前言
GPU的发展起源可追溯至20世纪80-90年代,其核心驱动力来自游戏对浮点运算(FPU)的爆炸性需求。早期CPU的FPU性能仅为游戏需求的1/20,迫使英特尔通过MMX、SSE等向量处理单元提升并行计算能力,但仍无法满足需求。制造商随后开发了外接浮点运算网卡,这类“插入式卡”逐渐演变为现代GPU的雏形。
1999年,NVIDIA推出了GeForce 256,首次提出了“GPU”这一概念,标志着GPU作为通用计算平台的开始。GeForce 256具备了实时图形处理的能力,支持可编程性,使得GPU不仅限于图形显示,还能用于科学计算。
GPU技术市场:在2016年,NVIDIA凭借Pascal架构的发布和VR技术的支持,首次超越AMD和Intel,成为全球最大的GPU制造商
1、什么是GPU?
GPU是graphics processing uint,图像处理器,与CPU(中央处理器)相对应。 显卡实际是GPU和显存共同构成的。
GPU和CPU设计目标不同:
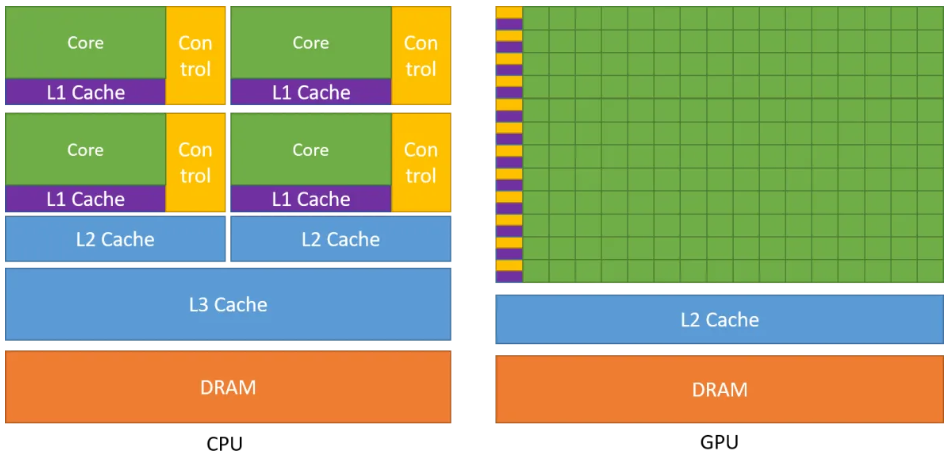
- CPU旨在尽可能快的速度执行几十个线程,有少数几个可快速计算的物核心,有更多的晶体管用于数据缓存和流量控制;
- GPU旨在尽可能多的并行执行数千个线程,有几百到几千个不那么快速计算的核心,有更多的晶体管用于算术逻辑单元;所以,GPU是靠众多的计算核心获得较高的计算性能的。如下图cpu和gpu核心对比
![]()
2、GPU硬件架构
-
线程组织分层概念:
线程(thread):一个CUDA的并行程序会被以许多个threads来执行
线程束(warp):GPU中执行线程的最小单元,一个线程束由32个连续的线程组成。比线程束更小的执行单元没有意义``
线程块 (block):数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信
网格(grid):多个blocks则会再构成grid。 -
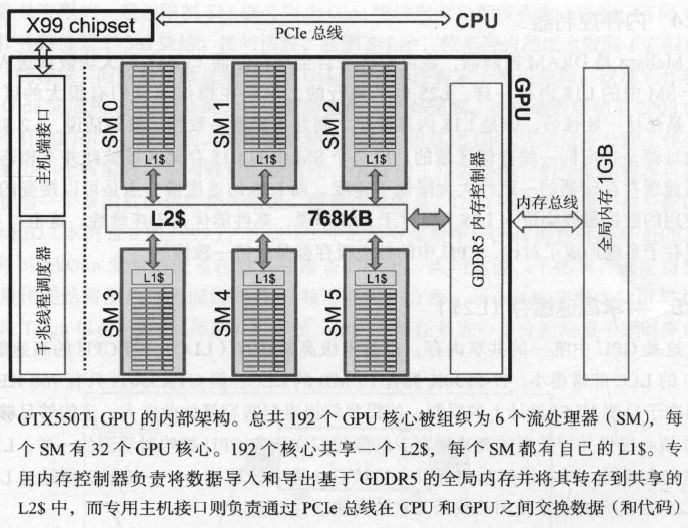
GTX550Ti GPU内部架构示意图:
![]()
-
GPU硬件部件构成:
流处理器(SM):包含多个GPU核心、共享内存..等,见下表SM构建模块
GPU核心:包括FP(浮点执行单元)、INT(整数执行单元)等
千兆线程调度器:根据SM的可用性来分配每个块
内存控制器:负责将来自全局寄存器的大块数据送入L2$
共享高速缓存(L2$):末级缓存(LLC),在所有核心之间共享,是GPU缓存GM的地方。与CPU架构中的末级缓存L3$相比内存非常小。
主机接口:GPU内部负责连接PCIe总线的控制器,即在CPU和GPU之间控制传输数据的部分
SM构建模块:![]()
-
NVIDIA不同GPU架构发展: 漫谈英伟达GPU架构进化史:从Celsius到Blackwell
支持CUDA编程的几个系列:(http://developer.nvidia.com/cuda-gpus)
Tesla系列:其中的内存为纠错内存
Quadro系列:支持高速OpenGL(open graphics library)渲染,主要用于专业绘图设
计
GeForce系列:主要用于游戏与娱乐,但也常用于科学计算
Jetson系列:嵌入式设备中的GPU

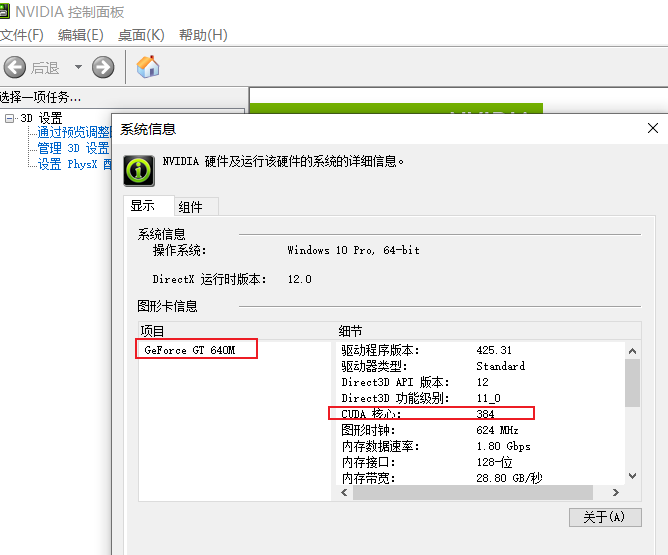
3、查询我电脑的GPU信息
打开NVIDIA控制面板,查看系统信息:
4、统一计算设备架构
GPU自诞生来,定位为CPU监督下工作的“协处理器”,所有数据达到GPU前先到达CPU(PCIe总线连接),所以GPU计算实际是指CPU+GPU的异构计算,CPU为主机(host),而GPU为设备(device)。而CUDA、OpenCL是两种主要的GPU编程语言
- CUDA语言
为了运行GPGPU程序员开发的代码而不学习任何使用OpenGL计算图行学知识,nividia于2007年推出的统一计算设备架构,CUDA仅应用于Nvidia平台。
CUDA基于C语言(CPU端)提供高性能处理,GPU端必须和CPU端一样,只用特定关键字区分主机和设备端代码。有CUDA编译器决定在那个设备上运行,GPU的并行性在GPU端显现。因此nividia设计了NVCC编译器。
-
OpenCL语言
2009年推出,允许为intel、AMD和其他类型GPU开发GPU代码。OpenCL的设备端不必是一个GPU,可以是FPGA、DSP等具有并行架构的设备 -
CPU与GPU架构差异
1.GPU环境中,GPU核心负责所有任务的执行,但任务指令来自CPU
2.GPU环境中,GPU核心总不自己处理获取数据,数据都来自CPU端,计算结果再传回CPU端。因此GPU只在后台扮演计算加速器的角色,为CPU完成外包任务。
3.CPU+GPU这种体系架构只有存在大量的并行处理单元才非常有效,而不是仅2个、4个单元。GPU在任何时候都不能低于同时执行32个任务。在GPU环境中,称合并在一起的32个线程为“线程束”。GPU将一个 核心完成的任务称为一个线程,而任何时刻执行的线程数都不会低于一个线程束。
4.线程束概念很重要。数据必须以同样大小的数据块为单位输入GPU。
5.数据以半个线程束大小传给GPU核心,表示将数据传入GPU核心的存储子系统每次应该输入16个数据,即要求一个能一次传输16个数据的并行存储系统(所以GPU的DRAM是DDR5构成的)
6.GPU核心和CPU核心是完全不同的处理单元,因此有不同的ISA(指令集架构),所以必须编写两种不同的程序,但都可以用nvcc编译器编译。而CUDA语言将两者结合在一起