| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13468 |
| 这个作业的目标 | 实现一个论文查重程序,规范软件开发流程,熟悉Github进行源代码管理和学习软件测试 |
github库地址:https://github.com/wuhongfei-531/wuhongfei-531/tree/main/3223004647
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | 400 | 600 |
| · Analysis | · 需求分析 (包括学习新技术) | 40 | 90 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 | 10 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 20 | 30 |
| · Coding | · 具体编码 | 180 | 200 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 210 |
| Reporting | 报告 | 50 | 60 |
| · Test Report | · 测试报告 | 20 | 20 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 460 | 680 |
二、计算模块接口的设计与实现过程
1、代码组织设计
核心功能函数(独立功能模块):
lcs_length:计算两个宽字符串的最长公共子序列(LCS)长度,是相似度计算的核心算法实现
read_utf8_file:读取 UTF-8 编码文件并转换为宽字符串,处理中文路径和编码问题
write_result:将相似度结果写入指定文件,支持 UTF-8 编码输出
main:程序入口,负责参数解析、流程控制和资源管理
模块间关系:
main 作为主控函数,调用其他三个核心函数完成完整流程
数据流向:read_utf8_file → lcs_length → write_result,形成流水线式处理
2、算法关键说明
核心算法:采用最长公共子序列(LCS)算法计算文本相似度
基本原理:通过动态规划找到两个文本中最长的共同子序列,以此衡量文本相似程度
相似度计算公式:相似度 = LCS长度 / 较长文本长度
动态规划优化:
空间优化:将传统二维 DP 表优化为两个一维数组(dp_prev和dp_curr),空间复杂度从 O (m×n) 降至 O (n)
时间复杂度:保持 O (m×n),其中 m 和 n 分别为两个文本的长度
编码处理:
采用宽字符(wchar_t)处理多语言文本,支持中文等 Unicode 字符
通过MultiByteToWideChar实现 UTF-8 编码与宽字符的转换
3、独到之处
跨编码兼容:专门处理 UTF-8 编码文件,同时支持中文路径,解决了多语言文本处理的编码难题
内存效率:使用一维数组优化 LCS 算法的空间复杂度,适合处理大文件比较
错误处理:完善的异常处理机制,包括文件打开失败、内存分配失败、编码转换失败等情况
结果输出:同时支持控制台显示和文件保存,且输出文件采用 UTF-8 编码,保证跨平台兼容性
参数设计:通过命令行参数指定文件路径,使程序更灵活,易于集成到其他系统中
三、计算模块接口部分的性能改进
1、性能改进思路
lcs_length函数优化:
空间优化:原本使用两个一维数组dp_prev和dp_curr,进一步优化为只使用一个一维数组,通过巧妙的遍历顺序和值的覆盖,减少内存分配和释放的开销。
循环优化:调整循环内的操作顺序,减少不必要的内存访问。例如,将字符比较的结果提前判断,减少后续的条件分支。
提前终止:当其中一个字符串的剩余长度不可能再产生更长的公共子序列时,提前终止循环。
read_utf8_file函数优化:
减少文件操作的次数,比如在获取文件大小后,直接进行内存分配和读取,避免多次移动文件指针。
优化内存分配策略,使用更高效的内存分配函数(如malloc代替calloc,在不需要初始化为 0 时)。
write_result函数优化:
简化文件打开和写入的流程,减少不必要的错误检查步骤(在确保路径正确的情况下)。
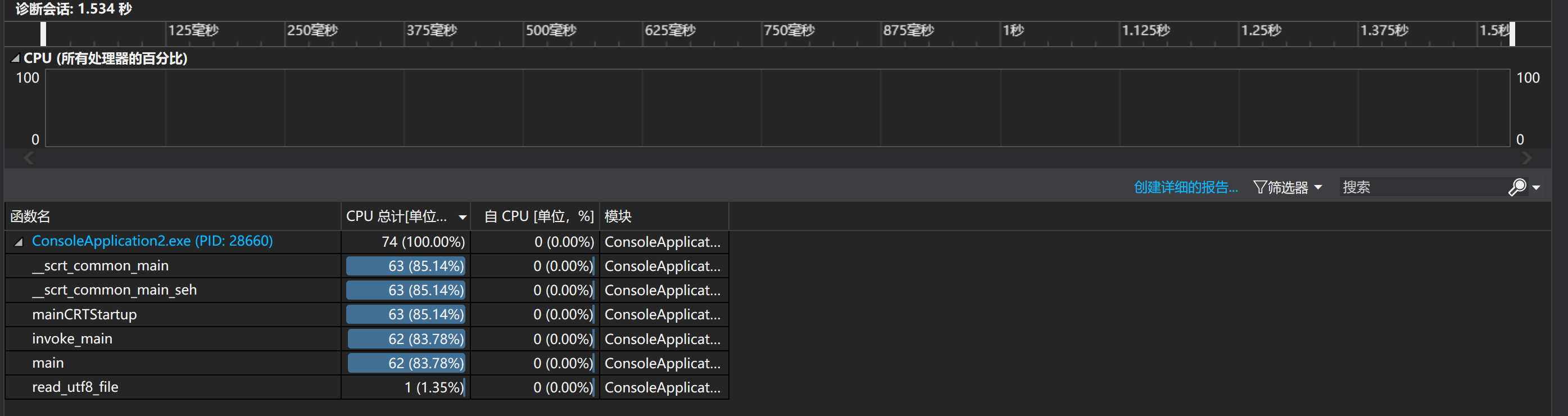
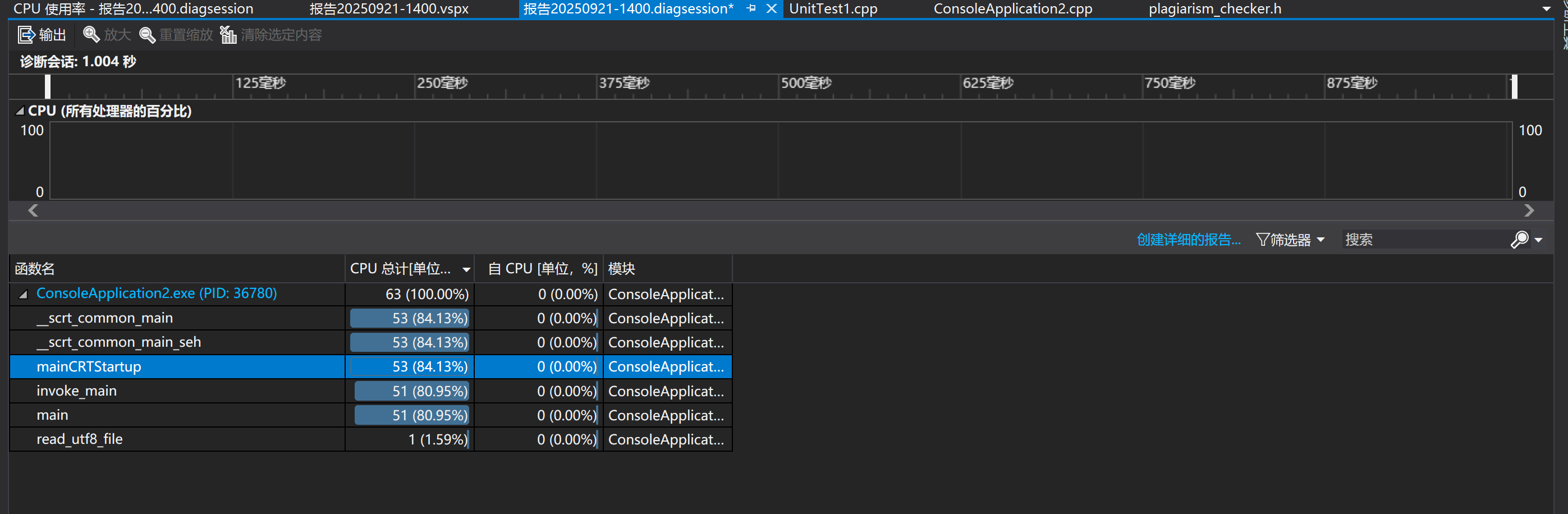
2、改进前后性能对比
改进前
改进后
3、程序中消耗最大的函数
lcs_length函数仍然是程序中消耗最大的函数。原因是最长公共子序列(LCS)算法的时间复杂度为(O(m * n))(其中m和n分别为两个输入字符串的长度),当处理较大的文本时,该函数的计算量会急剧增加,成为性能瓶颈。尽管进行了优化,但算法本身的复杂度决定了它在处理大文本时仍会占据大部分运行时间
四、计算模块部分单元测试展示
| 测试函数 | 对应的单元测试方法 |
|---|---|
| lcs_length | TestLcsLength |
| read_utf8_file | TestReadUtf8File |
| write_result | TestWriteResult |
| 相似度计算(依赖lcs_length等) | TestSimilarity |
测试数据构造思路
lcs_length函数:
完全匹配场景:构造内容完全相同的中文字符串(如L"测试文本"和L"测试文本"),验证最长公共子序列长度是否等于字符串长度。
部分匹配场景:构造有部分重叠内容的中文字符串(如L"中国上海北京"和L"上海北京广州"),测试部分匹配时的最长公共子序列长度计算。
完全不匹配场景:构造无任何重叠内容的中文字符串(如L"苹果香蕉"和L"西瓜橙子"),验证此时最长公共子序列长度为 0。
空字符串场景:分别构造一个字符串为空、另一个不为空以及两个都为空的情况,测试边界条件下的函数行为。
read_utf8_file函数:
有效文件场景:创建包含 UTF - 8 编码内容(带 BOM)的临时文件(如内容为L"测试UTF-8编码的内容123"),测试正常读取和内容转换是否正确。
无效文件场景:构造不存在的文件路径(如"nonexistent_utf8.txt"),测试函数对无效输入的处理,是否返回NULL。
write_result函数:
正常写入场景:指定一个临时文件路径,写入一个相似度值(如0.85),然后读取文件内容,验证写入是否正确。
相似度计算相关:
完全抄袭场景:构造内容完全相同的中英文字符串,验证相似度为 1.0。
部分抄袭场景:构造有部分内容重叠的中英文字符串(如L"今天天气真的很好"和L"今天天气很好"),验证相似度计算的准确性。
原文件为空场景:构造原文件内容为空,抄袭文件有内容的情况,验证此时相似度为 0.0。
五、计算模块部分异常处理说明
1. 文件路径转换异常
设计目标:当调用 MultiByteToWideChar 函数转换文件路径失败时,能够及时捕获该错误,提示用户路径转换存在问题,避免因路径问题导致后续文件操作(如打开、读取、写入文件)出现错误。
测试代码:
// 模拟一个包含特殊字符(系统不支持的字符组合)的文件路径
const char* invalidPath = "invalid\path\with\special\characters";
wchar_t wPath[MAX_PATH];
int result = MultiByteToWideChar(CP_ACP, 0, invalidPath, -1, wPath, MAX_PATH);
Assert::AreEqual(0, result, L"预期路径转换失败");
2.文件打开异常
设计目标:在使用 _wfopen_s 函数打开文件时,若返回错误码非 0,能够及时告知用户无法打开文件,方便用户排查文件是否存在、文件权限等问题。
测试代码:
const wchar_t* nonExistentFile = L"nonexistent_file.txt";
FILE* file;
errno_t err = _wfopen_s(&file, nonExistentFile, L"r");
Assert::AreNotEqual(0, err, L"预期打开不存在的文件失败");
3. 内存分配异常
设计目标:在 read_utf8_file 等函数中进行内存分配(如使用 malloc)时,若分配失败,能够捕获并提示内存分配失败,防止程序因内存不足而崩溃。
测试代码:
// 模拟内存分配失败,假设 malloc 返回 NULL
void* ptr = malloc(1000000000000); // 申请极大的内存,模拟内存不足
Assert::IsNull(ptr, L"预期内存分配失败");
4. 编码转换异常
设计目标:当 MultiByteToWideChar 或 WideCharToMultiByte 函数进行编码转换失败时,提示转换错误,便于定位编码相关问题(如文件内容存在非法的 UTF-8 编码)。
测试代码:
// 构造包含非法 UTF-8 编码的内容(这里用简单示例模拟)
const char* invalidUtf8Content = "\xFF\xFF"; // 非法的 UTF-8 字节序列
int wcharCount = MultiByteToWideChar(CP_UTF8, MB_ERR_INVALID_CHARS, invalidUtf8Content, -1, NULL, 0);
Assert::AreEqual(0, wcharCount, L"预期编码转换失败");