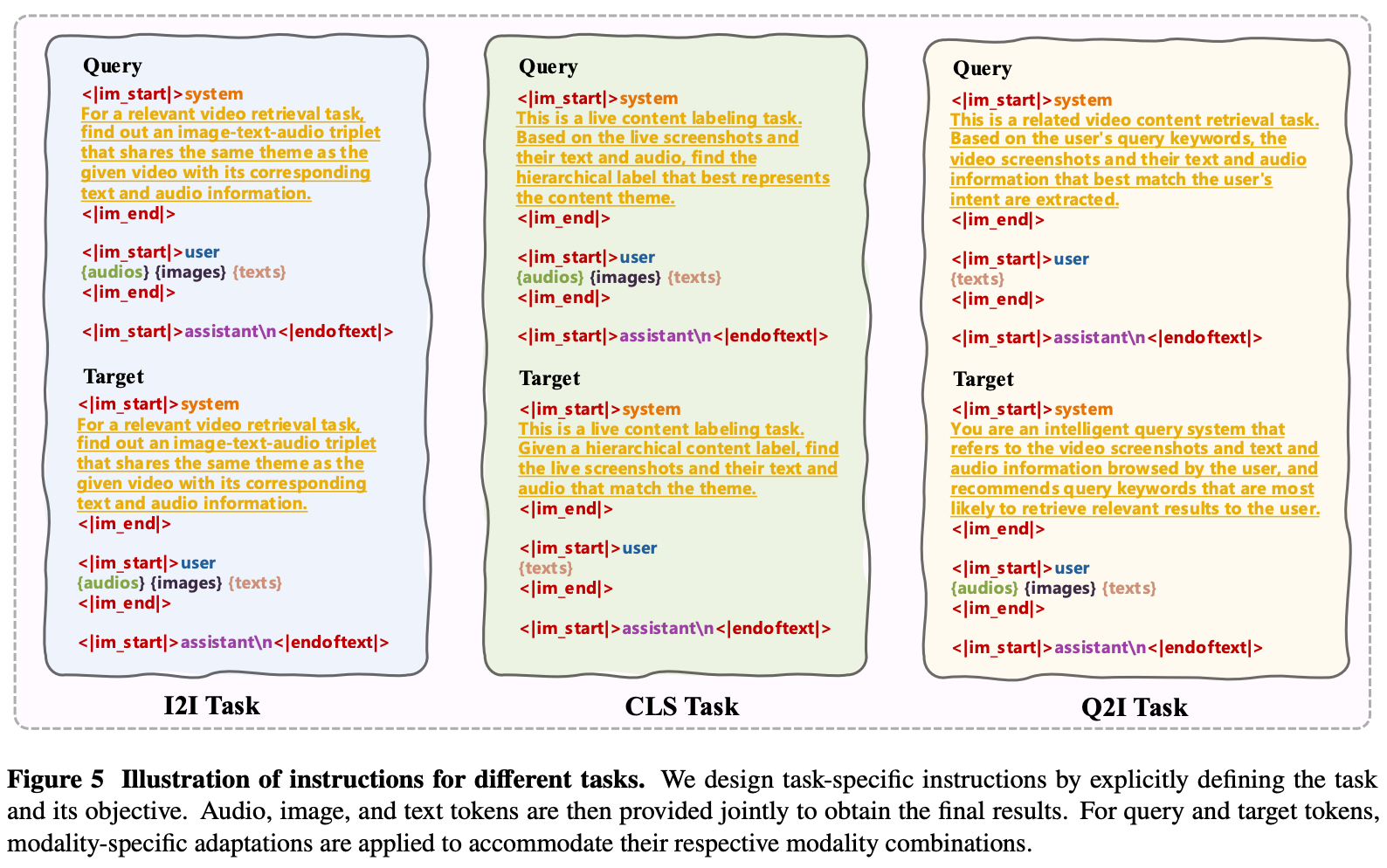
Text Tokenizer
Q:Text Tokenizer是什么算法?输入输出是什么?
- 输入:
- text Modality: titles, tags, author labels, OCR texts, and ASR texts.
- Instruction: 像是整体格式的控制模板,包括:System Prompt、用户信息、助手标识
- 输出:token ID序列、位置编码、注意力编码(标识token的效性)
Vision Encoding
Vision Encoder:将分辨率resize到固定,对于高分辨率或者视频数据而言tokens数量庞大
Visual Perceiver: 将visual tokens外加16个可学习的Query tokens,通过该子网络后提取出这个16浓缩后的tokens,从而降低下降融合时的tokens计算量,所以这里Query tokens与搜索领域所说的用户query不是一会事。
Audio Encoding
使用CLAP模型,比Whisper速度更快,模型结构与预训练方法上比较像CLIP。
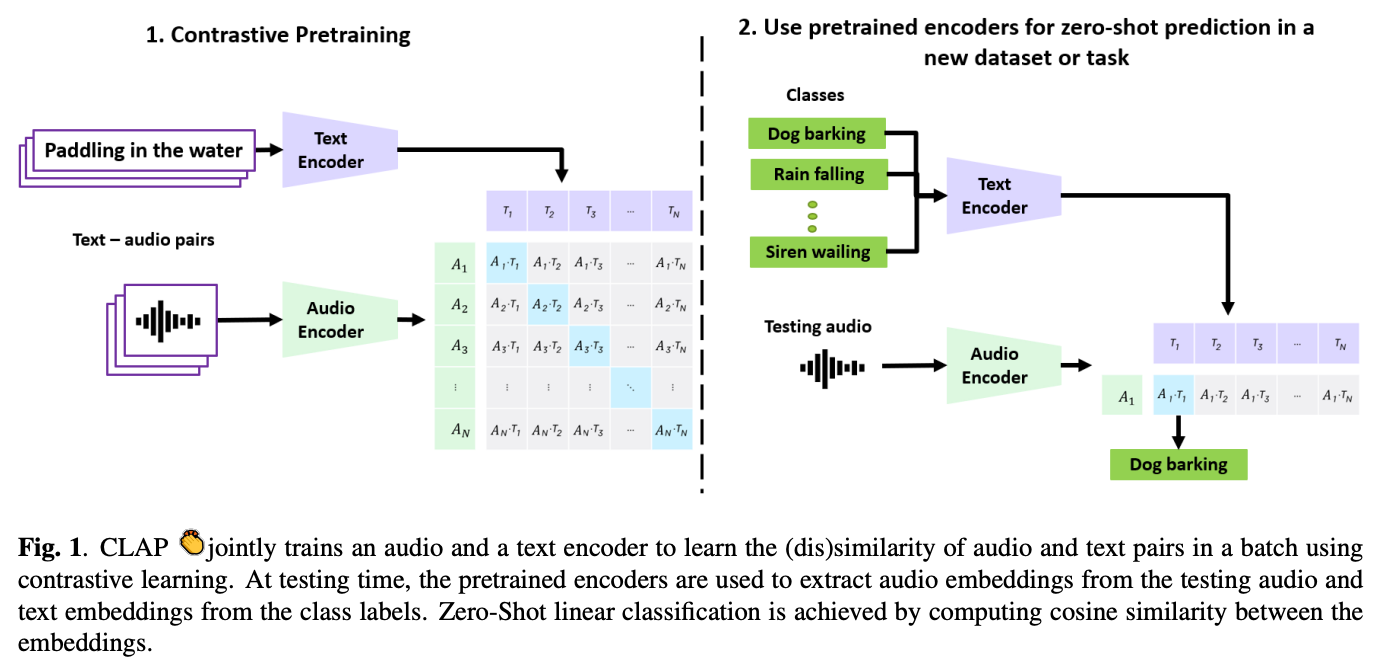
Fusion
简单而言:多模态token concat -> attention聚合 -> Tanh非线性激活 -> MeanPool => 融合后的多模态token
这种Fusion方式与VLM2Vec中取最后一层最后一个token的方式不一致,哪种方法更好呢?
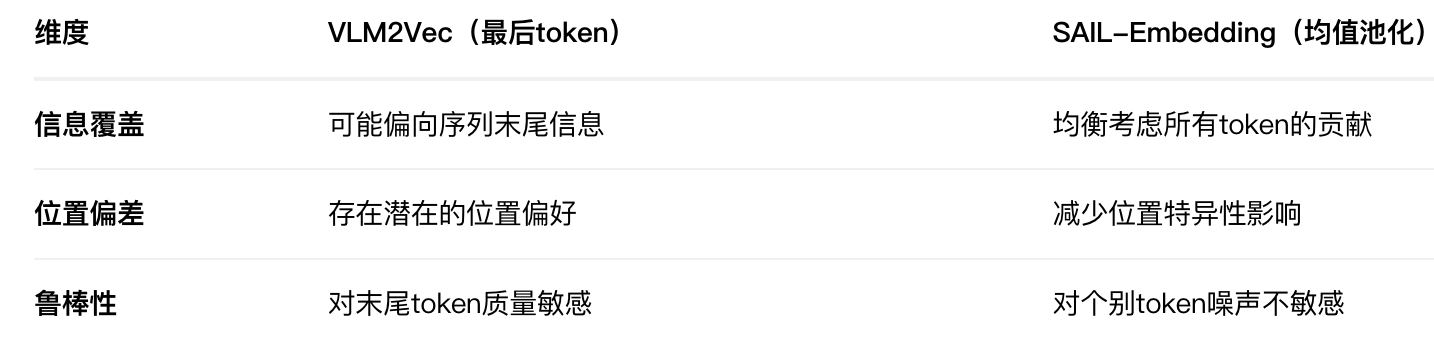
训练策略
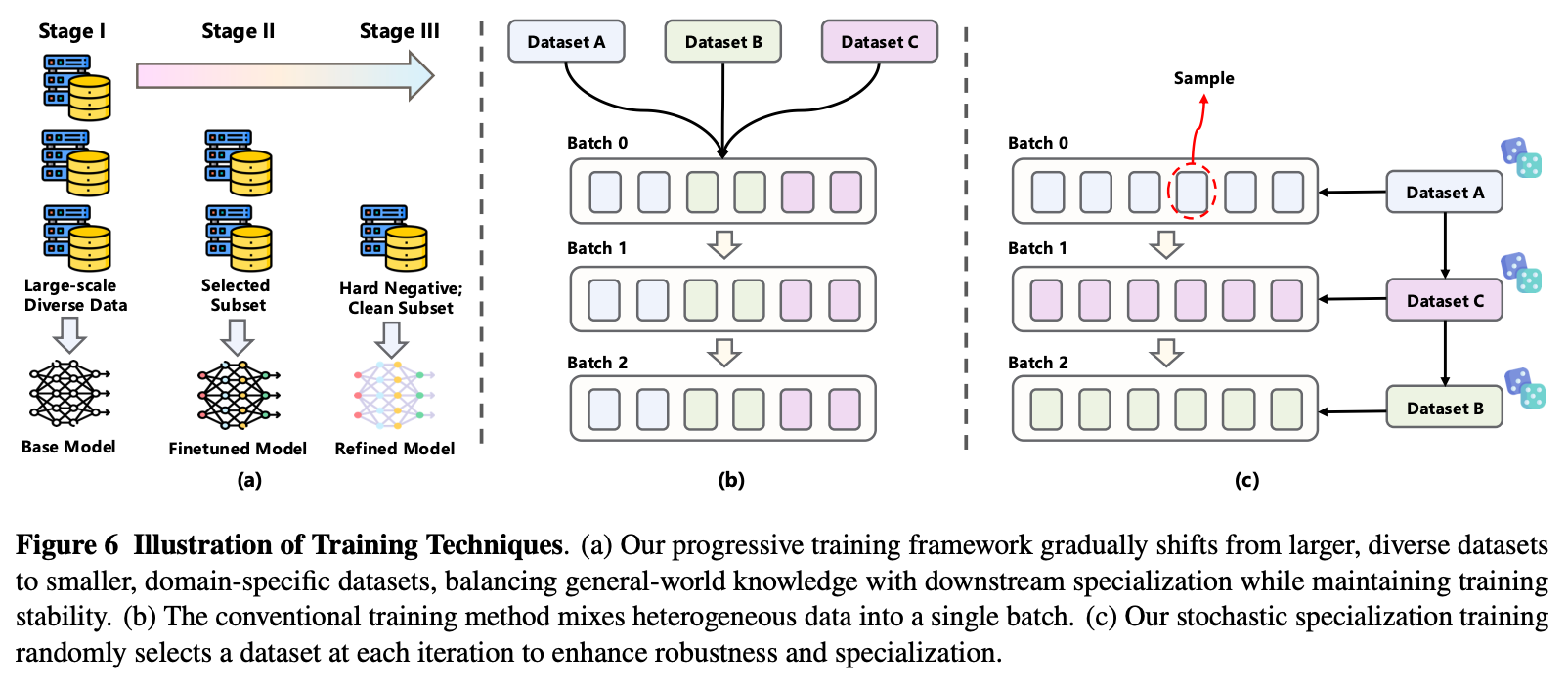
策略
大规模数据预训练 => 下游任务Finetune => 构造难负样本集进一步Refine
Loss
![]()
NCE Loss
使用的MRL NCE Loss,MRL全称为Matryoshka Representation Learning,该操作会将1536维embedding切出多个子vector例如128d与768d,这些向量同时做NCE Loss。
![]()
CoSENT Loss
参考苏神的博客。为了解决直接优化绝对余弦相似度(如设定正样本对相似度为1,负样本对为0)所带来的问题。其核心创新在于将学习目标从拟合绝对分数转变为学习相对顺序。参考下述公式,关键在于求和条件 sim(i,j)>sim(k,l)。它并不关心sim(i, j)和sim(k, l)的具体数值是多少,只关心它们之间的大小关系。
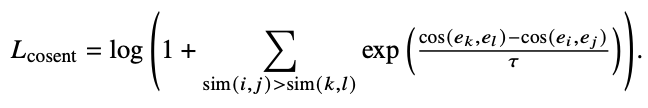
Q:在计算Loss时,我怎么知道sim(i, j)与sim(k, l)之间的相似度关系呢?
- 二元标签:类似NCE那样,正样本对的相似度必然大于负样本对相似度;
- 多分类标签:对于NLI(自然语言推理)数据,标签是“蕴含”、“中立”、“矛盾”三类。可建立一个顺序关系:
sim(蕴含)>sim(中立)>sim(矛盾) - 连续分数: 某些数据集包含相似度真值,例如 STS-B数据集。
mICL Loss
mICL全称为multimodal In-Context Learning,即为每种模态单独计算NCE Loss。
![]()
IF Loss
全称为Late Fusion,通过门控融合机制保护视觉信息的完整性,防止在多模态融合过程中视觉语义被文本信息主导。

Stochastic Specialization Training
故名思义,随机特定数据集训练。之前工作都是将多个数据源混合少量样本训练,这么做增加了梯度估计的方差,使训练不稳定。本工作改为每次随机选择一个数据集,并仅从该数据集中采样构建一个完整的训练批次,提升训练效率和模型在各数据集上的专业化性能。
Collaboration-aware Recommendation Enhancement Training
Sequence-to-Item Distillation
在用户历史1k次搜索视频序列中,过滤出它主动交互的行为,将最近一次的序列中item设计为目标视频,由些可以构造一个蒸馏训练方法,参考Figure7 a。
ID-to-Item Distillation
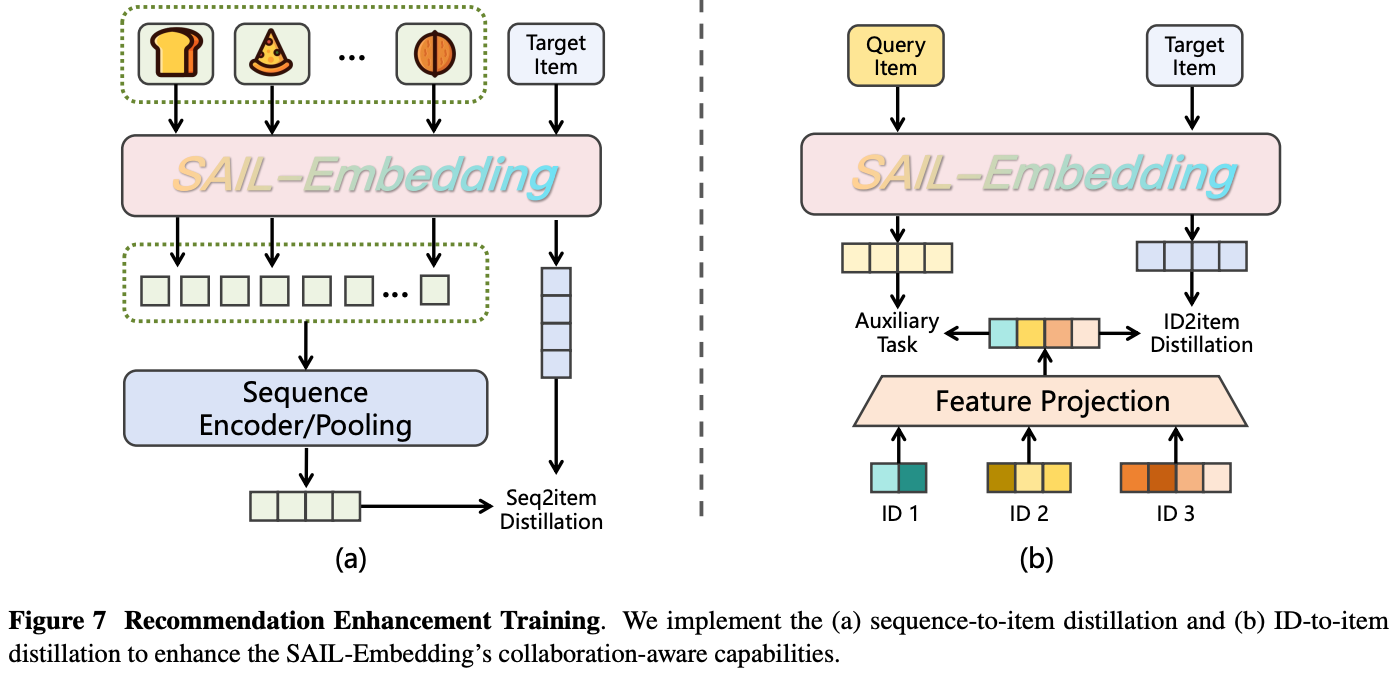
参考Figure7b
Q:图中的Query Item与Target Item分别指得是什么?
- Query Item的embedding:指通过SAIL-Embedding多模态模型计算得到的表征。它融合了物品的视觉、文本、音频等内容信息,代表的是该物品的内容语义特征。
- Target Item的embedding:指同一Item在现有推荐系统中已有的、基于协同过滤(如用户行为序列)学习到的ID表征。它代表的是该物品的用户协作特征。
Q:图中下方ID1/ID2/ID3指得是什么?
该Item的ID(如视频ID、作者ID),从推荐系统的嵌入表中查找出对应的ID1, ID2, ID3等embedding,它们通过Feature Projection映射成Target Item的协作表征。典型的ID有以下可能的类别:
- 物品ID:物品的唯一标识符,其嵌入反映了该物品的整体受欢迎程度和属性。
- 作者ID:内容创作者的身份标识,其嵌入反映了该作者的风格、受众群体和影响力。
- 类别/标签ID:物品所属的分类或主题标签,其嵌入反映了该类别的用户偏好分布。
- 其他实体ID:如品牌ID、音乐ID、地理位置ID等,取决于具体的业务场景。
Experiment

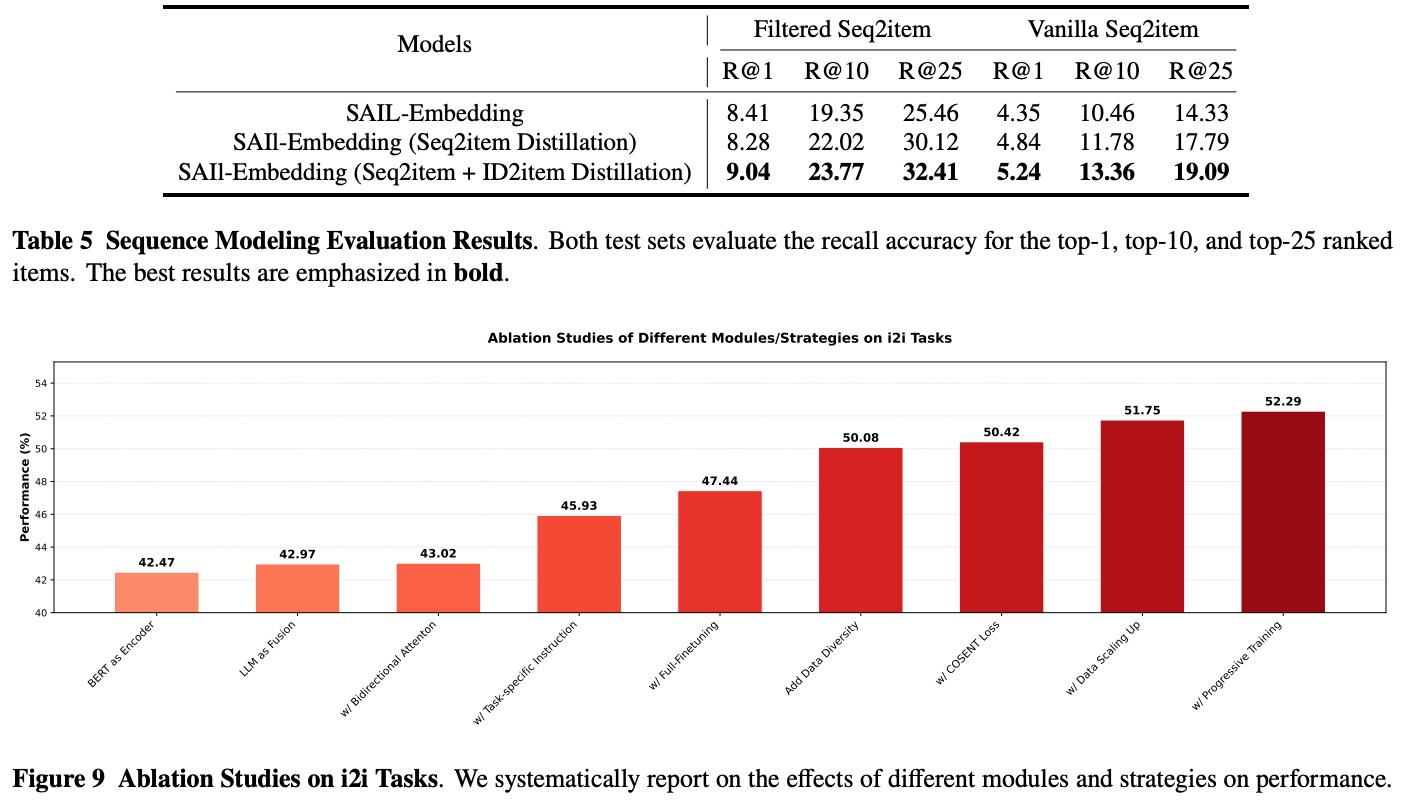
Ablation Study
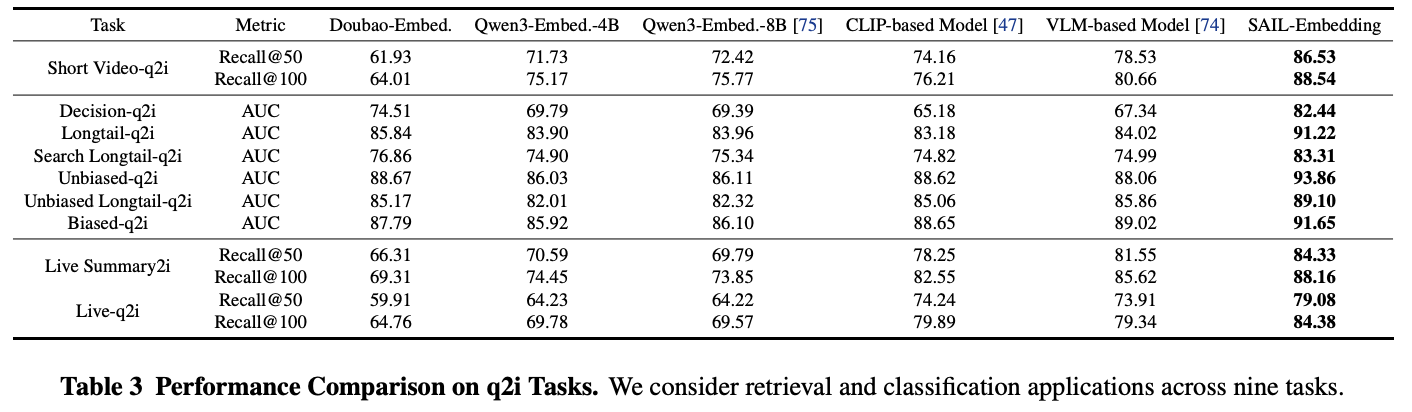
Q:i2i, q2i这两个任务为什么要分开评测(不都是多模态检索任务吗)?
表征需求不同:i2i(item2item)需要强大的跨模态融合能力,q2i(query2item)需要优秀的文本-多模态对齐能力
总结与思考
很详实的工作,共20页的内容,分享了很多实战的干货,实验结果也很充分。
相关链接
翻译