借助 ChatGPT API 将 AI 集成到测试自动化框架中
了解如何通过集成 AI 为自动化框架生成真实数据、检测日志异常,并提升 CI/CD 运行的可靠性。
当我第一次尝试在测试自动化框架中集成 AI 时,以为它仅能用于少数基础场景。经过几次实验后,我发现 ChatGPT API 在多个方面切实帮我节省了时间,还增强了测试自动化框架的功能:生成真实测试数据、在白盒测试中分析日志,以及处理 CI/CD 中的不稳定测试(抖动测试)。
一、ChatGPT API 入门
ChatGPT API 是 OpenAI 提供的编程接口,基于 HTTP(s)协议运行。它允许开发者发送请求,并从选定的模型中获取原始文本、JSON、XML 或其他任意偏好格式的输出结果。
API 文档通俗易懂,包含请求/响应体示例,让首次调用变得简单直接。我只需在 OpenAI 开发者平台生成 API 密钥,将其配置到框架属性中即可完成请求认证。
二、构建 API 集成客户端
我分别用 Java 和 Python 实现了集成,核心逻辑一致:发送 JSON 格式的 POST 请求并读取响应,因此该模式几乎可应用于所有编程语言。由于我更倾向于在自动化中使用 Java,以下是客户端的示例代码:
import java.net.http.*;
import java.net.URI;
import java.time.Duration;public class OpenAIClient {private final HttpClient http = HttpClient.newBuilder().connectTimeout(Duration.ofSeconds(20)).build();private final String apiKey;public OpenAIClient(String apiKey) { this.apiKey = apiKey; }public String chat(String userPrompt) throws Exception {String body = """{"model": "gpt-5-mini","messages": [{"role":"system","content":"你是测试自动化领域的得力助手..."},{"role":"user","content": %s}]}""".formatted(json(userPrompt));HttpRequest req = HttpRequest.newBuilder().uri(URI.create("https://api.openai.com/v1/chat/completions")).timeout(Duration.ofSeconds(60)).header("Authorization", "Bearer " + apiKey).header("Content-Type", "application/json").POST(HttpRequest.BodyPublishers.ofString(body)).build();HttpResponse<String> res = http.send(req, HttpResponse.BodyHandlers.ofString());if (res.statusCode() >= 300) throw new RuntimeException(res.body());return res.body();}
}
你可能已经注意到,请求体中的一个查询参数是 GPT 模型。不同模型在速度、成本和功能上存在差异:部分模型速度更快,部分成本更低,还有些支持多模态而另一些不支持。因此,在集成 ChatGPT API 前,建议先确定最适合业务场景的模型,并为其设置使用限制。在 OpenAI 官网中,你可以找到模型对比页面,通过多模型横向对比做出更合适的选择。
此外,自定义客户端还可扩展支持服务器推送流事件(server-sent streaming events),实现结果实时生成实时展示;也可集成实时 API(Realtime API)以支持多模态场景。这些功能可用于实时处理日志和错误,即时识别异常。
三、集成架构
根据我的经验,只有将 ChatGPT API 应用于合适的测试场景,集成才有实际意义。我在实践中发现了前文提到的三个真实应用场景,下面将详细解析:
(一)用例 1:测试数据生成
我尝试的第一个场景是为自动化测试生成测试数据。相比依赖硬编码值,ChatGPT 能提供丰富且真实的数据集------从包含家庭信息的用户档案,到精密科学领域使用的专属数据均可生成。在我的实践中,这种多样化的数据帮助发现了许多硬编码数据或固定数据集永远无法触及的问题,尤其是在边界值和罕见边缘场景方面。
下图展示了集成 ChatGPT API 生成测试数据的工作流程:首先 TestNG 运行器启动测试套件,在执行测试前,向 ChatGPT API 请求自动化测试所需数据;随后测试数据在数据提供层进行处理,自动化测试将基于新生成的数据执行,并进行预期断言验证。
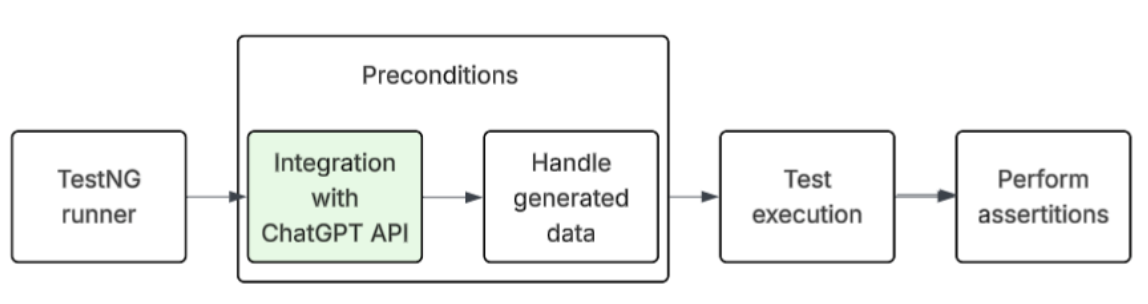
流程节点:TestNG 运行器 → ChatGPT API → 数据集成处理 → 测试执行 → 断言验证
代码示例
class TestUser { public String firstName, lastName, email, phone; public Address address;
}
class Address { public String street, city, state, zip;
}public List<TestUser> generateUsers(OpenAIClient client, int count) throws Exception {String prompt = """仅生成严格符合JSON格式的测试用户数据。数据结构:{"users":[{"firstName":"","lastName":"","email":"","phone":"","address":{"street":"","city":"","state":"","zip":""}}]}生成数量 = %d。仅输出JSON,无需其他文本。""".formatted(count);String content = client.chat(prompt);JsonNode root = new ObjectMapper().readTree(content);ArrayNode arr = (ArrayNode) root.path("users");List<TestUser> out = new ArrayList<>();ObjectMapper m = new ObjectMapper();arr.forEach(n -> out.add(m.convertValue(n, TestUser.class)));return out;
}
该方案解决了测试数据重复的问题,有助于更早发现错误和异常。主要挑战在于提示词的可靠性------如果提示词不够严格,模型可能会添加额外文本,导致 JSON 解析器报错。在我的实践中,提示词版本控制是管控优化过程的最佳方式。
(二)用例 2:日志分析
在我最近接触的一些开源项目中,自动化测试还通过分析日志来验证系统行为。在大多数这类测试中,团队期望调用某个 REST 接口后,特定消息能出现在应用控制台、DataDog 或 Loggly 等日志工具中------这类测试在团队进行白盒测试时非常必要。
但如果更进一步,将日志发送给 ChatGPT,让它检查消息序列并识别可能对服务至关重要的潜在异常,会产生怎样的效果?
这种集成的工作流程如下:
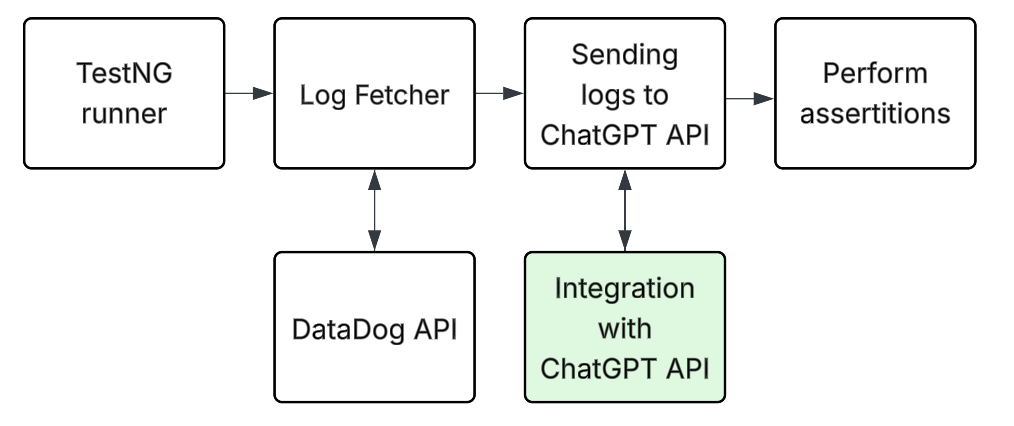
流程节点:TestNG 运行器 → 日志获取器(Log Fetcher) → 数据脱敏处理 → ChatGPT API → 断言执行 核心集成:DataDog API 与 ChatGPT API 联动
当自动化测试获取服务日志(例如通过 Datadog API)后,会对日志进行分组,并将经过清洗的片段发送给 ChatGPT API 进行分析。ChatGPT API 需返回带置信度得分的结构化判定结果:若标记异常,测试失败并显示响应中的原因;否则测试通过。这种方式既能保持断言的针对性,又能捕捉到未明确编码的意外模式。
代码示例
// 脱敏中间件(保持简洁高效)
public final class LogSanitizer {private LogSanitizer() {}public static String sanitize(String log) {if (log == null) return "";// 脱敏API密钥log = log.replaceAll("(?i)(api[_-]?key\\s*[:=]\\s*)([a-z0-9-_]{8,})", "$1[已脱敏]");// 脱敏JWT令牌log = log.replaceAll("([A-Za-z0-9-_]{20,}\\.[A-Za-z0-9-_]+\\.[A-Za-z0-9-_]+)", "[已脱敏JWT]");// 脱敏邮箱地址log = log.replaceAll("[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+", "[已脱敏邮箱]");return log;}
}// 定义结构化判定结果模型
record Verdict(String verdict, double confidence, List<String> reasons) {}public Verdict analyzeLogs(OpenAIClient client, String rawLogs) throws Exception {String safeLogs = LogSanitizer.sanitize(rawLogs);String prompt = """你是日志分析助手。给定日志,检测异常内容(错误、超时、堆栈跟踪、不一致序列)。仅返回以下格式的JSON,严格遵循该结构:{"verdict":"PASS|FAIL","confidence":0.0-1.0,"reasons":["...","..."]}日志(UTC时间):----------------%s----------------""".formatted(safeLogs);// 调用模型并解析JSON内容字段String content = client.chat(prompt);ObjectMapper mapper = new ObjectMapper();JsonNode jNode = mapper.readTree(content);String verdict = jNode.path("verdict").asText("PASS");double confidence = jNode.path("confidence").asDouble(0.0);List<String> reasons = mapper.convertValue(jNode.path("reasons").isMissingNode() ? List.of() : jNode.path("reasons"),new com.fasterxml.jackson.core.type.TypeReference<List<String>>() {});return new Verdict(verdict, confidence, reasons);
}
在实现这类集成前,需注意日志通常包含敏感信息(如 API 密钥、JWT 令牌或用户邮箱),直接将原始日志发送到云 API 存在安全风险,因此必须进行数据脱敏处理。这也是我在示例中添加 LogSanitizer 中间件的原因------确保日志发送到 ChatGPT API 前,敏感数据已被脱敏。
同时需要明确,这种方式不能替代传统断言,而是对其进行补充。你可以用它替代数十个复杂检查,让模型自动检测异常行为。关键是将 ChatGPT API 的判定结果视为建议,最终决策由自动化框架根据设定的阈值做出------例如,仅当置信度高于 0.8 时,才判定测试失败。
(三)用例 3:测试稳定性优化
测试自动化中最常见的问题之一是不稳定测试(抖动测试)的出现。测试失败可能由多种原因导致,包括 API 契约或接口变更,而最糟糕的情况是因测试环境不稳定导致失败。通常,团队会为这类不稳定测试启用重试机制:多次运行测试直至通过,或连续三次失败后判定测试失败。但如果让 AI 决定测试是否需要重启,或直接标记为失败/通过,会有怎样的改进?
这种思路在测试框架中的应用流程如下:
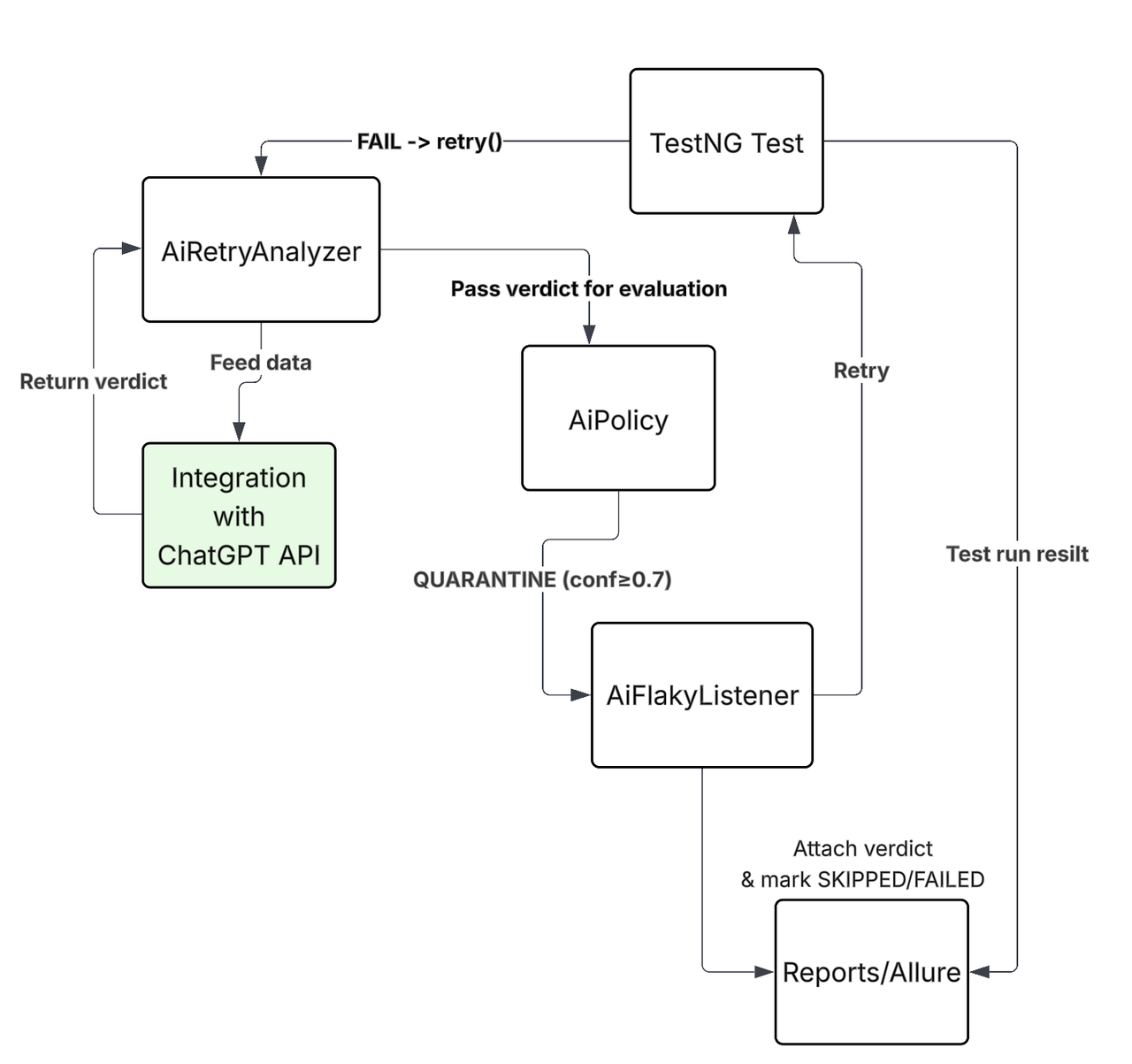
流程节点:测试失败 → AI 重试分析器(AiRetryAnalyzer) → 收集上下文数据 → ChatGPT API → AI 策略(AiPolicy) → 决策执行 决策分支:置信度≥0.7 → 隔离测试(QUARANTINE);其他情况 → 重试或标记失败 辅助组件:AI 不稳定测试监听器(AiFlakyListener) → 附加判定结果并标记跳过/失败 → Allure 报告
当测试失败时,首先收集尽可能多的上下文信息,包括堆栈跟踪、服务日志、环境配置,以及(如适用)代码差异。将所有这些数据发送给 ChatGPT API 进行分析,获取判定结果后传递给AiPolicy。
至关重要的是,不能让 ChatGPT 独立做出决策:若置信度足够高,AiPolicy可将测试隔离,避免流水线被阻塞;若置信度低于特定阈值,可重试测试或直接标记失败。我认为应始终将决策逻辑保留在自动化框架中,以保持对测试结果的控制,同时充分利用 AI 集成的价值。
该方案的核心目标是节省不稳定测试的分析时间,减少不稳定测试的数量。经过 ChatGPT 处理后的报告信息量更丰富,能更清晰地揭示失败的根本原因。
四、结语
我认为将 ChatGPT API 集成到测试自动化框架中,是扩展框架功能的有效方式,但这种集成存在一些权衡因素,需要谨慎考量。
其中最重要的因素之一是成本。例如,在包含 1000 个自动化测试的套件中,每次运行约有 20 个测试失败,将日志、堆栈跟踪和环境元数据发送到 API 的每次运行,可能会消耗超过 50 万个输入令牌;若再加上测试数据生成,令牌消耗会迅速增加。我认为关键在于成本与数据量直接相关:发送的数据越多,费用越高。
另一个主要问题是安全和隐私风险。日志和测试数据通常包含 API 密钥、JWT 令牌或用户数据等敏感信息,在生产环境中,将原始数据发送到云端几乎是不可接受的。在实践中,这意味着要么使用部署在本地的开源大语言模型(如 LLaMA),要么在框架与 API 之间添加脱敏/匿名化层,确保敏感字段在离开测试环境前被移除或替换。
模型选择也很关键。我发现,在许多情况下,最佳策略是混合使用不同模型:小型模型用于常规任务,仅在确实需要更高准确性的场景中使用大型模型。
考虑到这些因素,ChatGPT API 仍能为测试工作带来实际价值:帮助生成真实测试数据、更智能地分析日志,以及更轻松地管理不稳定测试。集成还能让报告更具信息量,添加测试人员原本需要手动调研的上下文和分析内容。
正如我在实践中观察到的,要有效利用 AI,需要控制成本、保护敏感数据,并将决策逻辑保留在自动化框架中,以实现对 AI 决策的有效管控。这让我想起自动化发展初期,团队们也曾权衡利弊,寻找技术真正的价值所在。