开篇
-
为什么我要从头写 Transformer?
Follow CS336 的课程作业,个人探索理解一下 Transformer 的实现机制,为后面做推理优化打下基础。 -
读完本文你能获得什么?
大概了解这个课程的工作量,并且我有一些踩坑过的东西就可以避免了 -
仓库地址?
作业1个人仓库
如果有任何侵权,请联系我删除文章 -
实现的效果?
根据给定的提示词补充完整一个故事:

背景知识: Transformer
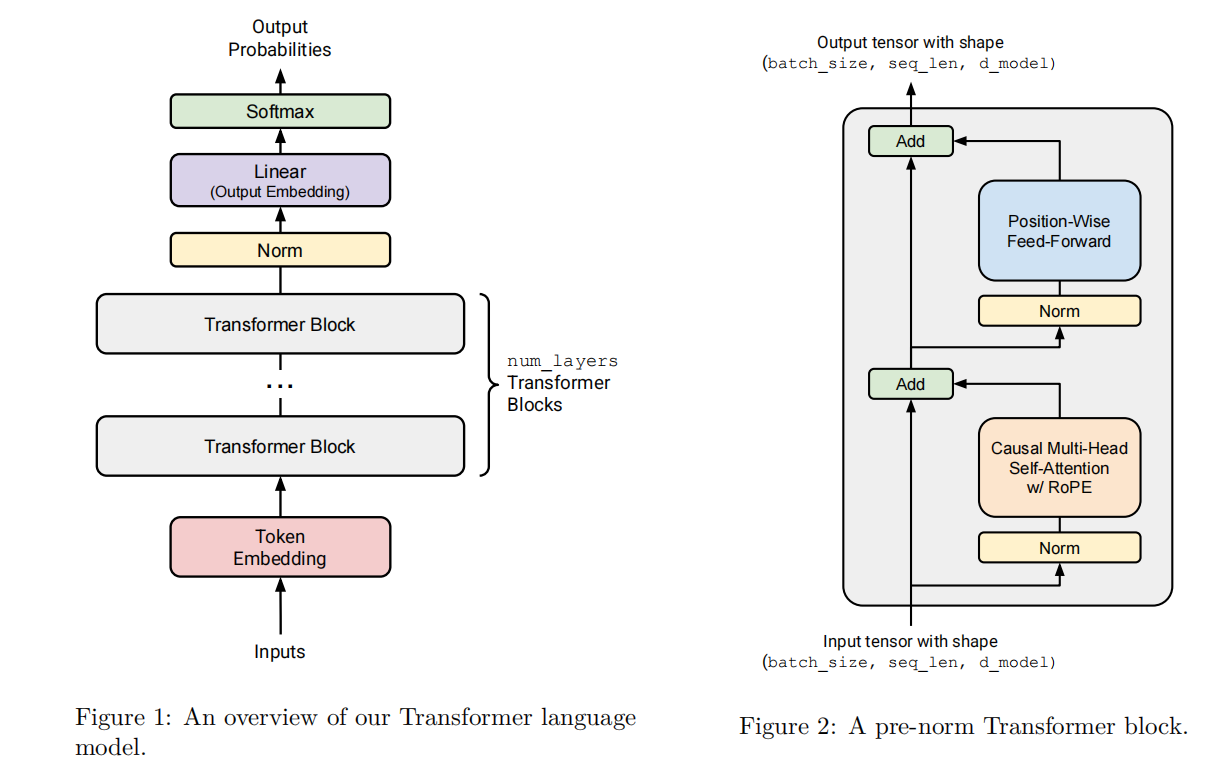
这里给出的结构是 课程中的 Transformer 结构,可以看出来大概由几个模块组成:
Token Embedding: 将输入的TokenID列表转化成输入表示的向量Transformer Blocks: 由num_layer个Transformer Block组成
这里每一个Transformer Block都包含注意力机制,RoPE,以及FFN的实现Norm: 再进行一次归一化操作Output Embedding & Softmax: 通过线性层,将归一化之后的结果转化成分类结果并且输出
模块实现及基本原理
Tokenizer
Tokenizer 是将输入的自然语言转换成 TokenId 的模块,用来数据处理以及生成 Token 使用;这里使用的计算方法是 BPE(byte-level byte-pair encoding) 按字节分组后逐渐合并的方法。具体方法可以参考材料Neural Machine Translation of Rare Words with Subword Units
下面给出流程图:
关于BPE的实现,最值得注意的是,每次更新所有 A B-> AB 这个步骤可以通过提前索引所有的 pair 和它们对应的 token list 来实现高效的查询和更新操作。
Q:为什么使用 Byte Level 的合并机制训练分词器,而不是直接使用字节作为输入或者词典作为输入?
A:如果直接使用字节训练,词表很短,但是同一个token的表示就会很长,并且丢失了很多语义信息;如果直接使用单词训练,词表很短,但是会有一些中间特征被忽略了,因此使用BPE可以很好的得到中间的特征表示。
Transformer Block
Self-Attention(注意力机制)
提到 Transformer 就不得不提到 经典的文章 Attention Is All You Need 给出的注意力机制的实现和 Transformer 模型。
关于注意力机制,个人理解是通过多次上下文的计算,求出上下文中词与词之间的相关性;这里有一篇比较好的博客可以参考注意力机制
这里直接引用实现的公式:
其中 \(Q\), \(K\) 和 \(V\) 是输入向量和权重向量相乘的结果,\(d_k\) 是模型参数
\(softmax\) 函数的表示是
简单来说,softmax 函数会把向量转化成概率表示,用于进一步的输出或者其他训练。
Mask
在注意力机制的实现过程中,还需要对于一些上下文的信息做隐藏操作;比如下面这个表格很好地体现了Mask的实现:
| 位置 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 1 | 0 | -∞ | -∞ | -∞ |
| 2 | 0 | 0 | -∞ | -∞ |
| 3 | 0 | 0 | 0 | -∞ |
| 4 | 0 | 0 | 0 | 0 |
第 1 行:生成第 1 个词时只能看自己;
第 3 行:生成第 3 个词时可看 1,2,3,不能看 4。
将这个矩阵加到原始的点积结果之后再进行softmax 操作就可以得到合法的token 概率输出
多头自注意力机制
简单来说,多头注意力机制通过并行运行多个Self-Attention层并综合其结果,能够通过不同的头的分解,得到更加丰富的信息表示
Pre-Norm
SwiGLU
Embedding
输入 Embedding层用于将输入的Token Id的整数值矩阵转换成每个Token的\(d_{\text{model}}\) 维度的向量;这里一定要转换成向量表示是用于后续 Transformer 的矩阵计算;
输入Embedding 的模型结构有些接近线性层的实现;这一层的输入是:
(batch_size, sequence_length) 的矩阵
输出是(batch_size, sequence_length, d_model) 维度的矩阵,其中Embedding 矩阵的参数是 (vocab_size, d_model);
(以下问题是AI生成的)
Q: 为什么Transformer 之类的架构可以把Embedding 层直接作为模型第一层?
A: 可以把 Embedding 层直接放在 Transformer 第一层,根本原因是 Transformer 的所有后续运算都是“纯数值运算”(矩阵乘法 + 非线性),它不要求输入具有任何空间或顺序先验。
位置信息表示 - RoPE
核心作用:将向量之间的位置信息加入注意力机制的计算中,使得模型可以学习到有关位置相关的信息
精华文章:RoPE
模型参数计算
结合上面提到的信息,让我们进行一个简单的模型参数计算;假设目前有一个模型参数配置:
- vocab_size : 50,257
- context_length : 1,024
- num_layers : 48
- d_model : 1,600
- num_heads : 25
- d_ff : 6,400
Q: 有多少训练参数?假设所有参数都是单精度的浮点数,加载模型需要多少内存?
输入/输出 Embedding:(vocab_size, d_model) = 2*80,411,200 = 160,822,400
单个Transformer Block:
- Attention层:
- \(W_Q:(h*d_k, d_{\text{model}})\)
- \(W_K:(h*d_k, d_{\text{model}})\)
- \(W_V:(h*d_v, d_{\text{model}})\)
这里的 \(d_k\)=\(d_v\)=\(d_{\text{model}}/h\)
-
FFN 层:$$\mathrm{FFN}(x)=\mathrm{SwiGLU}(x,W_1,W_2,W_3)=W_2!\bigl(\mathrm{SiLU}(W_1x)\odot W_3x\bigr)$$
- \(W_1, W_3: (d_\text{ff}, d_{\text{model}})\)
- \(W_2: (d_{\text{model}}, d_\text{ff})\)
因此单个 Transformer Block的参数是 \(W_{\text{block}} = 3*d_{\text{model}}*d_{\text{model}}+3*d_\text{ff}*d_{\text{model}}\) = 38400000
总计 \(\text{num_layers}*W_{\text{block}}=1,843,200,000\)
因此得到总计的模型参数量是:2B参数
参考网上的材料,GPT-2 XL 实际上只有1.5B的参数量,GPT-2 XL 的FFN并不是使用 SwiGLU训练的,因此会多出一些权重参数
训练模块
交叉熵
计算模型的输出与实际的值之间的差异,这里不加解释地给出公式:
其中
AdamW 优化器
同样不加解释地给出优化器公式
模型训练过程
环境:1张4090显卡(from AutoDL)
创建时间: 2025-08-27 00:36:35
实验配置
| 参数 | 值 |
|---|---|
| vocab_size | 10000 |
| context_length | 256 |
| d_model | 512 |
| num_layers | 4 |
| num_heads | 16 |
| d_ff | 1344 |
| rope_theta | 10000.0 |
| batch_size | 128 |
| max_iters | 5000 |
| learning_rate | 0.0003 |
| min_learning_rate | 1e-05 |
| warmup_iters | 1000 |
| weight_decay | 0.1 |
| grad_clip | 1.0 |
| data_path | data/tokenized_data.bin |
| split_ratio | 0.9 |
| device | cuda |
| seed | 42 |
训练结果
- 最终训练损失: 1.6731
- 最终验证损失: 1.6473
- 最终验证困惑度: 5.19
- 总训练时间: 1644.53 秒 (0.46 小时)
训练统计
- 总迭代次数: 4999
- 平均每迭代时间: 0.3290 秒
下图为训练完成的学习率曲线
