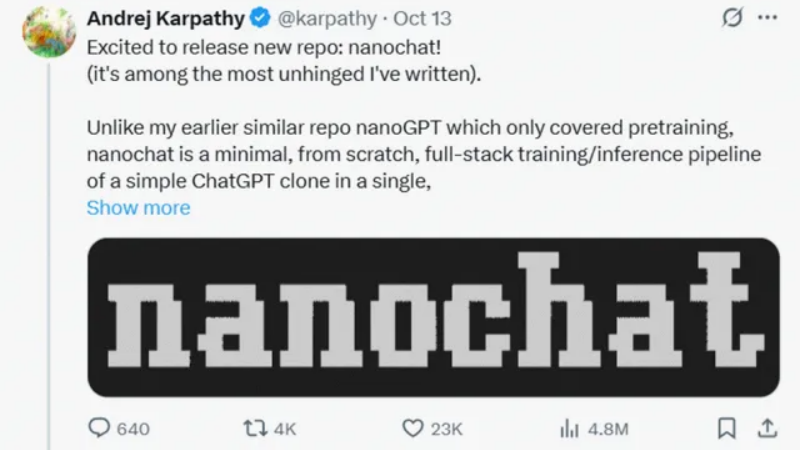
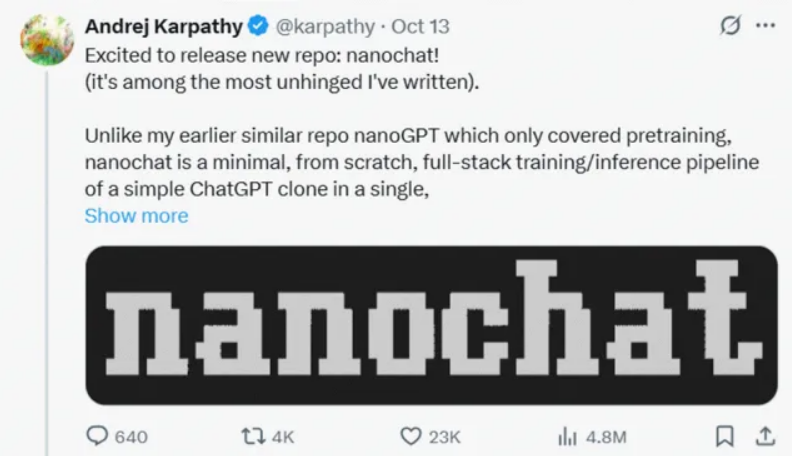
 10月13日,AI领域大神AndrejKarpathy发布了自己的最新开源项目。截至当前,GitHub项目上已经达到29.1KStar。
10月13日,AI领域大神AndrejKarpathy发布了自己的最新开源项目。截至当前,GitHub项目上已经达到29.1KStar。The best ChatGPT that $100 can buy.
10 月 13 日,AI 领域大神 AndrejKarpathy 发布了自己的最新开源项目。截至当前,GitHub 项目上已经达到 29.1KStar。
nanochat 是什么
nanochat 是 AI 领域专家 AndrejKarpathy 发布的开源项目,该项目包含从数据准备、预训练、中期训练、监督微调(SFT)、强化学习(RL)到推理部署的完整流程,约8000 行代码,其以极低成本和高效流程训练小型语言模型,实现类似ChatGPT 的对话功能。
AndrejKarpathy 表示,像 nanochat 这样的模型训练成本大概在 100 到 1000 美元之间,而 100 美元级别的模型的参数量只有GPT-3 的千分之一,只需使用 8张H100GPU 训练不到 4 小时,就可以训练出一个能够写故事/诗歌、回答简单问题的模型。
如果将预算增加到1000 美元,只需要训练约41.6 小时就能使模型性显著提升,能解决简单数学/代码问题并参与多项选择题测试。

GitHub 链接:
https://github.com/karpathy/nanochat
Lab4AI 链接:
https://www.lab4ai.cn/project/detail?utm_source=jssq_&id=f19f6e05f51a454d82383cc1ba250dde&type=project
| nanochat 的主要功能
虽然代码量只有8000 行,但是它也实现了以下功能:
全新Rust 分词器(Tokenizer)训练:使用Rust 语言实现训练分词器;
在FineWeb 数据集上预训练:在FineWeb 数据集上对 Transformer 架构的大语言模型进行预训练,并在多个指标上评估 CORE 分数;
中期训练:在SmolTalk 用户-助手对话数据集、多项选择题数据集、工具使用数据集上进行中期训练;
监督微调(SFT):在世界知识多项选择题数据集(ARC-E/C、MMLU)、数学数据集(GSM8K)、代码数据集(HumanEval)上进行监督微调;
强化学习(RL)优化:使用“GRPO”算法在 GSM8K 数据集上对模型进行强化学习微调;
高效推理引擎:实现高效模型推理,支持KV 缓存、简易预填充/解码流程、工具使用(轻量级沙箱环境中的 Python 解释器),并通过 CLI 或类 ChatGPT 的 WebUI 与模型交互;
自动训练总结:生成单一的Markdown 格式报告卡,总结整个训练推理流程,并以“游戏化”形式展示结果。
一键复现
过去提到LLM 训练,人们脑海里浮现的是动辄上百万美元的算力成本、庞大的研发团队和海量的数据储备,这让个人开发者和中小型团队望而却步;
而nanochat 不仅将成本压缩至100 美元,大模型实验室Lab4AI 更通过“一键体验”模式,让这个几乎人人可承担的价格真正转化为“人人可操作”的尝试,不再需要纠结环境配置、流程调试,普通人跟着指引就能亲手搭建属于自己的简易版 ChatGPT,这种“低门槛+ 易操作”的组合,也恰好解决了学习者“纸上谈兵”的痛点——以往看过无数教程却仍不知全流程如何落地,
如今大模型实验室Lab4AI 推出的 nanochat 体验项目“100 美元实现自己的 ChatGPT”。
提供从数据准备到推理服务的“一键式”全流程工具链,学习者不用再为环境搭建、代码调试耗费精力,只需跟着引导逐步操作,就能直观感受模型训练的每一个环节,让“无从下手”变成“步步有迹可循”。
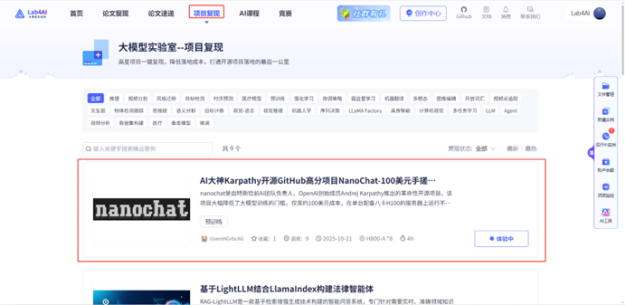
Step1:登录 Lab4AI.cn。
在“项目复现”中找到“AI 大神 Karpathy 开源 GitHub 高分项目 NanoChat-100 美元手搓 ChatGPT”。
项目内已经提供完整的复现NanoChat 的全流程代码和环境,您只需配置 8 卡,即可手搓 ChatGPT。
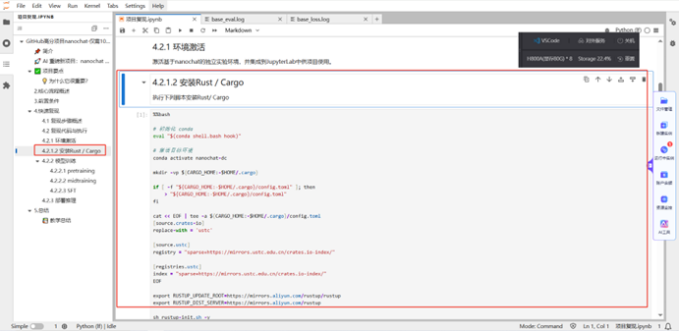
Step2:环境激活。
系统内已经预置可用的conda 虚拟环境,此环境可满足后续步骤的需要。您只需执行下列脚本安装 Rust/Cargo。
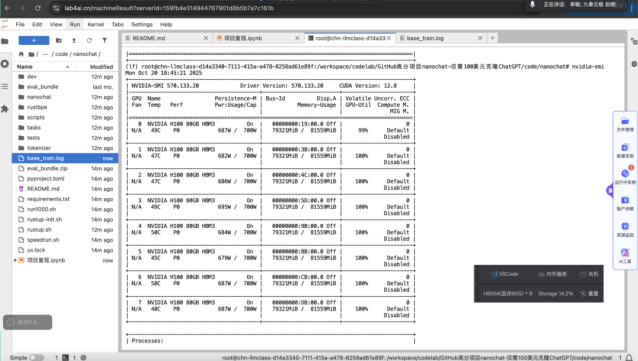
Step3:模型训练。
本次复现中,我们将训练分为pretrain、midtrain 和 SFT 三个阶段。pretrain 阶段约需要 2.5-3 小时,midtrain 阶段约耗时 30 分钟内。
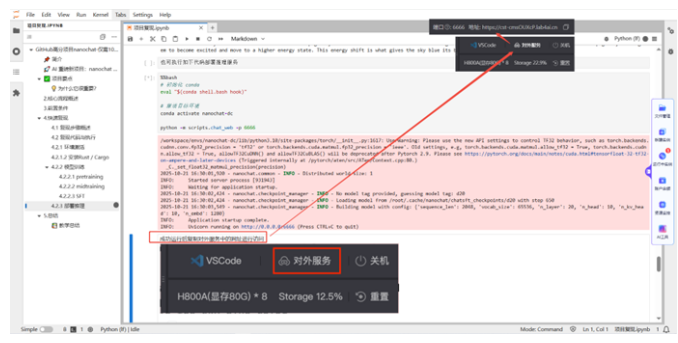
下方为训练时各卡的工作状态。从图中看,8 块 NVIDIAH10080GB 显卡已经全部运行中,几乎吃满了所有的 GPU 算力。
您可以通过监控这些指标,亲眼看到模型是如何被“训练”出来的。
Step4:模型评估。
每个训练阶段有相应的评估程序输出结构化评估结果。
以下是本次实践的pretrain 后的评估结果,从结果得知:模型初步掌握了世界运作的基本逻辑。PIQA(物理互动问答):61.26%,表明模型已经初步掌握了世界运作的基本逻辑。COPA(因果推理):54.00%,表明模型开始具备初步的因果判断能力。Winograd(指代消解):56.04%,表明模型能处理一些简单的句法歧义。
当面对复杂推理的阅读理解任务能力很弱。ARCEasy(基础科学问答):45.50%,表明模型掌握了一些基础的科学知识,但还不够牢固。ARCChallenge(挑战科学问答):26.79%,表明模型缺乏深度的、学科性的知识。
面对知识密集型与复杂逻辑任务时,模型表现出了短板。
Jeopardy!(知识问答):0.90%,
SQuAD(阅读理解):1.59%,
CoQA(对话式问答):4.31%,
OpenBookQA(开卷问答):26.40%。
Step5:部署推理。
训练完成的模型支持如下两种推理方式:通过命令行的方式进行推理;通过WebUI 的方式进行推理。
(1)通过命令行对话,执行后即可在下方看到推理内容。

(2)通过WebUI 执行对话。执行代码后,鼠标滑过右上角的【对外服务】,将链接复制到浏览器,打开后即可对话。
Lab4AI 支撑从研究到落地
Lab4AI 提供除了一键复现之外,还提供更多的价值:
1. 如果你是科研党
每日更新Arxiv 上的论文,支持翻译、导读、分析,帮你快速跟进前沿研究;还能一键复现其他大模型;若你有自己的数据集,能直接在平台上进行代码微调,平台还支持使用 LLaMA-Factory 进行 WebUI 微调大模型,甚至对接投资孵化资源,把科研创意变成落地成果。


2.如果你是学习者
如果你想掌握大模型相关技能,Lab4AI 的优势更明显:Lab4AI 提供多种在线课程,更有LLaMA Factory 官方合作课程,让您理论学习和代码实战同时进行。LLaMA Factory 官方合作课程课程聚焦于当下最受欢迎的LLaMA Factory 框架,带您从理论到实践,一站式掌握大模型定制化的核心技能,课程还送 300 元算力、完课证书。