此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第一课第一周,即1.1到1.6部分的内容笔记
1.课程内容
第一周的内容较为简单,并不涉及具体实操,其地位相当于教材中的绪论部分,简单介绍了神经网络(Neural Network,NN)和深度学习(Deep Learning,DL)相关的基本概念,优势与课程计划等内容。
因此,总结本章内容时会省去课程介绍部分,并添加相当一部分的基础知识以便理解。
1.1 什么是神经网络?
课程中并未照本宣科地给出神经网络的定义,而是通过预测房价的例子来理解神经网络。
这里先给出网络中对神经网络的一种阐述:
神经网络是受生物神经系统启发而设计的计算模型,旨在模拟人脑的工作方式,用于解决复杂的模式识别和学习问题。它由多个节点(也叫神经元)构成,这些节点按照不同的层级(输入层、隐藏层、输出层)组织,通过加权连接相互连接。神经网络的核心思想是通过训练过程调整这些连接的权重,以最小化预测输出与实际结果之间的误差,从而使模型能够在新数据上进行准确的预测和分类。
我们抓住重点,即神经网络由神经元组成,要了解什么是神经网络,先要了解什么是神经元。
同样先给出神经元的一种阐述:
神经元是神经网络的基本计算单元,接收输入信号,加权求和后添加偏置,再通过激活函数输出结果。
我们通过课程中里的例子来进行说明:
现在,我们有一个数据集,包含房屋面积和房屋价格两类数据。我们希望通过这两类数据寻找规律,即通过房屋面积预测房屋价格。

如图中左侧所示,此即为一个最简单的神经网络,它由一个输出层神经元节点,一个隐藏层神经元节点和一个输出层神经元节点组成。
课程中的基础介绍较为简略,我们先行补充一下输入层,隐藏层,输出层的概念。
- 输入层的神经元接收外部数据(此时为房屋面积),并将这些数据传递到网络的下一层。每个输入神经元代表输入数据的一个特征,输入层节点数量由特征数量决定。
- 隐藏层的神经元负责数据处理和特征抽取。隐藏层位于输入层和输出层之间,通常有多个隐藏层,这些层主要用于学习数据中的复杂模式。每个隐藏层的神经元通过权重连接接收来自输入层或前一隐藏层的输出信号,并对这些信号进行加权求和。在加权求和后,神经元会通过激活函数进行非线性变换,决定该神经元的输出。这个输出将传递到下一层(可能是另一层隐藏层或输出层)
- 输出层的神经元负责生成最终的结果(此时为房屋价格),如分类标签或回归值。输出层的神经元通常代表模型的预测结果。
需要注意的一点是,在课程中,吴恩达老师称此网络为“单神经元网络”,这里的单神经元是指隐藏层的神经元个数,实际上,输入输出层的节点也是可以被称为神经元,只是这些节点不涉及权重等参数的计算,我们理解即可。
在了解神经元后,紧接着我们就产生了下一步问题,像这样把几个神经元连接起来就可以预测价格了吗?神经网络到底是怎么工作的呢?
神经网络的关键在于隐藏层的设置,我们的数据通过输入层进入隐藏层,而隐藏层的神经元工作如展开篇幅过长,我们在此只阐述隐藏层神经元最基本的功能:对随机初始化权重的输入进行加权求和,本质上是一种线性变换,这个过程我们是不可见的,也就是所谓的“隐藏”。
但结合题目,又产生了新的问题:我们不难想到,房屋面积和房屋价格都不可能为负数,因此,本题的拟合函数一定是一个非线性函数,如下图所示:

那隐藏层又如何处理数据的非线性关系呢?
这里便可以引入之前的概念里多次出现的激活函数了。
激活函数 是一种数学函数,它的输入是神经元的加权和(即输入信号和权重的乘积之和),输出是经过函数变换的结果。激活函数的主要作用是通过非线性变换引入网络的非线性特性,使神经网络能够表示和处理复杂的模式。
个人理解来说,激活函数就是结合问题非线性的实际关系后对隐藏层输出的进一步变换,提供了处理复杂能力的关系。
目前已有的激活函数多种多样,最简洁且实用的便是适用本题的线性修正单元(Rectified Linear Unit,ReLU)激活函数,其公式为:
因此,在隐藏层添加激活函数后,即可处理房屋面积和房屋价格都不可能为负数的情况。
在此之后,最终的输出会和答案进行对比计算误差并以此更新输入的权重,如此反复,最终达成良好的,可以处理复杂问题的拟合效果,这便是神经网络的简要工作原理,涉及的其他过程会在之后的课程中再详细展开。
单神经网络如此工作,多神经网络同样如此,我们再对房屋价格问题进行简单的扩展,扩大神经网络的规模,如下图所示:
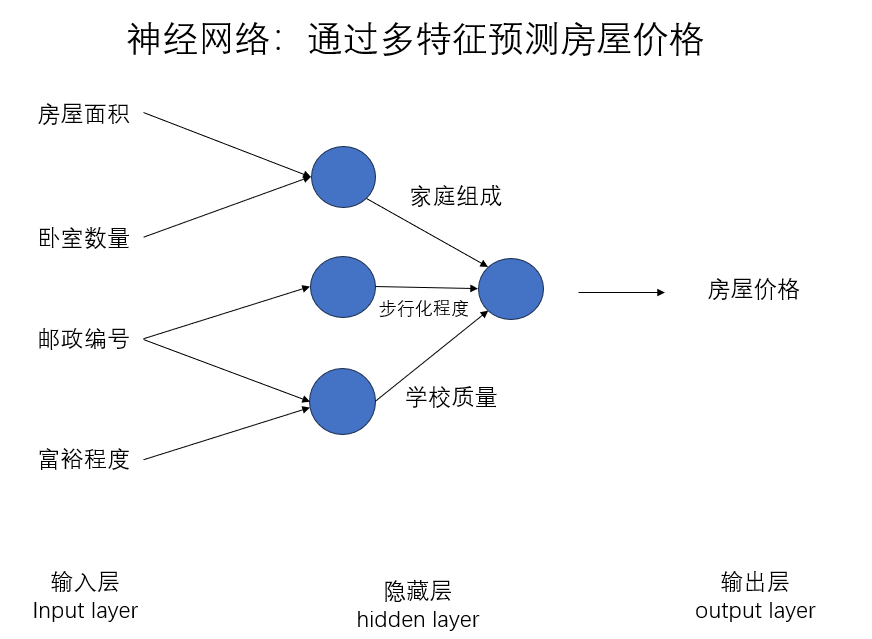
可以发现,我们增加了输入的特征数量的同时也增加了一层新的隐藏层,实际上,隐藏层层数的增加是对特征的进一步抽象,就如图中所示,我们可以从房屋面积和卧室数量推断家庭组成,从邮政编号和富裕程度推断学校质量,多数情况下,这将更有利于我们的拟合效果。
但要说明的是,这张图的连接关系只是便于理解,实际上,我们更常用下面这样的连接:

可以看到,我们的每个输入特征都对和下一层的隐藏神经元进行了全连接,隐藏层间同样如此,由神经网络自身完成特征的进一步提取,我们只需设置好输入,参数,中间的过程即可完全由神经网络自己完成。
总之,在拥有足够数据量的监督学习情况下, 神经网络非常擅长数据的拟合。
1.2神经网络的发展和应用领域都有什么?
神经网络的主要应用和其创造的经济价值都基于机器学习中的监督学习。
监督学习(Supervised Learning)是机器学习中的一种学习方式,在这种学习过程中,算法从一组输入数据和对应的正确输出(标签)中学习,目的是通过建立一个映射关系,从而预测新的、未见过的数据的标签。具体来说,监督学习的目标是根据已知的训练数据,学会一个函数模型,该模型能够将输入映射到正确的输出。
通俗来讲,把模型比作学生,训练比作考试,监督学习就是学生可以在考试-对答案-考试的重复中不断提高自己的成绩。
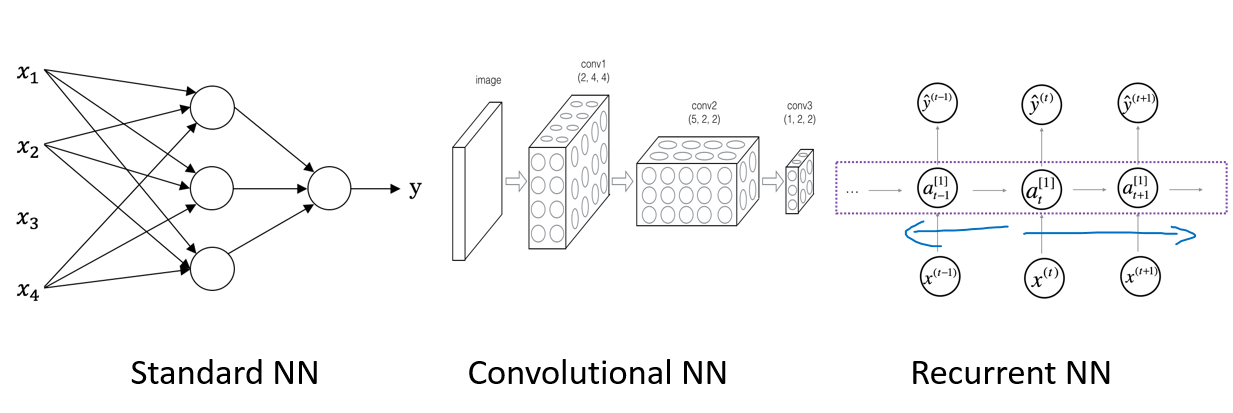
在监督学习的基础上,神经网络又发展出常用于处理图像数据的卷积神经网络(Convolutional Neural Network, CNN)和处理序列数据的循环神经网络(Recurrent Neural Network, RNN)
二者都有自己适用的应用领域,举例如下:
- NN:房地产,广告点击
- CNN:图片分类,标记
- RNN:音频处理,语言反应
- 面对无人驾驶等复杂问题,则常需要复杂的混合神经网络
![Pasted image 20251003201009]()
1.3什么是结构化数据和非结构化数据?
- 结构化数据是指高度组织化且以预定义的数据模型进行存储的数据。这些数据通常可以在表格中表示,并且每个数据项(如行和列)都有明确的定义。
- 非结构化数据是指没有预定格式或数据模型的数据。这类数据没有固定的组织形式,通常无法被传统的数据库直接存储和查询。它包括各种文本、图像、音频、视频等类型的数据。
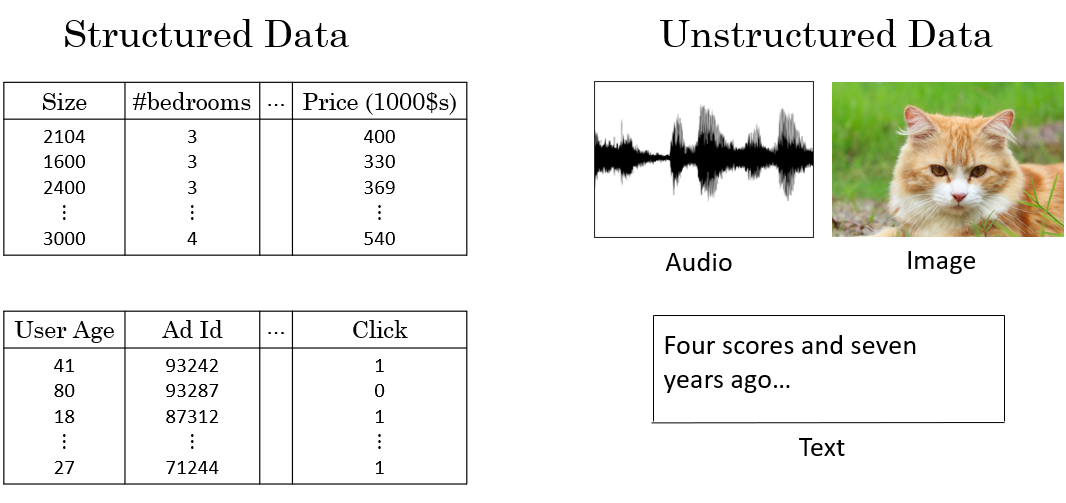
得益于深度学习和神经网络的发展,计算机相比几年前,能更好地处理和应用非结构化数据,也同样创造了巨大的经济价值。
1.4深度学习为什么会兴起?
- 传统的机器学习算法随着数据量的进一步增加进入瓶颈期,而相比之下,规模反而推动了深度学习的发展,一个大型的神经网络在海量数据的支持下表现极佳。
- 在数据量较小的情况下,各类算法的优劣并不明显,更取决于组件和算法的涉及,但当数据量到达一定量级,神经网络便会稳定占据优势。
- 算法方面的创新也进一步推动了代码运行速度,让思考,实验,修改的周期更短。
![Pasted image 20251003205549]()

2.课后习题
习题链接:【中英】【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第一周测验
本部分习题均为选择,无编程习题,熟悉相关概念即可。