中文分词是NLP中一个独特且富有挑战性的任务,因为中文文本没有像英文空格那样的天然词语边界。
现代分词器模型(尤其是基于Transformer的模型如BERT、GPT等使用的中文分词器)主要采用子词分词算法,但其处理方式与英文有显著不同。
| 特性 | 传统中文分词器 (如Jieba, HanLP) | 现代模型分词器 (如BERT的分词器) |
|---|---|---|
| 目标 | 将文本切分成语言学意义上的词。 | 将文本切分成对模型训练最有效的单元。 |
| 输出 | 词的序列。[“我”, “喜欢”, “读书”] |
子词/字符的序列。[“我”, “喜”, “欢”, “读”, “书”] 或 [“我”, “喜欢”, “读”, “书”] |
| 歧义处理 | 需要复杂的算法(如HMM、CRF)来解决分词歧义(如“乒乓球拍卖完了”)。 | 将问题抛给模型。模型在预训练过程中通过上下文自行学习消歧。 |
| 与模型关系 | 独立于下游的NLP模型,是预处理步骤。 | 深度集成,是模型的一部分,分词方式与模型架构共同设计。 |
主流的中文分词器(如BERT、ERNIE等使用的)并不像传统中文分词器那样先进行“词”的切分,而是将句子切分成更小的、更灵活的单元。主要有两种策略:
1. 字符级分词
这是最简单直接的方法。
-
做法:将每个汉字或标点符号视为一个独立的Token。
-
示例:
-
文本:
"我喜欢读书" -
分词结果:
[“我”, “喜”, “欢”, “读”, “书”]
-
-
优点:
-
非常简单,无需复杂的分词算法。
-
词汇表很小(几千个常用汉字就足以覆盖绝大多数文本)。
-
完全避免了分词歧义问题。
-
-
缺点:
-
序列长度会很长。
-
模型需要从零学习词语和短语的语义,增加了学习负担。例如,模型需要自行理解“喜欢”是一个整体,而不是“喜”和“欢”的简单相加。
-
-
使用模型:很多早期的中文BERT模型(如Google官方发布的
bert-base-chinese)就采用这种方式。
2. 子词分词(主要是WordPiece)
这是目前更主流、效果更好的方法。它结合了字符级和词级的优点。
-
做法:
-
首先,它会有一个通过大量中文语料训练得到的词汇表。这个词汇表中不仅包含常用汉字,也包含常见的词语和词缀。
-
对于一个句子,它首先尝试匹配最长的、在词汇表中存在的单元。如果找不到,就把词拆分成更小的子词,直到所有部分都在词汇表中。
-
-
示例:
-
词汇表包含词语:
-
文本:
"人工智能很强大" -
分词结果:
[“人工”, “##智能”, “很”, “强大”] -
说明: “人工智能”被拆成了“人工”和“##智能”,其中
##表示这是一个词的后续部分。“强大”作为一个整体词存在于词汇表中。
-
-
词汇表不包含词语:
-
文本:
"韮菜盒子" -
分词结果:
[“韮”, “##菜”, “盒”, “##子”] -
说明: “韮菜”可能不在词汇表里,所以被拆成“韮”和“##菜”。“盒子”被拆成“盒”和“##子”,这是一种常见的子词组合。
-
-
-
优点:
-
平衡了词汇表大小和语义:常见词保持完整,生僻词或新词可以拆解。
-
更好的泛化能力:模型能通过“##子”理解“盒子”、“鞋子”、“孩子”等有共同词缀的词。
-
效率更高:序列长度比纯字符级短。
-
-
使用模型:很多后续优化的中文模型(如ERNIE, RoBERTa-wwm-ext)都采用了这种更智能的子词分词。
一、输入
二、输出
三、模型结构
四、处理流程
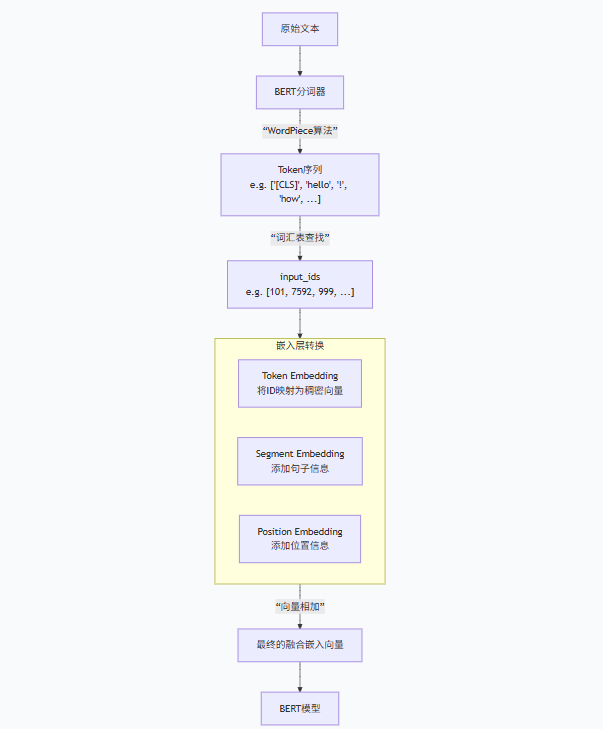
BERT 分词器通过 “基础分词 + WordPiece 子词拆分” 实现对文本的细粒度处理,既缓解了未登录词(OOV)问题,又保留了词的语义完整性,同时通过特殊符号和辅助信息适配模型的双向编码需求,是 BERT 模型性能的重要保障。
BERT 词汇表中每个词(token)对应的向量
1. 词汇表与初始向量的初始化
2. 词嵌入的动态学习过程
3. 词嵌入的最终形态
MLM网络结构详细分解
1. 输入表示 (Input Representation)
输入是一个经过处理的句子(或一对句子),其中部分Token被特殊处理。
-
原始Token:
[CLS]我 爱 自然 语言 处理[SEP] -
MLM处理后的Token(如图):
-
随机选择15%的Token作为待预测候选。
-
在这15%中:
-
80%的概率替换为
[MASK]:例如 “爱” ->[MASK] -
10%的概率替换为随机Token:例如 “语言” -> “苹果” (但此例中我们仍展示为更常见的
[MASK]) -
10%的概率保持不变:例如 “语言” -> “语言” (但此例中我们仍展示为更常见的
[MASK])
-
-
最终输入模型的是:
[CLS]我[MASK]自然[MASK]处理[SEP]
-
每个Token的输入表示由三部分相加构成:
-
Token Embeddings: 词嵌入,
[MASK]有自己对应的嵌入向量。 -
Segment Embeddings: 句子分段嵌入,用于区分两个句子。
-
Position Embeddings: 位置嵌入,表示每个Token在序列中的顺序。
2. BERT主干网络 (Backbone Network)
-
结构: 一个多层的(例如12层或24层)Transformer编码器堆叠而成。
-
核心机制: 每一层都包含一个多头自注意力机制和一个前馈神经网络。
-
功能: 通过自注意力机制,每个位置的Token都能与序列中的所有其他Token进行交互,从而生成一个上下文感知的编码向量。
-
输入输出:
-
输入: 序列的嵌入表示
(batch_size, sequence_length, hidden_size)。 -
输出: 经过深层Transformer编码后的序列表示,形状与输入相同。图中的
[MASK]位置对应的输出向量,已经包含了来自全局上下文的信息,用于预测原始词。
-
3. MLM输出层 (MLM Head)
这是MLM任务特有的部分,它只应用于被Mask的位置(或其候选位置)。
-
输入: BERT最后一层输出的、对应被Mask位置的上下文向量(例如,图中“爱”和“语言”位置对应的输出向量
T_[MASK]1和T_[MASK]2)。 -
结构:
-
一个线性层: 通常是一个前馈网络,使用GELU激活函数。这一步的作用是进行特征变换和降维(有时)。
-
Layer Normalization: 对输出进行标准化,稳定训练过程。
-
输出权重矩阵: 这是最关键的一步。使用BERT输入嵌入矩阵
W_embedding的转置 作为输出层的权重矩阵。-
动机: 这被称为 权重绑定,可以减少模型参数,并被认为能使输入和输出空间保持一致,提升模型性能。
-
-
-
输出: 一个大小为
vocab_size(例如30522)的概率分布。通过Softmax函数计算,表示该被Mask位置是词汇表中每个词的可能性。-
对于第一个
[MASK],模型会输出一个分布,其中 “爱” 的概率应该最高。 -
对于第二个
[MASK],会输出另一个分布,其中 “语言” 的概率应该最高。
-
4. 损失计算 (Loss Calculation)
-
计算方式: 使用交叉熵损失。
-
范围: 仅计算被Mask的那些位置的损失。图中未被Mask的位置(如“我”、“自然”、“处理”等)的输出不参与MLM的损失计算。
-
目标: 通过优化这个损失,BERT学会了如何根据上下文来预测被遮盖的词语,从而深入理解语言的内在规律。
训练模式 vs. 推理模式的重要区别
-
训练: 如上所述,模型可以同时看到多个被
[MASK]的Token,并并行地预测它们。因为训练时我们有真实标签,计算损失不需要依赖上一个预测结果。 -
推理: 标准的BERT本身并不直接用于像传统语言模型那样逐词生成文本。如果需要用MLM方式进行预测,通常做法是:
-
每次只Mask一个Token(或少量Token)。
-
让模型预测这个Token。
-
用预测出的词替换掉
[MASK],再预测下一个。
但这种方式效率很低。所以BERT通常用于完形填空(一次预测一个Mask)或作为特征提取器,而不是自回归文本生成。
-