github链接 https://github.com/yasinalong/3123004077
首部
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 熟悉一套软件开发的流程 |
psp
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 240 | 300 |
| Development | 开发 | 190 | 250 |
| · Analysis | · 需求分析(包括学习新技术) | 60 | 100 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 | 10 | 15 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 15 | 20 |
| · Coding | · 具体编码 | 45 | 50 |
| · Code Review | · 代码复审 | 15 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 15 | 20 |
| Reporting | 报告 | 50 | 55 |
| · Test Report | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 15 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结,并提出过程改进计划 | 15 | 10 |
| 合计 | 240 | 305 |
开发步骤
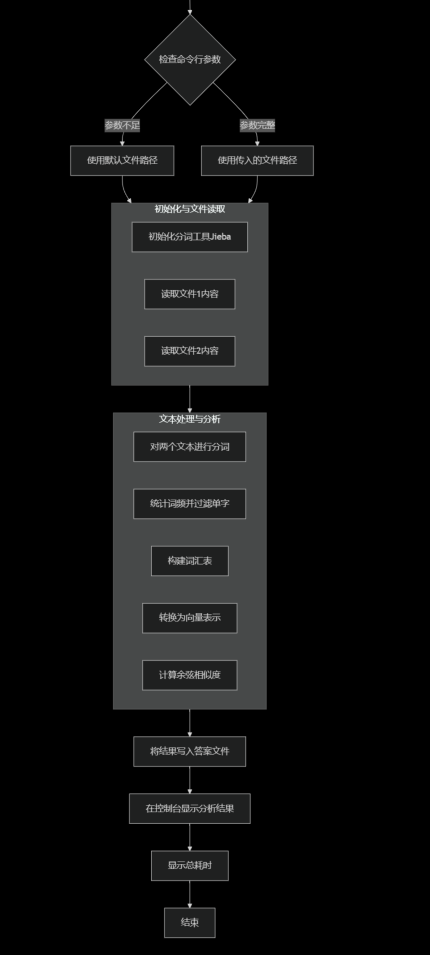
1.git clone下GitHub上面的cppjieba项目,然后进行测试

问题1.jieba的初始化非常慢,在vs的debug环境下需要大概6s的时间,这个速度实在是太慢了
解决办法:调整为release的环境下即可是快速加载大概需要500ms,提升了整整10倍的效率
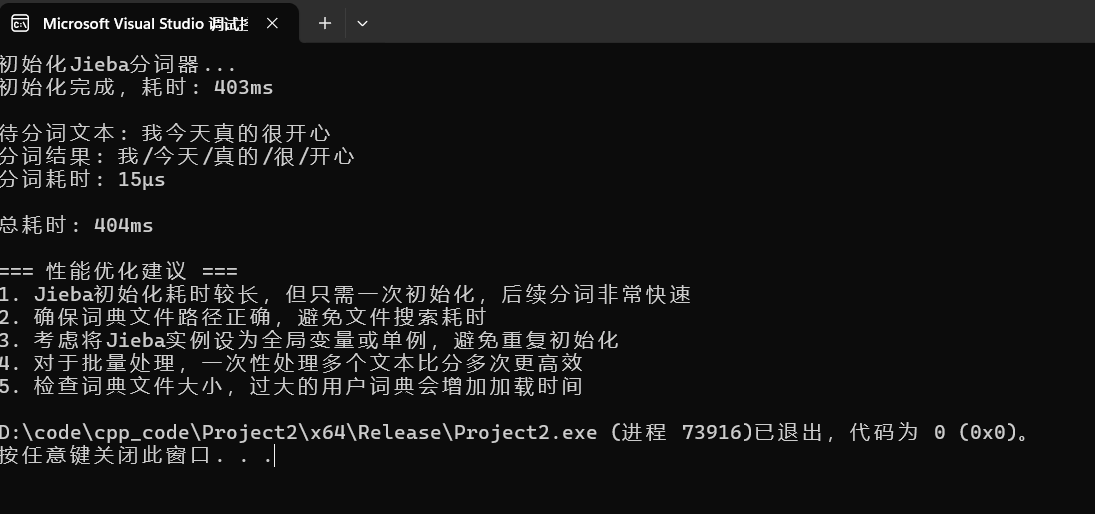
2.加载两个文件在到内存中,然后进行分词,已经进行简单的文本初始化
性能消耗:分词完成平均消耗1s
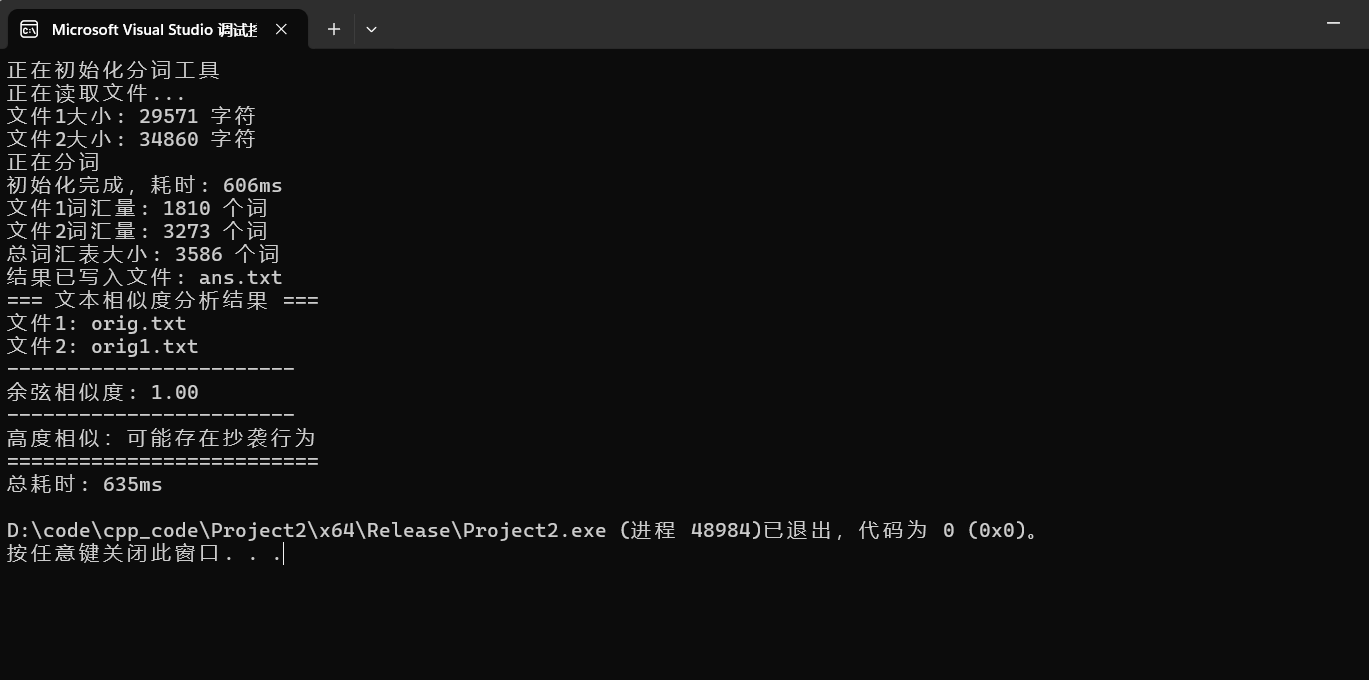
3.构建词汇表,文本向量化,计算余弦相似度
函数解析图及其作用
1.std::string readFile(const std::string& filePath)
读取文件内容到内存中去
2.std::unordered_map<std::string, int> preprocessText(cppjieba::Jieba& jieba, const std::string& text)
文本处理,分词,去掉重复的词,统计词的频率
3.std::vectorstd::string buildVocabulary(const std::unordered_map<std::string, int>& freq1,const std::unordered_map<std::string, int>& freq2)
构建词汇表
4.std::vector convertToVector(const std::unordered_map<std::string, int>& wordFreq,const std::vectorstd::string& vocabulary)
将词频转化为向量
5.double cosineSimilarity(const std::vector& vec1, const std::vector& vec2)
计算余弦相似度
6.void writeFile(const std::string& ansPath, double cosineSim)
把结果写回文件
7.void displayResults(double cosineSim, const std::string& file1, const std::string& file2)
显示结果在屏幕上
性能分析
1.性能占用

2.函数分析

性能瓶颈主要是jieba的初始化词库需要加载很长的时间
算法测试
void runtext(std::string& text1, std::string& text2)
{//用于测试text1 = "自然语言处理是人工智能领域中的一个重要方向,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。";//text2 = "量子计算是一种遵循量子力学规律调控量子信息单元进行计算的新型计算模式,它与传统计算机原理完全不同。";//text2 = "自然语言处理是人工智能领域中的一个关键方向,它研究能实现人与计算机之间用自然语言进行有效交流的各种理论和方法。";//text2 = "自然语言处理是AI领域中的一个重要方向,它研究能实现人类与电脑之间用自然语言进行有效通信的各种理论和方法。";text2 = "人工智能领域中的一个重要方向是自然语言处理,它研究各种理论和方法,能实现人与计算机之间用自然语言进行有效通信。";
}
测试函数结果 分别是 0.26 0.91 0.91 0.97